

3.4. Вычисление вероятности цепочек языковых элементов.
В лингвистике очень редко имеют дело с независимыми событиями, т.к. вероятность появления букв, фонем, слогов, морфем и т.д. зависит от позиций этих лингвистических объектов в слове, словосочетании, предложении. Например, вероятность появления буквы п в начале слова равна 0,207, а после начального я условная вероятность её появление составляет 0,001.
Каждый текст можно представить, как совместное наступление некоторой линейной последовательности лингвистических событий – совместное появление цепочки словоформ, последовательности слогов, цепочек фонем или букв. Определение вероятности появления этих цепочек опирается на теорему умножения вероятностей.
Пример. Определите вероятность появления в русских текстах двухбуквенного сочетания «яn» в начале слова, если вероятность появления буквы я в начале слова равна 0,018, а вероятность появления буквы п после начального я составляет 0,001.
3.5. Формула полной вероятности. Формула Байеса.
1 H2) Формула полной вероятности.
П H1 A
 усть
событие А может произойти только
усть
событие А может произойти только
H3
Hn


Тогда вероятность события А находится
по формуле (формула полной вероятности):
![]()
Доказательство:
![]()
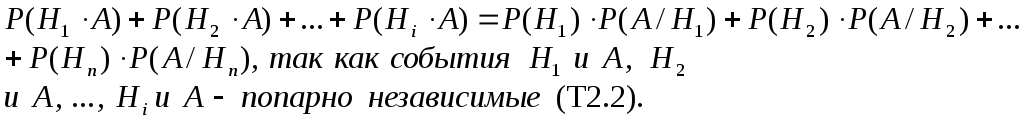
2) Формула Байеса (формула проверки гипотез).
Пусть событие А уже произошло, тогда вероятность того, что появилось событие Нi, где i=1,2,3,…n, равна:
![]() (Формула Байеса),
(Формула Байеса),
где P(A) можно найти по формуле полной вероятности.
Доказательство:
![]() Приравнивая
правые части равенств получаем
Приравнивая
правые части равенств получаем
![]()
Отсюда
имеем
![]()
Формула полной вероятности используется для вычисления общей вероятности лингвистического события при условии, что известны вероятности в узко-тематических выборках.
Формула Байеса, по которой вычисляется апостериорная вероятность лингвистических гипотез, используется в различных лингвистических исследованиях, в том числе, в теории решения задач, применяемой в инженерной лингвистике.
Пример.11 Имеется английский научно-технический текст общей длиной в 400 тыс. словоупотреблений (около тысячи стандартных страниц). По тематике этот текст распадается на следующие 4 выборки разной длины:
- радиоэлектроника – 200 тыс. словоупотреблений;
- автомобилестроение – 100 тыс. словоупотреблений;
- судовые механизмы – 50 тыс. словоупотреблений;
- строительные материалы. – 50 тыс.словоупотреблений.
Словоформа ‘are’ - множественное число настоящего времени глагола ‘to be’ ‘быть’ употреблена…
в 1-й выборке-1610 раз, во 2-й -1273, в 3-й – 469, в 4-й – 346 раз.
а) Необходимо определить вероятность того, что извлечённое наугад из данного текста словоупотребление будет словоформой ‘are’.
б) Пусть наугад извлечённая словоформа в выборке оказалась глаголом ‘are’. Найти вероятность того, что эта словоформа извлечена из текста по электронике.
3.6. Теорема Бернулли
Пусть производится n независимых одинаковых испытаний.
Событие А в каждом из испытаний может появиться с вероятностью p, и не появиться с вероятностью q=1-p.
Тогда вероятность того, что событие А появится m раз из n находится по формуле
![]() - формула Бернулли.
- формула Бернулли.