

Нейросетевые технологии / АСУ Скобцов Искусственные нейронные сети лекции
.pdf11
кодируется двоичным 12-разрядным вектором X=(x1,…,x12). Каждый i-й
разряд соответствует своей клетке и xi=1 в том случае, если изображение данной буквы хотя бы частично “закрашивает” эту клетку. Например, буква
„А‟ кодируется входным вектором (010010111101)
Рис.7 Персептрон для распознавания букв
К сожалению однослойные НС способны работать только с линейно разделимыми классами и не могут решать другие задачи, например, проблему исключающего ИЛИ, что вызвало в свое время массу критических работ
(прежде всего Минского) и замедлило развитие теории НС. Для устранения этих недостатков были предложены многослойные НС прямого распространения.
1.3.2 Многослойные сети
Переход к многослойным сетям обеспечивает решение более сложных задач. Доказано, что двухслойная нейронная сеть, в первом слое которой нейроны имеют сигмоидную активационную функцию (рис.3в), а во втором линейную активационную функцию, может апроксимировать с заданной точностью любую функцию многих переменных и соответственно построить любую разделяющую поверхность [2-3]. Таким образом многослойная НС прямого распространения является универсальным апроксиматором, что фактически и обуславливает ее широкое применение. К сожалению этот
12
результат относится к классу теорем существования, которые не дают конструктивного метода синтеза и обучения НС. Отсутствие формально обоснованного метода обучения для многослойных НС долгое время сдерживало развитие теории НС и их практическое применение. Наконец в
1986 г. был открыт (фактически переоткрыт) метод обучения многослойных НС, получивший название “метод обратного распространения ошибки” (back propagation errror), после чего начался новый период интенсивной работы в области теории и практики НС.
Нейросети отличаются от классических вычислительных систем (в
том числе и параллельных) тем, что для решения задач в них используются не заранее разработанные алгоритмы, а специально подобранные примеры – обучающие выборки, на которых они учатся. Для этого применяются различные методы обучения, которые наряду с самими НС являются важнейшей компонентой. Естественно для различных типов НС используются разные методы обучения. Обучение НС фактически сводится к поиску некоторых ее параметров, при которых сеть реализует на своих выходах требуемые функции (от входных значений). При этом возможно:
-изменение топологии сети путем образования или удаления связей между нейронами;
-изменение синаптических коэффициентов (весов) связей между нейронами;
-изменение характеристик составляющих НС нейронов (параметров и типа активационных функций).
Чаще всего структура НС выбирается “вручную” (хотя в некоторых программных пакетах это реализовано с помощью генетических алгоритмов)
и обучение сводится к поиску синаптических коэффициентов Wij. Прежде всего, различают обучение «с учителем» и «обучение без учителя».
Метод обратного распространения ошибки.
Обучение с учителем применяется, в основном, для сетей с прямыми связями. На этапе обучения происходит вычисление синаптических коэффициентов на основе примеров (пара вход-выход), сгруппированных в

13
обучающее множество. Такое множество состоит из ряда примеров
(образцов) – обучающей выборки, с указанием для каждого из них значений выходов нейронной сети, которые было бы желательно получить. Этот процесс называется обучением с учителем. При этом учитель подает на вход сети вектор входных значений X, и для каждого выхода сообщает желаемое
значение d j, p . Такое обучение можно рассматривать как решение
оптимизационной задачи. Еѐ целью является минимизация функции ошибки
(или невязки) Е на обучающем множестве путем выбора значений весов W.
Часто в качестве меры погрешности берется квадратичная ошибка, которая определяется по формуле
E(W ) |
1 |
(d j , p |
y j , p )2 , , |
(2) |
|
|
|||||
2 |
|||||
|
j , p |
|
|
||
где d j, p - требуемое |
(желаемое) значение выхода p |
на j-м образце |
|||
выборки;
y j, p - реальное значение выхода p на j-м образце выборки при текущих значениях синаптических коэффициентов.
При минимизации ошибки E чаще всего используются следующие основные подходы: 1) градиентные методы; 2) стохастические методы; 3)
генетические алгоритмы.
В градиентных методах, как правило, находится градиент ошибки Е для всего обучающего множества, и веса W пересчитываются каждый раз после обработки всей совокупности обучающих примеров. Изменение весов происходит, как обычно, в направлении, обратном к направлению наибольшей крутизны функции ошибки. Подстройка весовых коэффициентов при этом выполняется следующим образом:
Wij (t 1) |
Wij (t) Wij , |
(3) |
|
W |
E |
, |
(4) |
|
|||
ij |
Wij |
|
|
|
|
||
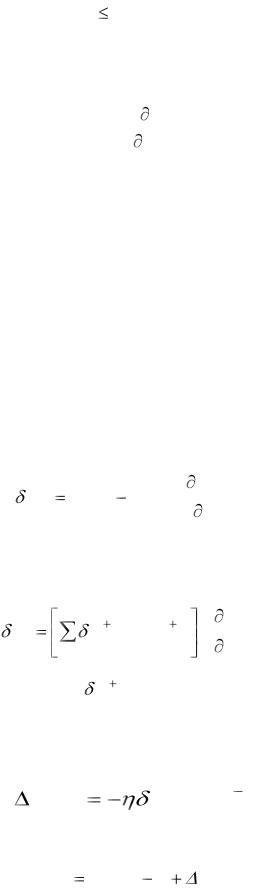
14
где 0  1 - коэффициент обучения, Wij – весовой коэффициент синаптической связи, соединяющий i-тый нейрон слоя (n-1) с j-тым нейроном слоя n. Как видно из (4), решающую роль при коррекции играет частная
1 - коэффициент обучения, Wij – весовой коэффициент синаптической связи, соединяющий i-тый нейрон слоя (n-1) с j-тым нейроном слоя n. Как видно из (4), решающую роль при коррекции играет частная
производная |
E |
, |
поэтому разработаны |
структурные |
методы еѐ |
|
|||||
|
Wij |
|
|
|
|
вычисления. |
Наиболее |
популярным является |
алгоритм |
обратного |
|
распространения (back propagation), суть которого в следующем.
1.Случайно инициализировать вектор синаптических весов W;
2.Подать на входы сети один из образов обучающего множества X и в режиме обычного функционирования нейросети, когда сигналы распространяются от входов к выходам, рассчитать значения выходов y j
всех нейронов;
3.Для каждого нейрона выходного слоя рассчитать рассогласование сигналов
по формуле
( N ) |
( N ) |
( N ) |
|
y(jN ) |
|
|
j |
(d j |
y j |
) * |
|
; |
(5) |
|
||||||
|
|
|
|
S j |
|
|
4. Для остальных нейронов (кроме выходного слоя) рассчитать обобщенное рассогласование согласно следующей формуле
(n) |
|
(n 1) |
|
(n 1) |
|
y j |
|
|
|
|
|
||
j |
|
k |
|
*W jk |
* |
|
|
, |
|
|
|
(6) |
|
|
|
S j |
|
|
|
||||||||
|
k |
|
|
|
|
|
|
|
|
|
|
||
где |
|
(n |
1) |
- ”обобщенное” рассогласование нейронов – последователей |
|||||||||
|
|
k |
|
|
|
|
|
|
|
|
|
|
|
j-го нейрона следующего слоя; |
|
|
|
|
|
||||||||
5. |
Найти |
|
|
корректирующее |
приращение |
для |
каждой |
связи |
|||||
W (n) |
|
|
|
(n) * y (n 1) |
|
|
|
|
|||||
|
ij |
|
|
|
j |
|
i |
|
|
|
|
|
|
и скорректировать все веса в сети по формуле: |
|
|
|
||||||||||
W |
(n) (t) |
W (n) (t |
1) |
W (n) (t) . |
|
|
|
(7) |
|||||
ij |
ij |
|
|
|
ij |
|
|
|
|
|
|||
6. Повторять шаги 2-4 для всех образцов обучающего множества, пока ошибка Е не достигнет приемлемого уровня.

15
Из приведенного алгоритма видно, что для каждого образа (элемента)
обучающей выборки сначала выполняется “прямой проход”, в котором от входов к выходам сети вычисляются значения выходов всех нейронов yi(n 1) .
Затем выполняется “обратное распространение” рассогласования (невязки)
 между требуемыми и реальными текущими значениями сигналов от выходов к входам сети. Рассмотренный метод является детерминистким, в
между требуемыми и реальными текущими значениями сигналов от выходов к входам сети. Рассмотренный метод является детерминистким, в
котором на каждой итерации синаптические веса корректируются по определенному алгоритму, основанному на сравнении требуемых и фактических сигналов. Основным недостатком градиентных методов является возможность сходимости в локальные экстремумы. Существенным ограничением является также требование дифференцируемости оптимизируемых функций. Поэтому для этих методов обычно используются обычно логистические (или тангенциальные) активационные функции.
Стохастические методы обучения минимизируют ошибку на основе псевдослучайного изменения синаптических весов с сохранением тех значений, которые ведут к уменьшению ошибки. Коррекции весов выполняется в соответствии с некоторой вероятностной функцией. Следует отметить, что даже изменения, ведущие к увеличению ошибки имеют
(небольшую) вероятность быть сохраненными согласно методу
“моделирования отжига”. Это позволяет решить проблему сходимости к локальным экстремумам (ценой увеличения времени обучения). Подобное обучение применяется в сетях, называемых машинами Больцмана и Коши.
В последнее время при обучении (и даже синтезе архитектуры сети)
все чаще используются генетические алгоритмы. В этом случае практически нет ограничений на вид оптимизируемой функции, поскольку в процессе оптимизации используется сама функция, а не ее производная, что расширяет возможности обучения.
16
1.4 Конкурентные сети
В предыдущем разделе на этапе обучения необходим “учитель”,
который заранее выполняет классификацию образов, входящих в обучающую выборку и организует ее ввод в компьютер. Но в естественной биологической системе трудно себе представить наличие учителя и сам процесс обучения.
Тем не менее, человек (и не только) способен выполнять классификацию без учителя, что дает основания думать, что объективно существуют алгоритмы обучения без учителя. В конкурентных сетях реализуется “обучение без учителя”. То есть в обучающей выборке для образов неизвестны правильные
(желаемые) выходные реакции. Для реализации этого подхода необходимо решить две основные проблемы: 1) разработать методы разбиения образов на классы без учителя – этап обучения; 2) выработать правила отнесения текущего входного образа к некоторому классу – этап распознавания.
Очевидно, разбиение на классы должно быть основано на использовании достаточно общих свойств классифицируемых объектов. В один класс должны попасть в некотором смысле похожие образы. При этом, как правило,
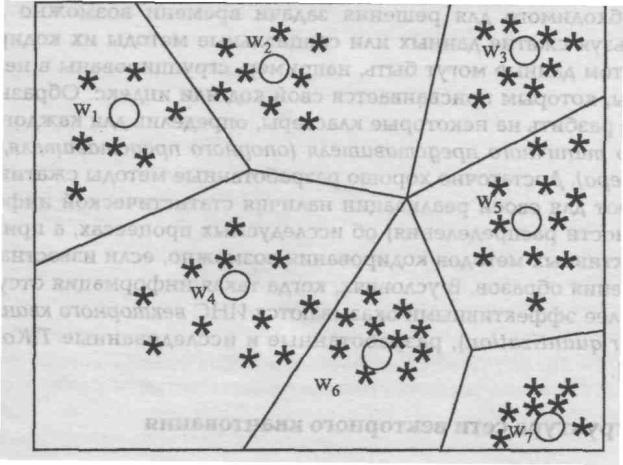
используют компактность образов. В этом случае каждому классу в пространстве признаков соответствует обособленная группа точек. Тогда задача классификации сводится к разделению в многомерном пространстве на части множества точек. Процесс разбиения множества образов на классы называют кластеризацией. Визуально в двумерном (или трехмерном)
пространстве разделение множества точек часто не представляет особых проблем, как это показано, например, на рис.8. Необходимо формализовать способ проведения границы между классами.
17
Рис. 8 Кластеризация данных
Архитектура сетей с конкурентным обучением достаточно проста.
Большинство сетей этого типа имеют один слой нейронов, которые расположены в узлах некоторой решетки, обычно двухмерной, как это показано на рис.4 e,f). Такие сети принято называть картами с самоорганизацией. Кроме плоской 4-угольной решетки часто используется 6-
угольная (гексагональная решетка с окрестностью Галея). Но даже для одной решетки понятие соседства можно определить по-разному. Например, для 4-
угольной сетки используется: 4- связность (соседними считаются 4 элемента
- окрестность Фон Неймана); 8-связность (соседями являются 8 элементов с учетом “диагональных” – окрестность Мура). Карты более высокой размерности также известны, но на практике используются редко. Число входов каждого нейрона определяется размерностью входных образов
(числом признаков). Каждый нейрон в слое соответствует одному классу
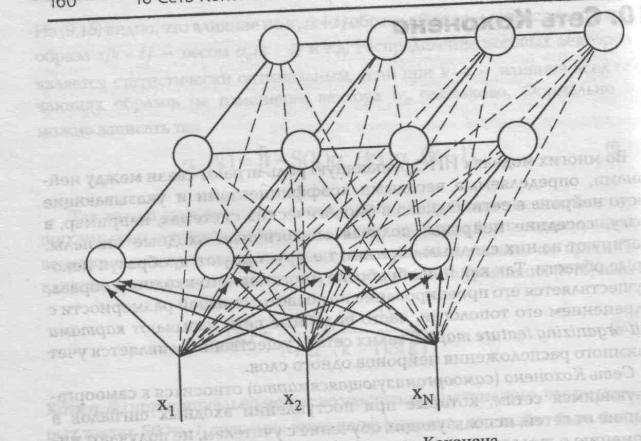
18
(кластеру), поэтому количество нейронов определяет число распознаваемых различных кластеров. На рис.9 представлена сеть Кохонена. Здесь снизу вверх поступают сигналы внешних входов. На каждый нейрон поступают сигналы всех внешних входов и выходные сигналы соседних нейронов. Как видно из рисунка каждый нейрон связан со своими ближайшими соседями по определенной схеме.
Рис.9 Архитектура самоорганизующейся сети Кохонена.
Данный тип нейронных сетей основан на конкуррентном обучении
(competitive learning), где нейроны выходного слоя соревнуются за право активации. При этом активным становится обычно один нейрон - победитель в сети или группе нейронов. Таким образом, здесь реализуется принцип
“победитель получает все”.
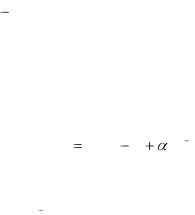
19
Нейроны в процессе конкуренции избирательно настраиваются на различные входные образы или классы образов. Положение таким образом настроенных нейронов упорядочивается по отношению друг к другу таким образом, что похожие входные образы отображаются в нейроны, которые близко расположены на решетке. Таким образом, координаты нейронов решетки являются индикатором статистических свойств, присущих данным входным образам. Пространственное положение выходных нейронов в топографической карте соответствуют определенной области признаков данных, выделенных из входного пространства.
Самоорганизующиеся карты разработаны по подобию человеческого мозга, который организован таким образом, что отдельные сенсорные входы представляются топологически упорядоченными картами в определенных его областях (на коре полушарий).
Как уже отмечалось, в самоорганизующихся сетях используется
“обучение без учителя”. Главная черта, делающая обучение без учителя привлекательным – это его самостоятельность. Процесс обучения, как и в случае обучения с учителем заключается в подстройке синаптических коэффициентов сети. Существует несколько алгоритмов обучения.
Обучение по Хеббу.
Очевидно, что подстройка синапсов может проводиться только на основании информации доступной в нейроне, т.е. его состоянии (значении выходного сигнала) yj и текущего значения синаптического коэффициента
Wij (t 1) .
Исходя из этих соображений и по аналогии с известными принципами самоорганизации нервных клеток разработан алгоритм обучения Хебба,
который основан на следующем правиле коррекции весов:
W (t) |
W (t 1) |
y (n 1) |
y (n) |
, |
(8) |
ij |
ij |
i |
j |
|
|
где
yi(n 1) - выходное значение i-го нейрона (n-1)-го слоя;

20
y (jn) - выходное значение j-го нейрона n-го слоя;
Wij (t),Wij (t 1) - весовые коэффициенты синапса, соединяющего i-й
и j-й нейроны на итерациях t и t-1 соответственно.
Очевидно, что при обучении данным методом усиливаются связи между соседними нейронами. Существует также дифференциальный метод обучения Хебба, в котором коррекция весов производится по формуле
W (t) |
W (t 1) |
[ y(n 1) |
(t) |
y(n 1) |
(t |
1)][ y(n) (t) |
y(n) (t 1)] . |
(9) |
ij |
ij |
i |
|
i |
|
j |
j |
|
Из этой формулы видно, что сильнее всего обучаются синапы,
соединяющие те нейроны, выходы которых наиболее динамично изменяются.
Полный алгоритм обучения выглядит следующим образом:
1.на стадии инициализации всем весовым коэффициентам присваиваются небольшие случайные значения;
2.на входы сети подается входной образ и сигнал возбуждения распространяется по всем слоям сети;
3. на основании полученных выходных значений yi , y j по формулам (8)
или (9) производится изменение весовых коэффициентов;
4.переход на шаг 2, пока выходы сети не стабилизируются с заданной точностью. При этом на втором шаге цикла попеременно предъявляются все образы обучающего множества.
Вид отклика на каждый класс входных образов неизвестен заранее и представляет собой произвольное сочетание состояний нейронов обусловленное случайным распределением весов на стадии инициализации.
Несмотря на это сеть обобщает похожие образы, относя их к одному классу.
1.4.2 Обучение по Кохонену |
|
|
|
|
||
Этот |
алгоритм |
предусматривает |
подстройку |
синаптических |
||
коэффициентов на основании их значений на предыдущей итерации |
||||||
|
|
W (t) |
W (t 1) |
[ y (n 1) W (t 1)] . |
(10) |
|
|
|
ij |
ij |
i |
ij |
|