

10.2.2.5. Прогрессивный алгоритм принятия многокритериальных решений
Метод, излагаемый в этом параграфе, стоит особняком от рассмотренных выше, так как разработан для задач с дискретными альтернативами. И по этой же причине он включен в конспект, чтобы дать некоторое представление о возможных подходах к решению таких задач.
На практике нередко возникают ситуации, когда при решении многокритериальной задачи с дискретными альтернативами трудно или дорого, или вообще невозможно (недоступно) рассматривать одновременно все альтернативы. Например, при подборе кандидатов на должность невозможно быстро охватить всех потенциально желающих занять эту должность, а длительное ожидание может быть неприемлемо. Тогда выбор производится поэтапно до определения подходящей кандидатуры (и, как правило, не до исчерпания всех альтернатив). Аналогичная проблема имеет место при конкурсном отборе проектов: если не находится проект, устраивающий комиссию, то может объявляться дополнительный конкурс. На этой концепции и основан прогрессивный алгоритм.
Предлагается сначала исследовать начальную (доступную) выборку альтернатив и при невозможности получить на ней приемлемое для ЛПР решение производится добавление альтернатив с последующим продолжением поиска. Отличительной особенностью метода является и то, что хотя он базируется на функции ценности ЛПР, определение или построение точной функции ценности не требуется.
Кратко алгоритм можно описать следующим образом. ЛПР предъявляется начальная выборка альтернативных решений. Сравнивая попарно все или часть альтернатив, ЛПР должен выразить свои предпочтения по каждой рассмотренной паре. Эти данные используются в формальных тестах, представляющих собой задачи линейного программирования, с помощью которых определяется класс функций, к которому можно отнести функцию ценности ЛПР. Из имеющегося набора альтернатив находится наилучшая. Затем определяются области, содержащие возможно или наверняка лучшие альтернативы, чем те что уже рассмотрены. С помощью статистического моделирования вычисляются вероятностные оценки для таких альтернатив. При этом используется предлагаемое или известное распределение генеральной совокупности, из которой берутся выборки. Эти оценки, являющиеся границами истинной вероятности отыскания в последующем лучших альтернатив, предъявляются ЛПР, который по ним решает продолжать или заканчивать поиск. В случае продолжения поиска добавляются новые альтернативы и процедура повторяется.
Теперь остановимся на некоторых деталях алгоритма. По информации ЛПР о его предпочтениях на парах альтернатив из начальной выборки формируется множество
![]() ,
,
где
y,
z – пара
альтернатив в критериальном пространстве
из имеющейся выборки Y![]() G.
Предпочтения в Р
должны быть транзитивны, что следует
из свойства функции ценности возрастать
с увеличением предпочтения. Как правило,
информация от ЛПР оказывается неполной
и тогда применяют способы, позволяющие
дополнить множество Р,
например, использующие свойство
транзитивности.
G.
Предпочтения в Р
должны быть транзитивны, что следует
из свойства функции ценности возрастать
с увеличением предпочтения. Как правило,
информация от ЛПР оказывается неполной
и тогда применяют способы, позволяющие
дополнить множество Р,
например, использующие свойство
транзитивности.
Рассматривается
три класса функций, одному из которых
может принадлежать истинная функция
ценности u(y):
линейные
(UL),
квазивогнутые (UQ)
и общего вида (UG).
Очевидно,
что UL![]() UQ
UQ![]() UG.
Как отмечалось выше, для идентификации
u(y)
применяются
специальные тесты. Первый тест позволяет
принять или отвергнуть гипотезу о
принадлежности u(y)
классу
UL.
Для этого решается следующая задача
ЛП:
UG.
Как отмечалось выше, для идентификации
u(y)
применяются
специальные тесты. Первый тест позволяет
принять или отвергнуть гипотезу о
принадлежности u(y)
классу
UL.
Для этого решается следующая задача
ЛП:
![]() ,
,
![]() (10.38)
(10.38)
![]() .
.
Пусть y![]() z
для ЛПР, если u(y)
z
для ЛПР, если u(y)![]() u(z)+
u(z)+![]() ,где
,где![]() >0,
характеризует ощутимое различие
альтернатив. Тогда линейнаяu(y)согласуется с P,
тоесть u(y)
>0,
характеризует ощутимое различие
альтернатив. Тогда линейнаяu(y)согласуется с P,
тоесть u(y)![]() UL,
если
UL,
если
![]() =
=![]() .
При
.
При![]() <
<![]() гипотеза
линейности функции ценности
отвергается и проверяется гипотеза,
что u(y)
гипотеза
линейности функции ценности
отвергается и проверяется гипотеза,
что u(y)![]() UQ
согласуется сP,
путем решения линейной задачи, подобной
(10.38), но более детализированной по
областям предпочтений. Если второй тест
дает
UQ
согласуется сP,
путем решения линейной задачи, подобной
(10.38), но более детализированной по
областям предпочтений. Если второй тест
дает
![]() <0,
то и эта гипотеза будет отвергнута, и
остается признать, чтоu(y)
<0,
то и эта гипотеза будет отвергнута, и
остается признать, чтоu(y)![]() UG.
UG.
Целесообразность продолжения поиска с дополнением выборки определяется ЛПР после получения оценки возможности нахождения альтернатив, лучших чем в текущей выборке. Очевидно, что при известной функции ценности u(y) множество возможных альтернатив, лучших чем в Y, определяется как
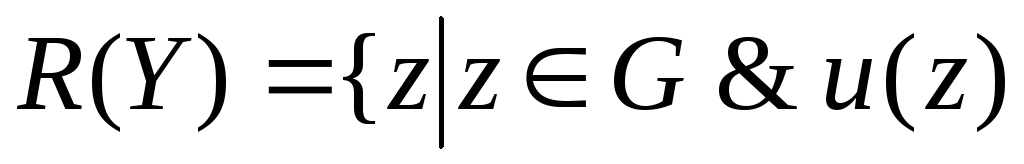 >
>![]() для
для
![]() .
.
Однако оно не может быть однозначно определено, когда известен лишь класс U, которому принадлежит функция ценности. Поэтому в таких случаях рассматриваются следующие множества:
-множество действительно лучших альтернатив
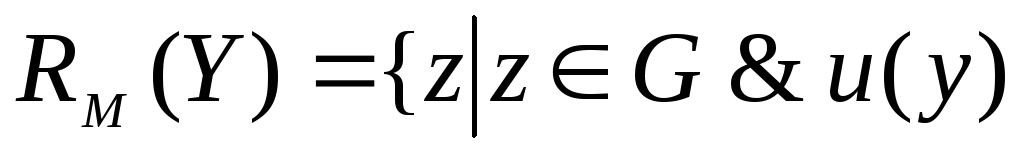 >
>![]() для
для
![]() и
и
![]() ;
;
-множество действительно худших альтернатив
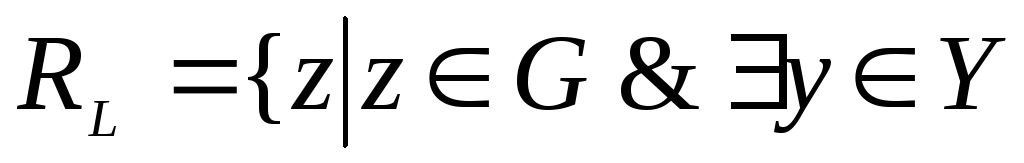 такой,
что
такой,
что
![]() для
для![]() ;
;
-множество возможно лучших альтернатив
![]()
Очевидно,
что
![]() ,
но при известнойu(y)
эти множества совпадают.
,
но при известнойu(y)
эти множества совпадают.
Для
классов UL
и UQ
имеются
тесты в виде задач ЛП, позволяющие
отнести рассматриваемую альтернативу
![]() (
(![]() )к множеству
RL
или RM.
В случае
)к множеству
RL
или RM.
В случае
![]() идентификация альтернатив из-за
отсутствия тестов сильно ограничена:
только приустановлении
соотношения доминирования (условия
достаточного, но не необходимого) можно
отнести рассматриваемую альтернативу
к одному из этих множеств. Заметим, что
и при квазивогнутых функциях тест,
дифференцирующий альтернативы, дает
также только достаточные условия.
Поэтому в классах UQ
и UG
нельзя точно идентифицировать множества
RM
и RL.
идентификация альтернатив из-за
отсутствия тестов сильно ограничена:
только приустановлении
соотношения доминирования (условия
достаточного, но не необходимого) можно
отнести рассматриваемую альтернативу
к одному из этих множеств. Заметим, что
и при квазивогнутых функциях тест,
дифференцирующий альтернативы, дает
также только достаточные условия.
Поэтому в классах UQ
и UG
нельзя точно идентифицировать множества
RM
и RL.
Для
определения оценки вероятности нахождения
лучших альтернатив (вне исследованной
выборки) новое множество S
альтернатив генерируется (имитируется)
случайным образом по данной функции
распределения вероятностей. В соответствии
с ранее определенным классом функции
ценности идентифицируются альтернативы
из S,
относящиеся
к множествам
![]() и
и![]() .
Отношение числа элементов множествR
и S
дает
приближенные
значения вероятностей нахождения
действительно и возможно лучших
альтернатив. При уровне риска 5%
доверительный интервал для неизвестной
точной вероятности р
определяется неравенством
.
Отношение числа элементов множествR
и S
дает
приближенные
значения вероятностей нахождения
действительно и возможно лучших
альтернатив. При уровне риска 5%
доверительный интервал для неизвестной
точной вероятности р
определяется неравенством
![]() ,
,
где
![]() – оценка,
– оценка,![]() – число элементов вS.
Это соотношение позволяет находить
доверительный интервал по
– число элементов вS.
Это соотношение позволяет находить
доверительный интервал по
![]() или, наоборот,
или, наоборот,![]() по желаемой точной оценки (величине
доверительного интервала).
по желаемой точной оценки (величине
доверительного интервала).
На
практике ЛПР интересует не столько
значение р,
сколько вероятность нахождения по
крайней мере одной лучшей альтернативы
и размер дополнительной выборки m,
позволяющей уверенно (в статическом
смысле) найти хотя бы одну лучшую
альтернативу. Если задать нижнюю границу
![]() для вероятности нахождения хотя бы
одной лучшей альтернативы, то размер
дополнительной выборки получим из
неравенства
для вероятности нахождения хотя бы
одной лучшей альтернативы, то размер
дополнительной выборки получим из
неравенства
![]() .
.
Так как мы знаем не р, а доверительный интервал, m определяется по двум значениям: нижней и верхней границам р.
Апробирование тестов, используемых в прогрессивном алгоритме, показало, что тест на квазивогнутость функции ценности можно применять при числе критериев, не превышающем трех. Более того, установление квазивогнутости не обязательно приведет к сужению границ вероятности нахождения лучшей альтернативы. Эти границы могут быть сужены при большем числе критериев, если оказывается справедливой гипотеза линейности. Но сила тестов ослабевает при 4-х и более критериях. Поэтому рекомендуется использовать в основном тест на линейность, так как в большинстве случаев знание только верхней границы вероятности достаточно для принятия решения об окончании или продолжении поиска. Минимальный размер начальной выборки, приемлемый для получения минимально необходимой информации о предпочтениях, составляет 8-10 альтернатив.
В заключение отметим, что прогрессивный алгоритм получает свое дальнейшее развитие на основе теории перспективности [40].