

2 qst(0x10001048, 0x10001074, Ox400b20, 0x4) ["qsort.c":147]
3 qsort(0x10001048, Ox1c2, 0x4, Ox400b20) [ "qsort.c" :63]
4 main() ["badqs.c":45]
5 __iatart() ["crt1tinit.s":13]
Это означает, что программа "погибла" в функции st rcmp; при изучении ситуации становится ясно, что два указателя, переданных этой функции, слишком малы — явное указание на проблему. Строка 13 в нашел тестовом файле badqs. с содержит вызов который обнаруживает загубивший вызов и указывает на ошибку.
Отладчик можно использовать также для отображения значений локальных и глобальных переменных, которые могут дать дополнительную информацию об ошибочном месте.
Читайте код перед тем, как исправлять. Один из эффективных, но недооцененных приеморхУгладки — тщательное чтение и обдумывание кода перед внесением в него исправлений. Порою хочется добраться до клавиатуры и начать редактировать программу, чтобы посмотреть, не исчезнет ли ошибка сама собой. Но все же, скорее всего, вы не знаете, что именно сломано, и измените что-нибудь не то, может быть сломав при этом что-нибудь еще. Распечатанный на бумаге критический участок кода выглядит совсем не так, как на экране, и поощряет потратить больше времени на обдумывание. Однако не печатайте листинги постоянно. На распечатку целой программы вы изведете уйму деревьев, а структуру программы, разбросанной по множеству страниц, гораздо сложнее увидеть. Кроме того, распечатка устареет в тот момент, когда вы начнете вносить изменения.
Сделайте перерыв. Иногда вы видите в исходном тексте то, что вы имели в виду, а не то, что вы на самом деле написали. Небольшое отвлечение от текста смягчит ваше недопонимание и поможет коду сказать самому за себя, когда вы к нему вернетесь.
Боритесь с желанием начать исправлять немедленно: подумать — хорошая альтернатива.
Объясните свой код кому-нибудь еще. Другой эффективный способ — объяснить свой код кому-нибудь еще. Такое объяснение часто помогает самому увидеть свою ошибку. Иногда требуется буквально несколько предложений — и звучит смущенная фраза: "Ой, я вижу, где ошибка, извини, что побеспокоил". Это просто замечательный метод, причем в качестве слушателей можно использовать даже непрограммистов.1 В одном университетском компьютерном центре рядом с центром поддержки сидел плюшевый медвежонок. Студенты, встретившиеся с таинственными ошибками, должны были сначала объяснить их этому медвежонку и только затем могли обратиться к консультанту.
Трудные ошибки, нет зацепок
"Не за что зацепиться. Что происходит?" Если у вас действительно нет ни малейшей догадки о том, что же происходит, жизнь становится сложнее.
Сделайте ошибку воспроизводимой. Первый шаг — убедиться, что вы можете заставить ошибку проявляться по вашему желанию. Довольно угнетающе искать ошибку, которая появляется только время от времени. Потратьте время и найдите
такую комбинацию входных данных и настроек, которые гарантированно приводят к ошибке, затем сделайте так, что эту ошибку можно было бы вызвать несколькими нажатиями клавиш. Если ошибка сложна, то при поиске проблемы вам придется повторять ее снова и снова, поэтому, упростив воспроизведение ошибки, вы сэкономите свое время.
Если ошибка появляется от случая к случаю, попытайтесь понять причину этого. Может быть, при каких-то условиях она появляется чаще? Даже если вы не в состоянии повторить ее каждый раз, то, сократив время ее ожидания, вы найдете ее быстрее.
Если программа способна выдавать отладочную информацию, включите ее. Программа случайного моделирования, например программа markov из третьей главы, должна иметь ключ командной строки, выдающий такую отладочную информацию, как, например, стартовое число генератора случайных чисел — это нужно для того, чтобы выдачу программы можно было воспроизвести; другой ключ должен позволять устанавливать это стартовое значение. Многие программы имеют подобные ключи командной строки, неплохо и вам сделать так же.
Разделяй и властвуй. Можно ли уменьшить объем входных данных, приводящих к "падению" программы? Сужайте диапазон возможностей, создавая наименьший набор данных, при котором ошибка все еще проявляется. При каких изменениях ошибка исчезает? Попытайтесь обнаружить важные тестовые случаи, специально фокусирующиеся на ошибке. Каждый тест должен быть нацелен на получение определенного результата, который подтверждает или опровергает какую-нибудь гипотезу о происходящем.
Попробуйте двоичный поиск. Отбросьте половину входных данных и посмотрите, осталась ли ошибка в выходных данных; если нет, то вер-j нитесь к предыдущему состоянию и отбросьте другую половину входных данных. Тот же самый процесс двоичного поиска можно применять и к тексту программы: удалите участок кода, который, по идее, не относится к ошибке, и посмотрите, не исчезла ли она. При сокращении данных для тестирования и больших программ полезен текстовый редактор с возможностью отмены редактирования.
Изучайте нумерологию ошибок. Иногда определенная регулярность чисел, сопровождающих ошибку, подсказывает, на что нужно обратить внимание. Однажды
вновой главе этой книги мы обнаружили серию опечаток, заключавшихся в пропадании случайных букв. Ситуация выглядела таинственной. Текст]$ыл создан посредством вырезания и вставки кусков другого файла,лшэтому казалось, что проблемы были в этих самых командах вырезйния и вставки. Откуда начать поиск? Мы взглянули на данные и заметили, что пропавшие символы были равномерно распределены по тексту. При измерении интервалов оказалось, что расстояние между пропавшими буквами было равно 1023 байтам — подозрительно круглое значение. Поиск в исходном тексте редактора нашел несколько кандидатов — чисел
врайоне 1024. Одно из этих чисел находилось в новом коде, поэтому мы исследовали именно его и немедленно обнаружили классическую "ошибку на единицу", где нулевой байт перезаписывал последний символ в 1024-байтовом буфере.
Изучение структуры чисел, связанных с ошибкой, указало прямо на нее. А затраченное время? Пара минут озадаченности, пять минут рассмотрения данных, чтобы обнаружить закономерность в пропадании символов, минута на поиск вероятных мест ошибки и еще одна минута, чтобы устранить ее. Такую ошибку
совершенно безнадежно было бы искать в отладчике, потому что в ней участвовали две многопроцессных программы, управлявшихся мышью и сообщавшихся друг с другом через файловую систему.
Выводите информацию, локализующую место ошибки. Если вы не понимаете, что именно делает программа, добавьте в нее операторы, отображающие дополнительную информацию, — зачастую это самый простой и недорогой способ выяснения. Например, выведите в каком-нибудь месте кода "сюда нельзя добраться", если вы считаете, что это так; теперь, если вы увидите это сообщение, переместите операторы вывода назад, ближе к началу, чтобы выяснить, в каком месте начинается неправильное поведение программы. Или же отображайте сообщение "добрались сюда", чтобы найти последнюю точку, в которой все еще было хорошо. Сообщения должны отличаться друг от друга, чтобы можно было понять, куда именно вы смотрите.
Отображайте сообщения в компактной фиксированной форме, чтобы их можно было легко просматривать глазами или с помощью программ типа дгер. (Такие программы просто бесценны при поиске текста. В девятой главе приведена простая реализация такой программы.) Если вы отображаете значение переменных, форматируйте их одинаково. В С и C++ показывайте указатели в виде шестнадцатеричных чисел, например %х или %р; это поможет вам увидеть, равны ли два указателя, взаимосвязаны ли они. Научитесь читать значения указателей и распознавать возможные и невозможные значения, например ноль, отрицательные или нечетные числа, а также маленькие числа. Хорошее знакомство с видами адресов поможет также при использовании отладчика.
Если выводимые результаты могут быть очень объемными, то может , быть достаточно отображать лишь одиночные буквы, например А, В, . . . , в качестве компактного отображения потока выполнения программы.
Пишите код, который проверяет сам себя. Если требуется дополнительная информация, напишите собственную функцию, которая проверяет условия, отображает содержимое соответствующих переменных и завершает программу:
/* check: проверить условие, напечатать сообщение */ /* и закончить работу */
void check(char *s)
{
if -(varl > var2) {
printf("%s: varl %d var2 %d\n", s, varl, var2); fflush(stdout);
/* для гарантии выполнения вывода */ abortQ; /* аварийное завершение */
}
}
Мы сделали так, что check вызывает a bo rt, стандартную функцию библиотеки языка С, которая приводит к аварийному завершению работы программы, чтобы затем можно было проанализировать ее с отладчиком. В каком-нибудь другом случае можно просто продолжить выполнение.
Теперь добавьте вызовы функции check везде, где она может быть полезна:
check("flo подозрительного места"); /* ... подозрительный код... */ check("после подозрительного места");
После исправления ошибки не выбрасывайте функцию check. Оставь-1 те ее в исходном тексте, закомментируйте или запретите с помощью отладочного флага, чтобы ее можно было включить опять, если возникнет другая сложная проблема.
В более запутанных случаях функция check может проводить проверку и отображать структуры данных. Этот подход можно обобщить, используя процедуры, проводящие постоянную проверку целостности структур данных и другой информации. В программе со сложными структурами данных полезно написать такие проверки, поместив их в саму программу до того, как возникнут какие-нибудь проблемы, чтобы их можно было просто включить в случае чего. Используйте их не только для отладки; пусть они будут включ'ены на всех стадиях разработки программы. Если они не сильно влияют на производительность, будет разумно оставить их включенными навсегда. Большие программы типа систем телефонной коммутации часто отводят значительные куски кода "аудитным" подсистемам, которые регулярно анализируют информацию и оборудование, сообщают о встреченных ошибках или даже исправляют их.
Ведите журнальный файл. Другая тактика — ведение журнального файла (log file), содержащего отладочную выдачу фиксированного формата. Когда случается "падение", журнал хранит записи, показывающие, что случилось непосредственно перед этим, web-серверы и другие сетевые программы ведут обширные журналы учета трафика, чтобы собирать информацию о клиентах и о работе программы. Вот такой фрагмент журнального файла можно было встретить на одной из наших машин:
[Sun Dec 27 16:19:24 1998*] HTTPd: access to
/usr/local/httpd/cgi-bin/test.html failed for
m1.cs.bell-labs.com, reason: client denied by server (CGI non-executable) from
http://m2.cs.bell-labs.com/cgi-bin/test.pi
Убедитесь, что вы сбрасываете буферы ввода-вывода, чтобы последние сообщения остались в журнальном файле. Функции вывода типа printf обычно буферизуют выводимые данные, чтобы делать вывод более эффективным; аварийное завершение приведет к потере этих буферизованных данных. В языке С вызов функции fflush гарантирует, что все выводимые данные будут записаны до внезапного завершения программы; в C++ и Java существуют аналогичные функции для выходных потоков. Если вы хотите избежать лишней работы, используйте для журнальных файлов небуферизованный ввод-вывод. Стандартные функции setbuf и setvbuf управляют буферизацией; setbuf (fp, NULL) отключает буферизацию потока fp. Стандартные потоки сообщений об ошибке (stderr, cerr, System, err) обычно небуферизованы.
Постройте график. Иногда, при тестировании и отладке, картинки эффективнее, чем текст. Как мы увидели во второй главе, картинки особенно полезны для понимания структур данных и, конечно же, при написании программ работы с графикой, но они
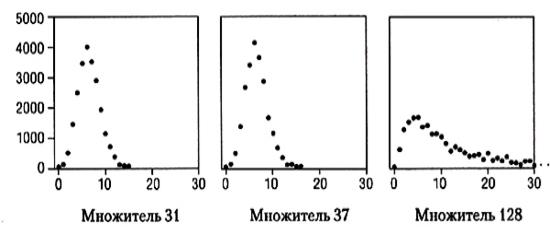
также могут использоваться для любых программ. Диаграммы разброса данных демонстрируют неверные значения гораздо лучше, чем столбцы чисел. Гистограммы отражают странные места в экзаменационных оценках, случайных числах, размерах "корзин" операторов захвата памяти и хэш-таблиц и т. п.
Если вы не понимаете, что происходит в вашей программе, попробуйте собрать статистику о структуре данных в ней и представить результаты графически. На приводимых графиках изображена статистика цепочек в программе markov из главы 3: по оси х показана длина цепочек, а по оси у — количество элементов в цепочках этой длины. Входные данные — наш стандартный текст, Псалмы (42 685 слов, 22 482 префикса). Первые два графика соответствуют хорошим мультипликаторам, 31 и 37, а третий — кошмарному мультипликатору 128. В первых двух случаях нет ни одной цепочки длиною больше 15 или 16, а большинство элементов хранится в цепочках из 5 или 6 элементов. В третьем случае область распределения много больше, самая длинная цепочка содержит 187 элементов, а в цепочках длиною больше 20 содержатся тысячи элементов.
Используйте различные инструменты. Используйте возможности среды, в которой ведете отладку. Например, программа сравнения файлов, вроде (Jiff, может сравнить результаты успешного и неуспешного запусков, чтобы вы сфокусировали внимание на том, что именно изменилось. Если отладочная выдача очень длинна, используйте g rер для поиска в ней или текстовый редактор для ее исследования. Боритесь с желанием отправить отладочную выдачу на принтер: компьютеры обрабатывают объемистые данные гораздо лучше людей. Используйте языки скриптов и другие средства для автоматизации обработки вывода при отладочных запусках.
Пишите тривиальные программки для проверки гипотез или для подтверждения того, что вы действительно понимаете, как работает та или иная возможность. Например, проверяйте, можно ли освобождать нулевой указатель, такой программой:
int main(void) / '
{
free(NULL)/ return 0;
}
Программы контроля версий исходных текстов типа RCS1 помогут понять, что изменилось, и вернуться к предыдущим версиям, выдающим проверенные результаты. Помимо указания на недавние изменения эти программы могут также