

Практика 2015 / Методические указания к практике / СПС ч1
.pdfФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ТВЕРСКОЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
__________________________________________________________________
КАФЕДРА «ИНФОРМАЦИОННЫЕ СИСТЕМЫ»
Введение в информационно-поисковые системы
Часть 1
Методические указания по изучению дисциплины "Мировые информационные ресурсы"
для студентов специальностей «Прикладная информатика (в экономике)» и «Информационные системы и технологии»
Тверь 2005
УДК 025.4.036:004.6(075.8)+025.4.036:004.738.5(075.8); 681.3.01(075.8)+681.324(075.8)
ББК 73.я7+32.81.я7
В методических указаниях рассматриваются основные принципы построения информационно-поисковых систем (ИПС) и их практического применения. Приводятся понятия и определения, обсуждаются информационные потребности пользователей. Рассматривается представление информации в ИПС, принципы анализа текстов и индексирования документов, типичные модели (булева и векторная) и алгоритмы поиска информации. Приводятся основные сведения о классификации документов. Обсуждаются современные словарные, классификационные и метапоисковые ИПС, их практическое применение и критерии эффективности.
Методические указания предназначены для студентов специальностей «Прикладная информатика (в экономике)» и «Информационные системы и технологии».
Методические указания обсуждены и рекомендованы к печати на заседании кафедры «Информационные системы» (протокол № 5 от 20.12.2004 г.).
Составители: В.К. Иванов, К.В. Иванов.
Введение в информационно-поисковые системы
Часть 1
Методические указания по изучению дисциплины "Мировые информационные ресурсы" для студентов специальностей «Прикладная информатика (в экономике)» и «Информационные системы и технологии»
Редактор Т.С. Синицына Технический редактор
_____________________________________________________________________
Подписано в печать |
|
|
Формат 60x84/16 |
Бумага писчая |
|
Физ. печ. л. 2.25 |
Усл. печ. л. 2.09 |
Уч.-изд. л. 1.96 |
Тираж 100 экз. |
Заказ № 14 |
С-14 |
_____________________________________________________________________
Типография ТГТУ
© Тверской государственный технический университет, 2005
3
Содержание
ВВЕДЕНИЕ....................................................................................................................................................................... |
4 |
1. ОСНОВНЫЕ ПРИНЦИПЫ ПОСТРОЕНИЯ ИПС............................................................................................... |
6 |
1.1. ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ.............................................................................................................................................. |
6 |
1.2. ИНФОРМАЦИОННАЯ ПОТРЕБНОСТЬ ПОЛЬЗОВАТЕЛЯ.............................................................................................................. |
7 |
1.3. РЕЛЕВАНТНОСТЬ............................................................................................................................................................ |
9 |
1.4. ОБЩАЯ СХЕМА ПРОЦЕССА ПОИСКА................................................................................................................................. |
11 |
2. ПРЕДСТАВЛЕНИЕ ИНФОРМАЦИИ В ИПС...................................................................................................... |
13 |
2.1. ИНДЕКСИРОВАНИЕ ДОКУМЕНТОВ.................................................................................................................................... |
13 |
2.2. ВЕКТОРНАЯ МОДЕЛЬ ТЕКСТА......................................................................................................................................... |
14 |
2.3. СТАТИСТИЧЕСКИЙ АНАЛИЗ ТЕКСТОВ. ЗАКОН ЦИПФА........................................................................................................ |
15 |
2.4. АНАЛИЗ ИНФОРМАЦИОННЫХ МАССИВОВ......................................................................................................................... |
19 |
2.4.1. Понятие относительной частоты............................................................................................................. |
19 |
2.4.2. Распределение частоты встречаемости терминов.................................................................................. |
21 |
2.5. ОПРЕДЕЛЕНИЕ ВЕСОВ ТЕРМИНОВ.................................................................................................................................... |
23 |
2.5.1. Частотная модель......................................................................................................................................... |
24 |
2.5.2. Вероятностная модель................................................................................................................................. |
24 |
2.5.3. Латентно-семантический анализ................................................................................................................ |
28 |
3. ХРАНЕНИЕ ИНДЕКСИРОВАННЫХ ДОКУМЕНТОВ..................................................................................... |
30 |
СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ................................................................................................... |
34 |

4
Введение
Очень давно человек впервые задумался о том, как хранить знания для дальнейшего удобного и эффективного использования. Классический пример этого – оглавление книги, которое делает возможным быстрый доступ к любому интересующему нас разделу.
С ростом числа книг возникла необходимость в более удобных способах хранения. В библиотеках появились каталоги, или индексы – наборы ключевых слов или понятий, связанные с коллекциями книг и других документов. С помощью каталогов доступ к информации становится достаточно простым, а скорость его относительно велика. Тем не менее, решение задач по поиску информации было в основном уделом работников библиотек и специалистов по теории поиска.
В ХХ веке развитие информационных технологий повлияло на все сферы человеческой жизни. Не стал исключением и информационный поиск. В 60 и 70-е годы для ускорения процессов каталогизации и поиска появились первые автоматизированные информационно-поисковые системы1 (ИПС). Они применялись в каталогах и информационных отделах крупных библиотек. Тогда и начались серьезные исследования теории и практики информационного поиска и построения ИПС [, , ].
Говоря об ИПС, следует разделять понятия «поиск информации» и «поиск данных». Поиск информации – это более широкое понятие, допускающее более мягкие критерии соответствия искомой информации потребности пользователя. В отличие от систем поиска данных, которые имеют дело со строго формализованными данными и запросами2, ИПС работают с информационными объектами разной (чаще всего небольшой) степени формализованности, в основном с текстами на естественном языке. Точность работы ИПС определяется релевантностью найденных документов, четкого однозначного критерия которой не существует (это будет показано в разделе 1.3) [, ].
За последние десять лет область информационного поиска значительно расширилась. Создание электронных библиотек на базе крупнейших мировых хранилищ информации, развитие систем мультимедийного поиска, широкое внедрение систем управления документами и т. п. являются стимулом для непрерывного совершенствования технологий поиска информации.
1 Английское обозначение информационно-поисковых систем – information storage and retrieval systems, information retrieval systems.
2 Такие системы обычно реализуются в системах управления базами данных (СУБД). Языки запросов, например, SQL или XPath, оперируют математически точными критериями поиска, а хранимые данные имеют четко определенную структуру. В настоящих методических указаниях эти системы не рассматриваются.
5
Однако наиболее революционным событием стало зарождение и развитие сети Интернет. В 90-е гг. ХХ в. человечество получило доступ к огромному массиву информации в самых разных предметных областях – миллионам связанных документов, которые расположены на компьютерах по всему миру. Интернет сегодня – это неструктурированное распределенное хранилище динамичной информации громадного объёма, в котором постоянно добавляются новые документы, а устаревшие редактируются или удаляются.
Колоссальное и непрерывно растущее количество информации приводит к тому, что обеспечение поиска в Интернете становится критически важной задачей. Однако без соответствующих поисковых средств проблема поиска в сети необходимой информации становится в настоящее время практически неразрешимой.
Появление поисковых систем сети Интернет стало новым этапом в развитии информационного поиска. Сегодня ИПС сети Интернет эффективно применяют разработанные за много лет методы поиска информации. Более 75% пользователей пользуются ИПС для поиска информации в Интернете []. В то же время специфика природы сети Интернет и ее непрерывное развитие ставят перед исследователями новые задачи, многие из которых не решены до сих пор.
Современные теоретические и практические исследования информационного поиска сконцентрированы вокруг нескольких крупных международных конференций []. К ним относятся серия конференций TREC (Text Retrieval Conference), проводимая институтом NIST (National Institute for Standards and Technology) США, конференции SIGIR (Special Interest Group on Information Retrieval), организованные международной группой исследователей и разработчиков технологий информационного поиска ACM (Association of Computing Machinery), а также конференция, которая занимается различными проблемами, связанными с Интернет – WWW Conference [, ]. В России по вопросам информационного поиска ежегодно проводится конференция «Электронные библиотеки (RCDL)» [, ].
Внастоящих методических указаниях рассматриваются информационный поиск
ипоисковые системы в основном с точки зрения используемых в них информационных технологий. Изложенный материал носит обзорный характер. Описаны модели и реализующие их алгоритмы, архитектура систем и технические особенности их реализации. Определенное внимание уделено и взаимодействию человека, осуществляющего поиск, с поисковой системой. Рассмотрены проблемы восприятия и интерпретации информации пользователем ИПС.
Рекомендации состоят из двух частей. В части 1 перечислена основная терминология информационного поиска, дано определение информационной потребности
6
пользователя и описана общая схема процесса поиска. Далее анализируются информационные массивы и их представление в ИПС, процессы индексирования и взвешивания терминов. Рассматривается порядок хранения индексированных документов. В части 2 описываются основные модели и алгоритмы поиска информации в ИПС, а также один из традиционных методов анализа документов – классификация. Перечисляются главные критерии эффективности ИПС и способы их оценки. В заключении описывается архитектура и состав современных ИПС, работающих в сети Интернет.
Изложение материала предполагает, что студенты знакомы с матричной алгеброй и теорией вероятностей, с основами математической логики, теорией информационных систем и основами теории баз данных, основами методологии тестирования и оценки систем, а также с основами Интернет-технологий.
1. Основные принципы построения ИПС
1.1. Понятия и определения
Информационный поиск – это отрасль знания, которая занимается представлением, хранением и доступом к информационным ресурсам. Теория информационного поиска оперирует несколькими ключевыми понятиями, определения которых даны ниже.
Информационный ресурс – это любой материальный объект, который фиксирует или подтверждает какие-либо знания и может быть включен в определенное собрание. По форме различают текстовые (книги, журналы, рукописи), графические или изобразительные (чертежи, схемы, графики, планы, карты, диаграммы), аудиовизуальные (звукозаписи, видеозаписи, фильмы) информационные ресурсы [].
Наряду с информационным ресурсом, в информационном поиске также используется понятие «документ». Под документом чаще всего понимается содержательно законченный текстовый информационный ресурс, который можно каким-либо образом уникально идентифицировать. ИПС оперируют электронными документами, т.
е.представлениями документов на машиночитаемых носителях в ЭВМ [].
Спонятием документа тесно связаны метаданные и суррогаты. Метаданные (метаинформация) – это структурированная информация о документе, например, библиографические сведения, информация о качестве документа, отзывы других пользователей. Под суррогатом понимают представление документа в виде заголовка, имени автора, аннотации, ключевых слов и т. д. [].
7
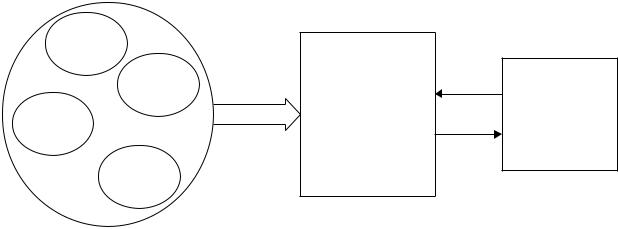
ИПС представляет собой комплекс программных и аппаратных средств, который обеспечивает отбор и представление электронных документов по заданным критериям.
На рис. 1 представлена общая схема работы информационно-поисковой систе-
мы.
Документ |
|
|
|
1 |
Сведения о |
|
|
Документ |
Запрос |
||
документах Информационно- |
|||
3 |
Ответ Пользователь |
||
Документ |
поисковая |
||
2 |
система |
|
|
Документ |
|
|
|
N |
|
|
Множество информационных ресурсов
Рис. 1. Информационно-поисковая система
ИПС работают с множествами документов, которые называются также коллекциями документов. Примерами таких множеств могут служить электронная библиотека, русскоязычная часть Интернета, энциклопедия на лазерном диске.
1.2. Информационная потребность пользователя
Итак, в определенный момент времени у некоторого пользователя возникает информационная потребность в документах по той или иной нужной ему тематике, которая обычно достаточно узка [].
В начальный момент эта потребность часто не может быть точно выражена словами. При этом любая поисковая система требует достаточно четких запросов. Следовательно, пользователь должен представить свою информационную потребность в виде некоторого выражения, которое может быть воспринято поисковой системой.
Выделяют четыре этапа представления информационной потребности [, , ]: −реальная информационная потребность – это неосознанная истинная инфор-
мационная потребность пользователя (потребность в некоторой новой информации при решении стоящей перед пользователем задачи);
−осознанная информационная потребность – появляется после осознания пользователем стоящей перед ним проблемы (осознанная потребность отличается
8
от реальной, более того, пользователь может понимать имеющуюся проблему неправильно);
−выраженная информационная потребность – результат описания осознанной информационной потребности с помощью естественного языка;
−формализованная информационная потребность – это результат представления выраженной потребности средствами формального поискового языка ИПС.
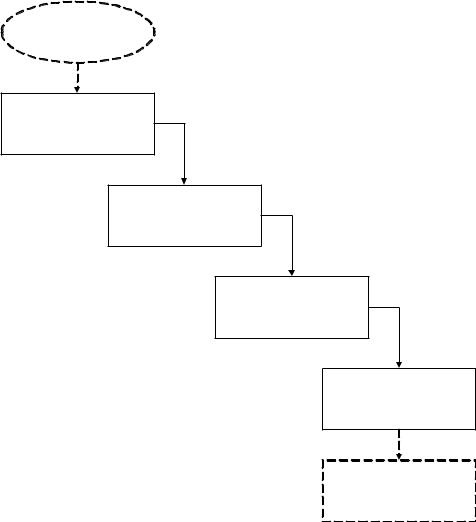
На рис. Рис. 2 показана эволюция представлений информационной потребности. По мере переходов от одного представления к другому отличие от первоначальной реальной потребности увеличивается.
Проблема, стоящая перед пользователем
Реальная
информационная потребность Осознание
Осознанная
информационная потребность Выражение
Выраженная
информационная
потребность Формализация
Формализованная
информационная
потребность
Информационнопоисковая система
Рис. 2. Представления информационной потребности
Необходимость формулирования информационной потребности на специальном информационно-поисковом языке (ИПЯ) определяется тем, что интерпретировать естественный язык весьма сложно. Это научно-практическое направление интенсивно развивается в настоящее время, и некоторые поисковые системы позволяют пользователям составлять запросы на естественном языке []. Однако в таком
9
случае информационную потребность в формализованном виде определяет сама система.
Информационная потребность, сформулированная на информационно-поиско- вом языке, называется запросом.
Запрос поступает в ИПС, и система возвращает некоторый ответ. Степень соответствия ответов поисковой системы запросу пользователя, а значит, и его информационной потребности, называется релевантностью [].
1.3. Релевантность
Релевантность – это фундаментальное понятие теории информационного поиска. Тем не менее, оно не является специфичным для информационно-поисковых систем, и изучается многими направлениями науки: философией, психологией, теорией искусственного интеллекта, теорией обработки естественных языков и т. д. [].
Понятие релевантности возникло одновременно с появлением первых библиотек, посетителям которых требовалось найти книги для удовлетворения информационной потребности. Стимулом для детального анализа релевантности послужило появление в середине ХХ века информационно-поисковых систем. Обсуждение понятия релевантности продолжается уже более полувека, но, несмотря на это, его единого общепринятого определения до сих пор не существует [].
Наиболее часто используются следующие виды релевантности [, ]:
1. Когнитивная релевантность, или пертинентность – характеризует степень соответствия информации из документа и реальной информационной потребности пользователя. Это истинная и наиболее трудноопределимая релевантность. Все остальные виды релевантности являются ее приближениями.
2.Тематическая (предметная) релевантность – характеризует степень близости предмета (тематики) информационной потребности и найденного документа. Под тематикой здесь понимается область интересов пользователя, в пределах которой существует его информационная потребность.
3.Ситуационная релевантность – определяет полезность информационного ресурса для задачи, решаемой пользователем, с точки зрения временных затрат, способа взаимодействия пользователя с системой и т. п.
4.Системная (алгоритмическая) релевантность – характеризует степень близости между формализованной информационной потребностью (запросом) и найденным поисковой системой документом.
Поскольку информационно-поисковый язык является формальным языком, для сравнения запросов и документов можно применять формальные критерии. Поэтому
10
алгоритмическую релевантность, в отличие от остальных видов релевантности, можно рассчитать без участия пользователя. Обычно она определяется самой поисковой системой в ходе работы поискового алгоритма.
Теоретически релевантность можно измерить некоторым числом в интервале от нуля (полностью непертинентный документ) до единицы (полностью пертинентный документ). На практике же релевантность в основном определяется при оценке просматриваемых документов – подходит ли данный документ пользователю или не подходит. Таким образом, релевантность обычно характеризуется бинарным значением [, , ].
Существуют также методы оценки релевантности по многозначной шкале. В этом случае коллектив экспертов просматривает доступные документы и присваивает каждому из них некоторое значение релевантности, которое определяется для каждого запроса. Такая методика используется главным образом при сравнении эффективности нескольких поисковых систем.
Один и тот же документ может быть релевантным согласно одному определению релевантности и нерелевантным согласно другому. Так, документ, релевантный алгоритмически, может оказаться непертинентным. Например, если в неспециализированной ИПС искать информацию о компьютерных манипуляторах типа "мышь" и использовать для этого запрос, состоящий из слова "мышь", то велика вероятность получения ряда непертинентных документов из области зоологии и географии, описывающих мышей-грызунов. При этом найденные непертинентные документы формально будут соответствовать запросу, так как в их тексте содержится термин запроса – "мышь".
Релевантность не является статичной величиной и может со временем меняться. Например, знания пользователя могут измениться после прочтения найденного документа, что в свою очередь может привести к составлению нового запроса, то есть к изменению формализованной информационной потребности. Это иллюстрирует интерактивную природу информационного поиска [, ].
Различные определения релевантности весьма затрудняют оценку эффективности поиска информации. Качество поиска в информационно-поисковых системах обычно характеризуется двумя критериями – полнотой и точностью. Полнота поиска определяется общим количеством найденных документов, а точность – соотношением между найденными релевантными и нерелевантными документами. Из-за многозначности определения релевантности абсолютного критерия точности поиска не существует, и в результатах любого поиска всегда присутствуют как релевантные, так и нерелевантные документы.