

6. Вероятность попадания нсв х в заданный промежуток
![]()
![]() или
или
(по определению и свойствам функции F(x) и f(x)).
Если
НСВ Х распределена по нормальному
закону Х~N(a;σ),
вероятность попадания Х в интервал (![]() вычисляется по формуле
вычисляется по формуле
![]()
где 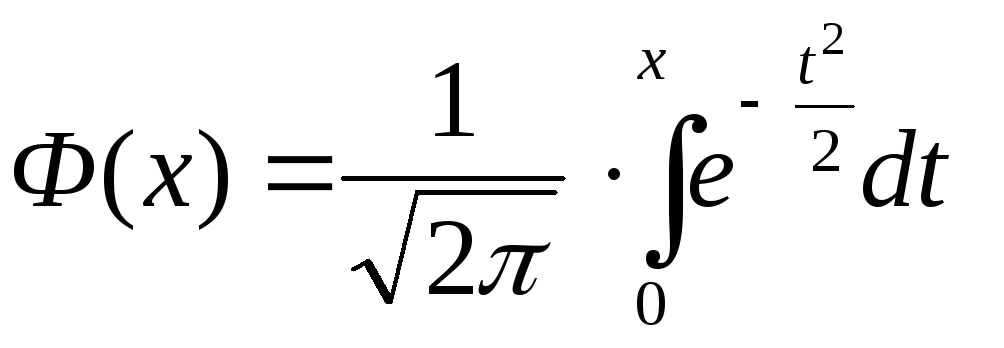 - функция Лапласа.
- функция Лапласа.
(значения функции Лапласа можно найти в таблице) .
Свойства
![]() :
:
1.
![]() -
функция
Лапласа нечётная.
-
функция
Лапласа нечётная.
2.
![]() ,
,
![]()
Пример. СВ Х распределена по нормальному закону с параметрами a=2; σ=4: Х~N(2;4).
Найти вероятность того, что СВХ попадёт в промежуток: а)(0;3),б) (4; ∞), в) (-∞;1).
7. Логнормальное распределение
Реальные распределения случайных лингвистических единиц характеризуются обычно правосторонней асимметрией, и не очень хорошо аппроксимируются нормальным законом. В связи с этим делаются попытки моделировать эти эмпирические распределения с помощью распределений Кэпптейна, Шалье, выравнивающих кривых Пирсона и Бордачёва. Такое моделирование должно опираться на лингвистическую сущность случайного явления или процесса, приводящему к определённому закону распределения.
С этой точки зрения наибольший интерес представляет логарифмически нормальное (логнормальное) распределение. Основная идея – в следующем. Значение случайной лингвистической величины Х обычно складывается из независимых внутриязыковых и экстралингвистических величин. Чаще всего эти значения являются результатом действия ряда причин. В этом случае нормально распределена не сама СВХ, а её логарифм.
Функция плотности вероятности логнормального распределения имеет вид
 ,
где
,
где
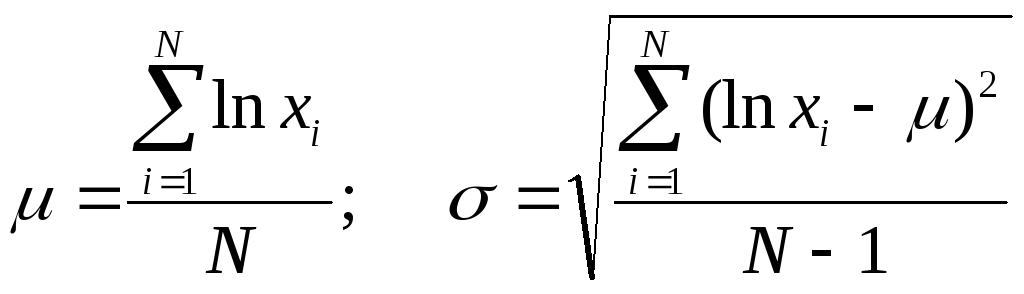 .
.
Функция плотности вероятности логнормального распределения характеризуется островершинностью, и имеет правостороннюю (положительную) скошенность.
Г. Хердан ( «Квантитативная лингвистика», Лондон, 1964г ) использует логнормальное распределение для математической экспликации вероятностного построения словаря языка и его реализации в тексте. По его мнению, логнормальность словаря и текста отражает присущий естественному языку принцип оптимального кодирования информации.
Иногда
для решения лингвистической задачи
необязательно находить вероятности
появления данного события 0,1,2,…N
раз, а достаточно указать наивероятнейшее
число появления этого события х0,
которое определяется по формуле
![]()
Лекция №5
5.1. Система двух случайных величин (двумерная св) (1 час)
5.1.1. Начальные понятия.
1) Упорядоченная пара (Х ; Y) случайных величин Х и Y называется системой двух СВ или двумерной СВ.
2) Закон распределения двумерной СВ – соответствие между значениями (Х ; Y) и их вероятностями.
3) СВ Х и Y называются независимыми, если закон распределения каждой из них не зависит от того, какое значение приняла другая.
4) Две СВ Х и Y называются функционально зависимыми, если зная значение одной из них, можно точно указать значение другой.
5) СВ Х и Y связаны стохастической зависимостью, если зная значение одной из них, можно указать закон распределения, а не точное значение другой.
Примеры: две СВ Х – «рост человека», Y – « вес этого же человека» связаны стохастической зависимостью;
СВ U – «количество существительных в отрывке текста определённой длины», V – «количество наречий в том же отрывке текста», также связаны стохастической зависимостью.