

5.2 Стохастичне моделювання і методи стохастичного аналізу
Стохастичне моделювання є доповненням і поглибленням детермінованого факторного аналізу. У факторному аналізі стохастичні моделі використовуються з трьох основних причин:
необхідно вивчити вплив факторів, за якими не можна побудувати жорстко детерміновану факторну модель;
потрібно вивчити вплив факторів, що не піддаються об’єднанню в одній жорстко детермінованій моделі;
слід вивчити вплив складних факторів, що не можуть бути виражені одним кількісним показником (наприклад, рівень науково-технічного прогресу).
На відміну від жорстко детермінованого стохастичний підхід для реалізації вимагає низку передумов:
а) наявність сукупності;
б) достатній обсяг спостережень;
в) випадковість і незалежність спостережень;
г) однорідність;
д) наявність розподілу ознак, близького до нормального;
е) наявність спеціального математичного апарату.
В економічних дослідженнях нерідко доводиться працювати в умовах малих вибірок (до 20 спостережень). У цьому випадкові як об’єкт аналізу використовують усю наявну сукупність і розглядають її як вибірку з гіпотетичної сукупності, яка складається з усіх можливих значень показників, що моделюються. Оскільки стохастична модель – це, як правило, рівняння регресії, вважається, що кількість спостережень повинна як мінімум у 6-8 разів перевищувати кількість факторів.
Якісна однорідність вибірки досягається шляхом логічного добору; критерієм кількісної однорідності може служити, зокрема, коефіцієнт варіації – його значення не повинно перевищувати 33%. Коефіцієнт варіації являє собою процентне відношення середньоквадратичного відхилення до середнього значення ознаки і визначається за формулами:
для результативної ознаки Y
V=![]() , (1)
, (1)
де
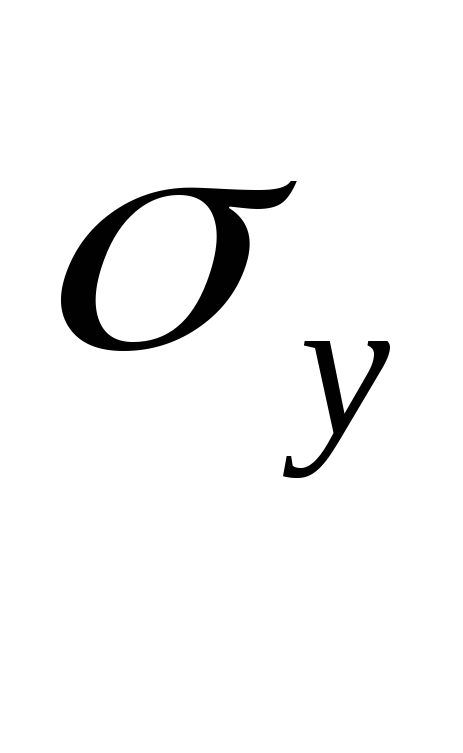 – середньоквадратичне відхилення, що
обчислюється за формулою
– середньоквадратичне відхилення, що
обчислюється за формулою
 , (2)
, (2)
де n – кількість спостережень;
аналогічно для факторних ознак Хі
V=![]() , (3)
, (3)
де Хі – середньоквадратичне відхилення, що визначається за формулою
![]() . (4)
. (4)
Побудова стохастичної моделі проводиться в декілька етапів:
якісний аналіз (постановка мети аналізу, визначення сукупності, результативних і факторних ознак, вибір періоду, за який проводиться аналіз, вибір методу аналізу);
попередній аналіз сукупності, що моделюється (перевірка однорідності сукупності, виключення аномальних спостережень, уточнення необхідного обсягу вибірки, встановлення законів розподілу досліджуваних показників);
побудова стохастичної (регресійної) моделі (уточнення переліку факторів, розрахунок оцінок параметрів рівнянь регресії, вибір конкуруючих варіантів моделей);
оцінювання адекватності моделі (перевірка статистичної істотності (суттєвості) рівняння в цілому та його окремих параметрів, перевірка відповідності формальних властивостей оцінок завданням дослідження);
економічна інтерпретація і практичне використання моделі (визначення просторово-часової стійкості побудованої залежності, оцінка практичних властивостей моделі).
Вихідні дані для побудови моделей. Для аналізу щільності зв’язку між результативним і факторними ознаками в наукових дослідженнях найбільш широко застосовують статистичні методи: кореляційний та регресійний аналіз, рангову кореляцію, головні компоненти й ін.
Використанню цих методів передує перевірка якості інформації, для чого необхідне первинне оброблення вихідних даних, що виконується в такому порядку: статистичне групування даних, дослідження розглянутої статистичної сукупності на однорідність, виключення з отриманих показників аномальних (нехарактерних) значень досліджуваних ознак і перевірка достатньої кількості спостережень.
Для перевірки однорідності вихідної інформації рекомендується використовувати метод перевірки гіпотези про нормальний розподіл ознаки в статистичній сукупності. З’ясування відповідності розподілу ознаки нормальному закону виконується з метою виключення з вибірки значень, що виходять за рамки нормального розподілу; перетворення вихідних даних за допомогою спеціальних функцій (зворотної, логарифмічної й ін.). Після цього дані знову перевіряються на однорідність. При негативних результатах такої перевірки необхідно збільшити кількість спостережень. Якщо й у цьому випадкові інформація неоднорідна, її варто розбити на однорідні класи.
Для вилучення з вихідної інформації аномальних спостережень необхідно виключити ті значення результативного і факторних ознак, розмір яких лежить за межами інтервалу
/Xi/,
/Yi/![]() . (5)
. (5)
У сукупності, що залишилася, середні значення та дисперсії ознак підлягають перерахуванню.
Необхідна кількість спостережень визначається за формулою
n=![]() , (6)
, (6)
де
![]() –
середньоквадратичне відхилення
результативної ознаки;
–
середньоквадратичне відхилення
результативної ознаки;
t – нормоване відхилення, що відповідає гарантійній імовірності й визначається з таблиць інтегральної функції Лапласа;
![]() –граничне
відхилення вибіркової середньої від
генеральної середньої (гранична помилка
вибірки).
–граничне
відхилення вибіркової середньої від
генеральної середньої (гранична помилка
вибірки).
У практичних розрахунках рекомендується використовувати розмір граничної помилки вибірки, що дорівнює 3-5% вибіркової середньої; при гарантійній імовірності 95% нормоване відхилення становить 1,96.
Якщо виявилося, що для вибірки на основі попередніх відомостей відхилення вибіркової середньої від генеральної перевищує допустимий розмір при встановленому рівні гарантійної ймовірності, то обсяг вибірки необхідно збільшити, тобто додатково зібрати статистичні дані.