

курсовая работа / Курсовая работа
.docx
ВСТУП
У нашому нелегкому житті розробка ефективних алгоритмів займає значну роль при вирішенні різного роду задач за допомогою електронних обчислювальних машин (ЕОМ). У відсотковому відношенні етап розробки алгоритмів займає приблизно 20% всього часу повного вирішення завдання. Цей етап є найбільш відповідальним, оскільки алгоритмічні помилки дуже часто важко виявити і виправити, в окремих випадках набагато простіше написати новий алгоритм і програму, ніж виправити існуючу. Зараз за допомогою алгоритмів вирішуються не тільки обчислювальні, а й багато прикладних завдань.
Алгоритм - це точний припис, що визначає обчислювальний процес, що веде від варійованих вихідних даних до шуканого результату. Саме слово «алгоритм» походить від латинської форми написання імені великого математика IX століття Аль Хорезмі (Мухаммеда ібн Муса аль Horesmi), який сформулював правила виконання арифметичних дій. Спочатку під алгоритмом і розуміли тільки правила виконання чотирьох арифметичних дій над багатозначними числами, а в подальшому це поняття стало використовуватися для позначення послідовності дій, що призводять до вирішення поставленого завдання. Призначення алгоритмів полягає в поясненні послідовності ходу виконання кроків для вирішення конкретного завдання.
Найбільш простий і універсальною формою представлення алгоритму є словесне опис, який містить записану на природній мові (точніше на підмножині природної мови) послідовність приписів. Виконання алгоритму передбачається в природній послідовності, тобто в порядку запису. При необхідності змінити порядок виконання приписів в явній формі вказується, яка припис належить виконати наступним. Таку словесну запись алгоритму називають псевдокоді, підкреслюючи цим її проміжне становище між нашою природною мовою і зрозумілим для комп'ютера мовою програм. Гідність псевдокоді є їх універсальність, а до недоліків можна віднести малу наочність запису.
Наочністю володіє інша форма запису - графічна схема алгоритму, або блок - схема. Така сема є графічний документ, який дає уявлення про порядок роботи алгоритму. Тут приписи мають вигляд різних геометричних фігур, а послідовність виконання операцій відображається за допомогою ліній, що з'єднує ці фігури. Умовні позначення, які застосовуються при складанні граф-схем алгоритмів, і правила виконання визначені в ГОСТ 19.701-90 (ИСО 5807-85) «Схеми алгоритмів, програм, даних і систем. Умовні позначення і правила виконання ». Недоліком графічних схем алгоритмів є громіздкість. Для вирішення спеціальних завдань, наприклад проектування обчислювальних пристроїв, застосовуються інші способи завдання алгоритмів, такі, як логічні (операторні) і матричні схеми. Їх перевагами є компактність і простота подальшої формалізації, а недоліком - мала наочність.
Курсова робота складається з трьох частин:
1) вибір варіанта завдання;
2) розробка алгоритму покриття;
3) розробка алгоритму сортування;
При розробці відповідних алгоритмів намагатися отримати більш ефективне рішення, опис алгоритмів виконувати у вигляді блок - схем з коментарями в тексті.
1. ВИБІР ВАРІАНТА ЗАВДАННЯ
1.1. Порядковий номер моєї групи (АЕ-113) дорівнює 3, мій порядковий номер у списку групи дорівнює 03, отже моє індивідуальне число Y = 3 * 100 +3 = 303.
1.2. Мій варіант алгоритму покриття визначається як залишок від ділення мого індивідуального числа Y на 4: А = (Y mod 4)+1 = (303 mod 4)+1 = 4, отже, розроблюваний алгоритм є за методом "мінімальний стовпець – максимальний рядок".
1.3. Мій варіант алгоритму сортування визначається як залишок від ділення мого індивідуального числа на Y на 5: С = (Y mod 5)+1 = (303 mod 5)+1 = 4, отже, що розробляється алгоритм є сортування простим обміном (бульбашкове сортування).
2. АЛГОРИТМ ПОКРИТТЯ ЗА МЕТОДОМ “МІНІМАЛЬНІЙ СТОВПЕЦ — МАКСИМАЛЬНИЙ РЯДОК”
2.1.
Математичний опис завдання та
методи
її вирішення. Нехай
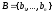 -
опорна
множина.
Є безліч підмножин
-
опорна
множина.
Є безліч підмножин
 множини
B (
множини
B ( ).
Кожній
підмножині
).
Кожній
підмножині
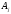 зіставлять
число
зіставлять
число
 ,
названою
ціною. Множина
,
названою
ціною. Множина
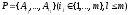 називається рішенням задачі про покриття,
або просто покриттям, якщо виконується
умова
називається рішенням задачі про покриття,
або просто покриттям, якщо виконується
умова
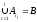 ,
при цьому ціна
,
при цьому ціна
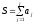 .
Термін «покриття» означає, що сукупність
множин
.
Термін «покриття» означає, що сукупність
множин
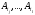 містить
всі елементи множини В, тобто «покриває»
безліч B.
містить
всі елементи множини В, тобто «покриває»
безліч B.
Безнадлишковим називається покриття, якщо при видаленні з нього хоча б одного елемента воно перестає бути покриттям. Інакше - покриття надлишкове.
Покриття
Р називається мінімальним, якщо його
ціна
 -
найменша серед всіх покриттів даного
завдання.
-
найменша серед всіх покриттів даного
завдання.
Покриття Р називається найкоротшим, якщо l - найменше серед всіх покриттів даного завдання.
Зручним
і наочним поданням вихідних даних та
їх перетворень в задачі про покриття є
таблиця покриттів. Таблиця покриттів
- це матриця Т відносини приналежності
елементів множин
 опорному
безлічі В. Стовпці матриці зіставлені
елементам множини В, рядки - елементам
множини
опорному
безлічі В. Стовпці матриці зіставлені
елементам множини В, рядки - елементам
множини
А:
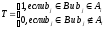
Нулі в матриці T не проставляються.
Є такі варіанти формулювання задачі про покриття:
1) Потрібно знайти всі покриття. Для вирішення завдання необхідно виконати повний перебір всіх підмножин множини А.
2) Потрібно знайти тільки беззбиткові покриття. Не існує простого і ефективного алгоритму, що не вимагає побудови всіх надлишкових покриттів: добре, якщо зменшується їх кількість. (Використовується граничний перебір або розкладання по стовпцю в ТП).
Потрібно знайти одне безнадлишкове покриття. Рішення завдання грунтується на скороченні таблиці.
Завдання про покриття можуть бути вирішені точно (при невеликій розмірності) або наближено.
Для знаходження точного рішення використовуються такі алгоритми.
1) Алгоритм повного перебору. (Заснований на методі впорядкування перебору підмножин множини А).
2) Алгоритм граничного перебору по увігнутому безлічі. (Заснований на однойменному методі скорочення перебору).
3) Алгоритм розкладання по стовпцю таблиці покриття. Заснований на методі скорочення перебору, який полягає в розгляді тільки тих рядків таблиці покриття, в яких є "1" в обраному для розкладання стовпці.
4) Алгоритм скорочення таблиці покриття. Заснований на методі побудови циклічного залишку таблиці покриття, для якого далі покриття будується методами граничного перебору або розкладання по стовпцю.
Наближене рішення задачі про покриття засноване на наступному міркуванні. Якщо навіть скорочений перебір призводить до дуже трудомісткого процесу рішення, то для отримання відповіді доводиться відмовлятися від гарантій побудови оптимального рішення (мінімального або найкоротшого); проте доцільно отримати не найгірший результат - хоча б безизбиточное покриття, задовольняє необхідній умові. При цьому на шкоду якості можна значно спростити процес рішення.
Алгоритм побудови покриття, близького до найкоротшим, заснований на методі мінімального стовпця - максимальної рядка.
2.2. Словесний опис алгоритму і його роботи. Покриття, близьке до найкоротшим, дає алгоритм перетворення таблиці покриттів - «мінімальний стовпець - максимальна рядок»:
1) Вихідна таблиця вважається поточної перетворюваної таблицею покриттів, безліч рядків покриттів - порожньо.
2) У поточній таблиці виділяється стовпець з найменшим числом одиниць. Серед рядків, що містять одиниці в цьому стовпці, виділяється одна з найбільшим числом одиниць. Цей рядок включається до покриття, поточна таблиця скорочується викреслюванням всіх стовпців, в яких обрана рядок має одиницю, якщо в таблиці є не викреслені стовпчики, то виконується п.2, інакше - покриття побудовано. При підрахунку кількості одиниць в рядку враховуються одиниці в не викреслених стовпцях.
Тому алгоритм роботи наступний:
1) введення числа рядків і стовпців таблиці покриття;
2) введення таблиці покриття;
3) пошук стовпця з найменшим числом одиниць. Якщо воно дорівнює 0, то п.5. Інакше, пошук рядка серед рядків, що містять одиниці в цьому стовпці, з найбільшим числом одиниць. Цей рядок включається до покриття.
4) викреслення стовпців, що містять одиницю в максимальній рядку, - проводиться шляхом присвоєння даному стовпцю мітки «1» в нульовий рядку. Перехід в п.4.
5) висновок безлічі покриття, кінець алгоритму.
2.3. Вибір структур даних. З аналізу задачі і її даних видно, що алгоритм повинен працювати з таблицею покриття і з деякими змінними, які представлені нижче (всі змінні цілого типу):
M - кількість рядків таблиці покриття;
N - кількість стовпців таблиці покриття;
Sum – сума одиниць у кожному стовпці;
MCS – кількість одиниць у мінімальному стовпці;
MCN – номер мінімального стовпця
I, J - змінні циклу по рядках і стовпцях відповідно;
Таблиця покриття - це двовимірна матриця. Її доцільно представити у вигляді двовимірного масиву (N +1, M). Кількість рядків збільшено на одну для
проставлення позначок викреслених стовпців. P - одномірний масив для зберігання номерів рядків, що покривають матрицю. Для зберігання номерів обраний масив, оскільки кількість рядків, хоча й невідомо заздалегідь, обмежена кількістю рядків матриці покриття (M).
2.4. Опис схеми алгоритму. Блок-схема даного алгоритму зображена на рис. у додатку 1.
Спочатку вводяться вихідні дані: розмірність таблиці m и n і сама таблиця покриття (блок 1). Далі знаходять нульові стовпці та рядки та викреслюють їх х покриття. Потім знаходять сумму одиниць у кожному стовпці і кожному рядку (блок 2). Після цього знаходимо мінімальний стовпець(блок 3). Потім знаходиться максимальний рядок узалежності від найденого мінімального стовпця(блок 4). Після цього вносимо необхідний рядок до покриття(блок 5), викреслюємо необхідні стовпці та рядки і перебудовуємо покриття(блок 6). Якщо ж всі стовпці викреслені, то випливає висновок знайденого найкоротшого покриття у вигляді номерів рядків, що покривають таблицю. Потім кінець алгоритму.
2.5. Підпрограми основного алгоритму. Функція Perebor знаходить суму одиниць у всіх стовпцях і рядках покриття (Рис. 2). Якщо сума одиниць у кожному стовпці та рядку дорівнює нулю, то алгоритм припиняє свою роботу. Функція Min_column знаходить мінімальний стовпець шляхом порівняння сум одиниць у кожному ствопці. Якщо є декілька мінімальних стовпів(тобто з однаковою сумою одиниць), то вибирають перший стовпець. Функція Max_row знаходить максимальний рядок шляхом порівняння сум одиниць у кожному рядку. Якщо є декілька максимальних рядків, то вибирають перший максимальний рядок. Функція Build_cover запам’ятовує рядки, які будуть покриттям, у кінці роботи алгоритму ми побачимо номера рядків покриття. Функція Erase_column видаляє мінімальний стовпець, максимальний рядок та усі стовпці, в яких рядок має одиницю. Рядки та стовпці будуть видалятися до тих пір, поки не буде знайдене покриття.
2.6. Приклад роботи алгоритму.
Нехай задана таблиця покриттів (див. Таб. 2). Розглянемо приклад роботи алгоритму.
1. Perebor
Таб. 2. (пример)
1) j=1, i=1, A[1,1]≠0
|
A |
1 |
2 |
3 |
4 |
5 |
|
A1 |
1 |
1 |
|
1 |
|
|
A2 |
1 |
|
1 |
|
1 |
|
A3 |
1 |
1 |
|
1 |
|
|
A4 |
|
|
|
1 |
1
|
2) j=2, i=1, A[1,2]≠0
3) j=3, i=1, A[1,3]=0, i<m
i=2, A[2,3] ≠0
4) j=4, i=1, A[1,4] ≠0
5) j=5, i=1, A[1,5]=0, i<m
i=2, A[2,5] ≠0
-
j=n, возврат 1.
2. Min_column
0) SUMpred= n
1) j=1, A[0,j] ≠1
SUMtek=3
SUMtek≤ SUMpred→ SUMpred= SUMtek, min_stlb=1
2) j=2, A[0,j] ≠1
SUMtek=2
SUMtek≤ SUMpred→ SUMpred= SUMtek, min_stlb=2
3) j=3, A[0,j] ≠1
SUMtek=1
SUMtek≤ SUMpred→ SUMpred= SUMtek, min_stlb=3
4) j=4, A[0,j] ≠1
SUMtek=3
SUMtek!≤ SUMpred
5) j=5, A[0,j] ≠1
SUMtek=2
SUMtek!≤ SUMpred
6) j=n, конец цикла
-
возврат min_stlb=3
3. Max_row
0) SUMpred=0
1) i=1, A[1, 3] ≠1
2) i=2, A[2,3]=1
SUMtek=3
SUMtek ≥SUMpred→ SUMpred= SUMtek, max_str=2
3) i=3, A[3,3] ≠1
4) i=4, A[4,3] ≠1
5) i=m, конец цикла
-
возврат max_str=2
5. Erase_columns
1) j=1
A[2,1]=1
A[0,1]=1
2) j=2
A[2,2] ≠1
3) j=3
A[2,3]=1
A[0,3]=1
4) j=1
A[2,4] ≠1
5) j=5
A[2,5]=1
A[0,5]=1
6) j=n, конец цикла
7) j=1…n
A[0,2] ≠1→ MIN_STLB(A)
3. Min_column
0) SUMpred=n
1) j=1, A[0,j]=1
2) j=2, A[0,j] ≠1
SUMtek=2
SUMtek≤ SUMpred→ SUMpred= SUMtek, min_stlb=2
3) j=3, A[0,3]=1
4) j=4, A[0,j] ≠1
SUMtek=3
SUMtek!≤ SUMpred
5) j=5, A[0,5]=1
6) j=n, конец цикла
7) возврат min_stlb=2
3. Max_row
0) SUMpred=0
1) i=1, A[1,2]=1
SUMtek=3
SUMtek ≥SUMpred→ SUMpred= SUMtek, max_str=1
2) i=2, A[2, 2] ≠1
3) i=3, A[3,2]=1
SUMtek=3
SUMtek ≥SUMpred→ SUMpred= SUMtek, max_str=3
4) i=4, A[
4, 2] ≠1
5) i=m, конец цикла
6) возврат max_str=3
4. P[3]=1
5. Erase_columns
1) j=1
A[3,1]=1
A[0,1]=1
2) j=2
A[3,2]=1
A[0,2]=1
3) j=3
A[3,3]≠1
4) j=4
A[3,4]=1
A[0,4]=1
5) j=5
A[3,5] ≠1
6) j=n, конец цикла
6. j=1…n
Все A[0,j]=1
i=1…m
Выводятся все P[i]=1, то есть
P[2], P[3]
Ответ: 1 и 2 строки.
3. АЛГОРИТМ СОРТУВАННЯ
3.1 Постановка завдання і математичний опис методів її рішення.
Необхідно розробити алгоритм сортування методом простих включень (бульбашковим методом). Дуже часто для зручності в обчислювально техніки однотипні дані представляються у вигляді масивів. Масив - це об'єкт даних, в якому зберігається кілька одиниць даних, ідентифікованих за допомогою одного або декількох індексів. У простому випадку масив має постійну довжину і зберігає одиниці даних одного і того ж типу.
Кількість використаних індексів масиву може бути різним. Масиви з одним індексом називають одновимірними, з двома - двовимірними і т. д. Одновимірний масив нестрого відповідає вектору в математиці, двовимірний - матриці. Найчастіше застосовуються масиви з одним або двома індексами, рідше - з трьома, ще більша кількість індексів зустрічається вкрай рідко.
При побудові алгоритму розглядається сортування одновимірного масиву. Сортування n-мірних масивів здійснюється аналогічними методами. Розглянутий метод полягає в тому, що сортування відбувається в циклі, на кожній ітерації циклу знаходиться мінімальний (максимальний) елемент масиву і він поміщається в кінець (початок масиву).
3.2 Словесний опис алгоритму
Даний метод полягає в наступному. Елементи умовно поділяються на готову послідовність аi, …аi-1, і вхідну послідовність а1, …аn. На кожному кроці, починаючи з i = 2 і збільшуючи я на одиницю, беруть i-й елемент вхідної послідовності та передають в готову послідовність, вставляючи його на відповідне місце. При пошуку відповідного місця зручно чергувати порівняння і пересилки, тобто як би "просіювати" порівнюючи його з черговим елементом а або вставляючи х, або пересилаючи аi направо і просуваючись наліво. "Просіювання" може закінчитися при двох різних умовах:
1) Найден елемент аi з ключем, меншим, ніж ключ х.
2) Досягнуто лівий кінець готової послідовності.
Цей типовий приклад циклу з двома умовами закінчення дає можливість розглянути добре відомий прийом фіктивного елемента ("бар'єру"). Його можна легко застосувати в цьому випадку, оновивши бар'єр а0 = х. (Зауважимо, що для цього потрібно розширити діапазон індексів в описі а до 0,...,n.)
Розробляється алгоритм сортує масив даних по зростанню. Сортування за убуванням виконується аналогічно, змінюється лише умова при порівнянні елементів.
Програма отримує масив даних. Створюється цикл з параметром i=1, i<n (n - розмір масиву). У вихідному циклі створюється вкладений цикл з параметром j=n-1,i,j--.
У циклі відбувається перевірка: якщо поточний елемент більше наступного, тоді елементи міняються місцями. В іншому випадку нічого не відбувається.
Після цього відбувається вихід з циклу і вихід із зовнішнього циклу. Далі виводиться відсортований масив. Кінець алгоритму.
3.3 Структури даних
В даному алгоритмі використовуються такі типи даних - змінні і масиви.
а - масив, який слід відсортувати.
N - розмір масиву. Розмір може бути довільним цілим позитивним числом.
i - інкремент.
j - декремент.
temp = тимчасова змінна, яка використовується при зміні значень змінних.
3.4 Технічний опис схеми, контрольний приклад і ефективність алгоритму.
На рис.3 представлена блок-схема алгоритму сортування методом простих включень (бульбашковим методом).
Робота алгоритму проеверяется на контрольному прикладі. Спочатку масив виглядає наступним чином:
5 8 2 4 1
На першому кроці елемент зі значенням «1» стає першим елементом. Решта елемента залишаються в тому ж порядку, але зсуваються на один:
1 5 8 2 4.
Далі все виконується аналогічно:
1 2 5 8 4.
1 2 4 5 8
1 2 4 5 8.
Ефективність алгоритму падає в разі, якщо елементи виявляються відсортованими останньої ітерації, а якщо елементи стають відсортованими на самому останньому кроці - ефективність максимальна.
ВИСНОВОК
У цій роботі розробляються алгоритми сортування сортування за методом простого обміну (бульбашкове сортування) та покриття за методом "мінімальній стовпець - максимальний рядок". Алгоритми виконані з достатньою для розуміння деталізацією виконуваних операцій. Розглянуто приклади використання розроблених алгоритмів.
Розглянуто ефективність роботи алгоритмів, способи її підвищення.
Розроблений алгоритм сортування методом простих включень (бульбашковий метод) виконує сортування елементів масиву. Недоліком його є те, що іноді масив може вийти відсортованим раніше останньої ітерації циклу сортування. Для вирішення цієї проблеми, наприклад, можна перевіряти, чи були проведені переміщення елементів на кожному кроці сортування, і, якщо вони не були зроблені, слід, що масив відсортований. У цьому випадку сортування припиняється.
Розроблений алгоритм знаходження найкоротшого покриття за методом "мінімальний стовпець – максимальний рядок". Цей алгоритм является найбільш ефективним тому, що швидко знаходить найбільш значущі для знаходження наймешного покриття підмножини. На мою думку, алгоритм не потребує вдосконалення.
СПИСОК ЛІТЕРАТУРИ
1. Вирт Н. Алгоритмы и структуры данных. – С.-П.: Невский диалект, 2001. – 350 с.
2. Новиков Ф. А. Дискретная математика для программистов. – С.-П.: Питер, 2003.–292 с.
3. Шендрик Е. В. Конспект лекций по дисциплине «Теория алгоритмов». – Одесса, 2003.
Алгоритм покриття Додаток 1
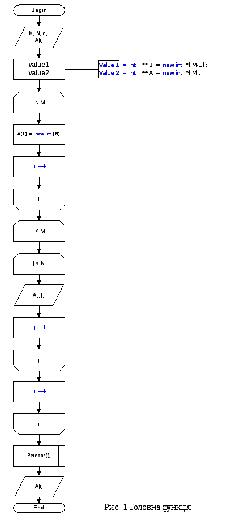
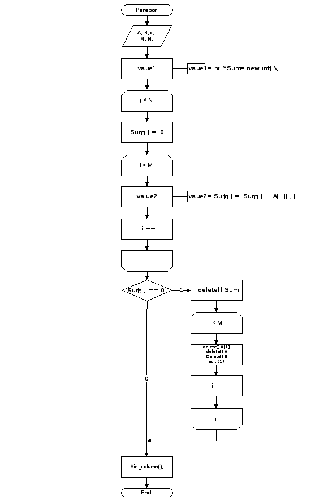
Рис. 2 Функція перебору

Рис. 3 Функція пошуку мінімального стовпця

Рис. 4(1) Функція пошуку максимального рядка
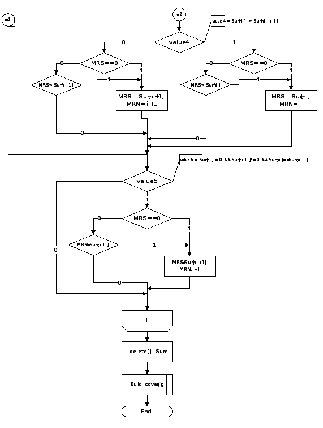
Рис. 4(2) Функція пошуку максимального рядка
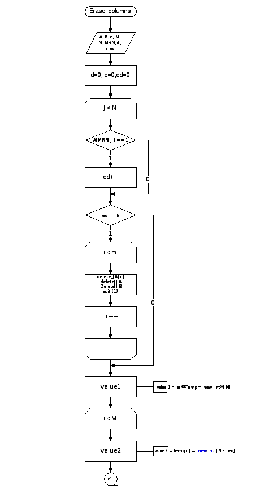
Рис. 5(1) Функція видалення рядків
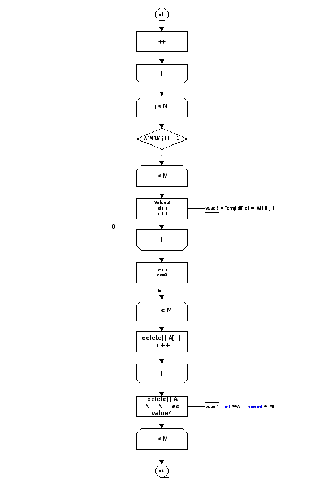
Рис. 5(2) Функція видалення рядків
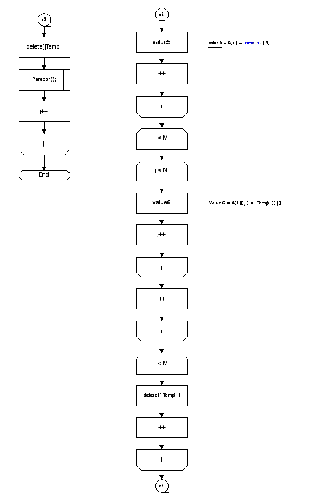
Рис. 5(3) Функція видалення рядків

Рис. 6 Функція побудови нового покриття
Алгоритм сортування Додаток 2

Додаток 3
// алгоритм нахождения покрытий.cpp: определяет точку входа для консольного приложения.
#include <iostream>
using namespace std;
void Perebor(int**A, int M, int N, int**B, int c);
void Min_column(int**A, int N, int M, int* Sum, int**B, int c);
void Max_row(int**A, int MCN, int M, int N, int**B, int c);
void Build_cover(int**A, int**B, int c, int MRN, int N, int M);
void Erase_columns(int**A, int**B, int MRN, int M, int N, int c);
int main()
{
setlocale(LC_ALL, "Russian");
int M, N, c = 0; //М - для хранения кол-ва строк, N- для хранения кол-ва столбцов
cout<<"Введите количество строк: ";
cin>>M;
cout<<"Введите количество столбцов: ";
cin>>N;
int **B = new int*[M - 1]; // массив В организован для хранения покрытия
int **A = new int*[M];
for (int i = 0; i < M; i++)
{
A[i] = new int[N];
}
cout<<"Заполните начальное покрытие 0 или 1\n";
int temp = 0; //Переменная используется для проверки того, что вводит пользователь
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
{
cout<<"Введите элемент "<<i<<""<<j<<":";
cin>>temp;
if((temp == 0) || (temp == 1))
{
A[i][j]=temp;
}
else
{
cout<<"Вы ввели неправильное число, теперь пиняйте на себя..."<<endl;
}
}
}
system("cls");
cout<<"Начальное покрытие имеет вид:"<<endl;
for(int i = 0; i < M; i++)
{
for(int j = 0; j < N; j++)
{
cout<<A[i][j]<<" ";
}
cout<<endl;
}
Perebor(A, M, N, B, c);
return 0;
}
void Perebor(int**A, int M, int N, int**B, int c)
{
int *Sum = new int[N]; //в массиве Sum будем хранить кол-во единиц в каждом столбце матрицы
for (int j = 0; j < N; j++)
{
Sum[j] = 0;
for (int i = 0; i < M; i++)
{
Sum[j] = Sum[j] + A[i][j];
}
if (Sum[j] == 0)
{
cout<<"В этой таблице нет покрытия!!!\n";
delete[]Sum;
for(int i = 0; i < M; i++)
{
delete[]A[i];
delete[]B;
system("pause");
exit(1);
}
}
Min_column(A, N, M, Sum, B, c);
}
}
void Min_column(int**A, int N, int M, int* Sum, int**B,int c)
{
int MCS = 0; //Переменная для хранения кол-ва единиц в минимальном столбце
int MCN = 0; // Переменная для хранения номера минимального столбца
for (int j = 0; j < N - 1; j++)//организовано для того, чтобы мин. столбцом стал первый обнаруженный мин. столбец
{
if (Sum[j] <= Sum[j + 1])
{
if (MCS == 0)
{
MCS = Sum[j];
MCN = j;
}
else
{
if(MCS > Sum[j])
{
MCS = Sum[j];
MCN = j;
}
}
}
else
{
if (MCS == 0)
{
MCS = Sum[j + 1];
MCN = j + 1;
}
}
}
delete[] Sum;
Max_row(A, MCN, M, N, B, c);
}
void Max_row(int**A, int MCN, int M, int N, int**B, int c)
{
int *Sum = new int[M];
int MRS = 0, MRN = 0;
for (int i = 0; i < M; i++)
{
Sum[i] = 0;
if (A[i][MCN] == 1)
{
for(int j = 0; j < N; j++)
{
Sum[i] = Sum[i] + A[i][j];
}
}
}
for (int i = 0; i < M - 1; i++)
{
if (Sum[i] - Sum[i + 1] != 0)
{
if(Sum[i] > Sum[i + 1])
{
if (MRS == 0)
{
MRS = Sum[i];
MRN = i;
}
else
{
if(MRS < Sum[i])
{
MRS = Sum[i];
MRN = i;
}
}
}
else
{
if (MRS == 0)
{
MRS = Sum[i + 1];
MRN = i + 1;
}
else
{
if(MRS < Sum[i + 1])
{
MRS = Sum[i + 1];
MRN = i + 1;
}
}
}
}
if (Sum[i] != 0 && Sum[i + 1] != 0 && Sum[i] == Sum[i + 1])
{
if (MRS == 0)
{
MRS = Sum[i + 1];
MRN = i + 1;
}
else
{
if(MRS <= Sum[i + 1])
{
MRS = Sum[i + 1];
MRN = i + 1;
}
}
}
}
delete[] Sum;
Build_cover(A, B, c, MRN, N, M);
}
void Build_cover(int**A, int**B, int c, int MRN, int N, int M)
{
B[c] = new int[N];
for(int j = 0; j < N; j++)
{
B[c][j] = A[MRN][j];
}
c++;
Erase_columns(A, B, MRN, M, N, c);
}
void Erase_columns(int**A, int**B, int MRN, int M, int N, int c)
{
int d = 0, e = 0; // Счётчики для массива Temp (d-строки, е-столбцы)
int ed = 0; //Счётчик количества единиц в максимальной строке
for (int j = 0; j < N; j++)
{
if (A[MRN][j] == 1)
{
ed++;
}
}
if (ed == N)
{
cout<<"Покрытие построено...\nК покрытию относятся строки под номерами:\t"<<MRN+1<<"\n";
for(int i = 0; i < M; i++)
{
delete[]A[i];
delete[]B;
system("pause");
exit(1);
}
}
int**Temp = new int*[M];
for (int i = 0; i < M; i++)
{
Temp[i] = new int[N - ed];
}
for (int j = 0; j < N; j++)
{
if (A[MRN][j] != 1)
{
for (int i = 0; i < M; i++)
{
Temp[d][e] = A[i][j];
d++;
}
e++;
d=0;