

LW21(лаба 2.1 інтел системи) / Примеріы разаработки ЭС
.pdfПримеры построения экспертных систем
Модель экспертной системы как правило состоит из двух программ: компилятора с языка правили рабочей системы.
При создании своей модели пользователь сначала пишет правила.
Правила образуют исходный файл, который компилируется системой.
После того как пользователь получает скомпилированную модель, наступает этап ее использования. Для этого пользователь запускает программу, которая запрашивает названии модели, которой он хочет воспользоваться.
Когда такое имя задано, то программа читает объектный файл для этой модели и начинается сеанс вопросов и ответов.
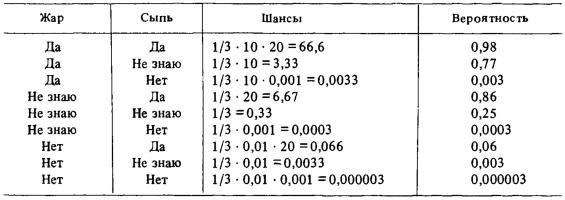
Рис. 1. Примеры базы правил
На рис, 1 представлена структурная схема небольшой базы правил. В этом примере имеется лишь одна цель, заключенная в самый верхний прямоугольник. Целью
служит: ’’Вам следует взять с собой зонтик”, для чего модель задает пользователю вопросы.
От верхнего прямоугольника вниз отходят две стрелки к прямоугольникам, расположенным на втором уровне. Это — ’’Идет дождь” и ’’Сегодня будет дождь”, то есть решение
взять с собой зонтик определенным образом зависит от того, идет ли дождь сейчас, или будет ли он идти сегодня. На этом этапе просто констатируется факт зависимости.
Обратившись к прямоугольнику на рис. 1 с пометкой: ’’Сегодня будет дождь” , видим, что от него отходят три стрелки к трем другим прямоугольникам. В этих прямоугольниках содержатся слова: ’’Коровы стоят на лугу” , ’’Водоросли поникли” , ’’Барометр падает” , так что истинность этого утверждения зависит каким-то образом от истинности последних трех высказываний.
У других четырех утверждений отсутствуют выходящие из них стрелки.
В модели нет никакого другого способа вывести истинность или ложность этих утверждений, иначе как спросив пользователя.
Следовательно, эти четыре утверждения представляют собой вопросы и помечены оответствующим образом на рис. 1.
Утверждение: ’’Сегодня будет дождь” — не является ни целью, ни вопросом. Поэтому это утверждение называется правилом.
Выводы: прямоугольники на наших рисунках представляют собой гипотезы модели и являются либо целями, либо правилами, либо вопросами.
Сверху в дереве должны располагаться цели, в середине его могут также располагаться цели, если это необходимо пользователю.
У цели имеется два атрибута. Первый — это то, что вы хотите попросить систему
доказать, а второй — утверждение, которое будет выдано системой в качестве окончательного отчета.
Концевые вершины деревьев обязательно должны представлять собой вопросы. Все другие прямоугольники называются правилами.
Истинность или ложность каждого прямоугольника на рисунке (исключая прямоугольники-вопросы) выводится из истинности или ложности прямоугольников, на которые делается ссылка.
Вывод можно производить несколькими способами, так что с каждым прямоугольником связывается некоторый оператор.
Если в системе используется булева логика, то этими операторами служат булевы операторы И, ИЛИ и НЕ. Но в системе предусмотрен учет неопределенностей.
Вклад каждого фактора в некоторую гипотезу обычно не будет просто истинностью
или
ложью, а с ними будет связана некоторая вероятность.
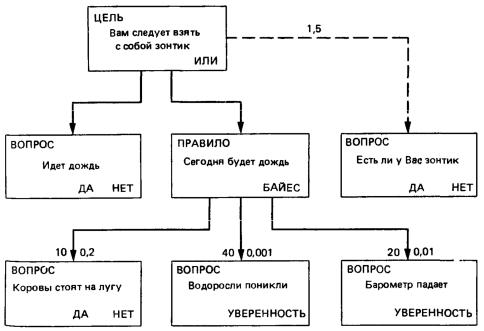
На рис. 2 показана та же модель, что и на рис. 8.1, но развернуая так, чтобы отобразить операторы и типы вопросов.
Оператор НЕ реализовать просто. Если А есть не В, то вероятность А-равна единице минус вероятность В :
ЕСЛИ А = НЕ В ТО РгА = 1 — РгВ.

Имеется множество различных способов задания нечетких операторов типов И и ИЛИ. Однако независимо от них такие операторы в пределе должны вести себя как обычные булевы операторы(когда вероятности определяющих факторов стремятся к нулю или единице).
В данном примере оператор И определяется как минимум. Это означает, что в выражении:
” А есть В и С и D” — при вероятностях А, В, С и D, обозначенных как РгА, РгВ, PrC, PrD, РгА является минимумом из величин РгА, PrC, PrD.
Аналогично оператор ИЛИ определяется как максимум. В выражении: ” А есть В ИЛИ С ИЛИ D” — РгА является максимумом из величин РгА, PrC, PrD.
Рис. 2. Типы используемых операторов вопросов
Функции И и ИЛИ могут быть реализованы многими способами, например функцию И можно было определять так, чтобы вероятности утверждений,вносящих в нее свой вклад, перемножались между собой.
Кроме этих трех расплывчатых логических операций необходима еще одна, которая дает возможность сказать что-то вроде: ” А зависит от В и С, но В является более важным, чем С”. Для реализации таких операций можно прибегнуть к байесовскому оператору.
Правило с байесовским оператором выглядит следующим образом:
Правило свинка(байесовское) ” У больного — свинка”
Жар ЛД 10 ЛН 0,01 Сыпь ЛД 20 ЛН 0,001 Априорно 0,25
Правило гласит, что свинка может быть выведена на основании наличия сыпи и жара. Последняя строка в этом примере: ’’Априорно 0,25” — означает, что в 25% случаев, рассматриваемых этой моделью, заранее ожидается заболевание свинкой.
В случае, если по некоторым причинам не можем проверить, есть ли у больного сыпь и жар, вероятность заболевания свинкой равна у него 0,25. Это число является
априорной вероятностью заболевания свинкой.
Первым этапом вычисления вероятности заболевания свинкой является превращение этой априорной вероятности в априорные шансы. Вероятность 0,25 соответствует 1/3
шанса, т.е. один шанс за эту болезнь, а три — против.
С каждым вносящим свой вклад фактором связаны два числа, известные как ЛД и ЛН. Здесь ЛД означает логическую достаточность, а ЛН — логическую необходимость.
В приведенном примере ЛД для жара равна 10, ЛН - 0,01. Если знаем, что жар у больного имеется, то умножаем априорный шанс заболевания свинкой на коэффициент ЛД. В данном случае это даст нам текущий, или апостериорный,шанс, равный 1/3 • 10 = 10/3.
Если известно, что имеется также и сыпь, то умножаем априорный шанс сыпи на ЛД для сыпи, равную 20, что дает апостериорныйшанс при учете и жара, и сыпи, равный 1/3- 1020.
Если знаем, что некоторый симптом отсутствует, то умножаем априорный шанс на соответствующий коэффициент ЛН.
Если неизвестно, присутствует некоторый симптом или нет, то умножаем на единицу, т. е. шанс не изменяется.
Приведенное в качестве примера правило может быть так переведено на обычный язык. Если нет никаких данных, то вероятность заболевания свинкой равна 0,25. Явное присутствие жара делает свинку в 10 раз более вероятной. Явное отсутствие жара делает заболевание свинкой в 100 раз менее вероятным. Явное присутствие сыпи
делает заболевание свинкой в 20 раз более вероятным, а четкое ее отсутствие - в 1000 раз менее вероятным.
Соответствующие этим случаям результаты приведены в табл. 1.
Таблица 1.
В качестве факторов, вносящих свой вклад в байесовское правило. могут выступать также и сами правила. Возникает вопрос: как интерпретировать вероятности этих правил в терминах ”да” , ’’нет” и ”не знаю” ? ”Да” , очевидно, эквивалентно вероятности, равной 1, ’’нет” — вероятности равной О, а ”не знаю” интерпретируется как вероятность, равная априорной вероятности.
Возникает проблема в том случае, когда эта вероятность не совпадает ни с одной из этих трех величин.
Обратившись опять к рис.2, видим, что там концевые вершины деревьев названы
вопросами.
Модель не располагает никакими средствами вычисления вероятностей этих утверждений, так что она должна спросить о них пользователя.
Пользователя просят дать оценку вероятности того, что это утверждение истинно.
Если требовать от пользователя сразу задать саму вероятность, то употребление такой системы может представить некоторые трудности.
Однако в большинстве случаев пользователь в состоянии в ответ на вопрос дать ответ ”да”, ”нет” , ”не знаю” . Этот ответ переводится системой в вероятность, где ”да” соответствует 1, ’’нет” - 0, а ”не знаю” соответствует априорной вероятности,
задаваемой конструктором.
Во втором классе вопросов, применяемых системой, пользователь в своем ответе
использует шкалу от +5 до —5.
На этой шкале +5 эквивалентно ”да” (или вероятности 1), —5 эквивалентно ’’нет” (или нулевой вероятности), а 0 эквивалентно ”не знаю” (т.е. априорной вероятности).
Промежуточные значения обозначают степени уверенности в истинности или ложности утверждения вопроса.
Например, ответ 4 может интерпретироваться как ’’очень вероятно” , —2 как
’’вероятно нет” , и т.д. Такие промежуточные значения система путем линейной интерполяции переводит в вероятности.
В том виде, в каком описана система, она опирается исключительно на вероятности.
Однако во многих моделях существуют такие участки, где наиболее естественно задавать вопросы, ответы на которые могут выражаться в виде числа.

Для того чтобы хорошо сочетать численные вопросы с системой нужен какой-то способ преобразования чисел в вероятности некоторым контролируемым образом. Для этого предлагается использовать два типа правил. Они называются ’’Диапазон” и ’’Модуль”. В математике эти типы операторов носят название функций принадлежности для нечетких множеств.
Предположим, что в модели имеется вопрос: ’ ’Дайте возраст больного в годах”, требуется утверждение, говорящее, что ’’больной является старым” и что в данный момент определили ’’старый” следующим образом: всякий моложе 60 лет безусловно не стар, старше 70 — является старым, а в отношении лиц между 60 и 70 годами не уверены что старые . Можно было бы написать два следующих правила:
Правило старый-больной ’’Больной является старым” Диапазон возраст-больного 60 70
Вопрос возраст-больного ’’Возраст больного в годах” Число 0 120
Модуль является аналогичной функцией, два параметра которой соответствуют среднему значению и допуску. Например, предположим, что температура некоторой химической реакции должна быть равна 80 градусам, причем допускается отклонение плюс-минус 5 градусов. Иногда можно написать такое правило:
Правило верная температура ’’Температура верная” Модуль Показание-температуры 80 5
Вычисления будут производиться следующим образом:
Если показание равно 80, то вероятность верная-температура равна 1.
Если показание меньше 75 или больше 85, то вероятность верная-температура равна 0. Для каждой промежуточной величины показания верная-температура вероятность находится в результате линейной интерполяции.
а)
б)
Рис. 3. Графики функций принадлежности типа ’’диапазон” (а) и ’’модуль” (б )
На рис. 3 приведены примеры соответствующих графиков. Имеется возможность строить более сложные функции принадлежности, используя диапазон и модуль как базовые строительные блоки.
Допустим, что описанные правила обеспечивают реализацию все функций, которые необходимы для логического определения модели проектируемой экспертной системы.
Однако ЭС должна иметь определенные средства управления порядком задания вопросов, а также иметь средства указывать, что при определенных обстоятельствах некоторые вопросы следует считать не относящимися к делу.
В [Фил Кокс] указывается, что существуют обстоятельства, при которых пользователю было бы очень неудобно, чтобы система задавала вопросы в том порядке, который
представляется ей удобным.
Второе требование заключается в том, чтобы иметь возможность указать системе, что некоторые вопросы уместны лишь при определенных обстоятельствах.
Если посмотрим на рис.4, то увидим, что он отличается от рис.2 добавлением прямоугольника, в котором содержатся слова: ’’Есть ли у Вас зонтик”; этот прямоугольник подсоединяется к целевому посредством штриховой стрелки, с пометкой: ’’Вам следует взять с собой зонтик” .
Около этой стрелки указаны два числа 1,5. Они означают, что, прежде чем будет предпринята какая-либо попытка выяснить, следует ли вам брать с собой зонтик, необходимо ответить на вопрос: ’’Есть ли у Вас зонтик”. Ответ должен лежать в диапазоне 1 5, означающем положительное утверждение.
Это записывается на языке правил с использованием ключевого слова ’’блокировка” и получило название блокирующего фактора.
Целевое правило модели, изображенной на рис. 4, записывается так:
Цель взять-зонтик ’’Вам следует взять с собой зонтик” Блокировка иметь-зонтик 1 5 Или дождь будет-идти
Этот простой механизм позволит осуществить все виды контроля порядка задания вопросов, описанные выше.
Рис. 4. Использование блокирующего фактора в базе правил на рис. 1, 2
На практике в процессе функционирования модели ЭС часто выдвигаются некоторые уникальные требования, которые не могут быть удовлетворены в том варианте системы, который был рассмотрен. Поэтому в модель ЭС включается средство, позволяющее пользователю писать внешние функции или внешние вопросы. Они представляют собой процедуры, составляемые конструктором модели и подсоединяемые к системе на этапе ее работы.
Внешняя функция представляет собой правило, содержащее определенную пользователем процедуру для вычисления текущего значения, исходя из значений влияющих на него факторов.
Например, в некоторых обстоятельствах пользователь может решить, что принятая в системе процедура вычисления нечеткого И как минимума из вероятностей влияющих факторов — это не то, что ему требуется.
Пользователь, возможно, предпочитает вычислить И как произведение вероятностей факторов. Это легко можно сделать с помощью внешней функции.
Внешние функции могут быть как вероятностными, так и числовыми. Использование внешних функций в ЭС предоставляет возможность для реализовать специализированных функций принадлежности для нечетких множеств, например упомянутой выше колоколообразной кривой.
Для понимания принципа работы программы системы рассмотрим, как расположены знания в ее основной памяти.
Память, взятая из неупорядоченного массива, состоит из двух типов записей, прямоугольников и стрелок. На рис.5 показан пример с зонтиком, так как он физически расположен в машине.
Записи для прямоугольников содержат лишь указатели, идущие к текстовому файлу. Имеется также массив указателей, ведущих ко всем целям модели. Этим обеспечивается начальный доступ к деревьям, которые образуют модель.
В каждой записи для прямоугольника имеется два действительных числа — текущая вероятность и априорная вероятность гипотезы, которую этот прямоугольник представляет.
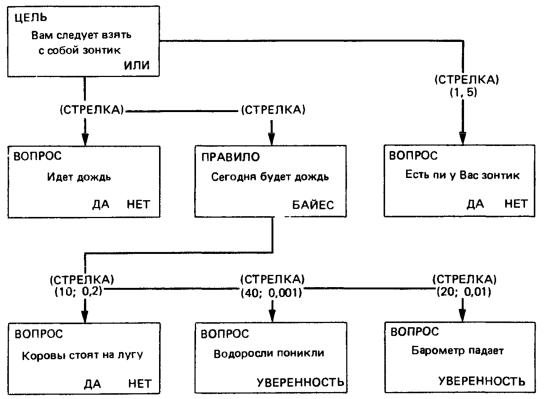
Рис. 5. Фактическое представление примера базы правил в памяти ЭВМ
Кроме того, там есть два указателя.
Первый из них указывает на начало цепочки из записей для стрелок, которые связывают его с влияющими на него факторами.
Второй указывает на другую цепочку записей для стрелок, которые, в свою очередь, указывают на блокирующие факторы для этого правила.
В записи имеются также два числа, указывающие на ассоциируемый текст из текстового файла для этой модели, на некоторые булевы флаги, отражающие текущее состояние прямоугольника, например ’’блокирован” , ’’получает ответ” и т.д.
Каждая запись для стрелки имеет два указателя.
Первый указывает на следующую за ней запись для стрелки в той цепочке, к которой она относится.
Другой указатель показывает на влияющий или блокирующий фактор.
В записи для стрелок также отведено место паре чисел. В них могут содержаться константы ЛД и ЛН, а если требуется — то константы области блокировки, которые ассоциированы с этой стрелкой.
Метод работы состоит в просмотре дерева, пока не встретится вопрос, на который нет ответа. Вопрос выдается на дисплей, а ответ поступает в поле текущей вероятности.
Затем вероятности всех прямоугольников на дереве пересчитываются. Этот процесс продолжается до тех пор, пока не будет прерван пользователем или пока все вопросы не окажутся исчерпаны.
Результаты трассировки на дисплей выводятся в виде обычного текста.
Например:
Текущий вопрос состоит в том, поникли водоросли или нет. Истинность утверждения, что водоросли поникли, существенно подкрепляет утверждение, что будет дождь, а ложность существенно противоречит ему.
По мере того как получаются ответы на вопросы, возникающие по пути к этой цели,
верхняя и нижняя границы для вероятностей будут изменяться.
Нижняя граница будет расти, а верхняя — падать. Когда будут получены ответы на все уместные вопросы, то верхняя и нижняя границы сольются, дав общее значение вероятности для этой цели.
В большинстве случаев пользователь не пытается найти точные значения вероятностей для всех целей в модели. Как правило, ему хочется знать, какие утверждения являются истинными с наибольшей вероятностью или какой образ действия имеет большую вероятность успеха.
Время от времени пользователь может смотреть на ’’гистограмму” и решать, в какой момент он достиг удовлетворяющей его точности.