

Міністерство освіти і науки України
Національний університет “Львівська політехніка”
Кафедра “Інформаційні системи і мережі”
Основні принципи оцифрування та Перетворення тексту з твердих носіїв в електронний вигляд за допомогою системи оптичного розпізнавання символів FineReader
Методичні вказівки до лабораторної роботи
з курсу
для студентів
спеціальності
Затверджено на засіданні кафедри
“Інформаційні системи і мережі”
Протокол № _____
від “___” __________
Львів - 2014
Укладачі
Відповідальний за випускЛитвин В.В., д.т.н., проф.
Мета роботи. Ознайомитися та на практиці засвоїти основні принципи введення (оцифрування) та перетворення текстової інформації з твердого носія в електронний вигляд з допомогою системи оптичного розпізнавання символів FineReader. Провести загальне ознайомлення з пакетами мовного розпізнавання тексту та підготувати отримані матеріали для публікації (на прикладі Вісника каф. ІСМ), виконавши аналіз певної предметної області.
Короткі Теоретичні відомості
Будь-який текст, перш ніж його опрацьовувати, потрібно ввести в комп’ютер. Окрім традиційного введення тексту за допомогою клавіатури застосовують методику оцифрування з твердого носія з подальшим оптичним розпізнаванням символів, адже введення символів «вручну» може бути надто трудоємним або пов’язаним з певними труднощами. Останнім часом шаленої популярності починають набувати програмні пакети мовного введення та розпізнавання тексту (наприклад DragonNaturallySpeakingPersonalEdition 1.0 і Диктант 2.5). Але такі пакети знаходяться на стадії вдосконалення та працюють переважно з англійськомовним матеріалом.
Для оцифрування інформації з твердого носія в електронний вигляд використовують цифрові фотографічні пристрої (камери в мобільних телефонах, компактні фотокамери без змінної оптики та традиційні дзеркальні камери (рис. 1) а також сканер. Для розпізнавання призначені професійні спеціалізовані пакети для оптичного розпізнавання символів, наприклад FineReader(додається на носіях разом з сканером (рис. 2) або демо-версія на сайті виробника).
Розглянемо детальніше узагальнено будову та основні принципи оцифрування зображень з подомогою фотографічних пристроїв. Всіх їх об’єднує наявність системи лінз (об’єктив), світлочутливого елементу (матриця, яка прийшла на зміну класичній фотоплівці (рис. 2) танавіпед– пристрій для налаштування параметрів зйомки (можуть бути на корпусі або зображені графічно на дисплеї самого апарату (рис. 1). Функція навіпеду – це оперативне керування камерою в різних режимах, наприклад, макрозйомки а також для перегляду фотографій і вибору тих, які слід видалити.



Рис. 1. Фотокамера мобільного телефону, компакт, дзеркальна камера із змінною оптикою та пристрій для налаштування параметрів зйомки (навіпед)


Рис. 2. Світлочутлива матриця та сканер
Світлочутлива матриця (рис. 2) – це мікросхема з міліонами світлочутливих елементів, число яких визначає роздільну здатність камери. Наприклад, мільйон – 1 мегапіксель, 2 мільйони – 2 мегапікселя і т.д.. В компактних камерах, як правило, застосовуютьCCD- матриці невеликого розміру (дуже розповсюджений формат 1.1/8 дюймів має діагональ всього 10 мм.!), які переважають всім, крім одного – при встановленні чутливості на рівні 400 одиницьISOі більше вони дають зображення з помітним цифровим шумом (рис. 3). В дзеркальних апаратах застосовують матриці великого розміру (виготовлені за іншою технологією –CMOS- матриці), які навіть при високій чутливості порядку 800ISOдають мінімальний рівень шумів (рис. 3).


Рис. 3. Рівень цифрового шуму на зображенні з дзеркальної камери та компактної
Для оцифрування текстових документів краще надати перевагу фотокамерам, які будуть забезпечувати невисокий рівень шуму, мають можливість оптичного (не цифрового) масштабування (зум-об’єктив), стабілізації зображення (для отрмання чіткіших, не розмитих зображень) а також наявність відповідних режимів зйомки (наприклад режим «Текст» чи «Макро»).
Сканер(англ.scanner) — пристрій, призначений для створення зображень певних об'єктів (оцифрування) шляхом опрацювання променів, які відбиваються від поверхні об'єкта (рис. 2). Процес отримання зображення називаютьскануванням. В основі принципу дії комп'ютерних сканерів є застосування фотоелементів у вигляді лінійки або матриці світлочутливих сенсорів для перетворення сигналів, отриманих в результаті відбиття світла від оригіналу (рис. 4).

Рис. 4. Принцип дії сканера
Найбільш поширеними моделями є планшетні сканери, в яких сканований об'єкт розміщують на склі планшета сканованою поверхнею вниз. Під склом розташовується рухома лампа, її переміщення забезпечує кроковий електродвигун.Світло, відбите від об'єкта, через системудзеркалпотрапляє на лінійку спеціальних фотоприймачів. Значення вихідних напруг лінійки фотоприймачів через комутатор подають на аналогов0-цифровий перетворювач (АЦП). Цифрові коди такого перетворення передаються у комп'ютер. За кожен крок двигуна сканується частинка об'єкта, що потім поєднуєтьсяпрограмним забезпеченнямдрайвера сканера у загальне зображення.
Якість сканованого зображення визначається багатьма чинниками. Серед них - тип сканованого оригіналу, технічні можливості сканера, розмір оригіналу, від якого залежить необхідна кратність збільшення, роздільна здатність при скануванні, а також особливості будь-якого опрацювання, який застосовується до зображення в ході сканування. Одним із найважливіших параметрів є Роздільна здатність. При скануванні оригінал розбивається на окремі частини однакового розміру — піксели. Багато авторів, згадуючи про роздільну здатність сканерів, говорять, наприклад: роздільна здатність 600 крапок на дюйм (dpi – dot per inch). В процесі сканування кожному пікселові присвоюється своя адреса і цифрове значення, що відповідає рівню сірого півтону, зареєстрованого елементом зчитування. Ця операція називається оцифруванням. Оцифрування, наприклад, штрихових оригіналів, порівняно проста операція. В процесі сканування піксел може бути або білим, або чорним. Однак і тут може мати місце втрата інформації. Наприклад, піксел містить 50% білого і 50% чорного, тоді потрібно вибирати щось одне. Це призводить до появи ефекту «зубчастості» в сканованому зображенні.
Наступний якісний показник — глибина кольору, котра і визначає кількість розпізнаних півтонів або кольорів. Глибина кольору — це кількість біт, які сканер може призначити для сканованого піксела. Сканер з глибиною 1 біт може реєструвати тільки два рівні — білий і чорний, сканер з глибиною точки 8 бітів може реєструвати 256 рівнів, 12 бітів — 4096 рівнів. Для найбільш якісних поліграфічних робіт достатньо сканера з глибиною точки 13-14 бітів, що, в свою чергу, дозволяє відтворити більше 1 млрд. кольорових відтінків. Проте слід пам’ятати, що після сканування отримані значення програмне оптимізуються, внаслідок чого зображення зберігається і опрацьовується, як 8-бітне (24-бітний формат true color).
Режими виконання операції сканування поділяють на чотири групи, в залежності від типу оригіналу, який підлягає скануванню:
для штрихових рисунків — режим Line Art;
для зображення в градаціях сірого — режим Greyscale;
для півтонового зображення — режим Halftones;
для кольорового зображення — Color в режимах RGB або CMYK.
Для керування роботи сканером необхідна відповідна програма-драйвер. До недавнього часу кожний драйвер для сканера мав свій власний інтерфейс. Це досить незручно, тому що для кожної моделі необхідна своя програма-оболонка. Ситуація змінилась при запровадженні протоколу TWAIN (Technology without an imported name — технологія без влаштованого імені), стандарту, при якому будь-яка програма може обмінюватись даними з будь-якою моделлю сканера. Виділяють декілька основних питань, які вирішуються при використанні даного протоколу: підтримка різних платформ комп’ютерів, підтримка різноманітних пристроїв вводу інформації, в тому числі відеоінформації, можливість роботи з різними форматами даних. В комплекті зі сканерами, як правило, постачається відповідне програмне забезпечення. Наприклад, додаткові модулі для Adobe PhotoShop, які роблять простішими сканування в адитивній моделі кольору RGB, виконують в процесі сканування перетворення зображення в поліграфічний CMYK-формат. А з допомогою пакету FineReader оцифрований документ можна розпізнати.
Класична система для оптичного розпізнавання символів (OCR‑cистема) – це комп’ютерна система, яка дозволяє перетворювати отримане зі сканера графічне зображення сторінок в електронний текстовий файл, який може бути потім опрацьований у текстовому редакторі.
Центральною проблемою розпізнавання є ідентифікація символів [3]. У перших системах для оптичного розпізнавання символів використовувався наступний алгоритм. Усім символам алфавіту ставились у відповідність матриці-еталони, які задавали розміщення темних та світлих крапок. Кожний символ зісканованого документу порівнювався з усіма еталонами. Якщо він виявлявся досить подібним на один із них (тобто відсоток співпадіння крапок зісканованого символу з крапками еталону є більше деякого порогового значення), то вважалося, що розпізнавання символу відбулося – гарантовано або умовно, в залежності від степеня співпадіння. в протилежному випадку, система для оптичного розпізнавання символів приймала рішення про неможливість ідентифікації.
Такі системи називаються шрифтовими системами (англійський термін multifont). Основна перевага алгоритму, який в них використовується — це простота реалізації. Однак його суттєвий недолік полягає в тому, що існують десятки різноманітних шрифтів, і система для оптичного розпізнавання символів повинна мати велику базу даних, яка містить накреслення символів для кожного з них. Крім того, такі системи не здатні розпізнавати нові шрифти, а нерідко навіть різні друкуючі машинки однієї марки мають свій, індивідуальний «почерк».
Системи для оптичного розпізнавання символів іншого класу, які називають омніфонтовими(шрифтонезалежними) системами, використовують в якості еталона порівняння евристичні правила накреслення символів, які не залежать від шрифту. На жаль, системи даного класу гірше працюють з текстами низької якості. Як відомо, висока якість не завжди властива вітчизняним документам. Тому російським та українським розробникам омніфонт-систем довелось немало попрацювати над власними алгоритмічними базами, які дозволяли б працювати з текстами в поганому поліграфічному виконанні.
Новим етапом розвитку омніфонт-систем стали інтелектуальні системидля оптичного розпізнавання символів [4].FineReader— омніфонтова система оптичного розпізнавання текстів (рис. 5). Це означає, що вона дозволяє розпізнавати тексти, набрані практично будь-якими шрифтами, без попереднього навчання. Особливістю програми FineReader є висока точність розпізнавання і мала чутливість до дефектів друку, що досягається завдяки застосуванню технології "цілісного цілеспрямованого адаптивного розпізнавання".
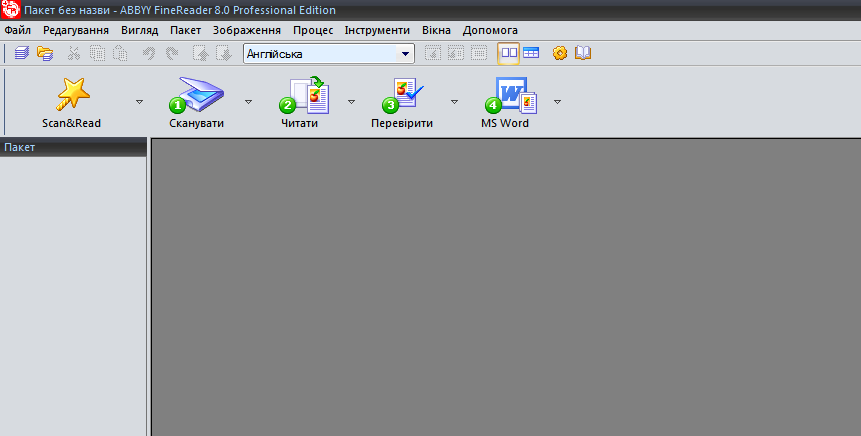
Рис. 5. Робоче вікно програми FineReader
Процес уведення документа в комп'ютер можна підрозділити на три етапи:
1. Сканування. На першому етапі сканер "переглядає" зображення і передає його в комп'ютер (рис. 6). Фактично відбувається ініціювання двох операцій - автоматичного аналізу макету сторінки і власне розпізнавання. Під час аналізу макету програма виділяє на сторінці табличні і текстові блоки, блоки зображень і так далі, готуючи таким чином сторінку до розпізнавання. Також можна провести автоматичний аналіз сторінок за допомогою командиПроцес – Розпізнати – Аналіз макета сторінки(сторінок), а після розбиття трохи відкоригувати блоки уручну. Як правило, при обробці зображення виділяють блоки наступних типів:
• Зона Розпізнавання- блок, використовуваний для розпізнавання і автоматичного аналізу частини зображення. Після клацання на кнопці2 виділений блок автоматично аналізується і розпізнається.
• Текст- блок, використовуваний для позначення тексту. Він повинен містити тільки одну колонку тексту. Якщо усередині тексту містяться картинки, вони виділяються окремими блоками.

Рис. 6. Вікно Зображення із зменшеною копією листа-оригіналу, яке з’явилося після натиснення кнопки Сканувати
• Таблиця- блок, що позначає таблицю або текст табличної структури. При розпізнаванні програма розбиває такий блок на рядки і стовпці і формує табличну структуру. У вихідному тексті даний блок передається як таблиця.
• Зображення- блок, використовуваний для позначення графічних зображень. Може містити картинку або будь-яку іншу частину тексту, яку ви хочете передати в розпізнаний текст як зображення.
• Штрих-код(тільки у версіїOffice) - блок для розпізнаванняштрих-кодів. Якщо документ містить штрих-код, то не обов'язкове передавати його як зображення; за допомогою блоку Штрих-код його можна перевести в послідовність букв і цифр. За замовчанням опція розпізнавання штрих-кода не встановлена. Щоб підключити її, на вкладціРозпізнаваннявікнаОпціївідзначте параметрШукати штрих-коди.
Залежно від налаштувань, різні блоки виділяються рамками різних кольорів і нумеруються. Переконайтеся, чи правильно FineReaderвизначив межі блоків і розпізнав їх типи. Обов'язково повірте, щоб в полі із спискомМоварозпізнаваннябула виставлена мова (або мови) вашого документа. Можна вибрати декілька мов одночасно.
Розпізнавання. Опрацювання зображення OCR-системою.
Зупинимося на другому кроці більш докладно. Викликається натиснення на кнопці Розпізнати (Читати), і блоки на сторінці почнуть поступово забарвлюватися, а на передньому плані з’явиться вікноРозпізнаванняз кнопкоюЗупинити, що відображає динаміку процесу. При розпізнаванні може з'явитися віконце попередженнями, наприклад, про неправильний вибір яскравості сканування або мови розпізнаваного тексту. Якщо якість сканування не дозволить правильно розпізнати текст, то можна відсканувати його повторно, скориставшись приведеними порадами. Якщо і це не принесе бажаного результату, скан покращують засобами спеціальних графічних редакторів (Лабор. Робота №3). Після розпізнавання панель розбиття на блоки зникає, з’являється сторінка з текстом. Наступний крок - перевірка. Тут можна просто перечитати і виправити текст, можна переглянути виділені кольором невпевнено розпізнані слова чилітери, виправити їх за допомогою словника або вікнаКрупний план(область внизу вікна з текстом). Можете на якийсь час відкласти виконання цього етапу і перевірити документ засобами іншого редактора, але для цього документ доведетьсяЗберегти(натиснути кнопку 4). За замовчуванням з'явиться Майстер збереження результатів, що питає, в якому ж вигляді зберігати результат. При цьому пропонується велика кількість варіантів.Відредагований текст можнаЗберегти у файл,при цьому буде величезний вибір варіантів, які згодом иожна використовувати в різних застосуваннях (*.rtf, *.pdf, *.dbf, *.html, *.xls, *.txt). Для цього потрібно вибрати командуЗберегтиу менюФайл.
Якщо потрібно передати розпізнаний текст в конкретний додаток, для подальшого редагування, слід вказати, наприклад, передати документ в Microsoft Word або Microsoft Excel. Система автоматично запустить вибране застосування з текстом, отриманим після розпізнавання.
Як уже згадувалося, розпізнавання зображення здійснюється на основі технології "цілісного цілеспрямованого адаптивного розпізнавання".
Цілісність- об'єкт описується як ціле за допомогою значимих елементів і відносин між ними.
Цілеспрямованість- розпізнавання будується як процес висування і цілеспрямованої перевірки гіпотез.
Адаптивність- здатність OCR-системи до самонавчання.
Останнім часом великої популярності, особливо в мобільних системах, набувають пакети програм мовного розпізнавання тексту. Окрім звиклих сервісів для перекладу від пошуковикаGoogle та різноманітних навігаційних систем, в яких керування виконується голосовими командами, популярними є пакети мовного розпізнавання текстуDragonNaturallySpeakingPersonalEditionіДиктант 2.5. В межах даної роботи ознайомитися з цими пакетами можна оглядово, використовуючи демонстраційні версії цих програм із сайту розробників.