

34. Конвейеризация и векторизация обработки данных
Для повышения скорости выполнения команд был придуман конвейер. Команда в процессе выполнения проходит целую цепь этапов. Каждое звено цепи обслуживается своим аппаратным обеспечением и процессор ждет, пока команда пройдет всю цепь, а затем загружает новую. Смысл конвейера заключается в том, что бы аппаратное обеспечение не простаивало, а постоянно работало. Это достигается тем, что после выполнения команды и передачи ее далее, звено принимает и выполняет следующую. Таким образом происходит частичное временное перекрытие выполнепия нескольких команд, которое зависит от количества звеньев конвейейра. Такой способ распараллеливания операций называется конвейеризацией.
Рассмотрим простой конвейер, состоящий из 5 звеньев. Звено выборки команд берет команду из памяти и помещает в буфер. Звено декодирования определяет тип команды и операндов, нужных команде. Звено выборки операндов определяет местонахождение операндов и вызывает их. Звено выполнения команд с помощью АЛУ совершает операцию, указанную командой. Звено возврата записывает результат операции в нужный регистр.


В современных процессорах звеньев конвейера может быть намного больше.
 Для
дальнейшего повышения производительности
в процессоре можно разместить не один,
а два конвейера, работающих параллельно.
Общее звено выборки берет из памяти две
команды и помещает каждую из них в
отдельный конвейер. Эти две команды не
должны конфликтовать между собой, т.е.
у них не должно быть совместно используемых
регистров и не должны пользоваться
одним и тем же операндом. Предупреждать
конфликты должно дополнительное
аппаратное обеспечение или компилятор.
Для
дальнейшего повышения производительности
в процессоре можно разместить не один,
а два конвейера, работающих параллельно.
Общее звено выборки берет из памяти две
команды и помещает каждую из них в
отдельный конвейер. Эти две команды не
должны конфликтовать между собой, т.е.
у них не должно быть совместно используемых
регистров и не должны пользоваться
одним и тем же операндом. Предупреждать
конфликты должно дополнительное
аппаратное обеспечение или компилятор.
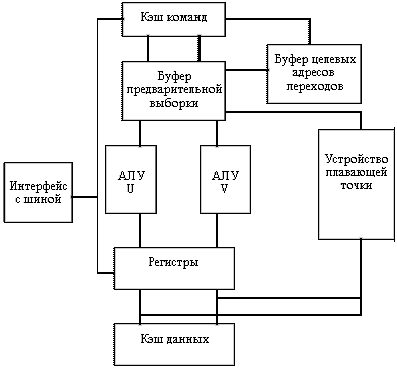
Рассмотрим упрощенную схему процессора Pentium I, использующего для выполнения команд два конвейера U и V. Команды могут направляться в каждое из этих устройств одновременно, причем более сложная команда поступает в конвейер U, а менее сложная - в конвейер V. Сложные вычесления с плавающей точкой выполняются одноименным устройством. Остальные устройства процессора предназначены для снабжения конвейеров необходимыми командами и данными. В этом процессоре используется раздельная кэш-память команд и данных (модифицированная гарвардская структура), что обеспечивает независимость обращений процессора к памяти.
В процессоре предусмотрен механизм предсказания ветвлений переходов. С этой целью на кристалле размещена небольшая кэш-память, которая называется буфером целевых адресов переходов (BTB), и две независимые пары буферов предварительной выборки команд. Неправильный прогноз приводит к приостановке работы конвейеров на 3-4 такта.
Так же можно разработать процессор с четырьмя конвейерами, но это требует создания дополнительного громоздкого аппаратного обеспечения. Разработчики пошли по иному пути. Пропускная способность звена выполнения команд меньше, чем других звеньев. Поэтому был разработан конвейер с большим количеством функциональных блоков. Архитектура, использующая такой конвейер, получила название “суперскалярная”. Более подробно суперскалярную архитектуру можно рассмотреть на примерепроцессора Pentium IV.
При обработке массивов данных, состоящих из элементов одинаковой структуры, называемых векторами, производятся одинаковае операции над этими элементами. Для повышения скорости обработки этих массивов, вводятся команды процессора, которые обеспечивают параллельную обработку данных, определяющих структуру вектора. Т.е.одновременно выполняются одни и те же вычисления над различными данными. Такой способ распараллеливания операций называется векторизациейи часто используется совместно с конвейерной обработкой.
 Производительность
процессора является интегральной
характеристикой, которая зависит от
показателей частоты процессора, его
разрядности, а так же особенностей
архитектуры (наличие кэш-памяти и др.).
Производительность процессора нельзя
вычислить. Она определяется в процессе
тестирования, т.е. определения скорости
выполнения процессором определенных
операций в какой-либо программной среде.
Производительность
процессора является интегральной
характеристикой, которая зависит от
показателей частоты процессора, его
разрядности, а так же особенностей
архитектуры (наличие кэш-памяти и др.).
Производительность процессора нельзя
вычислить. Она определяется в процессе
тестирования, т.е. определения скорости
выполнения процессором определенных
операций в какой-либо программной среде.
Чтобы правильно выбрать процессор нужно первым делом посмотреть на его главную характеристику – тактовую частоту, ее еще называют скорость. Как было сказано выше, от возможностей процессора зависит скорость работы всей Вашей системы (быстродействие). Тактовая частота задает ритм жизни компьютера. Чем выше тактовая частота, тем меньше длительность выполнения одной операции и тем выше производительность компьютера. Поэтому частота является главной характеристикой процессора.
Под тактом мы понимаем промежуток времени, в течение которого может быть выполнена элементарная операция. Тактовую частоту можно измерить и определить ее значение. Измеряется она в МегаГерцах (МГц) (MHz) или ГГц (GHz). Герц единица измерения, определяющая частоту какого-либо периодического процесса. Данная единица измерения имеет прямое соотношение с единицей времени, величиной в одну секунду. Иными словами, когда мы говорим 1 Гц - это означает одно исполнение какого-либо процесса за одну секунду (1 Гц = 1/с). Например, если мы имеем 10 Гц, то это означает, что мы имеем десять исполнений такого процесса за одну секунду. Приставка Мега увеличивает показатель базовой величины (Гц) в миллион раз (1 МГц - миллион тактов в секунду), а приставка Гига в миллиард (1 ГГц - миллиард тактов в секунду).
Вот уже лет пять, как частота процессоров замерла в районе 3 гигагерц.
Конвейерная архитектура (pipelining) была введена в центральный процессор с целью повышения быстродействия.
Конве́йер — способ организации вычислений, используемый в современных процессорах и контроллерах с целью повышения их производительности (увеличения числа инструкций, выполняемых в единицу времени), технология, используемая при разработке компьютеров и других цифровых электронных устройств.
Идея заключается в разделении обработки компьютерной инструкции на последовательность независимых стадий с сохранением результатов в конце каждой стадии. Это позволяет управляющим цепям процессора получать инструкции со скоростью самой медленной стадии обработки, однако при этом намного быстрее, чем при выполнении эксклюзивной полной обработки каждой инструкции от начала до конца.
Конвейеризация используется затем что бы поступающие данные из одной программы поступали тут же в другую.

4 инструкций ожидают исполнения
1) 1 инструкция забирается из памяти
2) 1 инструкция раскодируется, 2 инструкция забирается из памяти
3) 1 инструкция выполняется (то есть исполняется то действие, которое она кодировала), 2 инструкция раскодируется, 3 инструкция забирается из памяти
4) Итоги исполнения 1 инструкции записываются в регистры или в память,2 инструкция выполняется,3 инструкция раскодируется, 4 инструкция забирается из памяти
5) 1 инструкция завершилась, Итоги исполнения 2 инструкции записываются в регистры или в память, 3 инструкция выполняется, 4 инструкция раскодируется
6) 2 инструкция завершилась, Результаты исполнения 3 инструкция записываются в регистры или в память, 4 инструкция выполняется
7) 3 инструкция завершилась, Итоги исполнения 4 инструкции записываются в регистры или в память
8 ) 4 инструкция завершилась
9 )Все инструкции были выполнены
После освобождения k-й ступени конвейера она сразу приступает к работе над следующей командой. Если предположить, что каждая ступень конвейера тратит единицу времени на свою работу, то выполнение команды на конвейере длиной в N ступеней займёт N единиц времени, однако в самом оптимистичном случае результат выполнения каждой следующей команды будет получаться через каждую единицу времени.
Действительно, при отсутствии конвейера выполнение команды займёт N единиц времени (так как для выполнения команды по-прежнему необходимо выполнять выборку, дешифровку и т. д.), и для исполнения M команд понадобится (N * M)единиц времени; при использовании конвейера (в самом оптимистичном случае) для выполнения команд понадобится всего лишь (N + M )единиц времени.
Факторы, снижающие эффективность конвейера:
1. Простой конвейера, когда некоторые ступени не используются (например, адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами).
2. Ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд — out-of-order execution).
3. Очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что повышает производительность процессора, но, однако, приводит к увеличению длительности простоя (например, в случае ошибки в предсказании условного перехода). Не существует единого мнения по поводу оптимальной длины конвейера: различные программы могут иметь существенно различные требования.
Предсказание переходов.
Микроархитектура ядра должна решать проблему предсказания ветвлений программы. Суть проблемы в том, что, встретив инструкцию перехода, процессор останавливает конвейер. Задержка будет тем дольше, чем больше длина конвейера.
Поэтому инструкции перехода надо выявлять заранее и реагировать соответствующим образом. Для этого предназначен специальный блок предсказания переходов (Branch Prediction Unit). Его задача — предвидеть направление перехода и, в случае удачного предсказания, сэкономить время. Соответственно, если результат предсказания будет неудачным, происходит полная остановка конвейера и очистка буферов.
Если в программе есть условные переходы (то есть такие, которые зависят от результата выполнения какой-либо операции), надо постараться «угадать», произойдет этот переход, или нет. Метод гадания на кофейной гуще здесь не подходит. Поэтому блок предсказаний хранит специальную таблицу истории переходов (Branch History Table), в которой записана результативность предыдущих примерно 4000 предсказаний. Кроме того, отслеживается точность последнего предсказания, чтобы при необходимости откорректировать алгоритм работы. Благодаря этому декодер выполняет по подсказке блока предсказания условный переход, а затем блок предсказаний проверяет, правильно ли было предсказано это условие. Микроархитектура Prefetch (предзагрузки или предвыборки) позволяет заранее знать, какие данные понадобятся процессору в будущем.
Специальные механизмы анализируют последовательности адресов, по которым происходила загрузка данных, и пытаются предугадать следующий адрес.
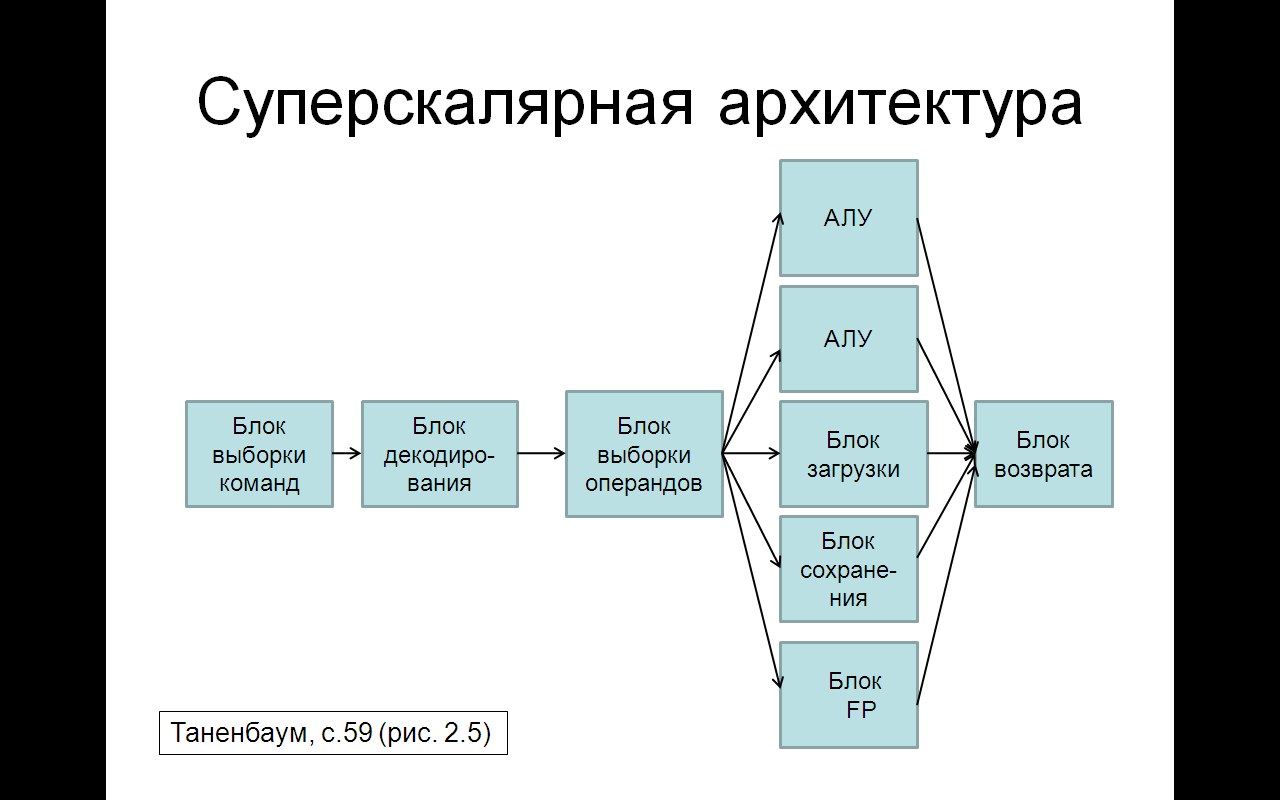
Суперскалярная архитектура
Один конвейер - хорошо, а два - еще лучше. Здесь общий отдел вызова команд берет из памяти сразу по две команды и помещает каждую из них в один из конвейеров. Каждый конвейер содержит АЛУ для параллельных операций. Чтобы выполняться параллельно, две команды не должны конфликтовать при использовании ресурсов (например, регистров), и ни одна из них не должна зависеть от результата выполнения другой. Как и в случае с одним конвейером, либо компилятор должен следить, чтобы не возникало неприятных ситуаций (например, когда аппаратное обеспечение выдает некорректные результаты, если команды несовместимы), либо же конфликты выявляются и устраняются прямо во время выполнения команд благодаря использованию дополнительного аппаратного обеспечения.
Суперскалярность - способность выполнения нескольких машинных инструкций за один такт процессора путем увеличения числа исполнительных устройств. Появление этой технологии привело к существенному увеличению производительности, в то же время существует определенный предел роста числа исполнительных устройств, при превышении которого производительность практически перестает расти, а исполнительные устройства простаивают.
Основная идея — один конвейер с большим количеством функциональных блоков.
Суперскалярная архитектура процессора, то есть процессор имеет два пятиступенчатых параллельно работающих конвейера обработки информации, благодаря чему он способен одновременно выполнять две команды за один такт. Необходимо отметить, что преимущества такой архитектуры проявляются только в случае специальной компиляции программного обеспечения, позволяющей осуществлять параллельную обработку.
Суперскалярная архитектура Pentium процессора представляет собой совместимую только с INTEL двухконвейерную индустриальную архитектуру, позволяющую процессору достигать новых уровней производительности посредством выполнения более, чем одной команды за один период тактовой частоты.
Параллелизм на уровне команд помогает в какой-то степени, но конвейеры и суперскалярная архитектура обычно увеличивают скорость работы всего лишь в 5 - 10 раз. Чтобы улучшить производительность в 50, 100 и более раз, нужно разрабатывать компьютеры с несколькими процессорами.
Многоядерность.
Параллельная работа двух и более ядер при меньшей тактовой частоте обеспечивает бóльшую производительность. Работающая в текущий момент программа распределяет задачи по обработке данных на оба ядра. Это обеспечивает максимальный эффект, когда и операционная система, и прикладные программы работают в параллельном режиме, как, например, это часто бывает с приложениями для обработки графики. Многоядерность влияет также на одновременную работу стандартных приложений. Например, одно ядро процессора может отвечать за программу, работающую в фоновом режиме, в то время как антивирусная программа занимает ресурсы второго ядра.
Стоит, однако, оговориться, что управление параллельными задачами, тем не менее, требует времени и задействует другие ресурсы системы. А иногда даже для решения одной из задач приходится ждать результата выполнения другой. Поэтому на практике наличие 2-х ядерного процессора не означает производительность вычислений в два раза быстрее. Хотя прирост быстродействия и может оказаться весьма значительным, но в зависимости от типа приложения.
Еще одно реальное преимущество многоядерного процессора – сниженное энергопотребление. Многоядерные чипы, в которых реализованы все современные технологии энергосбережения, быстрее обычных справляются с поставленными задачами и поэтому быстрее могут перейти в режим с меньшей тактовой частотой и, соответственно, с меньшим энергопотреблением. Особенно существенна эта деталь для ноутбука, чья автономная работа от аккумулятора в значительной степени продлевается.
35. Понятие шины расширения. Шины PCI, PCI-X, PCI-E.
PCI (англ. Peripheral component interconnect, дословно — взаимосвязь периферийных компонентов) — шина ввода/вывода для подключения периферийных устройств к материнской плате компьютера.
Стандарт на шину PCI определяет:
физические параметры (например, разъёмы и разводку сигнальных линий);
электрические параметры (например, напряжения);
логическую модель (например, типы циклов шины, адресацию на шине).
Развитием стандарта PCI занимается организация PCI Special Interest Group.
Весной 1991 года компания Intel завершает разработку первой макетной версии шины PCI. Перед инженерами была поставлена задача разработать недорогое и производительное решение, которое позволило бы реализовать возможности процессоров 486, Pentium и Pentium Pro. Кроме того, было необходимо учесть ошибки допущенные VESA при проектировании шины VLB (электрическая нагрузка не позволяла подключать более 3 плат расширения), а также реализовать автоконфигурирование устройств по примеру протокола Autoconfig для компьютеров Amiga.
В 1992 году появляется первая версия шины PCI, Intel объявляет, что стандарт шины будет открытым, и создаёт PCI Special Interest Group. Благодаря этому любой заинтересованный разработчик получает возможность создавать устройства для шины PCI без необходимости приобретения лицензии. Первая версия шины имела тактовую частоту 33 МГц, могла быть 32- или 64-битной, а устройства могли работать с сигналами в 5 В или 3,3 В. Теоретически, пропускная способность шины 133 Мбайт/с, однако в реальности пропускная способность составляла около 80 Мбайт/с.
В середине 1993 года компания Intel выходит из ассоциации VESA и начинает предпринимать активные шаги по продвижению шины PCI на рынке. Ответом на критику со стороны специалистов из конференций Usenet и конкурирующих компаний (характеристики шины были во многом аналогичны, например Zorro III, публиковались статьи об ошибочном дизайне шины) стала PCI 2.0.
В 1995 году появляется версия PCI 2.1 (ещё одно название — «параллельная шина PCI»), которая обеспечила передачу данных по шине с частотой 66 МГц и максимальную скорость передачи в 533 Мбайт/с (для 64-битного варианта с частотой 66 МГц). Кроме того, эта шина уже была поддержана на уровне ОС Windows 95 (технология Plug and Play). Версия шины PCI 2.1 оказалась настолько популярной, что вскоре уже она была перенесена на платформы с процессорами Alpha, MIPS, PowerPC, SPARC и др.
В 1997 году, в связи с развитием компьютерной графики и разработкой шины AGP, шина PCI перестала удовлетворять новым, повышенным требованием к видеокартам и перестала использоваться для установки видеокарт.
В настоящее время интерфейс PCI постепенно вытесняется интерфейсами PCI Express, HyperTransport и USB. На современные материнские платы (по состоянию на 2012 год)[источник не указан 66 дней] устанавливается лишь один, редко два PCI-разъёма, вместо 5-6, устанавливавшихся ранее. На некоторые современные материнские платы (в основном High-End-класса или форм-фактора mATX) PCI-разъём не устанавливается вовсе.
Первоначально 32 проводника адрес/данные на частоте 33 МГц. Позже появились версии с 64 проводниками (используется дополнительная колодка разъема) и частотой 66 МГц.
Шина децентрализована, нет главного устройства, любое устройство может стать инициатором транзакции. Для выбора инициатора используется арбитраж с отдельно стоящей логикой арбитра. Арбитраж «скрытый», не отбирает времени — выбор нового инициатора происходит во время транзакции, исполняемой предыдущим инициатором.
Транзакция состоит из 1 или 2 циклов адреса (2 цикла адреса используются для передачи 64-битных адресов, поддерживаются не всеми устройствами, дают поддержку DMA на памяти более 4 Гб) и одного или многих циклов данных. Транзакция со многими циклами данных называется «пакетной» (burst), понимается как чтение/запись подряд идущих адресов и даёт более высокую скорость — один цикл адреса на несколько, а не на каждый цикл данных, и отсутствие простоев (на «успокоение» проводников) между транзакциями.
Специальные типы транзакций используются для обращений к конфигурационному пространству устройства.
«Пакетная» транзакция может быть временно приостановлена обоими устройствами из-за отсутствия данных в буфере или его переполнения.
Поддерживаются «расщеплённые» транзакции, когда целевое устройство отвечает состоянием «в процессе» и инициатор должен освободить шину для других устройств, захватить её снова через арбитраж и повторить транзакцию. Это делается, пока целевое устройство не ответит «сделано». Используется для сопряжения шин с разными скоростями (сама PCI и frontside процессора) и для предотвращения тупиковых ситуаций в сценарии с многими межшинными мостами.
Богатая поддержка межшинных мостов. Богатая поддержка режимов кэширования, таких как:
posted write — данные записи немедленно принимаются мостом, и мост сразу отвечает «сделано», уже после этого пытаясь провести операцию записи на ведомой шине.
write combining — несколько запросов на posted write, идущих подряд по адресам, соединяются в мосте в одну «взрывную» транзакцию на ведомой шине.
prefetching — используется при транзакциях чтения, означает выборку сразу большого диапазона адресов одной «взрывной» транзакцией в кеш моста, дальнейшие обращения исполняются самим мостом без операций на ведомой шине.
Прерывания поддерживаются либо как Message Signaled Interrupts (новое), либо классическим способом с использованием проводников INTA-D#. Проводники прерываний работают независимо от всей остальной шины, возможно разделение одного проводника многими устройствами.
PCI-устройства с точки зрения пользователя самонастраиваемы (Plug and Play). После старта компьютера системное программное обеспечение обследует конфигурационное пространство PCI каждого устройства, подключённого к шине, и распределяет ресурсы.
Каждое устройство может затребовать до шести диапазонов в адресном пространстве памяти PCI или в адресном пространстве ввода-вывода PCI.
Кроме того, устройства могут иметь ПЗУ, содержащее исполняемый код для процессоров x86 или PA-RISC, Open Firmware (системное ПО компьютеров на базе SPARC и PowerPC) или драйвер EFI.
Настройка прерываний осуществляется также системным программным обеспечением (в отличие от шины ISA, где настройка прерываний осуществлялась переключателями на карте). Запрос на прерывание на шине PCI передаётся с помощью изменения уровня сигнала на одной из линий IRQ, поэтому имеется возможность работы нескольких устройств с одной линией запроса прерывания; обычно системное ПО пытается выделить каждому устройству отдельное прерывание для увеличения производительности.
Спецификация
частота шины — 33,33 или 66,66 МГц, передача синхронная;
разрядность шины — 32 или 64 бита, шина мультиплексированная (адрес и данные передаются по одним и тем же линиям);
пиковая пропускная способность для 32-разрядного варианта, работающего на частоте 33,33 МГц — 133 Мбайт/с;
адресное пространство памяти — 32 бита (4 байта);
адресное пространство портов ввода-вывода — 32 бита (4 байта);
конфигурационное адресное пространство (для одной функции) 256 байт;
напряжение 3,3 или 5 В.
Стандартные модификации
Типы PCI-слотов
PCI 2.0
Первая версия базового стандарта, получившая широкое распространение, использовались как карты, так и слоты с сигнальным напряжением только 5 вольт. Пиковая пропускная способность — 133 Мбайт/с.
PCI 2.1 — 3.0
Отличались от версии 2.0 возможностью одновременной работы нескольких шинных задатчиков (англ. bus-master, т. н. конкурентный режим), а также появлением универсальных карт расширения, способных работать как в слотах, использующих напряжение 5 вольт, так и в слотах, использующих 3,3 вольта (с частотой 33 и 66 МГц соответственно). Пиковая пропускная способность для 33 МГц — 133 Мбайт/с, а для 66 МГц — 266 Мбайт/с.
Версия 2.1 — работа с картами, рассчитанными на напряжение 3,3 вольта, наличие соответствующих линий питания являлась опциональной.
Версия 2.2 — сделанные в соответствии с этими стандартами карты расширения имеют универсальный ключ разъёма по питанию и способны работать во многих более поздних разновидностях слотов шины PCI, а также, в некоторых случаях, и в слотах версии 2.1.
Версия 2.3 — несовместима с картами PCI, рассчитанными на использование 5 вольт, несмотря на продолжающееся использование 32-битных слотов с 5-вольтовым ключом. Карты расширения имеют универсальный разъём, но не способны работать в 5-вольтовых слотах ранних версий (до 2.1 включительно).
Версия 3.0 — завершает переход на карты PCI 3,3 вольт, карты PCI 5 вольт больше не поддерживаются.
PCI 64
Расширение базового стандарта PCI, появившееся в версии 2.1, удваивающее число линий данных, и, следовательно, пропускную способность. Слот PCI 64 является удлинённой версией обычного PCI-слота. Формально совместимость 32-битных карт с 64-битным слотами (при условии наличия общего поддерживаемого сигнального напряжения) полная, а совместимость 64-битной карты с 32-битным слотами является ограниченной (в любом случае произойдёт потеря производительности). Работает на тактовой частоте 33 МГц. Пиковая пропускная способность — 266 Мбайт/с.
Версия 1 — использует слот PCI 64-бита и напряжение 5 вольт.
Версия 2 — использует слот PCI 64-бита и напряжение 3,3 вольта.
PCI 66
Версия PCI 66 является работающим на тактовой частоте 66 МГц развитием PCI 64; использует напряжение 3,3 вольта в слоте; карты имеют универсальный, либо форм-фактор на 3,3 В. Пиковая пропускная способность — 533 Мбайт/с.
PCI 64/66
Комбинация PCI 64 и PCI 66, позволяет вчетверо увеличить скорость передачи данных по сравнению с базовым стандартом PCI; использует 64-битные 3,3-вольтовые слоты, совместимые только с универсальными и 3,3-вольтовые 32-битные карты расширения. Карты стандарта PCI64/66 имеют либо универсальный (но имеющий ограниченную совместимость с 32-битными слотами) либо 3,3-вольтовый форм-фактор (последний вариант принципиально не совместим с 32-битными 33-мегагерцовыми слотами популярных стандартов). Пиковая пропускная способность — 533 Мбайт/с.
PCI-X
Основная статья: PCI Extended
Развитие версии PCI 64. Для всех вариантов шины существуют следующие ограничения по количеству подключаемых к каждой шине устройств: 66 МГц — 4, 100 МГц — 2, 133 МГц — 1 (или 2, если одно или оба устройства не находятся на платах расширения, а уже интегрированы на одну плату вместе с контроллером), 266, 533 МГц и выше — 1.
Версия 1.0 — введено две новые рабочие частоты: 100 и 133 МГц, а также механизм раздельных транзакций для улучшения производительности при одновременной работе нескольких устройств. Как правило, обратно совместима со всеми 3,3-вольтовыми и универсальными PCI-картами. Карты обычно выполняются в 64-битном формате на 3,3 В и имеют ограниченную обратную совместимость со слотами PCI64/66, а некоторые — в универсальном формате и способны работать (хотя практической ценности это почти не имеет) в обычном PCI 2.2/2.3. Пиковая пропускная способность — 1024 Мбайт/с.
Версия 2.0 — введено две новые рабочие частоты: 266 и 533 МГц, а также коррекция ошибок чётности при передаче данных (ECC). Расширяет конфигурационное пространство PCI до 4096 байт и допускает расщепление на 4 независимых 16-битных шины, что применяется исключительно во встраиваемых и промышленных системах, сигнальное напряжение снижено до 1,5 В, но сохранена обратная совместимость разъёмов со всеми картами, использующими сигнальное напряжение 3,3 В. Пиковая пропускная способность — 4096 Мбайт/с.
[править]
Mini PCI
Форм-фактор PCI 2.2, предназначен для использования, в основном, в ноутбуках.
Cardbus
PCMCIA форм-фактор для 32-битных карт, 33 МГц PCI.
CompactPCI
Используются модули размера Eurocard, включаемые в PCI backplane.
PC/104-Plus
Индустриальная шина, использующая набор сигналов PCI, но с другим разъёмом.
PMC
PCI Mezzanine Card, мезонинная шина, соответствующая стандарту IEEE P1386.1.
AdvancedTCA (ATCA)
Шина следующего поколения для телекоммуникационной индустрии.
Другие варианты
PCI Express, или PCIe, или PCI-E (также известная как 3GIO for 3rd Generation I/O; не путать с PCI-X и PXI) — компьютерная шина, использующая программную модель шины PCI и высокопроизводительный физический протокол, основанный на последовательной передаче данных.
Разработка стандарта PCI Express была начата фирмой Intel после отказа от шины InfiniBand. Официально первая базовая спецификация PCI Express появилась в июле 2002 года. Развитием стандарта PCI Express занимается организация PCI Special Interest Group.
В отличие от шины PCI, использовавшей для передачи данных общую шину, PCI Express, в общем случае, является пакетной сетью с топологией типа звезда. Устройства PCI Express взаимодействуют между собой через среду, образованную коммутаторами, при этом каждое устройство напрямую связано соединением типа точка-точка с коммутатором.
Кроме того, шиной PCI Express поддерживается:
горячая замена карт;
гарантированная полоса пропускания (QoS);
управление энергопотреблением;
контроль целостности передаваемых данных.
Шина PCI Express нацелена на использование только в качестве локальной шины. Так как программная модель PCI Express во многом унаследована от PCI, то существующие системы и контроллеры могут быть доработаны для использования шины PCI Express заменой только физического уровня, без доработки программного обеспечения. Высокая пиковая производительность шины PCI Express позволяет использовать её вместо шин AGP и тем более PCI и PCI-X. Де-факто PCI Express заменила эти шины в персональных компьютерах.
Для подключения устройства PCI Express используется двунаправленное последовательное соединение типа точка-точка, называемое линией (англ. lane — полоса, ряд); это резко отличается от PCI, в которой все устройства подключаются к общей 32-разрядной параллельной двунаправленной шине.
Соединение (англ. link — связь, соединение) между двумя устройствами PCI Express состоит из одной (x1) или нескольких (x2, x4, x8, x12, x16 и x32) двунаправленных последовательных линий. Каждое устройство должно поддерживать соединение по крайней мере с одной линией (x1).
На электрическом уровне каждое соединение использует низковольтную дифференциальную передачу сигнала (LVDS), приём и передача информации производится каждым устройством PCI Express по отдельным двум проводникам, таким образом, в простейшем случае, устройство подключается к коммутатору PCI Express всего лишь четырьмя проводниками.
Использование подобного подхода имеет следующие преимущества:
карта PCI Express помещается и корректно работает в любом слоте той же или большей пропускной способности (например, карта x1 будет работать в слотах x4 и x16);
слот большего физического размера может использовать не все линии (например, к слоту x16 можно подвести проводники передачи информации, соответствующие x1 или x8, и всё это будет нормально функционировать; однако, при этом необходимо подключить все проводники питания и заземления, необходимые для слота x16).
В обоих случаях, на шине PCI Express будет использоваться максимальное количество линий, доступных как для карты, так и для слота. Однако это не позволяет устройству работать в слоте, предназначенном для карт с меньшей пропускной способностью шины PCI Express. Например, карта x4 физически не поместится в стандартный слот x1, несмотря на то, что она могла бы работать в слоте x1 с использованием только одной линии. На некоторых материнских платах можно встретить нестандартные слоты x1 и x4, у которых отсутствует крайняя перегородка, таким образом, в них можно устанавливать карты большей длины чем разъем. При этом не обеспечивается питание и заземление выступающей части карты, что может привести к различным проблемам.
PCI Express пересылает всю управляющую информацию, включая прерывания, через те же линии, что используются для передачи данных. Последовательный протокол никогда не может быть заблокирован, таким образом задержки шины PCI Express вполне сравнимы с таковыми для шины PCI (заметим, что шина PCI для передачи сигнала о запросе на прерывание использует отдельные физические линии IRQ#A, IRQ#B, IRQ#C, IRQ#D).
Во всех высокоскоростных последовательных протоколах (например, гигабитный Ethernet), информация о синхронизации должна быть встроена в передаваемый сигнал. На физическом уровне, PCI Express использует метод канального кодирования 8b/10b (8 бит в десяти, избыточность — 20%) для устранения постоянной составляющей в передаваемом сигнале и для встраивания информации о синхронизации в поток данных. В PCI Express 3.0 используется более экономное кодирование 128b/130b с избыточностью 1,5%.
Некоторые протоколы (например, SONET/SDH) используют метод, который называется скремблинг (англ. scrambling) для встраивания информации о синхронизации в поток данных и для "размывания" спектра передаваемого сигнала. Спецификация PCI Express также предусматривает функцию скремблинга, но скремблинг PCI Express отличается от такового для SONET.
Битрейт в PCIe 1.0 составляет 2,5 Гбит/с. Для расчёта пропускной способности шины необходимо учесть дуплексность[3] и избыточность 8b/10b (8 бит в десяти). Например, дуплексная пропускная способность соединения x1 составляет:
2,5 · 2 · 0,8 = 4 Гбит/с
где 2,5 — битрейт, Гбит/с;
2 — учёт дуплексности (двунаправленности);
0,8 — учёт избыточности 8b/10b для 1.0 и 2.0; 0,985 — для 3.0;
В одну/обе стороны, Гбит/с Связей
x1 x2 x4 x8 x12 x16 x32
PCIe 1.0 2/4 4/8 8/16 16/32 24/48 32/64 64/128
PCIe 2.0 4/8 8/16 16/32 32/64 48/96 64/128 128/256
PCIe 3.0 8/16 16/32 32/64 64/128 96/192 128/256 256/512
PCIe 4.0 (предварительно) [4] 16/32 32/64 64/128 128/256 192/384 256/512 512/1024
Шина UMI — представляет собой модифицированный интерфейс PCI-E x4 c вдвое увеличеной пропускной способностью, за счет перехода с первой на вторую версию стандарта. Входит в состав чипсета AMD Fusion A55.
1.0
2.0
2.1
3.0
4.0 – в будущем
Слоты расширения предназначены для установки карт различного назначения, расширяющих функциональные возможности компьютера. На слоты выводятся стандартные шины расширения ввода-вывода, а также промежуточные интерфейсы.
Стандартизованные шины расширения ввода-вывода обеспечивают основу функциональной расширяемости РС-совместимого персонального компьютера, который с самого рождения не замыкался на выполнении сугубо вычислительных задач. Хотя многие компоненты, ранее размещавшиеся на платах расширения, постепенно «переселяются» на системную плату, для настольных компьютеров набор шин расширения ввода-вывода имеет важное значение.
Шины PCI и PCI-X являются основными шинами расширения ввода/вывода в современных компьютерах; для подключения видеоадаптеров их дополняет порт AGP. Шины расширения ввода/вывода (Expansion Bus) являются средствами подключения системного уровня: они позволяют адаптерам и контроллерам периферийных устройств непосредственно использовать системные ресурсы компьютера — пространство адресов памяти и ввода/вывода, прерывания, прямой доступ к памяти. Устройства, подключенные к шинам расширения, могут и сами управлять этими шинами, получая доступ к остальным ресурсам компьютера. Шины расширения механически реализуются в виде слотов (щелевых разъемов) или штырьковых разъемов; для них характерна малая длина проводников, то есть они сугубо локальны, что позволяет достигать высоких скоростей работы. Эти шины могут и не выводиться на разъемы, но использоваться для подключения устройств в интегрированных системных платах.
Поначалу шина PCI вводилась как пристройка к системам с шиной ISA. Она разрабатывалась в расчете на процессоры Pentium, но хорошо сочеталась и с процессорами i486. Позже PCI на некоторое время стала центральной шиной: она соединялась с шиной процессора высокопроизводительным мостом («северным» мостом), входящим в состав чипсета системной платы. В современных системных платах с «хабовой» архитектурой шину PCI отодвинули на периферию, не ущемляя ее в мощности канала связи с процессором и памятью, но и не нагружая транзитным трафиком устройств других шин.
Шина PCI является синхронной — фиксация всех сигналов выполняется по положительному перепаду (фронту) сигнала CLK. Номинальной частотой синхронизации считается частота 33,3 МГц, при необходимости она может быть понижена. Начиная с версии PCI 2.1 допускается повышение частоты до 66,6 МГц при «согласии» всех устройств на шине. В PCI-X частота может достигать 133 МГц.
Шина PCI – первая шина в архитектуре IBM PC, которая не привязана к этой архитектуре. Она является процессорно-независимой и применяется, например, в компьютерах Macintosh. В отличие от остальных шин, компоненты расположены на левой поверхности плат PCI-адаптеров. По этой причине крайний PCI –слот обычно разделяет использование посадочного места с соседним ISA-слотом (Shared slot).
Процессор через так называемые мосты (PCI Bridge) может быть подключен к нескольким каналам PCI, обеспечивая возможностьо дновременной передачи данных между независимыми каналами PCI (возможно только в спецификации 2.1).
В PCI используется параллельная мультиплексированная шина адреса/данных (AD) с типовой разрядностью 32 бит. Спецификация определяет возможность расширения разрядности до 64 бит; в PCI-X версии 2.0 определен также 16-битный вариант шины. При частоте шины 33 МГц теоретическая пропускная способность достигает 132 Mбайт/с для 32-битной шины и 264 Мбайт/с для 64-битной; при частоте синхронизации 66 МГц — 264 Мбайт/с и 528 Мбайт/с соответственно. Однако эти пиковые значения достигаются лишь во время передачи пакета: из-за протокольных накладных расходов реальная средняя пропускная способность шины оказывается ниже.
Обмен информацией по шине PCI и PCI-X организован в виде транзакций — логически завершенных операций обмена. В типовой транзакции участвуют два устройства —инициатор обмена (initiator), он же ведущее устройство (master), и целевое устройство (ЦУ, target)), оно же ведомое (slave). Правила взаимодействия этих устройств определяются протоколом шины PCI. Устройство может следить за транзакциями на шине и не являясь их участником (не вводя никаких сигналов); режиму слежения соответствует термин Snooping. Есть особый тип транзакции (Special Cycle) — широковещательный, в котором инициатор протокольно не взаимодействует ни с одним из устройств. В каждой транзакции выполняется одна команда — как правило, чтение или запись данных по указанному адресу. Транзакция начинается с фазы адреса, в которой инициатор задает команду и целевой адрес. Далее могут следовать фазы данных, в которых одно устройство (источник данных) помещает данные на шину, а другое (приемник) их считывает. Транзакции, в которых присутствует множество фаз данных, называются пакетными. Есть и одиночные транзакции (с одной фазой данных). Транзакция может завершиться и без фаз данных, если целевое устройство (или инициатор) не готово к обмену. В шине PCI-X добавлена фаза атрибутов, в которой передается дополнительная информация о транзакции.
В каждый момент времени шиной может управлять только одно ведущее устройство, получившее на это право от арбитра. Каждое ведущее устройство имеет пару сигналов — REQ# для запроса на управление шиной и GNT# для подтверждения предоставления управления шиной. Устройство может начинать транзакцию (устанавливать сигнал FRAME#) только при полученном активном сигнале GNT# и дождавшись отсутствия активности шины. Заметим, что за время ожидания покоя арбитр может «передумать» и отдать управление шиной другому устройству с более высоким приоритетом. Снятие сигнала GNT# не позволяет устройству начать следующую транзакцию, а при определенных условиях (см. далее) может заставить прекратить начатую транзакцию. Арбитражем запросов на использование шины занимается специальный узел — арбитр, входящий в мост, соединяющий данную шину с центром. Схема приоритетов (фиксированный, циклический, комбинированный) определяется программированием арбитра.
PCI-Express (PCIe, PCI-E) – последовательная, универсальная шина впервые обнародованная 22 июля 2002 года.
Является общей, объединяющей шиной для всех узлов системной платы, в которой соседствуют все подключённые к ней устройства. Пришла на замену устаревающей шине PCI и её вариации AGP, по причине возросших требований к пропускной способности шины и невозможности за разумные средства улучшить скоростные показатели последних.
Шина выступает как коммутатор, просто направляя сигнал из одной точки в другую не изменяя его. Это позволяет без явных потерь скорости, с минимальными изменениями и ошибками передать и получить сигнал.
Данные по шине идут симплексно (полный дуплекс), то есть одновременно в обе стороны с одинаковой скоростью, причём сигнал по линиям, течёт непрерывно, даже при отключении устройства (как постоянный ток, или битовый сигнал из нулей).
Синхронизация построена избыточным методом. То есть вместо 8 бит информации, передаётся 10 бит, два из которых являются служебными (20%) и в определённой последовательности служат маячками для синхронизации тактовых генераторов или выявления ошибок. Поэтому, заявленная скорость для одной линии в 2.5 Гбит\с, на самом деле равна примерно 2.0 Гбит\с реальных.
Питание каждого устройства по шине, подбирается отдельно и регулируется с помощью технологии ASPM (Active State Power Management). Она позволяет при простое (без подачи сигнала) устройства занижать его тактовый генератор и переводить шину в режим пониженного энергопотребления. Если сигнал не поступал в течение нескольких микросекунд, устройство считается неактивным и переводится в режим ожидания (время зависит от типа устройства).
36.USB (Universal Serial Bus— универсальная последовательная шина) является промышленным стандартом расширения архитектурыPC, ориентированным на интеграцию с телефонией и устройствами бытовой электроники. ШинаUSBсовсем молодая — версия 1.0 была опубликована в начале 1996 года, и скептики иронично расшифровывали ее название как «неиспользуемая последовательная шина» (UnusedSerialBus). Однако сейчас устройств с интерфейсомUSBуже предостаточно. Шина позволяет соединять устройства, удаленные от компьютера на расстояние до 25 м (с использованием промежуточных хабов). ШипаUSBориентирована на периферийные устройства, подключаемые кPC. Изохронные передачиUSВ позволяют передавать цифровые аудио-сигналы, видеоданные. Все передачи управляются централизованно, иPCявляется необходимым управляющим узлом, находящимся в корне древовидной структуры шины. АдаптерUSBпользователи современных ПК получают почти бесплатно, поскольку он входит в состав всех современных чипсетов системных плат. Непосредственное соединение несколькихPCшинойUSBне предусматривается, хотя выпускаются «активные кабели» для связи пары компьютеров и устройства-концентраторы.
^ Организация шины USB
USBобеспечивает обмен данными между хост-компьютером и множеством периферийных устройств (ПУ). Согласно спецификацииUSB, устройства (device) могут являться хабами, функциями или их комбинацией. Хаб (hub) только обеспечивает дополнительные точки подключения устройств к шине. Устройство-функция (function)USBпредоставляет системе дополнительные функциональные возможности, например подключение кISDN, цифровой джойстик, акустические колонки с цифровым интерфейсом и т. п. Комбинированное устройство (compounddevice), реализующее несколько функций, представляется как хаб с подключенными к нему несколькими устройствами. УстройствоUSBдолжно иметь интерфейсUSB, обеспечивающий полную поддержку протоколаUSB, выполнение стандартных операций (конфигурирование и сброс) и предоставление информации, описывающей устройство. Работой всей системыUSBуправляет хост-контроллер (hostcontroller), являющийся программно-аппаратной подсистемой хост-компьютера. Шина позволяет подключать, конфигурировать, использовать и отключать устройства во время работы хоста и самих устройств.
Шина USBявляется хост-центрической: единственным ведущим устройством, которое управляет обменом, является хост-компьютер, а все присоединенные к ней периферийные устройства — исключительно ведомые.
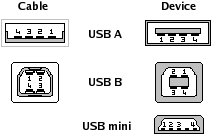
В отличие от громоздких дорогих шлейфов параллельных шин АТА и особенно шины SCSIс ее разнообразием разъемов и сложностью правил подключения, кабельное хозяйствоUSBпростое и изящное. КабельUSBсодержит одну экранированную витую пару с импедансом 90 Ом для сигнальных цепей и одну неэкранированную для подачи питания (+5 В), допустимая длина сегмента — до -5 м. Система кабелей и коннекторовUSBне дает возможности ошибиться при подключении устройств. Для распознавания разъемаUSBна корпусе устройства ставится стандартное символическое обозначение.
Каждое устройство на шине USB(их может быть до 127) при подключении автоматически получает свой уникальный адрес. Логически устройство представляет собой набор независимых конечных точек (endpoint), с которыми хост-контроллер (и клиентское ПО) обменивается информацией.
Каждое устройство обязательно имеет конечную точку с номером 0, используемую для инициализации, общего управления и опроса его состояния.
Кроме нулевой точки устройства-функции могут иметь дополнительные точки, реализующие полезный обмен данными. Дополнительные точки не могут быть использованы до их конфигурирования (установления согласованного с ними канала).
Каналом (pipe) вUSBназывается модель передачи данных между хост-контроллером и конечной точкой устройства. Имеются два типа каналов: потоки и сообщения. Поток (stream) доставляет данные от одного конца канала к другому, он всегда однонаправленный. Сообщения (message) имеют формат, определенный спецификациейUSB.
Каналы организуются при конфигурировании устройств USB. Для каждого включенного устройства существует канал сообщений (ControlPipe0), по которому передается информация конфигурирования, управления и состояния.
^ Типы передач данных
Архитектура USBдопускает четыре базовых типа передачи данных.
1 Управляющие посылки (controltransfers) 1
2 Передачи массивов данных (bulkdatatransfers)
3 Прерывания (interrupt)
4 Изохронные передачи (isochronoustransfers)
Архитектура USBпредусматривает внутреннюю буферизацию всех устройств, причем чем большей полосы пропускания требует устройство, тем больше должен быть его буфер.USBдолжна обеспечивать обмен с такой скоростью, чтобы задержка данных в устройстве, вызванная буферизацией, не превышала нескольких миллисекунд.
^ Устройства и хабы
Хаб — кабельный концентратор — является ключевым элементом системы РnР в архитектуреUSB. Хаб выполняет множество функций:
1 обеспечивает физическое подключение устройств, формируя и воспринимая сигналы в соответствии со спецификацией шины на каждом из своих портов;
управляет подачей питающего напряжения на нисходящие порты, причем предусматривается установка ограничения на ток, потребляемый каждым портом;
отслеживает состояние подключенных к нему устройств, уведомляя хост об изменениях;
обнаруживает ошибки на шине, выполняет процедуры восстановления и изолирует неисправные сегменты шины;
5 обеспечивает связь сегментов шины, работающих на разных скоростях.
Устройства, подключенные к шине USB, могут пребывать в следующих состояниях:
Attached— устройство подключено, но питание еще не подано;
Powered— устройство подключено, питание подано, но еще не выполнен сброс;
3 Default— устройство подключено, питание подано и выполнен сброс, но уникальный адрес еще не назначен, и устройство отзывается по «дежурному» нулевому адресу;
4 Address— устройство подключено, питание подано, выполнен сброс и назначен уникальный адрес, но устройство еще не сконфигурировано;
5 Configured— устройство подключено, питание подано, выполнен сброс, назначен уникальный адрес и устройство сконфигурировано; хост может использовать функции, предоставляемые устройством; после конфигурирования (начального или смены конфигурации) все регистры, счетчики и т. п. программные и аппаратные элементы устанавливаются в исходное состояние;
6 Suspended— устройство подключено и питание подано, но приостановлено в целях энергосбережения (по отсутствию активности шины в течение определенного времени); устройство может уже иметь уникальный адрес и быть сконфигурированным, но хост не «может использовать функции, предоставляемые устройством (устройство выйдет из этого состояния, когда обнаружит активность шины).
Хост
У каждой шины USBдолжен быть один (и только один!) хост-компьютер с контроллеромUSB. Хост делится на три основных уровня.
^ 1 Интерфейс шины USB
2 Система USB. Система состоит из трех основных частей.
А Драйвер хост-контроллера — HCD (Host Controller Driver) —
Б Драйвер USB — USBD (USB Driver)
В Программное обеспечение хоста
3 Клиенты USB
В совокупности уровни хоста имеют следующие возможности:
обнаружение фактов подключения и отсоединения устройств USB;
манипулирование потоками управления между устройствами и хостом;
манипулирование потоками данных;
сбор статистики активности и состояний устройств;
5 управление электрическим интерфейсом между хост-контроллером и устройствами USB, включая управление электропитанием.
Хост-контроллер является аппаратным посредником между устройствами USBи хостом.
USBподдерживает динамическое подключение и отключение устройств. Нумерация устройств шины является постоянным процессом, отслеживающим изменения физической топологии.
Хост определяет, является новое подключенное устройство хабом или функцией, и назначает ему уникальный адрес USB.
^ Применение шины USB
Благодаря своей универсальности и способности эффективно передавать разнородный трафик шина USBприменяется для подключения кPCсамых разнообразных устройств. Она призвана заменить традиционные портыPC— СОМ иLPT, а также порты игрового адаптера и интерфейсаMIDI. ПривлекательностьUSBпридает возможность подключения/отключения устройств на ходу и возможность их использования практически сразу, без перезагрузки ОС.
Основные области применения USB:
Устройства ввода — клавиатуры, мыши, трекболы, планшетные указатели и т. п. Здесь USBпредоставляет единый интерфейс для различных устройств.
Принтеры — USBобеспечивает примерно ту же скорость, что иLPT-порт в режиме ЕСР, но при использованииUSBне возникает проблем с длиной кабеля и подключением нескольких принтеров к одному компьютеру (правда, требуются хабы), а так же позволит ускорить печать в режиме высокого разрешения за счет сокращения времени на передачу больших массивов данных:
Сканеры: применение USBпозволяет отказаться от использования контроллеровSCSIили занятияLPT-порта.
Аудио — колонки, микрофоны, головные телефоны (наушники). USBпозволяет передавать потоки данных, достаточные для обеспечения самого высокого качества. Передача в цифровом виде от самого источника сигнала до приемника и цифровая обработка в хост-компьютере обеспечивают избавление от проблем наводок.
^ Музыкальные синтезаторы и MIDI-контроллеры с интерфейсомUSB— шина позволяет компьютеру обрабатывать потоки множества каналовMIDI
Видео- и фотокамеры — USBпозволяет передавать статические изображения любого разрешения за приемлемое время, а также передавать поток видеоданных с достаточной частотой кадров и высоким разрешением без сжатия (и потери качества). С интерфейсомUSBвыпускают как камеры, так и устройства захвата изображения с телевизионного сигнала иTV-тюнеры.
Коммуникации — с интерфейсом USBвыпускают разнообразные модемы, включая кабельные иxDSL, адаптеры высокоскоростной инфракрасной связи (IrDAFIR) — шина позволяет преодолеть предел скорости СОМ-порта (115,2 Кбит/с), не повышая загрузку центрального процессора.
^ Преобразователи интерфейсов позволяют через порт USB, имеющийся теперь практически на всех компьютерах, подключать устройства с самыми разнообразными интерфейсами.
^ Устройства хранения — винчестеры, устройства чтения и записи CDиDVD, стримеры скорость передачи данных становится соизмеримой с АТА иSCSI, а ограничений по количеству устройств достичь трудно.
Игровые устройства — джойстики всех видов (от «палочек» до автомобильных рулей), пульты с разнообразными датчиками (непрерывными и дискретными) и исполнительными механизмами— подключаются унифицированным способом.
Телефоны — аналоговые и цифровые (ISDN). Подключение телефонного аппарата позволяет превратить компьютер в секретаря с функциями автодозвона, автоответчика, охраны и т. п.
Мониторы. — здесь шина USBиспользуется для управления параметрами монитора.USB-мониторы позволяют системе управлять ими — регулировки яркости, контраста, цветовой температуры и т. п. могут теперь выполняться программно, а не только от кнопок лицевой панели монитора.
Электронные ключи — устройства с любым уровнем интеллектуальной защиты могут быть выполнены в корпусе вилок USB. Они гораздо компактнее и мобильнее аналогичных устройств для СОМ- иLPT-портов.
Хабы USBвыпускаются как в виде отдельных устройств, так и встраиваются в периферийные устройства (клавиатуры, мониторы).
232C (COM port) до 115 Kбит/с (~ 10 Кбайт/с)
Centronics (LPT port) 30 – 100 Кбайт/с IEEE-1284 (EPP, ECP) до 1-2 Мбайт/с (зависит от кабеля)
USB 1.0 – до 12 Мбит/с (до 1.5 Мбайт/с) 2.0 – до 480 Мбит/с (до 60 Мбайт/с) 3.0 – до 4.8 Гбит/с (*)(до 600 Мбайт/с)
IEEE-1394 (FireWire 800) до 90 Мбайт/с IEEE-1394b (FireWire S3200) до 3.2 Гбит/с (до 400 Мбайт/с)
PCMCIA первоначально расшифровывалась как Peripheral Component Microchannel Interconnect Architecture, позднее – Personal Computer Memory Card International Association, начиная со второй версии спецификации стали использовать термин PC Card.
Принтеры, модемы и другое периферийное оборудование подключается к компьютеру через стандартизированные интерфейсы, иногда называемые портами. В зависимости от способа передачи информации (параллельного или последовательного) между сопрягаемыми устройствами различают параллельные и последовательные интерфейсы.
Последовательный порт RS-232-C
Интерфейс RS-232-C разработан EIA (Electronic Industries Association - Ассоциация производителей электроники) и является стандартом для соединения ЭВМ с различными последовательными внешними устройствами, в качестве которых первоначально выступали в основном терминалы и печатающие устройства. В операционных системах компьютеров IBM PC каждому порту RS-232-C присваивается логическое имя СOМ1: -COM4:.
Последовательная передача данных состоит в побитовой передаче каждого байта цифровой информации, в форме кадра данных, содержащего сигнал начала передачи (Start), сигнал окончания передачи (Stop) и информационные биты.

Структура кадра данных при передаче байта информации в стандарте RS-232-C
Бит ST сигнализирует о начале передачи данных, затем передается информационные биты - вначале младшие, потом старшие.
Иногда используется контрольный бит Р, которому присваивается такое значение, чтобы общее число единиц или нулей было четным или нечетным. Это применяется для контроля правильности передачи кадра. Приемное устройство проверяет кадр на четность и при несовпадении с ожидаемым значением передает запрос о повторе передачи кадра. Бит (или биты) SP сигнализирует об окончании передачи байта.
Использование (или нет) битов р, ST, SP задает формат передачи данных (кадра) на уровне RS-232. Принимающее и передающее устройства должны применять одинаковые форматы.
Основу последовательного порта составляет микросхема UART (Universal Asyncronous Receiver-Transmitter - универсальный асинхронный приемопередатчик - Intel 16450/16550/16550А).
Разъем для подключения последовательного порта может содержать 25 или 9 выводов (соответственные обозначения - D25 и D9). Только два провода этих разъемов используются для передачи и приема данных, остальные отведены для вспомогательных и управляющих сигналов.
Стандарт RS-232-C определяет взаимодействие между устройствами двух типов:
DTE (Data terminal equipment - оконечное/терминальное устройство);
DCE (Data communication equipment - устройство связи).
В большинстве случаев компьютер, терминал являются DTE, модемы, принтеры, графопостроители - DCE.
Если опустить ненужные подробности, то можно сказать, что для связи DTE-DCE (например, компьютер-внешний модем) в Разъемах необходимо осуществить соединение проводов по принципу «вход-вход» и «выход-выход», для связи же DTE-DTE (например, компьютер-компьютер) принцип соединения другой - «вы-ход-вход» и «вход-выход» (такое соединение в обиходе получило название нуль-модем).
При передаче цифровых (импульсных) данных на большие расстояния по обычным проводам начинают сказываться эффекты так называемых «длинных линий», впервые обнаруженные при прокладке трансатлантического кабеля для телеграфной связи Европа-Америка. Сигналы расплываются, накладываются друг на друга создают помехи и подвержены внешним помехам. Для избежания данных эффектов необходимо использование кабелей связи с высокими характеристиками, а также установка на линии электронных устройств, корректирующих передаваемые сигналы (повторители), либо применение модемов.

Искажение импульсных сигналов в длинных линиях
а - исходный вид; б - вид на стороне приемника
По аналогичным причинам передача цифровой информации при соединениях типа DCE-DCE и DCE-DTE, описанных выше, ограничена определенными расстояниями. Официальное ограничение по длине соединительного кабеля по стандарту RS-232-C составляет 15.24 м. На практике это расстояние зависит от скорости передачи данных и может быть значительно больше.
Параллельный порт (Centronics) используется для одновременной передачи 8 битов информации. В компьютерах этот порт используется главным образом для подключения принтера, хотя это не исключает возможность подсоединения к нему других устройств, например графопостроителей или даже других ПЭВМ.
Параллельные порты компьютера обозначаются LPT1- LPT4, поддерживаются BIOS-прерыванием INT 17h:
00h - вывод символа без аппаратных прерываний;
O1h - инициализация интерфейса и принтера;
02h - опрос состояния принтера.
Конструктивно порт обычно оформлен в виде 25-контактного разъема типа D (DB25).
Имеется восемь шин данных, для каждой из них - своя линия заземления.
Кроме того, имеются управляющие сигналы:
сигнал строба strobe на контакте 1 сообщает принтеру, что текущая передача данных окончена и принтер может печатать символ;
линия подтверждения готовности АСК на контакте 10. До тех пор, пока на этой линии высокий потенциал, компьютер не посылает данных;
линия занятости Busy сигнализирует компьютеру о том, что принтер занят;
линия выбора Select показывает, что принтер выбран (то есть режим on-line);
линия автоматического перевода строки Fdxt;
линия ошибки Error - принтер сообщает об ошибке (например, кончилась бумага);
линия Ink - компьютер переводит принтер в то состояние, в котором он находился после включения питания (то есть начальное состояние);
линия Slctin - по этой линии компьютеру сообщается, готов ли принтер принимать данные (при низком уровне сигнала - готов, при высоком - нет).
Параллельное соединение применяется на расстояниях не более 5 метров, некоторые источники ограничивают расстояние 1-2 метров; при увеличении длины параллельных проводов возрастает межпроводная емкость, что приводит к перекрестным помехам, кроме того, растут материальные затраты на реализацию линии.
В принципе, параллельные порты должны быть двунаправленными и соответствовать требованиям стандарта ЕРР, поскольку он позволяет передавать данные в 10 раз быстрее, чем стандартные параллельные порты (2 Мбит/с против 200 Кбит/с).
Порт располагается обычно на задней стенке компьютера как D-образная 25-контактная розетка. Там может также иметься D-об-разная 25-контактная вилка.
Более новые параллельные порты выполнены в стандарте IEEE 1284, первая редакция которого вышла в 1994 году Этот стандарт определяет пять следующих режимов работы:
Режим совместимости.
Режим тетрады.
Режим байтов.
Режим ЕРР (Расширенный параллельный порт).
Режим ЕСР (Режим с расширенными возможностями).
Centronics - это ранний стандарт для передачи данных от ведущего устройства к принтеру. Большинство принтеров использует этот протокол передачи. Подтверждение передачи обычно осуществляется путем программного управления стандартным параллельным портом.
Когда компьютер включается впервые, BIOS (базовая система ввода-вывода) определяет число имеющихся портов и назначает им имена lpt1, lpt2 и lpt3. BIOS сначала проверяет адрес 3BCh. Если параллельный порт найден здесь, ему назначается имя LPT1, затем проверяется адрес 378h. Если контроллер параллельного порта найден там, ему назначается следующее свободное имя устройства. Это было бы LPT1, если плата не была найдена по 3BCh, или LPT2, если бы она была найдена в 3BCh. Последний опрашиваемый порт - 278h, и для него следует та же самая процедура. Поэтому можно иметь LPT2 с адресом 378h, а не 278h, как ожидалось.
Перечисленные режимы конфигурируются через BIOS.
Интерфейс Fire Ware (IEEE 1394)
Из главных особенностей IEEE 1394 можно отметить:
последовательная шина вместо параллельного интерфейса позволила использовать кабели малого диаметра и разъемы малого размера;
поддержка «горячего подключения» и отключения;
питание внешних устройств через IEEE 1394 кабель;
высокая скорость;
возможность строить сети различной конфигурации из разнотипных устройств;
простота конфигурации и широта возможностей;
поддержка асинхронной и синхронной передачи данных.
Интерфейс во многом подобен USB 1.0, но является более быстродействующим. В различных спецификациях устанавливается быстродействие от 12.5 Мбит/с до 1.6 Гбит/с и более.
Это создает возможность для соединения интерфейсом FireWire ЭВМ с такими устройствами, как аналоговые и цифровые видеокамеры, телевизоры, принтеры, сетевые карты и накопители информации.
USB (Universal Serial Bus - «универсальная последовательная шина») – последовательный интерфейс передачи данных для среднескоростных и низкоскоростных периферийных устройств.
Для подключения периферийных устройств к шине USB используется четырёх-проводный кабель, при этом два провода (витая пара) в дифференциальном включении используются для приёма и передачи данных, а два провода - для питания периферийного устройства. Благодаря встроенным линиям питания USB позволяет подключать периферийные устройства без собственного источника питания (максимальная сила тока, потребляемого устройством по линиям питания шины USB, не должна превышать 500мА, у USB 3.0— 900мА).
USB
2.0
![]()
USB
3.0
Поддерживаемые скорости
Low Speed (1.1, 2.0) rate of 1.5 Mbit/s (187 KB/s).
Full Speed (1.1, 2.0) rate of 12 Mbit/s (1.5 MB/s).
Hi-Speed (2.0) rate of 480 Mbit/s (60 MB/s).
Super-Speed (3.0) rate of 4.8 Gbit/s (600 MB/s).
Разъемы USB
Составляющие USB
Host controller
Root Hub
Hub
Function
Device
Port
Logical Device
USB (Universal system bus) - стандарт, разработанный совместно фирмами Compaq, DEC, Microsoft, IBM, Intel, NEC и Northern Telecom (версия первого утвержденного варианта появилась довольно давно - 15 января 1996 года ) и предназначенный для организации соединения многочисленных и разнотипных внешних устройств с помощью единого интерфейса.
Стандарт USB предполагает взаимодействие по архитектуре «клиент-сервер» (используется терминология «Master-Slave», или «главный-служебный») и позволяет подключать до 127 устройств последовательно или используя концентратор USB (hub), к которому подсоединяется до семи устройств. Разъемы содержат четыре контакта, включая провода питания (5 В) для устройств с малым потреблением, таких как клавиатуры, мыши, джойстики и тому подобное
USB обеспечивает обмен данными между хост-компьютером и множеством периферийных устройств (ПУ). Согласно спецификации USB, устройства (device) могут являться хабами, функциями или их комбинацией. Хаб (hub) только обеспечивает дополнительные точки подключения устройств к шине. Устройство-функция (function) USB предоставляет системе дополнительные функциональные возможности, например подключение к ISDN, цифровой джойстик, акустические колонки с цифровым интерфейсом и т. п. Комбинированное устройство (compound device), реализующее несколько функций, представляется как хаб с подключенными к нему несколькими устройствами. Устройство USB должно иметь интерфейс USB, обеспечивающий полную поддержку протокола USB, выполнение стандартных операций (конфигурирование и сброс) и предоставление информации, описывающей устройство. Работой всей системы USB управляет хост-контроллер (host controller), являющийся программно-аппаратной подсистемой хост-компьютера. Шина позволяет подключать, конфигурировать, использовать и отключать устройства во время работы хоста и самих устройств.
Каждое устройство на шине USB (их может быть до 127) при подключении автоматически получает свой уникальный адрес. Логически устройство представляет собой набор независимых конечных точек (endpoint), с которыми хост-контроллер (и клиентское ПО) обменивается информацией. Каждое устройство обязательно имеет конечную точку с номером 0, используемую для инициализации, общего управления и опроса его состояния. Кроме нулевой точки устройства-функции могут иметь дополнительные точки, реализующие полезный обмен данными. Дополнительные точки не могут быть использованы до их конфигурирования (установления согласованного с ними канала). Каналом (pipe) в USB называется модель передачи данных между хост-контроллером и конечной точкой устройства. Имеются два типа каналов: потоки и сообщения. Поток (stream) доставляет данные от одного конца канала к другому, он всегда однонаправленный.Сообщения (message) имеют формат, определенный спецификацией USB. Каналы организуются при конфигурировании устройств USB. Для каждого включенного устройства существует канал сообщений (Control Pipe 0), по которому передается информация конфигурирования, управления и состояния.
Типы передач данных Архитектура USB допускает четыре базовых типа передачи данных. 1 Управляющие посылки (control transfers) 1 2 Передачи массивов данных (bulk data transfers) 3 Прерывания (interrupt) 4 Изохронные передачи (isochronous transfers)
Архитектура USB предусматривает внутреннюю буферизацию всех устройств, причем чем большей полосы пропускания требует устройство, тем больше должен быть его буфер. USB должна обеспечивать обмен с такой скоростью, чтобы задержка данных в устройстве, вызванная буферизацией, не превышала нескольких миллисекунд. Устройства и хабы
Хаб — кабельный концентратор — является ключевым элементом системы РnР в архитектуре USB. Хаб выполняет множество функций: 1 обеспечивает физическое подключение устройств, формируя и воспринимая сигналы в соответствии со спецификацией шины на каждом из своих портов;
управляет подачей питающего напряжения на нисходящие порты, причем предусматривается установка ограничения на ток, потребляемый каждым портом;
отслеживает состояние подключенных к нему устройств, уведомляя хост об изменениях;
обнаруживает ошибки на шине, выполняет процедуры восстановления и изолирует неисправные сегменты шины;
обеспечивает связь сегментов шины, работающих на разных скоростях.
Хост
У каждой шины USB должен быть один (и только один!) хост-компьютер с контроллером USB. Хост делится на три основных уровня. 1 Интерфейс шины USB 2 Система USB. Система состоит из трех основных частей. А Драйвер хост-контроллера — HCD (Host Controller Driver) Б Драйвер USB - USBD (USB Driver) В Программное обеспечение хоста 3 Клиенты USB В совокупности уровни хоста имеют следующие возможности:
обнаружение фактов подключения и отсоединения устройств USB;
манипулирование потоками управления между устройствами и хостом;
манипулирование потоками данных;
сбор статистики активности и состояний устройств;
управление электрическим интерфейсом между хост-контроллером и устройствами USB, включая управление электропитанием. Хост-контроллер является аппаратным посредником между устройствами USB и хостом. USB поддерживает динамическое подключение и отключение устройств. Нумерация устройств шины является постоянным процессом, отслеживающим изменения физической топологии. Хост определяет, является новое подключенное устройство хабом или функцией, и назначает ему уникальный адрес USB.
Применение шины USB
Благодаря своей универсальности и способности эффективно передавать разнородный трафик шина USB применяется для подключения к PC самых разнообразных устройств. Она призвана заменить традиционные порты PC - СОМ и LPT, а также порты игрового адаптера и интерфейса MIDI. Привлекательность USB придает возможность подключения/отключения устройств на ходу и возможность их использования практически сразу, без перезагрузки ОС.
Устройства ввода информации. Сенсорные экраны.