

3.7. Вероятностное моделирование порождения текста.
При исследовании механизмов порождения текста результаты отдельного лингвистического исследования не представляют большого интереса. При осуществлении массового эксперимента одно и то же испытание повторяется много раз. Лингвистические единицы выбираются из текста группами фиксированной длины: например, по 10 фонем, по 100 предложений, по 500 словоформ и т.п. Повторяющиеся испытания образуют серии, в каждом из которых интересующее нас событие появляется или не появляется определённое число раз. Например, нас интересует общее число появления слова море в определённом числе предложений (серии) составляющих текст «Евгения Онегина» или другого произведения А.С.Пушкина.
При решении многих теоретических и инженерно-лингвистических задач оказывается необходимым знать вероятность появления определённого числа интересующих исследователя лингвистических единиц в серии. Если образующие серию лингвистические испытания являются независимыми и возможны только два исхода опыта: появление или не появление признака А, то мы можем вычислить вероятность с помощью теоремы Бернулли.
Примером
этой схемы может служить повторная
выборка согласных (А) и гласных (![]() )
фонем из определённого текста. Предположим,
что в некотором тексте длиной в n
фонем
имеется m
гласных
и n-m
согласных. Требуется определить, что
среди извлечённых N
фонем ровно x
окажутся согласными, причём порядок
следования согласной и гласной фонем
безразличен.
)
фонем из определённого текста. Предположим,
что в некотором тексте длиной в n
фонем
имеется m
гласных
и n-m
согласных. Требуется определить, что
среди извлечённых N
фонем ровно x
окажутся согласными, причём порядок
следования согласной и гласной фонем
безразличен.
При составлении алгоритмов пословного машинного перевода и информационного поиска возникают задачи, связанные с прогнозированием появления в сегментах заданной длины определённого числа словоформ, морфем или словосочетаний, принадлежащих к некоторым классам. Формула Бернулли позволяет решать задачи такого типа, при условии, что сохраняется взаимная независимость образующих данный сегмент словоформ.
Пример12Средняя длина простого предложения или синтаксически оформленной части сложного предложения в английских научно-технических текстах лежит между 10 и 11 словоформами. Относительная частота появления существительных в подъязыке английской электроники близка к 1/3(априорная вероятность). Примем, что типовым синтаксически оформленным сегментом в английских научно-технических текстах является простое предложение, а также главное и придаточное предложение длиной в 10 словоформ. Считая появление отдельных словоформ в этих сегментах независимыми событиями текста, определить вероятность того, что из 10 словоупотреблений, составляющих типовой сегмент ровно 2 будут существительными.
3.8. Предельные теоремы в схеме Бернулли
Чтобы получить достаточно достоверные результаты приходится проводить большое число независимых испытаний. При этом величины n и m могут быть велики, что делает вычисление по формуле Бернулли слишком трудоёмким. В таких случаях применяют асимптотические формулы для вычисления биномиальной вероятности при n→∞.
1)
Формула Пуассона
![]() ,
где параметр
,
где параметр
![]() ,
,
применяется при больших n ( n≥100) и малых р (p≤0,1), а≤10
2) Локальная теорема Муавра-Лапласа
![]()
применяется при больших n и р≠0; р≠1.
![]() Выражение
Выражение
![]() называется функцией Гаусса, значения
которой табулированы.
называется функцией Гаусса, значения
которой табулированы.
3) Интегральная теорема Муавра-Лапласа
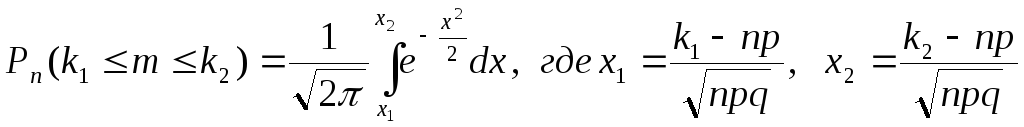
применяется
в тех случаях, когда требуется вычислить
вероятность того, что в n
независимых
испытаниях событие А появится от
![]() до
до
![]() раз
включительно, при больших n
и р≠0; р≠1.
раз
включительно, при больших n
и р≠0; р≠1.
Лекция №4.
Случайная величина.