

4.3. Методы повышения эффективности алгоритмов
Эффективность алгоритма определяется мерой близости к оптимальному значению его критерия качества, под которым понимается минимум временной либо ёмкостной сложности; в сложных случаях используют составной критерий, включающий в себя оба параметра сложности с некоторыми выбранными весами. Ясно, что с увеличением размера задачи, для которой разрабатывается алгоритм, всё более важной становится проблема эффективности алгоритма. Заметим здесь же, что построение эффективного алгоритма для конкретной задачи тесно связано с выбором подходящих структур данных для этой задачи.
Существует большое число приёмов, иногда очень хитроумных, построения эффективных алгоритмов для конкретных задач. В то же время наработано небольшое число методов построения эффективных алгоритмов, которые применимы ко многим задачам и даже их классам. Ниже рассматриваются основные из этих методов.
4.3.1. Рекурсия
Процедуру, которая прямо или косвенно обращается к себе, называют рекурсивной. Применение рекурсии часто позволяет давать более ясные и сжатые описания алгоритмов, чем это было бы возможно без неё.
Рекурсия является особенно мощным средством в математических определениях. Рассмотрим несколько примеров таких определений.
1. Натуральные числа:
а) 1 есть натуральное число;
б) целое число, следующее за натуральным, есть натуральное число (х'=x+1 – см. c. 64).
2. Древовидные структуры:
а )
О
есть дерево (называемое пустым деревом);
)
О
есть дерево (называемое пустым деревом);
б) если Т1 и Т2 деревья, то
есть дерево (нарисованное сверху вниз).
3. Функция факториал n! для неотрицательных целых чисел:
а) 0!=1;
б) если n>0, то n! = n(n-1)!
Мощность рекурсии связана с тем, что она позволяет определять бесконечное множество объектов с помощью конечного высказывания. Точно так же бесконечные вычисления можно описать с помощью конечной рекурсивной программы, даже если эта программа не содержит явных циклов. Однако лучше всего использовать рекурсивные алгоритмы в тех случаях, когда решаемая задача, или вычисляемая функция, или обрабатываемая структура данных определена с помощью рекурсии. В общем виде рекурсивную программу P можно изобразить как композицию R базовых операторов Si (не содержащих P) и самой P:
PR[Si, P]. (4.18)
С процедурой принято связывать некоторое множество локальных объектов, т.е. переменных, констант, типов и процедур, которые определе-ны только в этой процедуре, а вне её не существуют или не имеют смысла. Каждый раз, когда такая процедура рекурсивно вызывается, для неё создаётся новое множество локальных переменных. Хотя они имеют те же имена, что и соответствующие элементы множества локальных переменных, созданного при предыдущем обращении к этой процедуре, значения переменных различны. Следующие правила области действия идентификаторов позволяют исключить какой-либо конфликт при использовании имён: идентификаторы всегда ссылаются на множество переменных, созданное последним; то же правило относится и к параметрам процедуры.
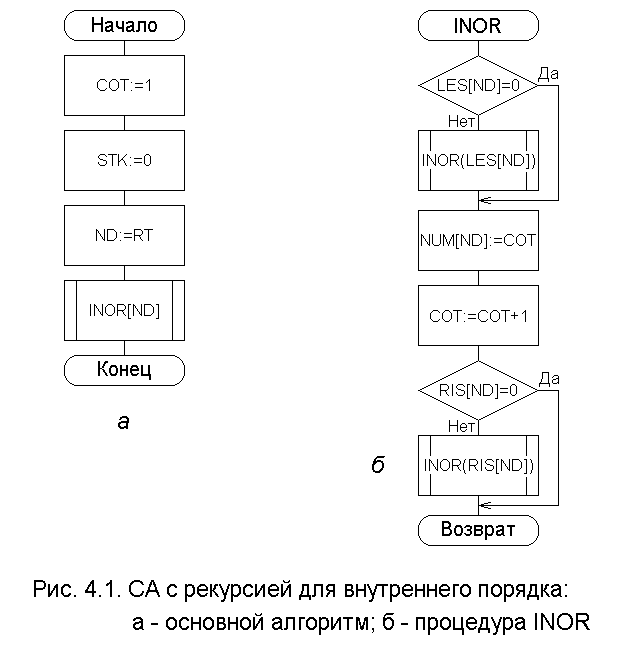
В качестве примера рекурсивного алгоритма рассмотрим процедуру прохождения двоичного дерева во внутреннем порядке с присвоением узлам соответствующего номера.
Алгоритм 4.1. Нумерация узлов двоичного дерева в соответствии с внутренним порядком (INOR INternal ORder).
ВХОД. Двоичное дерево, представленное массивами LES (Left Son-левый сын) и RIS (RIght Son правый сын).
ВЫХОД. Массив, называемый NUM (NUMber - номер), такой, что NUM[i] - номер узла i во внутреннем порядке.
МЕТОД. Кроме массивов LES, RIS и NUM, алгоритм использует глобальную переменную COT (COunT счёт), значение которой номер очередного узла в соответствии с внутренним порядком. Начальное значение переменной СОТ является 1. Параметр ND (NoDe узел) вначале равен RT (RooT корень). На рис. 4.1а изображена СА основного алгоритма, а на рис. 4.1б процедура INOR(ND), которая применяется рекурсивно.
Основной алгоритм таков:
begin
COT := 1;
ND := RT;
INOR (ND)
еnd.
Процедура INOR (ND) записывается следующим образом:
procedure INOR (ND)
begin
if LES[ND] 0 then INOR (LES[ND]);
NUM[ND] := COT;
COT := COT + 1;
if RIS[ND] 0 then INOR (RIS[ND])
end.
Рекурсия даёт несколько преимуществ и, прежде всего, простоту программ. Если бы приведенный выше алгоритм не был записан рекурсивно, надо было бы строить явный механизм для прохождения дерева. Двигаться вниз по дереву нетрудно, но чтобы обеспечить возможность вернуться к предку, надо запомнить всех предков в стеке, а операторы работы со стеком усложнили бы алгоритм.
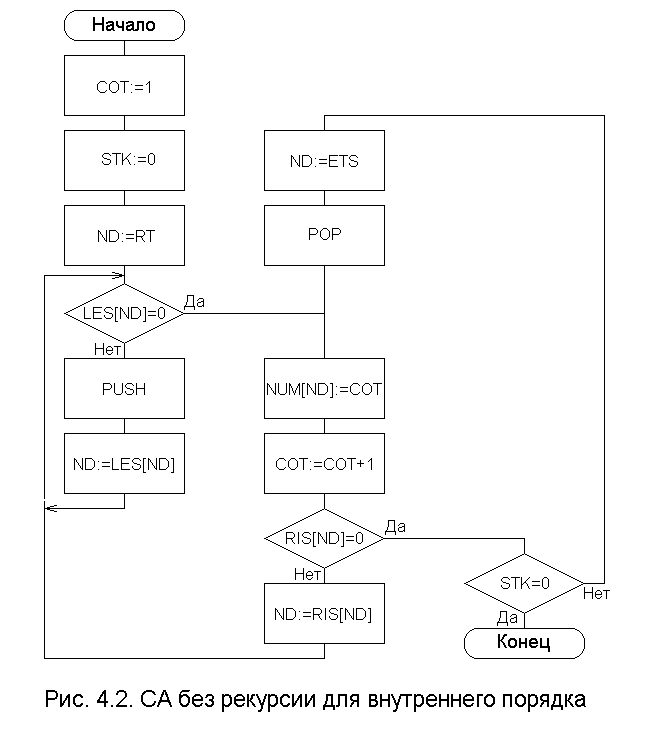
Рассмотрим возможный вариант того же алгоритма, но без использования рекурсии.
Алгоритм 4.2. Вариант алгоритма 4.1 без рекурсии.
ВХОД. Тот же, что и у алгоритма 4.1.
ВЫХОД. Тот же, что и у алгоритма 4.1.
МЕТОД. При прохождении дерева в стеке запоминаются все узлы, которые ещё не были занумерованы и которые лежат на пути из корня в узел, рассматриваемый в данный момент. При переходе из узла v к его левому сыну узел v запоминается в стеке. После нахождения левого поддерева для v узел v нумеруется и выталкивается из стека. Затем нумеруется правое поддерево для v.
При переходе из v к его правому сыну узел v не помещается в стек, поскольку после нумерации правого поддерева не нужно возвращаться в v, а следует вернуться к тому предку узла v, который еще не занумерован (т.е. к ближайшему предку w узла v такому, что v лежит в левом поддереве для w). Схема этого алгоритма приведена на рис. 4.2.
Запишем нерекурсивный вариант процедуры обхода дерева.
begin
COT := 1 ;
ND := RT;
STK := 0;
L: while LES[ND] 0 do
begin
PUSH; (* затолкнуть узел в стек *)
ND := LES[ND]
end;
C: NUM[ND] := COT;
COT := COT +1;
if RIS[ND] 0 then
begin
ND := RIS[ND];
goto L;
end;
 ifSTK
0
then
ifSTK
0
then
begin
ND := ETS; (*ETS - номер элемента в вершине стека*)
POP; (* вытолкнуть узел из стека *)
goto C;
end
end.
Рассмотрим процедуру INOR из алгоритма 4.1. Когда, например, она вызывает себя с фактическим параметром LES[ND], она запоминает в стеке адрес нового значения параметра ND вместе с адресом возврата, который указывает, что по окончании работы этого вызова выполнение программы продолжается со второй строки 2. Таким образом, переменная ND эффективно заменяется на LES[ND], где бы ни входила ND в это определение процедуры.
В алгоритме 4.2 сделано так, что окончание выполнения вызова INOR с фактическим параметром RIS[ND] завершает выполнение и самой вызывающей процедуры. Поэтому не обязательно теперь хранить адрес возврата или узел (ND) в стеке, если фактическим параметром является RIS[ND].
Подобно операторам цикла, рекурсивные процедуры могут привести к бесконечным вычислениям. Поэтому необходимо рассмотреть проблему окончания работы процедур. Очевидно, что для того чтобы работа когда-либо завершилась, необходимо, чтобы рекурсивное обращение к процедуре Р подчинялось условию В, которое в какой-то момент перестаёт выполняться. Поэтому более точно схему рекурсивных алгоритмов можно представить в виде
P if B then R[Si, P], (4.19)
или
P R [Si, if B then P]. (4.20)
Наиболее надежный способ обеспечить окончание процедуры связать с Р параметр (значение) n и рекурсивно вызвать Р со значением этого параметра n-1. Тогда замена условия В на n>0 гарантирует окончание работы. Это можно изобразить следующими схемами программ:
P(n) if n>0 then R [Si, P(n-1)], (4.21)
P(n) R [Si, if n>0 then P(n-1)]. (4.22)
На практике нужно обязательно убедиться, что наибольшая глубина рекурсии не только конечна, но и не слишком велика. Дело в том, что при каждом рекурсивном вызове процедуры Р для размещения её переменных выделяется некоторая память. Кроме этих локальных переменных, нужно ещё сохранять текущее состояние вычислений, чтобы вернуться к нему, когда закончится выполнение новой активации Р и нужно будет вернуться к старой. Другими словами, рекурсивный алгоритм работает в два прохода: сначала алгоритм "уходит" на всю глубину, резервируя память для переменных процедуры, а затем возвращается, вычисляя их значения.
Рекурсивные алгоритмы наиболее пригодны в случаях, когда поставленная задача или используемые данные определены рекурсивно. Но это не значит, что при наличии таких рекурсивных определений лучшим способом решения задачи непременно является рекурсивный алгоритм.
Программы, в которых следует избегать использования рекурсии, можно охарактеризовать схемой, изображающей их строение:
P if B then (S; P), (4.23)
или эквивалентной ей
P (S; if B then P). (4.24)
Эти схемы естественно применять в тех случаях, когда вычисляемые значения определяются с помощью простых рекуррентных соотношений.
Рассмотрим известный пример вычисления факториалов fi = i!:
i = 0, 1, 2, 3, 4, 5,... ,
f = 1, 1, 2, 6, 24, 120,... (4.25)
"Нулевое" число определяется явным образом как f0=1, а последующие числа обычно определяются рекурсивно - с помощью предшествующего значения:
fi+1 = (i+1)·fi . (4.26)
Эта формула предполагает использование рекурсивного алгоритма для вычисления n-го факториального числа. Если ввести две переменные I и F для значений i и fi на i-м уровне рекурсии, то для перехода к следующему числу в последовательности (4.25) понадобятся такие вычисления:
I := I+1; F := F*I; (4.27)
подставив (4.27) вместо S в (4.23), получим рекурсивную программу
P if I<n then (I := I+1; F := F*I; P);
I := 0; F := 1; (4.28)
Первую строку в (4.28) можно записать следующим образом:
procedure P;
begin
if I<n then
begin
I := I+1; F := F*I; P
end
end. (4.29)
Вместо процедуры можно ввести чаще используемую процедуру-функцию, т.е. некоторую процедуру, с которой явно связывается вычисляемое значение. Поэтому функцию можно использовать непосредственно как элемент выражения. Тем самым переменная F становится излишней, а роль I выполняет явный параметр процедуры.
function F(I);
begin
if I>0 then F(I) := F(I-1)*I
else F(I) := 1
end. (4.30)
Совершенно ясно, что здесь рекурсию можно заменить обычной итерацией, а именно программой
I := 0; F := 1;
while I<n do
begin
I := I+1; F := F*I
end. (4.31)
В общем виде программу, соответствующую схеме (4.23) или (4.24), нужно преобразовать так, чтобы она соответствовала схеме
P (x := xo; while B do S). (4.32)
Есть и другие, более сложные рекурсивные схемы, которые можно и должно переводить в итеративную форму. Примером служит вычисление чисел Фибоначчи, определяемых с помощью рекуррентного соотношения
fibn+1 = fibn + fibn-1 (4.33)
для n>0 и fib1=1, fib0=0.
При непосредственном подходе получим программу
function Fib(n);
begin
if n=0 then Fib(n) := 0 else
if n=1 then Fib(n) := 1 else
Fib(n) := Fib(n-1) + Fib(n-2)
еnd. (4.34)
При вычислении fibn обращение к функции Fib(n) приводит к рекурсивным активациям этой процедуры. Сколько раз? Можно заметить, что каждое обращение при n>1 приводит к двум дальнейшим обращениям, т.е. общее число обращений растёт экспоненциально. Ясно, что такая программа непригодна для практического использования.
Однако очевидно, что числа Фибоначчи можно вычислить по итеративной схеме, при которой использование вспомогательных переменных x=fibi и y=fibi-1 позволяет избежать повторного вычисления одних и тех же значений. Тогда программа принимает вид
/* вычисляем x=fibn для n>0 */
i := 0; x := 1; y := 0;
while i<n do
begin
z := x; i := i+1;
x :=x+y; y := z
end.
Отметим, что три присваивания x, y и z можно выразить всего лишь двумя присваиваниями без использования вспомогательной переменной z: x := x+y; y := x-y.
Итак, следует избегать рекурсии, когда имеется очевидное итеративное решение поставленной задачи. Но это не означает, что всегда нужно избавляться от рекурсии любой ценой; во многих случаях она вполне применима. Тот факт, что рекурсивные процедуры можно реализовать на нерекурсивных по сути машинах, говорит о том, что для практических целей любую рекурсивную программу можно преобразовать в чисто итеративную. Но это требует явного манипулирования со стеком рекурсий, и эти операции до такой степени заслоняют суть программы, что понять её становится очень трудно. Следовательно, алгоритмы, которые по своей сути скорее рекурсивны, чем итеративны, нужно представлять в виде рекурсивных процедур.
Примеры рекурсивных процедур (построение кривых Гильберта, Серпинского, алгоритмы с возвратом и др.) – см. в [9].