

Лекция № 4. Распознавание речи
Коммуникационный акт
Структура коммуникационного акта
Правило Байеса
Структура коммуникационной системы человека
Процесс порождения и восприятия речи у человека
2.1. Порождение и восприятие речи
2.2. Представление речи во временной и частотной областях
3. Автоматическое распознавание речи
Акустико-фонетический подход
Подход, основанный на распознавании образов
Подход на основе искусственного интеллекта
Подход, основанный на применении искусственных нейронных сетей
Первичная обработка
Спектральный анализ
Модель анализа на основе гребенки фильтров
Модель анализа на основе линейного предсказывающего кодирования
Векторное квантование
Модель анализа на основе психоакустического линейного предсказания
Принятие решения
Байесовское правило
Скрытые Марковские модели
Модель языка
Верхние уровни
Синтаксический уровень
Семантические представления
Нейросетевой подход
Реализация и использование систем распознавания речи
Моделирование диалога человека и машины
Прикладные разработки, связанные с пониманием речи
РАСПОЗНАВАНИЕ РЕЧИ
Наиболее сложным аспектом предмета распознавания речи является его междисциплинарный характер и необходимость применения комплексного подхода к решению частных проблем. Перечислим дисциплины, которые могут решать те или иные проблемы распознавания речи:
- обработка сигналов;
- физика (акустика);
- распознавание образов;
- теория информации и теория коммуникации;
- лингвистика;
- физиология, в том числе, нейрофизиология;
- компьютерные науки;
- психология, в том числе нейропсихология;
- математика;
- нейроинформатика.
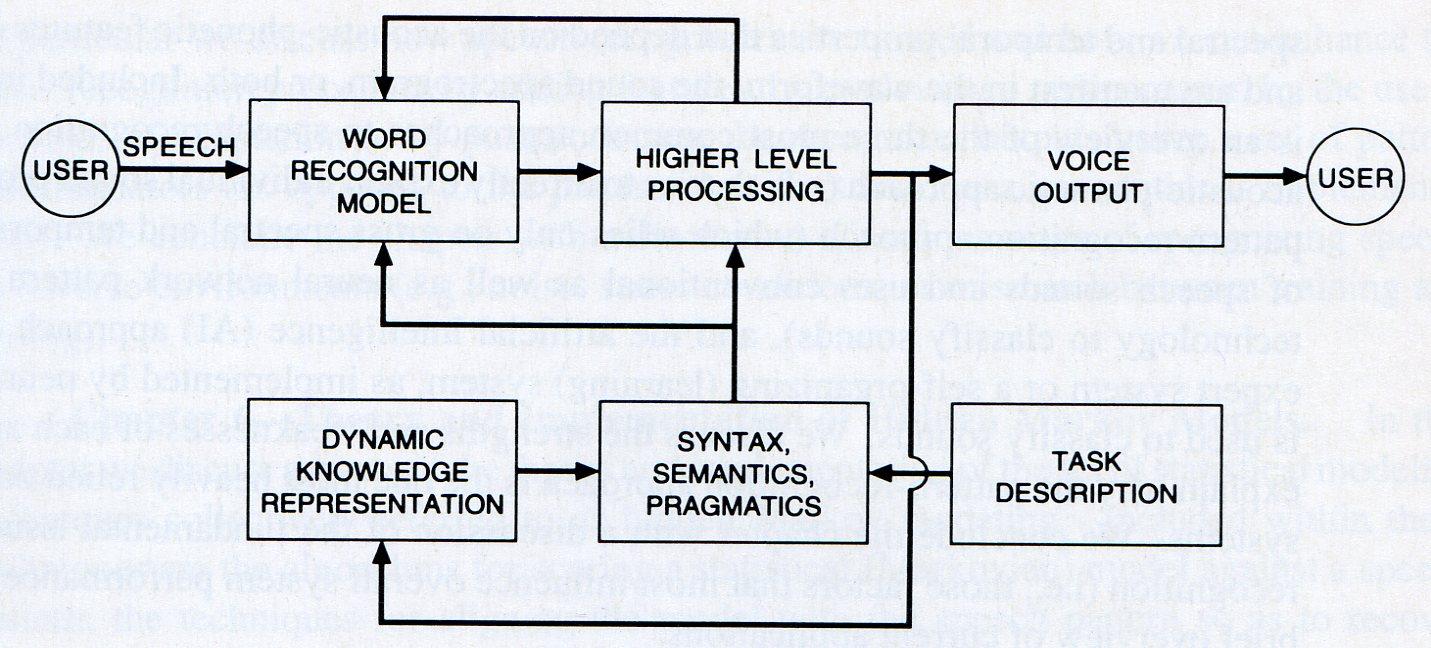
Рис. 1.1. Общая блок-схема ориентированной на задачу системы распознавания речи.
Общая модель распознавания речи, представленная на Рис. 1.1. начинается с порождения пользователем речевого сигнала с целью выполнения некоторой задачи. Сначала речевой сигнала декодируется в последовательность слов, которая удовлетворяет требованиям синтаксиса, семантики и прагматики. Значения распознанных слов затем уточняются в соответствие с контекстом ранее распознанных сообщений. Обратная связь от верхних уровней уменьшает сложность задачи распознавания ограничением перебора гипотез распознавания. Отвечает система пользователю синтезированным речевым сигналом, или некоторым ожидаемым от нее действием.
Коммуникационный акт.
1.1. Структура коммуникационного акта.
В конце 40-х гг. американский математик Клод Шеннон [2] ввёл модель коммуникации (рис. 1.2).

Рис. 1.2. Информационно-кодовая модель коммуникации Шеннона и Уивера
Механизм ее работы таков – сначала коммуникатор решает, какое из имеющихся сообщений ему активировать. После выделения оно модифицируется в сигнал с помощью какого-либо кодирующего устройства в сигнал, который идет через коммуникационный канал связи к декодирующему устройству, с помощью которого реципиент воспринимает данное сообщение и декодирует его. Например, для телефона канал - это провод, сигнал - электрический импульс, идущий по нему, а средства отправления и восприятия – микрофон и телефон. В разговоре же средством отправления являются артикуляторные органы, сигналом - колебание звуковых волн, проводящим каналом - воздух (разговор в вакууме невозможен) а ухо реципиента - средством восприятия. При рассмотрении схемы передачи сообщения необходимо учесть искажения, вносимые каналом передачи информации, которые обобщенно можно назвать шумом.
Процесс передачи включается в более общее действие, которое состоит из процессов трех уровней: технического, семантического и интенционального. Технические проблемы заключаются в том, как наиболее четко и аккуратно передать сообщение реципиенту. Семантический уровень определяет смысл сообщения. И, наконец, проблема интенционального уровня заключается в наиболее эффективном изменении поведения реципиента в направлении, указанном сообщением. В данном случае нас интересуют проблемы технического и семантического уровней.
Коммуникационный акт в наиболее простом случае может быть представлен как передача адресантом одного из известных адресату кодов с последующим выбором адресатом на основе полученного зашумленного кода наиболее вероятной гипотезы о переданном сообщении. Этот выбор называется классификацией – отнесением полученного сообщения к одному из классов. Аналитически обосновано, что не существует классификатора, работающего лучше Байесовского классификатора (классификатора, работающего на основе правила Байеса).
Используем методы статистического моделирования для интерпретации речевых событий, поступающих на вход системы.
На входе системы,
использующей статистические методы
моделирования, имеется последовательность
векторов признаков![]() ,
полученных в результате первичной
обработки (например, речевой волны). Для
выработки статистических гипотез
берется некоторое множество классов
,
полученных в результате первичной
обработки (например, речевой волны). Для
выработки статистических гипотез
берется некоторое множество классов![]() ,
к которым эти гипотезы должны быть
отнесены. В общем случае задача
классификации может рассматриваться
как статистическая задача распознавания
образов, что позволяет построить
оптимальный классификатор на основе
критерия максимума апостериорной
вероятности:
,
к которым эти гипотезы должны быть
отнесены. В общем случае задача
классификации может рассматриваться
как статистическая задача распознавания
образов, что позволяет построить
оптимальный классификатор на основе
критерия максимума апостериорной
вероятности:
![]() , (11)
, (11)
где
–
![]() вероятность принадлежности заданного
образа классу
вероятность принадлежности заданного
образа классу![]() .
.
1.2. Правило Байеса.
Пусть
имеется группа событий
![]() (классов, к которым относятся входные
сообщения), обладающая следующими
свойствами:
(классов, к которым относятся входные
сообщения), обладающая следующими
свойствами:
1)
все события попарно несовместны:
![]() ;
;
2) их объединение образует пространство элементарных исходов :

![]() .
.
В этом случае будем говорить, что H1, H2,..., Hn образуют полную группу событий. Такие события иногда называют гипотезами.

Рис. 1.3. Декодирование сигнала и выделение информации.
Пусть
![]() - полная группа событий и
- полная группа событий и![]() – некоторое событие. Тогда по формуле
Байеса исчисляется вероятность реализации
гипотезы
– некоторое событие. Тогда по формуле
Байеса исчисляется вероятность реализации
гипотезы![]() при условии, что событие А произошло.
Формула Байеса,
полученная Т. Байесом в 1763 году, позволяет
вычислить апостериорные вероятности
событий через априорные вероятности и
функции правдоподобия.
при условии, что событие А произошло.
Формула Байеса,
полученная Т. Байесом в 1763 году, позволяет
вычислить апостериорные вероятности
событий через априорные вероятности и
функции правдоподобия.
![]()
Здесь
А – конкретное наблюдение (измерение).
Формулу Байеса еще называют формулой
вероятности гипотез. Будем считать, что
у нас достаточно данных для определения
вероятности принадлежности объекта
каждому из классов. Вероятность
![]() называют априорной вероятностью гипотезы
называют априорной вероятностью гипотезы![]() ,
а вероятность
,
а вероятность![]() – апостериорной вероятностью,
поскольку задает распределение индекса
класса после эксперимента (a
posteriori
– т.е. после того, как измерение было
произведено). Также будем считать, что
известны функции распределения вектора
признаков для каждого класса
– апостериорной вероятностью,
поскольку задает распределение индекса
класса после эксперимента (a
posteriori
– т.е. после того, как измерение было
произведено). Также будем считать, что
известны функции распределения вектора
признаков для каждого класса
![]() .
Они называются функциями правдоподобия
A по отношению кHk.
Если априорные вероятности и функции
правдоподобия неизвестны, то их можно
оценить методами математической
статистики на множестве прецедентов.
Байесовский подход исходит из
статистической природы наблюдений. За
основу берется предположение о
существовании вероятностной меры на
пространстве образов, которая либо
известна, либо может быть оценена. Цель
состоит в разработке такого классификатора,
который будет правильно определять
наиболее вероятный класс для пробного
образа. Тогда задача состоит в определении
"наиболее вероятного" класса.
.
Они называются функциями правдоподобия
A по отношению кHk.
Если априорные вероятности и функции
правдоподобия неизвестны, то их можно
оценить методами математической
статистики на множестве прецедентов.
Байесовский подход исходит из
статистической природы наблюдений. За
основу берется предположение о
существовании вероятностной меры на
пространстве образов, которая либо
известна, либо может быть оценена. Цель
состоит в разработке такого классификатора,
который будет правильно определять
наиболее вероятный класс для пробного
образа. Тогда задача состоит в определении
"наиболее вероятного" класса.
Если
априорные вероятности и функции
правдоподобия неизвестны, то их можно
оценить методами математической
статистики на множестве прецедентов.
Например,
![]() ,
где
,
где![]() – число прецедентов из
– число прецедентов из![]() .
.![]() – общее число прецедентов.
– общее число прецедентов.![]() может быть приближено гистограммой
распределения вектора признаков для
прецедентов из класса
может быть приближено гистограммой
распределения вектора признаков для
прецедентов из класса![]() .
.
Рассмотрим
случай двух классов
![]() и
и![]() .
Естественно выбрать решающее правило
таким образом: объект относим к тому
классу, для которого апостериорная
вероятность выше. Такое правило
классификации по максимуму апостериорной
вероятности называется Байесовским:
если
.
Естественно выбрать решающее правило
таким образом: объект относим к тому
классу, для которого апостериорная
вероятность выше. Такое правило
классификации по максимуму апостериорной
вероятности называется Байесовским:
если![]() ,
то
,
то![]() классифицируется в
классифицируется в![]() ,
иначе в
,
иначе в![]() .
Таким образом, для Байесовского решающего
правила необходимо получить апостериорные
вероятности
.
Таким образом, для Байесовского решающего
правила необходимо получить апостериорные
вероятности![]() .
Это можно сделать с помощью формулы
Байеса.
.
Это можно сделать с помощью формулы
Байеса.
Итак, Байесовский подход к статистическим задачам основывается на предположении о существовании некоторого распределения вероятностей для каждого параметра. Недостатком этого метода является необходимость постулирования как существования априорного распределения для неизвестного параметра, так и знание его формы.
Байесовские процедуры классификацииразработаны на основе теоремы Байеса и специально предназначены для работы со входными данными высокой размерности. Несмотря на простотуБайесовских процедур, результаты их работы по своим характеристикам могут превзойти результаты работы более сложных алгоритмов классификации.

Чтобы продемонстрировать основные принципы работы Байесовских процедур классификации, рассмотрим вышеприведенный пример. Как видно, объекты могут быть разделены на два класса:GREENилиRED. Наша цель - классифицировать новые наблюдения по мере их поступления, то есть нужно решить к какому классу они принадлежат, используя информацию о принадлежности классам уже имеющихся в нашем распоряжении объектов.
Так как объектов типа GREENв два раза больше объектов типаRED, разумно предположить, что шансы принадлежности вновь поступившего наблюдения классуGREENв два раза больше шансов принадлежать классуRED. В терминах байесовского анализа это предположение именуется априорной вероятностью. Априорная вероятность определяется накопленным опытом (в нашем случае процентным соотношением объектов типаGREENиRED). Эта величина обычно используется для предсказания исходов до их реального наступления.
Таким образом, мы можем записать:

Так как общее число объектов - 60, 40 из них принадлежат классу GREEN и 20 - классуRED, то априорная вероятность принадлежности классу будет:
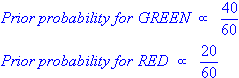

Определив априорную вероятность, мы готовы классифицировать новый объект (белый круг). В силу хорошей группировки объектов, разумно предположить, что чем больше объектов типа GREEN(илиRED) попадает в окрестность точкиX, тем вероятнее, что новое наблюдение будет принадлежать этому классу. Для вычисления степени правдоподобия, проведем окружность с центром в точкеX, которая охватит априорно выбранное число точек безотносительно к их классовой принадлежности. Затем подсчитывается число точек каждого типа. По этим данным вычисляем степень правдоподобия:

На вышеприведенной иллюстрации видно, что степень правдоподобия принадлежности XклассуGREENниже соответствующего значения для классаRED, так как окружность заключает 1 объект типаGREENи 3 объекта типаRED. Следовательно:

Хотя априорная вероятность указывает на возможную принадлежность наблюдения XклассуGREEN(объектов типаGREENв два раза больше объектов типаRED), величина меры правдоподобия приводит к противоположному заключению:Xпринадлежит классуRED(в окрестности точкиXобъектов типаREDбольше чем объектов типаGREEN). Конечное классифицирующее решение в байесовском анализе принимается на основе двух источников информации: априорной вероятности и степени правдоподобия. Для определения апостериорной вероятности применяется правило Байеса (названо в честь Thomas Bayes 1702-1761).

В результате мы классифицируем Xкак объект типаRED,так как апостериорная вероятность принадлежности этому классу имеет наибольшего значения.
Байесовские процедуры классификацииразработаны на основе теоремы Байеса и специально предназначены для работы со входными данными высокой размерности. Несмотря на простотуБайесовских процедур, результаты их работы по своим характеристикам могут превзойти результаты работы более сложных алгоритмов классификации.

Чтобы продемонстрировать основные принципы работы Байесовских процедур классификации, рассмотрим вышеприведенный пример. Как видно, объекты могут быть разделены на два класса:GREENилиRED. Наша цель - классифицировать новые наблюдения по мере их поступления, то есть нужно решить к какому классу они принадлежат, используя информацию о принадлежности классам уже имеющихся в нашем распоряжении объектов.
Так как объектов типа GREENв два раза больше объектов типаRED, разумно предположить, что шансы принадлежности вновь поступившего наблюдения классуGREENв два раза больше шансов принадлежать классуRED. В терминах байесовского анализа это предположение именуется априорной вероятностью. Априорная вероятность определяется накопленным опытом (в нашем случае процентным соотношением объектов типаGREENиRED). Эта величина обычно используется для предсказания исходов до их реального наступления.
Таким образом, мы можем записать:

Так как общее число объектов - 60, 40 из них принадлежат классу GREEN и 20 - классуRED, то априорная вероятность принадлежности классу будет:


Определив априорную вероятность, мы готовы классифицировать новый объект (белый круг). В силу хорошей группировки объектов, разумно предположить, что чем больше объектов типа GREEN(илиRED) попадает в окрестность точкиX, тем вероятнее, что новое наблюдение будет принадлежать этому классу. Для вычисления степени правдоподобия, проведем окружность с центром в точкеX, которая охватит априорно выбранное число точек безотносительно к их классовой принадлежности. Затем подсчитывается число точек каждого типа. По этим данным вычисляем степень правдоподобия:

На вышеприведенной иллюстрации видно, что степень правдоподобия принадлежности XклассуGREENниже соответствующего значения для классаRED, так как окружность заключает 1 объект типаGREENи 3 объекта типаRED. Следовательно:

Хотя априорная вероятность указывает на возможную принадлежность наблюдения XклассуGREEN(объектов типаGREENв два раза больше объектов типаRED), величина меры правдоподобия приводит к противоположному заключению:Xпринадлежит классуRED(в окрестности точкиXобъектов типаREDбольше чем объектов типаGREEN). Конечное классифицирующее решение в байесовском анализе принимается на основе двух источников информации: априорной вероятности и степени правдоподобия. Для определения апостериорной вероятности применяется правило Байеса (названо в честь Thomas Bayes 1702-1761).

В результате мы классифицируем Xкак объект типаRED,так как апостериорная вероятность принадлежности этому классу имеет наибольшего значения.