

1.6 Свойства мпвс
Рассмотрим, как влияет число процессоров N на средние времена ожидания и пребывания заявок, если системы с различным числом процессоров имеют постоянное суммарное быстродействие Bs=N*B = const ;
Пусть ![]() - трудоемкость обслуживания, среднее
число процессорных операций, выполняемых
при обслуживании одной заявки. Тогда
получим, что средняя длительность
обслуживания заявки
- трудоемкость обслуживания, среднее
число процессорных операций, выполняемых
при обслуживании одной заявки. Тогда
получим, что средняя длительность
обслуживания заявки
![]() возрастает
пропорционально числу процессоров в
системе.
возрастает
пропорционально числу процессоров в
системе.
Загрузка процессора
![]() и не зависит от числа процессоров.
и не зависит от числа процессоров.
Вывод: С увеличением числа процессоров при сохранении суммарного
быстродействия средние времена ожидания и пребывания заявок в системе увеличиваются прямо пропорционально числу процессоров в системе, следовательно, минимум среднего ожидания (пребывания) заявок достигается, если все быстродействие 7B 4s 0 будет сосредоточено в одном процессоре.
2 К о н в е й е р н ы е в с (к в с)
Одним из самых простых и наиболее распространенных способов повышения быстродействия процессоров является конвейеризация процесса вычислений.
Преимущество КВС перед параллельными является возможность использования пакетов программ, уже написанных для последовательных ВС.
В любом процессоре машинная команда проходит ряд этапов обработки: выборки команды из ОП (ВК), вычисления адреса операнда в оперативной памяти (ВА), выборку операнда из памяти (ВО), операцию в АЛУ. В процессоре последовательной ВС для этих функций используется единственное устройство, поэтому время выполнения команды:
tК = tВК + tВА + tВО + tАЛУ.
Чтобы уменьшить
tК можно для каждой функции ввести
собственное оборудование. В таком
процессоре любая команда последовательно
проходит все устройства, находясь на
каждом этапе время ![]() t.
t.


ПК ПО ПК - память команд

 ПО
- память операндов
ПО
- память операндов



 УВК,УВА,УВО -
устройства вы-
УВК,УВА,УВО -
устройства вы-


 УВК УВА
УВО АЛУ борки команд,
вычисление ад-
УВК УВА
УВО АЛУ борки команд,
вычисление ад-
реса, выборки операндов.
Рис.2.1.



 i i-1
i-2 i-3
i i-1
i-2 i-3






 t1
t1
i+1
i
i-1 i-2 ![]()


 t2
t2
i+2 i+1 i i-1
 t3
tk
t3
tk
i+3 i+2 i+1 i
 t4
t4
 i+4 i+3 i+2
i+1
i+4 i+3 i+2
i+1


 t5
t5
Рис.2.2.
Так, команда с
номером i поступает в УВК, через время![]() она переходит в УВА, а в УВК поступает
команда с номером i+1;затем через время
она переходит в УВА, а в УВК поступает
команда с номером i+1;затем через время
![]() команда i поступает в УВО, i+1 -> в УВА,
i+2 -> в УВК и т.д. Наконец команда i
поступает в АЛУ и через время
команда i поступает в УВО, i+1 -> в УВА,
i+2 -> в УВК и т.д. Наконец команда i
поступает в АЛУ и через время ![]() t
вырабатывается результат. После этого
через время
t
вырабатывается результат. После этого
через время ![]() будет
получен результат команды i+1.
будет
получен результат команды i+1.
Таким образом,
несмотря на то, что общее время выполнения
любой команды сохранилось, результаты
вырабатываются через время ![]() t
= tk / n, где n - число этапов конвейера.
t
= tk / n, где n - число этапов конвейера.
Принцип построения процессора напоминает конвейер сборочного завода, на котором изделие проходит ряд рабочих мест. На каждом рабочем месте над изделием проводится новая операция.
Эффект ускорения достигается за счет одновременной обработки ряда изделий на разных рабочих местах.
Временная диаграмма строилась при следующих сокращениях:
1) в потоке выбираемых из ПК команд отсутствуют команды условных переходов;
2) все команды имеют одинаковое время нахождения на разных этапах.
Наличие команд условного перехода будет вынуждать переход к командам, которые в данный момент отсутствуют в конвейере, что потребует опустошения и повторного заполнения конвейера из ПК, а неодинаковая длина команд приведет к приостановкам конвейера. Такой в общем случае асинхронный характер функционирования конвейера снижает быстродействие КВС.
Процедура увеличения
быстродействия конвейерных ВС состоит
в следующем: в существующем варианте
конвейера выбирается устройство с
наибольшим временем срабатывания и
разделяется на два и более устройств с
меньшим временем срабатывания каждое.
При этом цикл конвейера ![]() t
уменьшается. Если и после этого
быстродействие КВС недостаточно,
выбирается наиболее медленное устройство
и процесс повторяется.
t
уменьшается. Если и после этого
быстродействие КВС недостаточно,
выбирается наиболее медленное устройство
и процесс повторяется.
Рассмотрим конвейеризацию устройств процессора: АЛУ, УВК, УВА, УВО.
Арифметический конвейер можно построить для любых арифметико-логических операций:сложения, умножения, логических операций.
Конвейер для выполнения операции сложения двух чисел с П.З. Числа представлены в форме A*Rp , где A - мантисса, R - основание системы счисления, p - порядок.




Ai -> выравнивание выравнивание сложение нормализация

Bi-> порядков мантисс мантисс результата
Конвейер для умножения целых чисел




(


 мн.)Ai
Дешифратор
мн.)Ai
Дешифратор




 множителя
множителя



 Сi
Сi









(



 мт.)Bi
мт.)Bi



Рис.2.3.
Каждым входом ![]() первого каскада управляет один разряд
множителя. В зависимости от его значения
на вход
первого каскада управляет один разряд
множителя. В зависимости от его значения
на вход ![]() подаются два смежных сдвинутых частичных
произведения. Число каскадов конвейерного
умножителя равно log2z
, где z- разрядность чисел Ai и Bi .
подаются два смежных сдвинутых частичных
произведения. Число каскадов конвейерного
умножителя равно log2z
, где z- разрядность чисел Ai и Bi .
Для увеличения
производительности УВК используют
множество автономных по функционированию
блоков памяти. Число этих блоков
![]() . и может достигать величины 8...64 (кратно
степени 2), где
. и может достигать величины 8...64 (кратно
степени 2), где
![]() -
интервал выхода чисел с каскада на
каскад конвейера. Так как на каждый
полученный в АЛУ результат приходится
одна выборка команды из ПК, то время
выборки этой команды не должно превышать
-
интервал выхода чисел с каскада на
каскад конвейера. Так как на каждый
полученный в АЛУ результат приходится
одна выборка команды из ПК, то время
выборки этой команды не должно превышать
![]() t.
t.
Рассмотрим варианты организации многоблочной памяти.
Выборка команд со сдвигом во времени
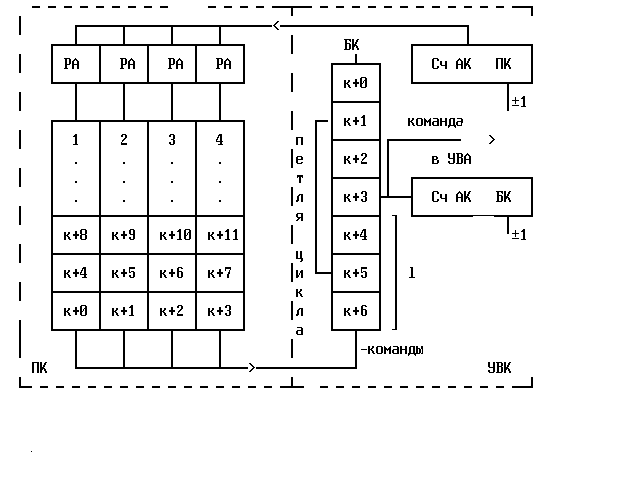
1-4 это блоки памяти.
l- запас новых команд в БК.
Рис.2.4.
В регистре адреса
(РА) блоков памяти 1..4 через каждые ![]() t
подается новый адрес из счетчика адреса
команд СчАК ПК. С таким же сдвигом по
времени на выходе ПК будут появляться
команды, которые затем поступают в
буфер команд (БК), представляющих собой
совокупность быстрых регистров. При
поступлении каждой новой команды В БК
содержимое всех его регистров сдвигается
вверх на одну позицию и верхняя команда
выбрасывается из БК.
t
подается новый адрес из счетчика адреса
команд СчАК ПК. С таким же сдвигом по
времени на выходе ПК будут появляться
команды, которые затем поступают в
буфер команд (БК), представляющих собой
совокупность быстрых регистров. При
поступлении каждой новой команды В БК
содержимое всех его регистров сдвигается
вверх на одну позицию и верхняя команда
выбрасывается из БК.
В УВК имеется СчАК БК, который указывает положение в БК считываемой в УВА команды. При считывании из БК каждой команды его содержимое уменьшается на единицу, при добавлении в БК новой команды из ПК - увеличивается на единицу.
Если l становится меньше заданного уровня, то УВК запускает СчАК ПК и производится выборка из ПК новых команд.
Выборка широким словом
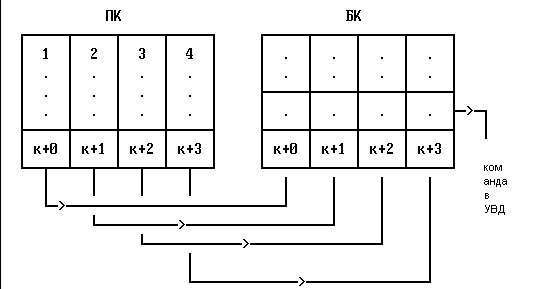
Рис.2.5.
За один цикл памяти в БК заносится несколько команд (широкое слово), операции в БК выполняются также, как и ранее.
Сократить цикл работы УВО можно также использованием многоблочной памяти для уменьшения времени чтения операнда. Однако между выборкой команд и выборкой операндов существует принципиальное различие. Команды в программе и памяти располагаются в порядке линейного нарастания их номеров. Следовательно, во время исполнения текущей команды всегда можно вычислить адреса и выбрать любые следующие команды. Но упорядоченная выборка команд порождает неупорядоченную последовательность адресов для выборки операндов. Это означает, что выборка операндов для некоторой команды не может быть произведена заранее до выборки этой команды. => выборка операндов не может быть конвейеризирована => для построения ПО используется не конвейерный, а поточный принцип организации многоблочной памяти.
Поточная организация УВО
 Рис.2.6.
Рис.2.6.
Поступающие из УВА адреса операндов распределяются по блокам ПО. Так как распределение адресов носит случайный характер, в блоках памяти возможны очереди, для размещения которых введены буфера адресов (БА).
Выбираемые из памяти операнды должны сразу поступать в АЛУ, однако в следствии неравномерности их появления из ПО и разной длительности исполнения операций в АЛУ вводятся буферные регистры операндов чтения (БОЧ) и записи (БОЗ).
С каждой парой операндов связан свой код операции, который хранится также в буфере кода операций (БКОП).
Следовательно, в буфере операндов (БО) и БКОП хранятся готовые к исполнению в АЛУ группы информации.
Зависимость цикла выборки одного операнда от количества блоков памяти
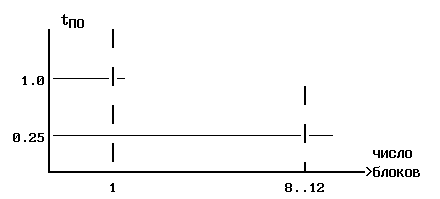
Рис.2.7.
Мы изучили структуры отдельных устройств конвейерного процессора.