

ТВиМС / Стат_Лекц / Стат_Примитивы / СтаЛР_1_Пр
.doc-
Прямая линейной регрессии
-
Постановка задачи
-
Пусть имеются два массива числовых данных, значения которых в векторной форме можно записать так:
y1nT = (y1, y2, … yn) и x1nT = (x1, x2, ... xn).
Графически эти массивы можно представить в виде точек (рис. 1) на плоскости XOY.
X
Рис. 1
Линейная регрессия
Массив yn1, называемый откликами, рассматривается как случайный, а массив xn1, называемый предикторами, – не случайный. Для одних и тех же значений предиктора x j могут быть получено несколько откликов y i, … y k. Количество различимых значений предиктора обозначим литерой «m». Очевидно, что j = 1, …, m.
Задача заключается в установлении функциональной зависимости
Y = φ(X) (1)
между величинами Y и X по числовым данным, имеющимся в обоих массивах yn1 и x n1.
Такая зависимость называется регрессией Y от X.
Из всего многообразия функций φ выберем преобразование, линейное относительно некоторого вектора параметров
1kT = (0k-1 k<n
и вектора регрессоров
F1k = (f0 f1 … fk-1), (3)
которые являются дифференцируемыми функциями предиктора X, т.е.
fj = f j (X). (4)
В векторной форме подобное преобразование имеет вид:
y = F1k* k1 (5)
и называется линейной регрессией.
Регрессоры f j (4) подбираются исследователем по данным графического анализа массивов yn1 и xn1, а параметры k1 «оцениваются» путём обработки этих же массивов данных по определённым алгоритмам.
-
Подбор прямой «линейной регрессии»
В простейшей ситуации уравнение линейной регрессии имеет вид:
Y = f0*β0 + f1*β1 = β0 + β1* X, (6)
т.е. регрессоры f0 и f1 равны, соответственно, f0 = X0 = 1, f1 = X. Уравнение (6) представляет собой математическую модель (ММ) исследуемого явления. Напоминаем, что массивы yn1 и xn1 – это числовые данные (простая выборка), полученные в ходе эксперимента.
В процессе наблюдений истинные значения отклика Yi искажаются неопределённостями εi:
yi = Yi – εi. (7)
Массивы yn1 и xn1 позволяют составить систему из n уравнений типа (6):
yi = β0 + β1* xi – εi, (i = 1,2, … n). (8)
Неизвестные параметры β0 и β1, а также неопределённости εi оцениваются из решения системы (8), дополняемой ограничением наименьших квадратов, которое имеет вид:
=
![]() =
=![]() =
min. (9)
=
min. (9)
Ограничение, определяемое соотношением (9), называется ограничением по методу наименьших квадратов или более лаконично МНК-ограничением.
Обозначим оценки параметров и неопределённостей соответствующими буквами латинского алфавита:
![]() = b,
= b,
![]() = e.
= e.
В таком случае уравнения (8), решаемые с ограничением (9), принимают вид:
y i
= b0
+ b1*
xi
+ ei
i
= b0
+ b1*
xi
+ ei
. (10)
=
![]() =
min
=
min
Полученная система (10) решается методом абсолютного экстремума, необходимым условием существования которого является равенство нулю частных производных МНК-ограничения (9) по оцениваемым параметрам:
∂Ψ/∂b0 = 0 и ∂Ψ/∂b1 = 0.
Найдём эти производные:
∂ Ψ/∂b0
= – 2
Ψ/∂b0
= – 2![]() (yi
– b0
– b1*
xi)
= 0
(yi
– b0
– b1*
xi)
= 0
. (11)
∂Ψ/∂b1
= –2![]() xi*(yi
– b0
– b1*
xi)
= 0
xi*(yi
– b0
– b1*
xi)
= 0
Воспользуемся обозначениями Гаусса для образующихся сумм:
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
У равнения
(11) называются нормальными
и, с учётом обозначений Гаусса, могут
быть записаны так:
равнения
(11) называются нормальными
и, с учётом обозначений Гаусса, могут
быть записаны так:
n*b0 + [x]*b1 = [y]
. (12)
[x]*b0 + [x2]*b1 = [xy]
Матричный эквивалент системы (12) имеет вид
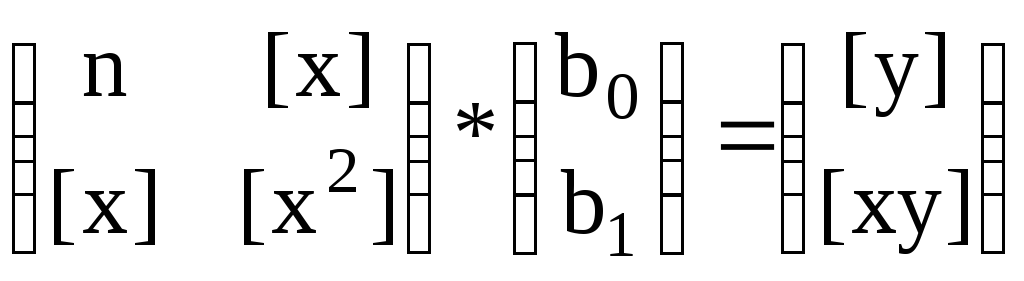 . (13)
. (13)
Решение системы (13), в матричной же форме, имеет вид:
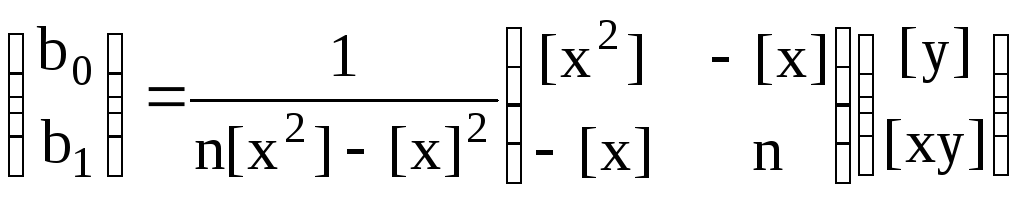 . (14)
. (14)
Прежде чем перейти к алгебраической форме выражения (14), введём дополнительные обозначения, которые упростят вычислительную процедуру:
![]() ,
,
![]() . (15)
. (15)
Окончательно, решение системы (14) можно записать так:
b 0
=
0
=
![]()
. (16)
b1
=
![]()
Вычисление параметров по формулам (14) или (16) контролируется по формуле связи, вытекающей из первого уравнения системы (12):
![]() =
b0
+ b1*
=
b0
+ b1*![]() . (17)
. (17)
После контроля оценок параметров b0 и b1 мы можем записать уравнение математической модели (6), называемое уравнением регрессии:
ŷ = b0 + b1*x. (18)
Оценки неопределённостей ei, называемые «остатками», могут быть вычислены по формуле (7) с заменой неизвестных истинных значений откликов Yi соответствующими регрессионными значениями ŷ i, найденными по уравнению регрессии (18):
ei = yi – ŷ i. (19)
Нахождение остатков контролируется соотношением
[e] = [y] – n*b0 – [x]*b1 0, (20)
вытекающим из формулы связи (17) и являющимся гарантией правильности построения уравнения регрессии (18).
-
Дисперсионный анализ модели
Массив откликов
yn1
характеризуется дисперсией σ2,
оценка которой
![]() для случая линейной регрессии вычисляется
по формуле (без
вывода!):
для случая линейной регрессии вычисляется
по формуле (без
вывода!):
![]() . (21)
. (21)
Апостериорные значения дисперсий оценок параметров могу быть получены по диагональным элементам обратной матрицы (14) коэффициентов нормальных уравнений (13):
![]() , (22)
, (22)
![]() . (23)
. (23)
Формулы (21) – (23) применимы только для двухпараметрической линейной модели!
-
Проверка статистических гипотез
При создании регрессионной математической модели обычно проверяют следующие нулевые гипотезы:
-
H0 = {ММ не адекватна измерениям yn1};
-
H0 = {Регрессия не знàчима};
-
H0 ={Параметр bj не знàчим};
-
H0 = {ММ не накрывает контрольную (ые) точку (и)}.
-
Гипотеза о неадекватности ММ
Гипотеза H0 = {2L ≠ 2e} о неадекватности модели проверяется путём сопоставления между собой различных оценок дисперсии откликов σ2. Дисперсия «подгонки»
![]() , (24)
, (24)
полученная по
уклонениям регрессионных значений ŷi
от локальных центров наблюдений
![]() сопоставляется с дисперсией «чистой
ошибки»
сопоставляется с дисперсией «чистой
ошибки»
![]() , (25)
, (25)
вычисленной по
уклонениям измеренных значений yi
от тех же локальных центров
![]() .
.
Поскольку оценки
![]() и
и
![]() для дисперсии σ2
получены по
данным одной и той же простой выборки
yn1,
то их сравнение может быть осуществлено
по F-критерию
на уровне значимости α
с числами степеней свободы
ν1
= m
– k
и ν2
= n
– m.
Здесь n
– это число откликов, m
– количество локальных центров, а k
– число параметров модели. Соответствующий
тест – это отношение дисперсии «подгонки»
к дисперсии «чистой
ошибки»:
для дисперсии σ2
получены по
данным одной и той же простой выборки
yn1,
то их сравнение может быть осуществлено
по F-критерию
на уровне значимости α
с числами степеней свободы
ν1
= m
– k
и ν2
= n
– m.
Здесь n
– это число откликов, m
– количество локальных центров, а k
– число параметров модели. Соответствующий
тест – это отношение дисперсии «подгонки»
к дисперсии «чистой
ошибки»:
tЭ
=
![]() /
/
![]() . (26)
. (26)
Предельное значение данного теста – это квантиль F-распределения на уровне значимости α:
tП = arg(Fm-k; n-m = α). (27)
Теперь, если tЭ > tП, то гипотеза о неадекватности модели H0 = {2L ≠ 2e} отвергается.
Примечание.
Поскольку квантиль
F-распределения
всегда больше единицы, т.е. Fν1;ν2>1,
то в случае, когда tЭ
=
![]() /
/
![]() <1,
мы можем не определять квантиль (27). В
таком случае гипотеза H0
= {2L
≠ 2e}
о неадекватности модели не будет
отвергнута на любом уровне значимости
α.
<1,
мы можем не определять квантиль (27). В
таком случае гипотеза H0
= {2L
≠ 2e}
о неадекватности модели не будет
отвергнута на любом уровне значимости
α.
-
Гипотеза о незначимости регрессии
Гипотеза H0
= {![]() =
=
![]() }
о незначимости регрессии
определяется
с использованием ещё двух оценок
дисперсии откликов σ2:
}
о незначимости регрессии
определяется
с использованием ещё двух оценок
дисперсии откликов σ2:
1) среднего квадрата регрессии
![]() , (28)
, (28)
найденного по
разностям регрессионных значений ŷi
и общего среднего
![]() ,
и
,
и
2) дисперсии остатков
![]() , (29)
, (29)
полученной по уклонениям измерений yi от соответствующих регрессионных значений ŷi.
Здесь так же используется F-критерий на том же уровне значимости α, но с другими степенями свободы: ν1 = 1 и ν2 = n – 2. Соответствующий тест – это отношение дисперсии «регрессии» к дисперсии «остатков»:
tЭ
=
![]() /
/
![]() . (30)
. (30)
Предельное значение теста tЭ – это квантиль F-распределения:
tП = arg(F1; n-2 = α). (31 )
Теперь, если tЭ
> tП,
то гипотеза H0
= {![]() =
=
![]() }
о незначимости
регрессии отвергается.
}
о незначимости
регрессии отвергается.
-
Гипотезы о незначимости параметров ММ
Гипотезы H0 = {β0 = 0} и H0 = {β1 = 0} о незначимости параметров ММ проверяются с помощью статистик, использующих МНК-оценки параметров и средние квадратические ошибки (СКО) этих оценок:
tЭ = |bj| / mbj. (32)
Результаты сопоставляются с квантилью t-распределения Стьюдента
tП = tn-2; 1-α/2 = arg(Sn-2 = 1 – α / 2). (33)
Формулы (22) и (23) для квадратов СКО оценок параметров b0 и b1 были получены выше.
Проверяемая гипотеза отвергается, когда tЭ > tП.
Если хотя бы одна из этих гипотез не отвергнута, то ММ должна быть изменена и вновь подвергнута всем предыдущим проверкам.
-
ММ накрывает контрольные точки
При построении ММ по данным эксперимента рекомендуется часть собранной информации (1% – 5%) зарезервировать в качестве контрольных данных. Дальнейшая процедура проверки эффективности построенной ММ заключается в следующих шагах.
У каждой контрольной точки {xk; yk} её отклик yk заменяется регрессионным значением ŷk (18). Далее, используя эту точечную оценку, на уровне значимости α строят доверительный интервал
Ik = { ykH; yk B}, (34)
нижняя и верхняя границы которого вычисляются в предположении Стьюдентовского распределения регрессионной оценки ŷk:
ykH = ŷk – tn-2; 1-α/2*mŷk , (35)
ykB = ŷk + tn-2; 1-α/2*mŷk , (36)
где
mŷk
= μ*![]() . (37)
. (37)
Если интервал (34) накрывает значение контрольного отклика yk, то предположение H0 = {ММ не накрывает контрольную точку} отвергается.
Дополнительно для
линии регрессии (18) можно построить
доверительную
область,
определяемую тремя парами нижних yH
и верхних yB
границ, вычисляемых в точках {xmin;
ŷmin
}, {![]() ;
;![]() }
и {xmax;
ŷmax
}:
}
и {xmax;
ŷmax
}:
yH = ŷ – tn-2; 1-α/2*mŷ , (38)
yB = ŷ + tn-2; 1-α/2*mŷ . (39)
Здесь
mŷ
= μ*![]() . (40)
. (40)
Через точки {yBmin;
![]() B;
yBmax}
и {yHmin;
B;
yBmax}
и {yHmin;
![]() H;
yHmax}
проходят кривые, представляющие собой
верхнюю и нижнюю границы
доверительной области.
Точки, которые были использованы для
построения регрессионной модели (18)
должны находиться внутри области. Что
касается контрольных точек, то достаточно,
чтобы их доверительные интервалы (34)
пересекались с доверительной областью
прямой линейной регрессии.
H;
yHmax}
проходят кривые, представляющие собой
верхнюю и нижнюю границы
доверительной области.
Точки, которые были использованы для
построения регрессионной модели (18)
должны находиться внутри области. Что
касается контрольных точек, то достаточно,
чтобы их доверительные интервалы (34)
пересекались с доверительной областью
прямой линейной регрессии.