

Преимущества и недостатки стековой адресации.
Стековая память
Стековой называют память, доступ к которой организован по принципу: "последним записан - первым считан" (Last Input First Output - LIFO). Использование принципа доступа к памяти на основе механизма LIFO началось с больших ЭВМ. Применение стековой памяти оказалось очень эффективным при построении компилирующих и интерпретирующих программ, при вычислении арифметических выражений с использованием польской инверсной записи. В малых ЭВМ она стала широко использоваться в связи с удобствами реализации процедур вызова подпрограмм и при обработке прерываний.
Принцип работы стековой памяти состоит в следующем (см. рис. 4.15). Когда слово А помещается в стек, оно располагается в первой свободной ячейке памяти. Следующее записываемое слово перемещает предыдущее на одну ячейку вверх и занимает его место и т.д. Запись 8-го кода, после H, приводит к переполнению стека и потере кода A. Считывание слов из стека осуществляется в обратном порядке, начиная с кода H, который был записан последним. Заметим, что выборка, например, кода E невозможна до выборки кода F, что определяется механизмом обращения при записи и чтении типа LIFO. Для фиксации переполнения стека желательно формировать признак переполнения.
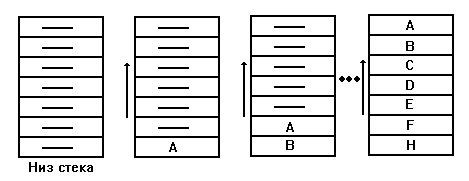
Рис. 4.15. Принцип работы стековой памяти.
Перемещение данных при записи и считывании информации в стековой памяти подобно тому, как это имеет место в сдвигающих регистрах. С точки зрения реализации механизма доступа к стековой памяти выделяют аппаратный и аппаратно-программный (внешний) стеки.
Аппаратный стек представляет собой совокупность регистров, связи между которыми организованы таким образом, что при записи и считывании данных содержимое стека автоматически сдвигается. Обычно емкость аппаратного стека ограничена диапазоном от нескольких регистров до нескольких десятков регистров, поэтому в большинстве МП такой стек используется для хранения содержимого программного счетчика и его называют стеком команд. Основное достоинство аппаратного стека - высокое быстродействие, а недостаток - ограниченная емкость.
Наиболее распространенным в настоящее время и, возможно, лучшим вариантом организации стека в ЭВМ является использование области памяти. Для адресации стека используется указатель стека, который предварительно загружается в регистр и определяет адрес последней занятой ячейки. Помимо команд CALL и RET, по которым записывается в стек и восстанавливается содержимое программного счетчика, имеются команды PUSH и POP, которые используются для временного запоминания в стеке содержимого регистров и их восстановления, соответственно. В некоторых МП содержимое основных регистров запоминается в стеке автоматически при прерывании программ. Содержимое регистра указателя стека при записи уменьшается, а при считывании увеличивается на 1 при выполнении команд PUSH и POP, соответственно.
Модель параллельных вычислений epic.
Параллелизм на уровне инструкций
Компьютерная программа — это, по существу, поток инструкций, выполняемых процессором. Но можно изменить порядок этих инструкций, распределить их по группам, которые будут выполняться параллельно, без изменения результата работы всей программы. Данный приём известен как параллелизм на уровне инструкций. Продвижения в развитии параллелизма на уровне инструкций в архитектуре компьютеров происходили с середины 1980-х до середины 1990-х.

![]()
Классический пример пятиступенчатого конвейера на RISC-машине (IF = выборка инструкции, ID = декодирование инструкции, EX = выполнение инструкции, MEM = доступ к памяти, WB = запись результата в регистры).
Современные процессоры имеют многоступенчатый конвейер команд. Каждой ступени конвейера соответствует определённое действие, выполняемое процессором в этой инструкции на этом этапе. Процессор с N ступенями конвейера может иметь одновременно до N различных инструкций на разном уровне законченности. Классический пример процессора с конвейером — это RISC-процессор с 5-ю ступенями: выборка инструкции из памяти (IF), декодирование инструкции (ID), выполнение инструкции (EX), доступ к памяти (MEM), запись результата в регистры (WB). Процессор Pentium 4 имеет 35-тиступенчатый конвейер.[5]

![]()
Пятиступенчатый конвейер суперскалярного процессора, способный выполнять две инструкции за цикл. Может иметь по две инструкции на каждой ступени конвейера, максимум 10 инструкций могут выполняться одновременно.
Некоторые процессоры, дополнительно к использованию конвейеров, обладают возможностью выполнять несколько инструкций одновременно, что даёт дополнительный параллелизм на уровне инструкций. Возможна реализация данного метода при помощи суперскалярности, когда инструкции могут быть сгруппированы вместе для параллельного выполнения (если в них нет зависимости между данными). Также возможны реализации с использованием явного параллелизма на уровне инструкций: VLIW и EPIC.
Архитектура EPIC имеет следующие особенности для устранения недостатков VLIW:
Каждая группа из нескольких инструкций называется бандлом (bundle). Каждый бандл может иметь стоповый бит, обозначающий, что следующая группа зависит от результатов работы данной. Такой бит позволяет создавать будущие поколения архитектуры с возможностью параллельного запуска нескольких бандлов. Информация о зависимостях вычисляется компилятором, и поэтому аппаратуре не придется проводить дополнительную проверку независимости операндов.
Для предподкачки данных используется инструкция программной подкачки (software prefetch). Предподкачка увеличивает вероятность того, что к моменту исполнения команды загрузки, данные уже будут в кеше. Также, в этой инструкции могут быть дополнительные указания для выбора различных уровней кеша для данных.
Инструкция спекулятивной загрузки используется для загрузки данных до того, как станет известно, будут ли они использованы (bypassing control dependencies), или будут они изменены перед использованием (bypassing data dependencies).
Инструкции проверки загрузки (check load instruction) помогает инструкциям спекулятивной загрузки при помощи проверок, зависела ли инструкция загрузки от последующей записи. В случае наличия подобной зависимости, спекулятивная загрузка должна быть повторена.
Архитектура EPIC также включает в себя несколько концепций (grab-bag) для увеличения ILP (параллелизма инструкций):
Предсказание ветвлений используется, чтобы снизить частоту переходов и для увеличения спекулятивности исполнения инструкций. В последнем случае, условное ветвление преобразуется в заполнение предикатных регистров, затем выполняются обе ветви. Результат той ветви, которая не должна была выполняться, отменяется по значению предикатного регистра.
Отложенные исключительные ситуации, использующие бит Not a thing в регистрах общего назначения. Они позволяют продолжать спекулятивное исполнение даже после исключительных ситуаций.
Крайне большой регистровый файл, чтобы избежать необходимости в переименовании регистров.
В архитектуре Itanium также был добавлен вращающийся регистровый файл[3], необходимый для упрощения программной конвейеризации циклов (software pipelining). При наличии такого файла исчезает необходимость в ручной раскрутке циклов и ручного переименования регистров.[4]