

КР по ОАиП / Учебное пособие Батура М.П. и Со
.pdfВ общем, алгоритм – строгий и четкий набор правил, определяющий последовательность действий, приводящих к достижению поставленной цели.
1.3. Свойства алгоритмов
Дискретность – значения новых величин (данных) вычисляются по определенным правилам из других величин с уже известными значениями.
Определенность (детерминированность) – каждое правило из набора однозначно, а сами данные однозначно связаны между собой, т.е. последовательность действий алгоритма строго и точно определена.
Результативность (конечность) – алгоритм решает поставленную задачу за конечное число шагов.
Массовость – алгоритм разрабатывается так, чтобы его можно было применить для целого класса задач, например, алгоритм вычисления определенных интегралов с заданной точностью.
1.4. Сложность алгоритма
Выполнение любого алгоритма требует определенного объема памяти компьютера для размещения данных и программы, а также времени по обработке этих данных – эти ресурсы ограничены и, следовательно, правомочен вопрос об эффективности их использования. Таким образом, в самом широком смысле понятие эффективности связано со всеми вычислительными ресурсами, необходимыми для работы алгоритма.
Однако обычно под «самым эффективным» понимается алгоритм, обеспечивающий наиболее быстрое получение результата, поэтому рассмотрим именно временнýю сложность алгоритмов.
Время работы алгоритма удобно выражать в виде функции от одной переменной, характеризующей «размер» конкретной задачи, т.е. объем входных данных, необходимых для ее решения. Тогда сравнительная сложность задач и может оцениваться через ее размер.
Поскольку описание задачи, предназначенной для решения посредством вычислительного устройства, можно рассматривать в виде слова конечной длины, представленной символами конечного алфавита, в качестве формальной характеристики размера задачи можно принять длину входного слова. Например, если стоит задача определения максимального числа в некоторой последовательности из n элементов, то и размер задачи будет n, поскольку любой вариант входной последовательности можно задать словом из n символов.
Временная сложность алгоритма – это функция, которая каждой входной длине слова n ставит в соответствие максимальное (для всех конкретных задач длиной n) время, затрачиваемое алгоритмом на ее решение.
Различные алгоритмы имеют различную временную сложность и выяснение того, какие из них окажутся достаточно эффективны, а какие нет, определяется многими факторами. Однако для сравнения эффективности ал-
11
горитмов был предложен простой подход, позволяющий прояснить ситуа-
цию. Речь идет о различии между полиномиальными и экспоненциальными
алгоритмами.
Полиномиальным называется алгоритм, временнàя сложность которого выражается некоторой полиномиальной функцией размера задачи n. Алгоритмы, временнáя сложность которых не поддается подобной оценке, назы-
ваются экспоненциальными.
Задача считается труднорешаемой, если для нее не удается построить полиномиального алгоритма. Это утверждение не является категорическим, поскольку известны задачи, в которых достаточно эффективно работают и экспоненциальные алгоритмы. Примером может служить симплекс-метод, который успешно используется при решении задач линейного программирования, имея функцию сложности f(n) = 2n. Однако подобных примеров не очень много, и общей следует признать ситуацию, когда эффективно исполняемыми можно считать полиномиальные алгоритмы с функциями сложности n, n2 или n3.
Например, при решении задачи поиска нужного элемента из n имеющихся в худшем варианте сложность равна n; если же оценить среднюю трудоемкость (продолжительность поиска), то она составит (n+1)/2 – в обоих случаях функция сложности оказывается линейной n.
Сложность задачи вычисления определителя системы n линейных уравнений с n неизвестными характеризуется полиномом 3-й степени. Повышение быстродействия элементов компьютера уменьшает время исполнения алгоритма, но не уменьшает степень полинома сложности.
1.5. Способы описания алгоритмов
Существует несколько способов описания алгоритмов. Наиболее распространенные способы – это словесное и графическое описания алгоритма.
Словесное описание алгоритма
В любом алгоритме для обозначения данных используют некоторый набор символов, называемых буквами. Конечную совокупность букв называют алфавитом, из любой конечной последовательности которого можно составить слово, т.е. в любом алфавите реальным данным можно сопоставить некоторые слова, в дальнейшем обозначающие эти данные.
При словесной записи алгоритм описывается с помощью естественного языка с использованием следующих конструкций:
1)шаг (этап) обработки (вычисления) значений данных – «=»;
2)проверка логического условия: если (условие) истинно, то выполнить действие 1, иначе – действие 2;
3)переход (передача управления) к определенному шагу (этапу) N.
Для примера рассмотрим алгоритм решения квадратного уравнения вида a x2+b x+c = 0:
1) ввод исходных данных a, b, c (a,b,c 0);
12

2)вычислить дискриминант D = b2 – 4a c ;
3)если D < 0, то перейти к п. 6, сообщив, что действительных корней
нет;
4)иначе, если D 0, вычислить х1= (–b+ 
 D )/(2a) и х2 = (–b–
D )/(2a) и х2 = (–b– 
 D )/(2a);
D )/(2a);
5)вывести результаты х1 и х2 ;
6)конец.
Графическое описание алгоритма
Графическое изображение алгоритма – это представление его в виде схемы, состоящей из последовательности блоков (геометрических фигур), каждый из которых отображает содержание очередного шага алгоритма. А внутри фигур кратко записывают действие, выполняемое в этом блоке. Такую схему называют блок-схемой или структурной схемой алгоритма, или просто схемой алгоритма.
Правила изображения фигур сведены в единую систему программной документации (дата введения последнего стандарта ГОСТ 19.701.90 –
01.01.1992).
По данному ГОСТу графическое изображение алгоритма – это схема данных, которая отображает путь данных при решении задачи и определяет этапы их обработки.
Схема данных состоит из следующих элементов:
–символов данных (символы данных могут отображать вид носителя данных);
–символов процесса, который нужно выполнить над данными;
–символов линий, указывающих потоки данных между процессами и носителями данных;
–специальных символов, которые используют для облегчения чтения схемы алгоритма.
Рассмотрим основные символы для изображения схемы алгоритма.
Символы ввода-вывода данных:
– данные ввода-вывода, если носитель не определен;
–ручной ввод с устройства любого типа, например с клавиатуры;
–отображение данных в удобочитаемой форме на устройстве, например дисплее.
Символы процесса:
А = 5 |
– процесс – отображение функции обработки данных, т.е. опе- |
|
рации, приводящей к изменению указанного значения; |
||
|
13
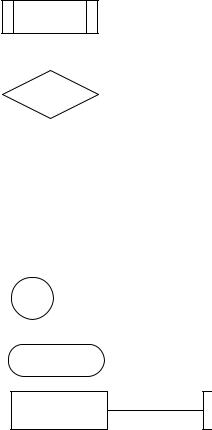
– предопределенный процесс – отображение группы операций, которые определены в другом месте, например в подпрограмме (функции);
– решение – отображение функции, имеющей один вход и ряд А<5 альтернативных выходов, из которых только один может быть активизирован после анализа условия, указанного внутри этого
символа.
Символы линий – отображают поток данных или управления. Линии – горизонтальные или вертикальные, имеющие только прямой угол перегиба. Стрелки – указатели направления не ставятся, если управление идет сверху вниз или слева направо.
Специальные символы
Соединитель – используется при обрыве линии и продолжении ее в другом месте (необходимо присвоить название).
Терминатор – вход из внешней среды или выход во внешнюю среду (начало или конец схемы программы).
Комментарий.
1.6. Способы реализации алгоритмов
Любую программу можно разбить на блоки, реализованные в виде алгоритмов (процессов), которые можно разделить на три вида:
1)линейные (единственное направление выполнения);
2)разветвляющиеся (направление выполнения определяет условие);
3)циклические (отдельные участки вычислений выполняются много-
кратно).
Любой циклический процесс включает в себя участок с разветвлением
иможет быть простым и сложным (вложенным).
Для решения вопроса о том, сколько раз нужно выполнить цикл, используется анализ переменной, которую называют параметром цикла.
Циклический процесс, в котором количество повторений заранее известно, называется циклом по счетчику, а циклический процесс, в котором количество повторений заранее неизвестно и зависит от получаемого в ходе вычислений результата, называют итерационным.
1.7. Пример простейшего линейного процесса
Наиболее часто в практике программирования требуется организовать расчет некоторого арифметического выражения при различных исходных данных. Например, такого:
14

|
|
tg 2 x |
|
x(m 1) |
|
|
|
z |
|
|
x2 m2 , |
||||
|
|
|
|||||
x2 m2 |
|||||||
|
|
|
|
|
|
||
где x > 0 – вещественное, m – целое.
Разработка алгоритма обычно начинается с составления схемы. Продумывается оптимальная последовательность вычислений, при которой, например, отсутствуют повторения. При написании алгоритма рекомендуется переменным присваивать те же имена, которые фигурируют в заданном арифметическом выражении либо иллюстрируют их смысл.
Для того чтобы не было «длинных» операторов, исходное выражение полезно разбить на ряд более простых. В нашей задаче предлагается схема вычислений, представленная на рис. 1.1.
Н а ч а л о
В в о д |
x , m |
|
||
|
|
|
|
|
|
|
|
|
|
a |
x 2 |
m 2 |
|
|
|
|
|
|
|
b |
= |
tg 2 х |
|
|
|
|
|
|
|
|
|
|
|
|
c |
= |
x n + 1 |
|
|
|
|
|
|
|
z = |
b / a + c ·a |
|
||
|
|
|
|
|
В ы в о д |
x , m , z |
|
||
|
|
|
|
|
К о н е ц Рис. 1.1. Схема линейного процесса
Она содержит ввод и вывод исходных данных, линейный вычислительный процесс, вывод полученного результата. Заметим, что выражение

 x2 m2 вычисляется только один раз. Введя дополнительные переменные a, b, c, мы разбили сложное выражение на ряд более простых.
x2 m2 вычисляется только один раз. Введя дополнительные переменные a, b, c, мы разбили сложное выражение на ряд более простых.
1.7. Пример циклического процесса
Вычислить значение функции y = sin x, представленной в виде разложения в ряд, с заданной точностью, т.е. до тех пор, пока разность между соседними слагаемыми не станет меньше заданной точности:
15

y sin x x x3 x5 x7 ....
3! 5! 7!
Схема алгоритма, приведенная на рис. 1.2, реализует циклический процесс, в состав которого (в блоке проверки |E|< eps) входит участок разветвления.
Начало x, eps
Y = A1= x;
i = 1;
A2=-A1(x x)/(2i(2i+1))
i = i +1
y = y +A2
E =A1+A2
A1 = A2
Нет |
Да |
Конец |
|E|<eps |
y, E, i |
Рис. 1.2. Схема циклического алгоритма
16
ГЛАВА 2. Базовые средства языка Си
Любая программа, написанная на языке высокого уровня, состоит из последовательности инструкций, оформленных в строгом соответствии с набором правил, составляющих синтаксис данного языка.
При создании программ разработчик может допустить следующие ошибки: синтаксические и логические.
Синтаксические ошибки – это результат нарушения формальных правил написания программы на конкретном языке программирования.
Логические ошибки разделяются, в свою очередь, на ошибки алгоритма и семантические ошибки.
Причиной ошибки алгоритма является несоответствие построенного алгоритма ходу получения конечного результата сформулированной задачи.
Причина семантической ошибки – неправильное понимание смысла (семантики) операторов выбранного языка программирования.
2.1. Алфавит языка Си
Алфавит любого языка составляет совокупность символов – тех неделимых знаков, при помощи которых записываются все тексты на данном языке.
Каждому из множества значений, определяемых одним байтом (от 0 до 255), в таблице знакогенератора ЭВМ ставится в соответствие символ. По кодировке фирмы IBM символы с кодами от 0 до 127, образующие первую половину таблицы знакогенератора, построены по стандарту ASCII и одинаковы для всех компьютеров, вторая половина символов (коды 128 – 255) может отличаться и обычно используется для размещения символов национального алфавита. Коды 176 – 223 отводятся под символы псевдографики, а коды 240 – 255 – под специальные знаки (прил. 1).
Алфавит языка Си включает:
–прописные и строчные буквы латинского алфавита и знак подчеркивания (код 95);
–арабские цифры от 0 до 9;
–специальные символы, смысл и правила использования которых будем рассматривать по тексту;
–пробельные (разделительные) символы: пробел, символы табуляции, перевода строки, возврата каретки, новой страницы и новой строки.
2.2. Лексемы
Из символов алфавита формируются лексемы (или элементарные конструкции) языка – минимальные значимые единицы текста в программе:
–идентификаторы;
–ключевые (зарезервированные) слова;
17

–знаки операций;
–константы;
–разделители (скобки, точка, запятая, пробельные символы).
Границы лексем определяются другими лексемами, такими как разделители или знаки операций, а также комментариями.
2.3. Идентификаторы и ключевые слова
Идентификатор (ID) – это имя программного объекта (константы, переменной, метки, типа, функции и т.д.). В идентификаторе могут использоваться латинские буквы, цифры и знак подчеркивания; первый символ ID – не цифра; пробелы внутри ID не допускаются.
Длина идентификатора определяется выбранной версией среды программирования. Например, в среде Borland C++ 6.0 идентификаторы могут включать любое число символов, из которых воспринимаются и используются только первые 32 символа. Современная тенденция – снятие ограничений длины идентификатора.
При именовании объектов следует придерживаться общепринятых соглашений:
–ID переменных и функций обычно пишутся строчными (малыми) бу-
квами – index, max();
–ID типов пишутся с большой буквы, например, Spis, Stack;
–ID констант (макросов) – большими буквами – INDEX, MAX_INT;
–идентификатор должен нести смысл, поясняющий назначение объекта в программе, например, birth_date – день рождения, sum – сумма;
–если ID состоит из нескольких слов, как, например, birth_date, то принято либо разделять слова символом подчеркивания, либо писать каждое следующее слово с большой буквы – birthDate.
В Си прописные и строчные буквы – различные символы. Идентификаторы Name, NAME, name – различные объекты.
Ключевые (зарезервированные) слова не могут быть использованы в качестве идентификаторов.
Список ключевых слов, определенных в стандарте ANSI Cи:
auto |
do |
goto |
signed |
unsigned |
break |
double |
if |
sizeof |
void |
case |
else |
int |
static |
volatile |
char |
enum |
long |
struct |
while |
const |
extern |
register |
switch |
|
continue |
float |
return |
typedef |
|
default |
for |
short |
union |
|
Здесь и далее по тексту объектами будем называть элементы, участвующие в программе.
18

2.4. Комментарии
Еще один базовый элемент языка программирования – комментарий – не является лексемой. Внутри комментария можно использовать любые допустимые на данном компьютере символы, поскольку компилятор их игнорирует.
В Си комментарии ограничиваются парами символов /* и */, а в С++ был введен вариант комментария, который начинается символами // и заканчивается символом перехода на новую строку.
2.5. Простейшая программа
Программа, написанная на языке Си, состоит из одной или нескольких функций, одна из которых имеет идентификатор main – главная (основная). Она является первой выполняемой функцией (с нее начинается выполнение программы) и ее назначение – управлять работой всей программы (проекта).
Общая структура программы на языке Си имеет вид:
<директивы препроцессора>
<определение типов пользователя – typedef> <описание прототипов функций> <определение глобальных переменных> <функции>
В свою очередь, каждая функция имеет следующую структуру:
<класс памяти> <тип> < ID функции> (<объявление параметров>) { – начало функции
код функции } – конец функции
Код функции является блоком и поэтому заключается в фигурные скобки.
Функции не могут быть вложенными друг в друга.
Рассмотрим кратко основные части общей структуры программ.
Перед компиляцией программа обрабатывается препроцессором (прил. 3), который работает под управлением директив.
Препроцессорные директивы начинаются символом #, за которым следует наименование директивы, указывающее ее действие.
Препроцессор решает ряд задач по предварительной обработке программы, основной из которых является подключение (include) к программе так называемых заголовочных файлов (обычных текстов) с декларацией стандартных библиотечных функций, использующихся в программе. Общий формат ее использования
#include < ID_файла.h>
где h – расширение заголовочных файлов.
Более подробное описание функции main рассматривается в п. 11.7.
19
Если идентификатор файла заключен в угловые скобки (< >), то поиск данного файла производится в стандартном каталоге, если – в двойные кавычки (” ”), то поиск файла производится в текущем каталоге.
К наиболее часто используемым библиотекам относятся:
stdio.h – содержит стандартные функции файлового ввода-вывода; math.h – математические функции;
conio.h – функции для работы с консолью (клавиатура, дисплей). Второе основное назначение препроцессора – обработка макроопре-
делений. Макроподстановка определить (define) имеет общий вид
#define ID строка
Например: #define PI 3.1415927
– в ходе препроцессорной обработки программы идентификатор PI везде будет заменяться значением 3.1415927.
Рассмотрим пример, позволяющий понять простейшие приемы программирования на языке Си:
#include <stdio.h> |
|
void main(void) |
|
{ |
// Начало функции main |
printf(“ Высшая оценка знаний – 10 !”); |
|
} |
// Окончание функции main |
Отличительным признаком функции служат скобки ( ) после ее идентификатора, в которые заключается список параметров. Перед ID функции указывается тип возвращаемого ею результата. Если функция не возвращает результата и не имеет параметров, указывают атрибуты void – отсутствие значений.
Для начала будем использовать функцию main без параметров и не возвращающую значения.
Код функции представляет собой набор инструкций, каждая из которых оканчивается символом «;». В нашем примере одна инструкция – функция printf, выполняющая вывод данных на экран, в данном случае – указанную фразу.
__________________________________________________________________
Приемы отладки в среде программирования Visual C++ 6.0 рассматриваются в прил. 5.
__________________________________________________________________
2.6. Основные типы данных
Данные в языке Си разделяются на две категории: простые (скалярные), будем их называть базовыми, и сложные (составные) типы данных.
Тип данных определяет:
–внутреннее представление данных в оперативной памяти;
–совокупность значений (диапазон), которые могут принимать данные этого типа;
20