

SPD_Lektsii / СПД Лекция 2
.pdfНавчальна дисципліна |
Системи передачі даних |
Модуль 1 |
Завадостійке кодування |
Змістовий модуль № 1 |
Коректувальні коди в однобічних системах передачі даних |
Тема 1 |
Завадостійке кодування |
Лекція № 2 Завадостійкі коди
ПЛАН ЛЕКЦІЇ
Навчальні питання:
1.Принципи завадостійкого кодування.
2.Класифікація завадостійких кодів.
3.Основні характеристики коригувальних кодів.
4.Загальні відомості про Коди Хемінга.
5.Алгоритми кодування та декодування кодів Хемінга.
Навчально-матеріальне забезпечення:
1.ПЕОМ, мультимедійний проектор.
2.Презентація у форматі PowerPoint.
Навчальна література:
1.Воробієнко П.П., Нікітюк Л.А., Резніченко П.І. Телекомунікаційні та інформаційні мережі: Підруч. для ВНЗ. – К.: Саммит-книга, 2010. – С. 62–94.
2.Олифер В.Г., Олифер H.A. Компьютерные сети. Принцип, технологии, протоколы: Учебник для вузов. 4-е изд. – СПб.: «Питер», 2010. – С. 118–156.
1. Принципи завадостійкого кодування.
В реальних умовах прийом двійкових символів завжди відбувається з помилками, коли замість символу «1» приймається символ «0» і навпаки. Помилки можуть виникати через завади, що діють у каналі зв’язку (особливо завади імпульсного характеру), зміни у часі характеристик передачі каналу (наприклад, завмирання), зниження рівня передачі, нестабільності амплітудно- і фазочастотних характеристик каналу і т. ін.
Завадостійкість – здатність пристрою (системи) приймати інформацію без завад із заданим ступенем достовірності, тобто виконувати свої функції при наявності завад. Завадостійкість оцінюють інтенсивністю завад, при яких порушення функцій пристрою ще не перевищує допустимих меж. Чим сильніше завада, при якій пристрій залишається працездатним, тим вище його завадостійкість.
Завадозахищеність – здатність пристрою (системи) перешкоджати впливу завад. Загальноприйнятим критерієм оцінки якості передачі в дискретних каналах є нормована на
знак або символ припустима імовірність помилки для даного виду повідомлень. Так, припустима імовірність помилки при передачі даних не більш 10-6 (на символ). Для забезпечення таких значень імовірностей одного поліпшення тільки якісних показників каналу зв’язки може виявитися недостатнім. Тому, основною мірою є застосування спеціальних методів підвищення якості прийому переданої інформації. Ці методи можна розділити на дві групи.
До першої групи відносяться методи збільшення завадостійкості прийому одиничних елементів (символів) дискретної інформації, що пов’язані з вибором рівня сигналу, відношення сигнал-завада (енергетичні характеристики), ширини смуги каналу, методів прийому і т. ін.
До другої групи відносяться методи виявлення та виправлення помилок, що засновані на штучному введенні надмірності в передане повідомлення. Збільшити надмірність переданого
сигналу можна різними способами. Через те, що обсяг сигналу: |
|
V P F T , |
(1) |
де P – потужність сигналу [Вт]; F – ширина спектра сигналу [Гц]; T – час передачі сигналу [с], то його збільшення можливе за рахунок збільшення P , F і T .
Практичні можливості збільшення надмірності за рахунок потужності та ширини спектра сигналу в СПД зі стандартних каналів різко обмежені. Тому для підвищення якості прийому, як правило, йдуть по шляху збільшення часу передачі та використовують наступні основні способи:
1.Багаторазова передача кодових комбінацій (метод повторення);
2.Одночасна передача кодової комбінації по декількох паралельно працюючих каналах;
3.Завадостійке (коригувальне) кодування, тобто використання кодів, що виправляють
помилки.
Іноді застосовують комбінації цих способів.
Багаторазове повторення ( l раз) кодової комбінації є самим простим способом підвищення вірогідності прийому і легко реалізується, особливо в низько-швидкісних СПД для каналів зі швидко мінливими параметрами.
Способу багаторазового повторення аналогічний спосіб передачі однієї і тієї ж інформації по кількох рівнобіжних каналів зв’язку. У цьому випадку, необхідно мати не менш 3-ох каналів зв’язку (наприклад, із ЧРК), несучі частоти яких потрібно вибирати таким чином, щоб помилки в каналах були незалежні. Перевагою таких систем є надійність і малий час затримки в одержанні інформації. Основним недоліком багатоканальних систем так само, як і систем з повторенням, є нераціональне використання надмірності.
Найбільше доцільно надмірність використовується при застосуванні завадостійких (коригувальних) кодів.
При завадостійкому кодуванні найчастіше вважають, що надмірність джерела повідомлень на вході кодеру дорівнює 0 . Це обумовлено тим, що дуже багато дискретних джерел
(наприклад, цифрова інформація на виході ПК) мають малу надмірність. Якщо надмірність первинних джерел повідомлень істотна, то в цих випадках по можливості прагнуть зменшити її шляхом ефективного кодування, застосовуючи, наприклад, коди Шенона-Фано або Хафмена. Потім методами завадостійкого кодування можна внести таку надмірність у сигнал, що дозволить досить простими засобами поліпшити якість прийому. Таким чином, ефективне кодування цілком може сполучатися з завадостійким.
У звичайному рівномірному не завадостійкому коді число розрядів n у кодових комбінаціях визначається числом повідомлень і підставою коду.
Коди, в яких всі кодові комбінації дозволені до передачі, називаються простими або однаково доступними та є цілком безнадлишковими. Безнадлишкові первинні коди мають великою «чутливість» до завад.
Внесення надмірності при використанні завадостійких кодів обов’язково пов’язано зі збільшенням n – числа розрядів (довжини) кодової комбінації. Таким чином, всю множину
N 2n комбінацій можна розбити на дві підмножини: підмножина дозволених комбінацій, тобто мають визначені ознаки, та підмножина заборонених комбінацій, цими ознаками не володіють.
Завадостійкий код відрізняється від звичайного тем, що в канал передаються не всі кодові комбінації N, які можна сформувати з наявного числа розрядів n , а тільки їхня частина NK , що
складає підмножину дозволених комбінацій.
Якщо при прийомі з’ясовується, що кодова комбінація належить до заборонених, то це свідчить про наявність помилок у комбінації, тобто в такий спосіб вирішується задача виявлення помилок. При цьому, прийнята комбінація не декодується (не приймається рішення про передане повідомлення). У зв’язку з цим завадостійкі коди називають кориктувальними кодами. Коригувальні властивості надлишкових кодів залежать від правила їхньої побудови, що визначає структуру коду, і параметрів коду (тривалості символів, числа розрядів, надмірності і т. ін.).
Перші роботи по коригувальних кодах належать Хемінгу, що ввів поняття мінімальної кодової відстані dmin і запропонував код, що дозволяє однозначно вказати ту позицію в кодовій
комбінації, де відбулася помилка. До « k » інформаційних елементів у коді Хемінга додається « r » перевірочних елементів для автоматичного визначення місця розташування помилкового символу.
2. Класифікація завадостійких кодів.
Як правило, повідомлення, що видаються джерелом, призначені для безпосереднього сприйняття органами почуттів людини і, звичайно, не пристосовані для їх передавання каналами
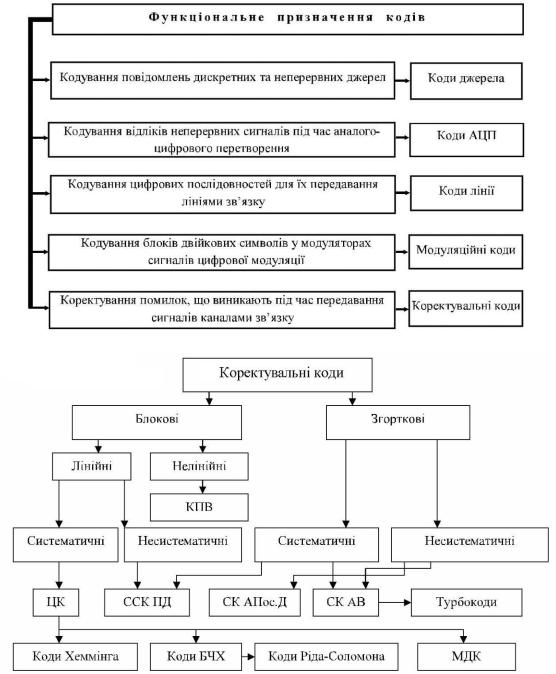
зв’язку. Тому вони в процесі передавання, як правило, піддаються кодуванню і, як правило, неодноразово. Необхідність кодування виникає насамперед із потреби пристосувати форму повідомлення до даного каналу зв’язку або пристрою, призначеному для перетворення або збереження інформації. Однак, після кодування кодером джерела в систему вмикається ще і кодер каналу. Це пов’язано насамперед з тим, що в сучасних телекомунікаційних системах повідомлення передаються цифровими сигналами та обробляються цифровими методами. У телекомунікаційних системах коди мають різне функціональне призначення, їх класифікація надана на рис. 1.
Рис. 1. Спрощена класифікація кодів
Рис. 2. Класифікація основних завадостійких кодів
На сьогодні відома значна кількість коректувальних кодів, які використовуються в системах цифрового зв’язку, і тому їхня систематизація і класифікація дуже ускладнена. У зв’язку з цим, при побудові класифікаційної діаграми (рис. 2) розглядаються тільки ті коди, які знаходять застосування у СПД.
Двійкові коректувальні коди можна поділити на два великих класи: блокові та згорткові. До блокових відносяться такі коди, в яких кодування та декодування здійснюються в межах блока, що складається з визначеного числа кодових символів. У літературі з завадостійкого кодування блоки
кодових символів називають по-різному: кодовими словами, кодовими комбінаціями та кодовими векторами.
Блокові коди розподіляються на рівномірні та нерівномірні. У рівномірних кодах, на відміну від нерівномірних, всі кодові комбінації містять однакове число n – символів (розрядів) з постійною тривалістю 0 імпульсів символів коду. Рівномірні коди в основному і застосовуються
в системах зв’язку, тому що це спрощує техніку передачі та прийому. Класичними прикладами нерівномірного коду є код Морзе, широко застосовуваний у радіозв’язку, і код Хафмена, застосовуваний для компресії інформації (факсимільний зв’язок, ПК). Ніяких спеціальних заходів для виправлення та виявлення помилок у коді Морзе не передбачається в зв’язку з великою надмірністю самого переданого тексту. У цьому змісті код Морзе не відноситься до класу коригувальних кодів.
До згорткових кодів, що називалися раніше безперервними, рекурентними або ланцюговими, відносяться такі коди, в яких процес кодування має безперервний характер без виділення меж при формуванні послідовності кодових символів. Важливою відмінністю згорткового кодування є те, що кодові символи на виході кодера залежать не тільки від інформаційних символів, що надійшли на даний момент часу, але й від попередніх символів на його вході. У найпростішому ланцюговому коді кожен перевірочний елемент формується шляхом додавання по модулю 2 сусідніх або віддалених один від одного на визначене число позицій інформаційних елементів. До каналу зв’язку передається послідовність імпульсів, у якій за кожним інформаційним надходить перевірочний. Подібну послідовність розрядів, що чергується, має, наприклад, кореляційний манчестерський код.
Блокові коди, в свою чергу, розподіляються на лінійні та нелінійні. До лінійних відносяться такі коди, в яких формування блоків, тобто кодування здійснюється з використанням лінійних операцій (підсумовування та множення над інформаційними символами з урахуванням арифметики за модулем 2). В іншому випадку, коректувальні коди відносяться до нелінійних, тому що сума двох кодових комбінацій (КК) з заданими властивостями не утворює комбінацію, що належить до даного коду. Найпростішим прикладом нелінійного коду є міжнародний 7- елементний код МТА-3, який ще називають кодом з постійною вагою (КПВ), в кожній кодовій комбінації якого міститься 3 одиниці та 4-ри нуля.
В свою чергу, лінійні коди розподіляються на систематичні та несистематичні. В систематичних кодах інформаційні символи на виході кодера формуються в кінці кодового слова. Належність до систематичних або несистематичних кодів визначається вибором коду та алгоритму кодування. Значну частину лінійних кодів займають циклічні коди (ЦК), які знаходять застосування у цифрових системах передачі (ЦСП) різного роду повідомлень. До них відноситься досить велике число коректувальних кодів, серед яких найбільш відомими є:
-коди Хемінга, що виправляють однократні та виявляють 2-кратні помилки;
-коди БЧХ, що володіють високою коректувальною здатністю, які запропоновані Боузом, Чоудхурі та Хоквінгемом;
-коди Ріда-Соломона, що являють собою важливий підклас кодів БЧХ з коефіцієнтами кінцевих полів Галуа, які знайшли застосування у системах космічного зв’язку;
-мажоритарно-декодовані коди (МДК), що виправляють багаторазові помилки, яким властиві прості алгоритми декодування.
Іншим прикладом несистематичного коду є код з контрольним підсумовуванням – ітеративний код. У цьому коді перевірочні розряди формуються в результаті підсумовування значень розрядів як у даній кодовій комбінації, так і однойменних розрядів у ряді сусідніх з нею комбінацій, що утворять спільний блок. Ітеративні коди дозволяють одержати так називані потужні коди, тобто коди з довгими блоками та великою кодовою відстанню при порівняно простій процедурі декодування. Ітеративні коди можуть будуватися як комбінаційні за допомогою добутку двох чи більш систематичних кодів. До комбінаційних кодів можна віднести також антіфедингові коди, що призначені для виявлення та виправлення помилок у каналах із завмираннями (федінгом) сигналів. Для таких каналів із групуванням помилок застосовують метод перемежування символів або декореляції помилок. Він полягає в тому, що символи, які входять в
одну кодову комбінацію, передаються не безпосередньо один за одним, а перемежовуються символами інших кодових комбінацій вихідного систематичного чи будь-якого іншого коду. Якщо інтервал між символами, що входять в одну кодову комбінацію, зробити довши «пам’яті» (інтервалу кореляції) каналу з завмираннями, то в межах тривалості однієї вихідної кодової комбінації групування помилок не буде. На прийомі після зворотної «розфасовки» у кодових комбінаціях можна робити декодування з виявленням і виправленням помилок.
Згорткові коди (ЗК), вперше запропоновані Елайесом, як і блокові, також розподіляються на систематичні та несистематичні. Перші, до яких відносяться самоортогональні згорткові коди (ССК), декодуються надто простим пороговим методом, а інші – з використанням алгоритму послідовного декодування (СК АПос. Д), запропоновані Дж. Возенкрафтом.
Заслуговує на згадку внесок, зроблений російськими вченими з питань завадостійкості кодування Зяблова В.В. і Золотарьова В.В., а саме в області каскадного кодування і багатопорогового декодування самоортогональних ЗК.
Широко використовуваний на даний час алгоритм Вітербі може застосовуватись як до несистематичних, так і до систематичних кодів (СК АВ). На основі алгоритму Вітербі розроблені і впроваджені турбокоди К. Берроу.
Проблема завадостійкого кодування являє собою велику область теоретичних і прикладних досліджень. Основними задачами при цьому є наступні: пошук кодів, що ефективно виправляють помилки необхідного виду; методів кодування та декодування і прості способи їхньої реалізації. Найбільш розроблені ці задачі стосовно до систематичних кодів. Такі коди успішно застосовуються в обчислювальній техніці, різних автоматизованих цифрових пристроях і цифрових системах передачі інформації.
3. Основні характеристики коригувальних кодів.
На даний час, найбільша увага з погляду технічних додатків приділяється двійковим блоковим коригувальним кодам. При використанні блокових кодів цифрова інформація передається у вигляді окремих кодових комбінацій (блоків) рівної довжини. Кодування та декодування кожного блоку здійснюється незалежно один від одного.
Майже всі блокові коди відносяться до роздільних кодів, кодові комбінації яких складаються з двох частин: інформаційної та перевірочної. При загальному числі n символів у блоці число інформаційних символів дорівнює k , а число перевірочних символів:
r n k . |
(2) |
До основних характеристик коригувальних кодів відносяться:
число дозволених і заборонених кодових комбінацій;
надмірність коду;
мінімальна кодова відстань;
число помилок, що виявляються або виправляються;
коригувальні можливості кодів.
Число дозволених і заборонених кодових комбінацій. Для блокових двійкових кодів, з числом символів у блоках рівним n , загальне число можливих кодових комбінацій визначається значенням:
N |
0 |
2n . |
(3) |
|
|
|
|
|
|
Число дозволених кодових комбінацій при наявності до інформаційних розрядів у |
||||
первинному коді дорівнює: |
|
|
|
|
N |
k |
2k . |
(4) |
|
|
|
|
|
|
Очевидно, що число заборонених комбінацій дорівнює:
N |
з |
N |
0 |
N |
k |
2n 2k , |
(5) |
|
|
|
|
|
а з врахуванням (2) відношення має вигляд:
N |
0 |
/ N |
k |
2n / 2k 2n k 2r |
, |
(6) |
|
|
|
|
|
де r – число надлишкових (перевірочних) розрядів у блоковому коді.
Надмірність коректувального коду. Надмірністю коригувального коду називають величину:
|
r |
|
n k |
1 |
k |
|
, |
(7) |
|||
|
|
|
|||||||||
|
n |
|
n |
|
|
|
|
n |
|
|
|
відкіля випливає: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bk |
|
k |
. |
|
(8) |
|||
|
|
|
n |
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
Ця величина показує, яку частину загального числа символів кодової комбінації складають інформаційні символи. У теорії кодування величину Bk називають відносною швидкістю коду.
Якщо продуктивність джерела інформації дорівнює Н символів за 1 с., то швидкість передачі після кодування цієї інформації виявиться рівною оскільки в закодованій послідовності з кожних n символів тільки до символів є інформаційними:
B H |
k |
. |
(9) |
|
|||
|
n |
|
|
Якщо число помилок, які потрібно знайти або виправити, великі, то необхідно мати код з великим числом перевірочних символів. Щоб при цьому швидкість передачі залишалася досить високою, необхідно в кожному кодовому блоці одночасно збільшувати як загальне число символів, так і число інформаційних символів. При цьому тривалість кодових блоків буде істотно зростати, що призведе до затримки інформації при передачі та прийомі. Чим складніше кодування, тим довша часова затримка інформації.
Мінімальна кодова відстань ( dmin ). Для того, щоб можна було знайти та виправити
помилки, дозволена комбінація повинна як найбільше відрізнятися від забороненої. Якщо помилки в каналі зв’язку діють незалежно, то імовірність перетворення однієї кодової комбінації в іншу буде тим менше, чим на більшу кількість символів вони розрізняються. Якщо інтерпретувати кодові комбінації як точки в просторі, то відмінність виражається в близькості цих точок, тобто у відстані між ними.
Кількість розрядів (символів), якими відрізняються дві кодові комбінації, можна прийняти за кодову відстань між ними. Для визначення цієї відстані потрібно скласти дві кодові комбінації по
модулю |
2 і підрахувати число одиниць в отриманій сумі. Наприклад, |
дві кодові комбінації |
||||
xi 01011 і x j 10010 мають відстань d (xi , x j ) 3 тому, що: |
|
|
||||
|
|
xi 01011 |
|
W 3 |
|
|
|
|
|
|
|
|
|
|
|
x j 10010 |
|
W 2 |
. |
(10) |
|
|
xi x j 11001 |
|
d (xi , x j ) |
||
|
|
|
|
|||
(Тут під операцією « » розуміється додавання по mod2). Помітимо, що кодова відстань |
||||||
d (xi , x j ) |
між комбінацією xi і нульовою x0 00...0 |
= 00..0 називають вагою W комбінації xi , |
||||
тобто вага xi дорівнює числу «1» у ній.
Відстань між різними комбінаціями деякого конкретного коду можуть істотно відрізнятися. Так, зокрема, у безнадлишковому первинному натуральному коді ( n k ) ця відстань для різних комбінацій може змінюватися від одиниці до величини n , рівної значності коду. Особливу важливість для характеристики коригувальних властивостей коду має мінімальна кодова відстань dmin , що обумовлена при попарному порівнянні всіх кодових комбінацій, яку називають
відстанню Хемінга.
У безнадлишковому коді всі комбінації є дозволеними, і, отже, його мінімальна кодова відстань дорівнює одиниці dmin 1. Тому досить спотворитися одному символу, щоб замість
переданої комбінації була прийнята інша дозволена комбінація. Щоб код мав коригувальні властивості, необхідно ввести в нього деяку надмірність, що забезпечувала б мінімальну відстань між будь-якими двома дозволеними комбінаціями не менш двох – dmin 2 .
Мінімальна кодова відстань є найважливішою характеристикою завадостійких кодів, що вказує на гарантоване число помилок, що виявляються або виправляються заданим кодом.
Число помилок, що виявляються або виправляються. При застосуванні двійкових кодів враховують тільки дискретні спотворення, при яких одиниця переходить у нуль (1→0) або нуль переходить в одиницю (0→1). Перехід 1→0 або 0→1 тільки в одному елементі кодової комбінації називають одиничною помилкою (одиничним спотворенням). У загальному випадку під кратністю помилки мають на увазі число позицій кодової комбінації, на яких під дією завади одні символи виявилися заміненими на інші. Можливі 2-кратні ( g 2 ) і багаторазові ( g 2 )
спотворення елементів у кодовій комбінації в межах 0 g n .
Мінімальна кодова відстань є основним параметром, що характеризує коригувальні здібності
даного коду. Якщо код використовується тільки для виявлення помилок кратністю |
g0 , то |
|
необхідно і досить, щоб мінімальна кодова відстань дорівнювала: |
|
|
dmin g0 1 . |
(11) |
|
У цьому випадку ніяка комбінація з g0 |
помилок не може перевести одну дозволену кодову |
|
комбінацію в іншу дозволену. Таким чином, |
умова виявлення всіх помилок кратністю g0 |
можна |
записати у вигляді: |
|
|
|
g0 dmin 1 . |
(12) |
Щоб можна було виправити всі помилки кратністю gu і менш, необхідно мати мінімальну |
||
відстань, що задовольняє умові: |
|
|
dmin 2gu 1 . |
(13) |
|
У цьому випадку, будь-яка кодова комбінація з числом помилок gu відрізняється від кожної дозволеної комбінації не менш чим у gu 1 позиціях. Якщо умова (13) не виконана, можливий випадок, коли помилки кратності gu спотворять передану комбінацію так, що вона стане ближче до однієї з дозволених комбінацій, чим до переданого або навіть перейде в іншу дозволену
комбінацію. Відповідно до цього, |
умова виправлення всіх помилок кратністю не більш gu |
можна |
записати у вигляді: |
|
|
|
gu (dmin 1) / 2 . |
(14) |
З (11) і (13) випливає, що якщо код виправляє всі помилки кратністю gu , то число помилок, |
||
що він може знайти, дорівнює |
g0 2gu . Слід зазначити, що співвідношення (11) |
і (13) |
установлюють лише гарантоване мінімальне число помилок, що виявляються або виправляються, при dmin заданому і не обмежують можливість виявлення помилок більшої кратності. Наприклад, найпростіший код з перевіркою на парність з dmin 2 дозволяє виявляти не тільки одиночні помилки, але і будь-яке непарне число помилок у межах g0 n .
Коректувальні можливості кодів. Питання про мінімально необхідну надмірність, при якій код володіє потрібними коригувальними властивостями, є одним з найважливіших у теорії кодування. Це питання дотепер не одержало повного рішення. На даний час, отриманий лише ряд верхніх і нижніх оцінок (границь), що встановлюють зв’язок між максимально можливою
мінімальною відстанню коригувального коду та його надмірністю. |
|
|||||
Так, границя |
Плоткіна дає верхню границю кодової відстані dmin |
при заданому числі |
||||
розрядів n у кодовій комбінації та числі інформаційних розрядів k , і для двійкових кодів: |
||||||
dmin |
n 2k 1 |
(15) |
або |
r 2 (dmin 1) log2 dmin |
(16) |
|
|
|
при n 2 (dmin 1) . |
|
|||
2k 1 |
|
|||||
|
|
|
|
|||
Верхня границя Хемінга встановлює максимально можливе число дозволених кодових комбінацій ( 2k ) будь-якого завадостійкого коду при заданих значеннях n і dmin :
2k |
|
|
|
|
2n |
|
, |
|
|
|
dmin 1 |
|
|||||
|
|
|
|
|
|
|
||
|
|
|
2 |
Cni |
||||
|
|
|
|
|
|
|||
|
|
|
|
|
i 0 |
|
|
|
де Cni – число сполучень з n елементів по i |
елементах. |
|
|
|||||
Звідси, можна одержати вираз для оцінки числа перевірочних символів: |
||||||||
|
dmin 1 |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|||||
r log2 |
|
|
. |
|||||
Cni |
||||||||
|
|
i 0 |
|
|||||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
(17)
(18)
Для значень dmin / n 0,3 різниця між границею Хемінга та границею Плоткіна порівняно
невелика.
Границя Варшамова-Гільберта для великих значень n визначає нижню границю для числа перевірочних розрядів, необхідного для забезпечення заданої кодової відстані:
|
|
|
d 2 |
i |
|
|
|
|
|
r |
|
|
|
(19) |
|
|
|
|
|
||||
|
|
log2 |
Cn1 . |
|
|||
|
|
|
i 0 |
|
|
|
|
Відзначимо, що для деяких окремих випадків Хемінг одержав прості співвідношення, що |
|||||||
дозволяють визначити необхідне число перевірочних символів: |
|
||||||
r |
log2 |
n 1 для dmin 3 , r |
log2 |
2n для dmin |
4 . |
||
Блокові коди з dmin 3 і 4 у літературі звичайно називають кодами Хемінга. Всі приведені вище оцінки дають представлення про верхню границю числа dmin при фіксованих значеннях n і k або оцінку знизу числа перевірочних символів r при заданих k і dmin .
Існуючі методи побудови надлишкових кодів вирішують в основному задачу пошуку такого алгоритму кодування та декодування, що дозволяв би найбільше просто побудувати та реалізувати код із заданим значенням dmin . Тому, різні коригувальні коди при однакових dmin порівнюються
по складності пристроїв, що кодують і декодують. Цей критерій є в деяких випадках визначальним при виборі того чи іншого коду.
4. Загальні відомості про коди Хемінга.
В середині 1940-х років Ричард Хемінг працював у компанії Bell Labs на обчислювальній машині Bell Model V. Це була електромеханічна машина, що використовує релейні блоки, швидкість яких була дуже низка: один оборот за кілька секунд. Дані вводилися в машину за допомогою перфокарт, і тому в процесі считування часто відбувалися помилки. У робочі дні використовувалися спеціальні коди, щоб виявляти та виправляти знайдені помилки, при цьому оператор дізнавався про помилку по світінню лампочок, виправляв і знову запускав машину. У вихідні дні, коли не було операторів, при виникненні помилки машина автоматично виходила з програми та запускала іншу.
Хемінг часто працював у вихідні дні та часто був повинний перезавантажувати свою програму через ненадійність перфокарт. Протягом кількох років він проводив багато часу над побудовою ефективних алгоритмів виправлення помилок. У 1950 році він опублікував спосіб, що на сьогоднішній день відомий як код Хемінга.
Завадостійкість – здатність пристрою (системи) приймати інформацію без завад із заданим ступенем вірогідності, тобто виконувати свої функції при наявності завад. Завадостійкість оцінюють інтенсивністю завад, при яких порушення функцій пристрою ще не перевищує припустимих меж. Чим сильніше завада, при якій пристрій залишається працездатним, тим вище його завадостійкість.
Завадозахищеність – здатність пристрою (системи) перешкоджати впливу завад.

По завадостійкості та завадозахищеності коди розділяють на: незавадостійкі, завадостійкі, коди з виявленням помилок і корегувальні коди. Завадозахищені це коди при який можна правильно виділити повідомлення (завадостійкість + скритність передачі).
Систематичні коди утворять велику групу з блокових, роздільних кодів (у який усі символи можна розділити на перевірочні та інформаційні). Особливістю систематичних кодів є те, що перевірочні символи утворяться в результаті лінійних операцій над інформаційними символами. Крім того, будь-яка дозволена кодова комбінація може бути отримана в результаті лінійних операцій над набором лінійно незалежних кодових комбінацій.
Коди Хемінга є кодами, що самоконтролюються, тобто кодами, що дозволяють автоматично виявляти помилки при передачі даних. Для їхньої побудови досить приписати до кожного слова один додатковий (контрольний) двійковий розряд і вибрати цифру цього розряду так, щоб загальна кількість одиниць у зображенні будь-якого числа було, наприклад, парним. Одиночна помилка в якому-небудь розряді переданого слова (у тому числі, може бути, і в контрольному розряді) змінить парність загальної кількості одиниць. Лічильники по модулю 2, що підраховують кількість одиниць, що містяться серед двійкових цифр числа, можуть давати сигнал про наявність помилок.
При цьому неможливо довідатися, у якому саме розряді відбулася помилка, і, отже, немає можливості виправити її. Залишаються непоміченими також помилки, що виникають одночасно в двох, 4-ох, і т. ін. – у парній кількості розрядів. Утім, подвійні, а тим більше 4-кратні помилки покладаються малоймовірними.
Як відомо, додавання по модулю 2 (логічне додавання, XOR, поразрядне доповнення, побітовий комплемент) – булева функція, а також логічна і бітова операція (умовна позначка: ). У випадку 2 перемінних результат виконання операції є істинним тоді і тільки тоді, коли лише один з аргументів є істинним (табл. 2 і 3). Для функції 3-ох і більш перемінних результат виконання операції буде щирим тільки тоді, коли кількість аргументів рівних 1, що складають поточний набір – непарне. Така операція природним образом виникає в кільці відрахувань по модулю 2, відкіля і виходить назва операції. Деякі властивості додавання по модулю 2 мають вигляд:
a 0 a , a a 0 , a b b a , a 1 a , a b b a , a b b a , a b b a . (1)
Таблиця 1 Для бінарного додавання по модулю 2
X |
Y |
X Y |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
Таблиця 2 Для тернарного додавання по модулю 2
X |
Y |
Z |
(X,Y,Z) |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
Побудова кодів Хемінга базується на принципі перевірки на парність ваги W (числа одиничних символів) в інформаційній групі кодового блоку: до послідовності додається такий
елемент, |
щоб |
число |
одиничних |
символів у |
послідовності, |
що вийшла, |
було парним |
||
r1 i1 i2 |
ik . Для S i1 i2 |
in r1 : |
S 0 – |
помилки нема, |
S 1 |
– однократна |
|||
помилка. |
Такий |
код |
називається |
k 1, k або |
n, n 1 . |
Перше |
число – |
кількість елементів |
|
послідовності, друге – кількість інформаційних символів. Для кожного числа перевірочних символів r 3,4,5, існує класичний код Хемінга з маркіруванням:
n, k 2r 1, 2r 1 r , |
(1) |
тобто – (7,4), (15,11), (31,26). При інших значеннях k виходить так званий усічених код, наприклад міжнародний телеграфний код МТК-2, у якого k 5 . Для нього необхідний код Хемінга (9,5), що є усіченим від класичного (15,11).
Пояснимо ідею перевірки на парність на прикладі найпростішого коригувального коду, що так і називається кодом з перевіркою на парність або кодом з перевіркою за паритетом (рівністю). У такому коді до кодових комбінацій безнадлишкового первинного двійкового k – розрядного коду додається один додатковий розряд (символ перевірки на парність, так званий перевірочним, чи контрольним). Очевидно, що додавання додаткового розряду збільшує загальне число можливих комбінацій вдвічі в порівнянні з числом комбінацій вихідного первинного коду, а умова парності розділяє всі комбінації на дозволені та недозволені. Якщо число символів «1» вихідної кодової комбінації парне, то в додатковому розряді формують контрольний символ «0», а якщо число символів «1» непарне, то в додатковому розряді формують символ «1». В результаті загальне число символів «1» у будь-якій переданій кодовій комбінації завжди буде парним. Код з перевіркою на парність дозволяє виявляти одиночну помилку при прийомі кодової комбінації, тому що така помилка порушує умову парності, переводячи дозволену комбінацію в заборонену. Критерієм правильності прийнятої комбінації є рівність нулю результату S підсумовування по mod 2 усіх n символів коду, включаючи перевірочний символ ri. При наявності одиночної помилки S приймає значення 1. Для прикладу розглянемо класичний код Хемінга (7,4). Згрупуємо перевірочні символи наступним способом:
r1 i1 i2 i3 , r2 i2 i3 i4 , r3 i1 i2 i4 .
Одержання кодового слова має вигляд:
|
|
|
1 |
0 |
0 |
0 |
1 |
0 |
1 |
|
|
|||
|
|
|
|
0 |
1 |
0 |
0 |
1 |
1 |
1 |
|
|
|
|
i1 i2 i3 |
i4 |
|
|
|
i1 |
i2 |
||||||||
|
0 |
0 |
1 |
0 |
1 |
1 |
0 |
|
||||||
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
0 |
0 |
1 |
0 |
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
||||||||
На вхід декодера |
надходить |
кодове |
слово |
|
V i |
i |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
|
позначені символи, що можуть спотворитися в результаті виправлення помилок будується послідовність синдромів:
S1 r1 i1 i2 i3 , |
|
S2 r2 i2 i3 i4 , |
|
S3 r3 i1 i2 i4 . |
|
3-символьна послідовність S S1, S2 , S3 |
називається |
i3 |
i4 |
r1 |
r2 |
|
r3 . |
|
i |
i |
r |
r |
|
r , де |
штрихом |
3 |
4 |
1 |
2 |
3 |
|
|
завади. У |
декодері, |
в режимі |
||||
синдромом. Термін «синдром»
використовується у медицині, де він позначає сполучення ознак, характерних для визначеного захворювання. У даному випадку, синдром S S1, S2 , S3 являє собою сполучення результатів
перевірки на парність відповідних символів кодової групи та характеризує визначену конфігурацію помилок (шумовий вектор). Одержання синдрому описується виразом:
|
|
|
1 |
0 |
1 |
|
|
|
|
|
|
|
|
1 |
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
1 |
1 |
0 |
|
|
|
i1 i2 i3 i4 |
|
|
|
|
|
|
|
S1 S2 |
S3 |
r1 r2 |
r3 |
0 1 |
1 |
||||||
|
|
|
|
1 |
0 |
0 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
0 |
1 |
0 |
|
|
|
|
|
|
|
0 |
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|||