

МИНИСТЕРСТВО ОБРАЗОВАНИЯ РОССИИ
ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ УПРАВЛЕНИЯ
Институт информационных систем управления Лабораторная работа №1
по дисциплине
ПРОГНОЗИРОВАНИЕ СОЦИАЛЬНО-ЭКОНОМИЧЕСКОГО РАЗВИТИЯ
Студента: Голуба А.А.
Специальность: Математические методы и исследование операций в экономике
Курс: IV
Группа: I
Преподаватель: Писарева О.М.
Москва 2001
Проверка гипотезы о наличии тренда методом фостера-стюарта
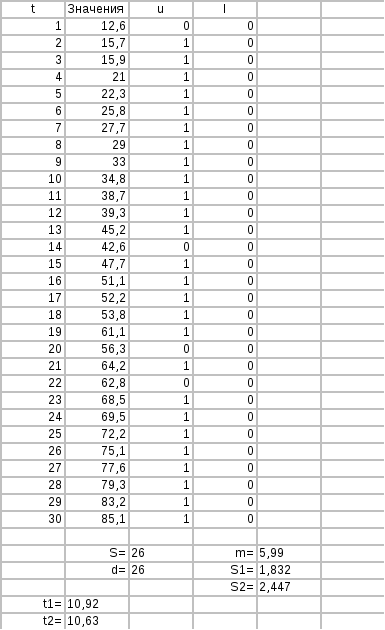
Поскольку t1 и t2>t табличного гипотеза о наличии тренда в средних и дисперсиях не отклоняется.
Построение тренда
При построение тренда для 30 данных получим следующие результаты:
|
Формула |
R2 |
Коэффициент Тейла |
|
Соl_2=10,148+2,492*Col_1 |
99,57 |
0,027 |
|
Col_2=9,1*Col_10.63 |
96,61 |
0,111 |
|
Col_2=(3,87+0,19*Col_1)2 |
98,21 |
0,111 |
|
Col_2=e2,84+0,059*Col_1 |
93,73 |
0,31 |
Из таблицы видно, что лучшей моделью является линейная. Построим эту модель по 35 данным.
Сol_2=10,1371+2,4938*Col_1
Построим доверительный интервал: 95,96 < Y < 103,86
Доверительный интервал для a: 9,14 < a < 11,13
Доверительный интервал для b: 2,44 < b < 2,54
Проверка гипотезы о правильности выбора вида тренда
Проверка гипотезы о правильности выбора вида тренда заключается в том, что отклонения от тренда будут носить случайный характер.
Критерий серий (основанный на медиане выборки)
Рассчитаем отклонения от тренда 1,2, … ,30, отсортировав, найдем медианное значение. Рассмотрим исходный ряд отклонений и сравним полученные значения с медианныммедпо следующему правилу
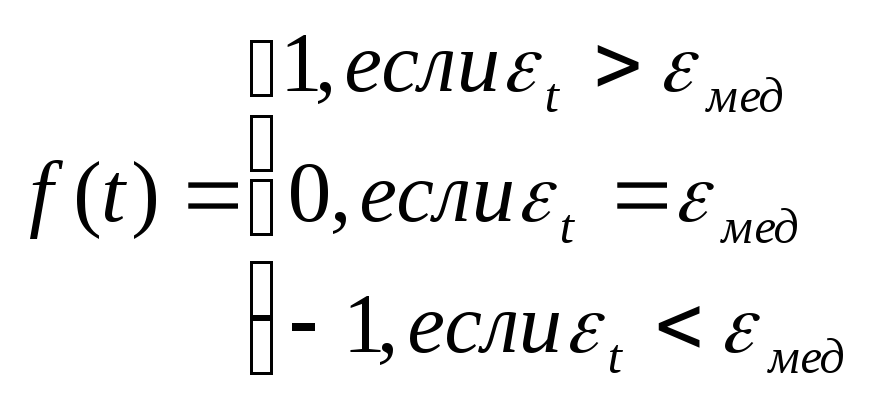
Последовательность идущих подряд 1 или –1 называется серией. Если отклонения от тренда случайные, то чередование серий должно быть также случайным. Для аналитической оценки случайности отклонений используют следующий метод: подсчитывают длину самой длинной серии Кмах(30) и общее число серий(30). Выборка признается случайной если выполняются следующие неравенства (для 5% уровня значимости):
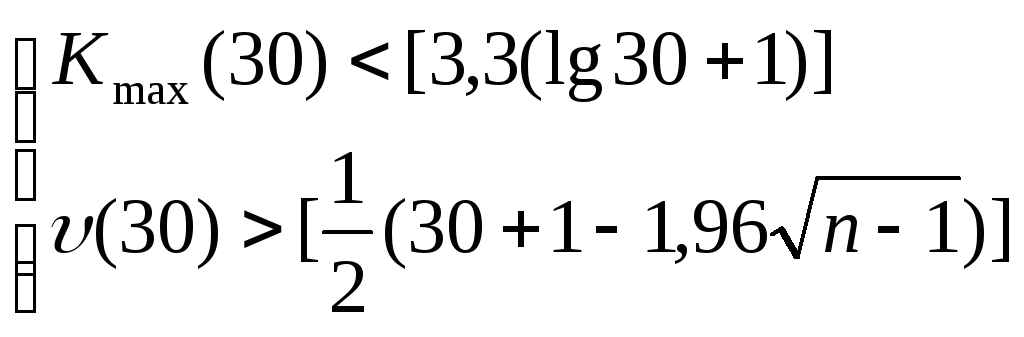
В результате расчетов получили, что медиана мед=-2,15,
Kmax(30) = 2 < 8,175
(30) = 23 >10,223.
Таким образом, отклонение уравнений временного ряда от тренда случайно, и уравнение тренда составлено правильно.
Проверка гипотезы о стационарности случайного компонента
Основным условием стационарности случайного процесса является зависимость автокорреляционной функции только от разности аргументов
ti – tj = . На практике ориентируются на n / 4, в нашем случае = 7.
Для
проверки гипотезы
о том, что значение автокорреляционной
функции зависит не от выбора начала
отсчета наблюдений, а только от величины
сдвига ,
найдем для случайного компонента
t
(t
= 1, …, 30)
значения автокорреляционной функции
![]() .
Затем, исключив последнее наблюдение
найдем новую автокорреляционную функцию
.
Затем, исключив последнее наблюдение
найдем новую автокорреляционную функцию![]() ,
и так далее, исключаяk
(k = 0, 1, …, K) наблюдений,
получим
= 7 групп,
содержащих по K
+ 1 коэффициентов
автокорреляции, так как рассматриваемый
ряд наблюдений содержит 30 значений, то
возьмем К=10, большее количество брать
не целесообразно, т.к. ряд не будет
коротким и полученные коэффициенты не
будут адекватными реальной ситуации.
,
и так далее, исключаяk
(k = 0, 1, …, K) наблюдений,
получим
= 7 групп,
содержащих по K
+ 1 коэффициентов
автокорреляции, так как рассматриваемый
ряд наблюдений содержит 30 значений, то
возьмем К=10, большее количество брать
не целесообразно, т.к. ряд не будет
коротким и полученные коэффициенты не
будут адекватными реальной ситуации.
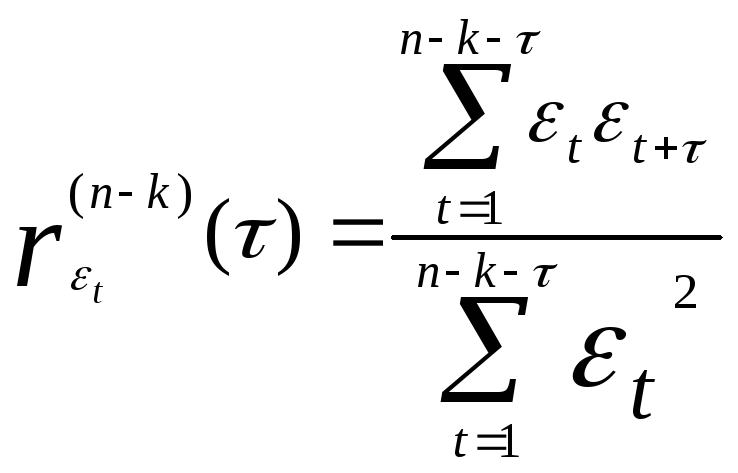
Для стационарного в широком смысле случайного процесса коэффициенты автокорреляции, входящие в одну и ту же группу должны быть однородными.
Для
проверки на однородность для каждого
из
![]() вычисляют
величинуz-критерия
вычисляют
величинуz-критерия
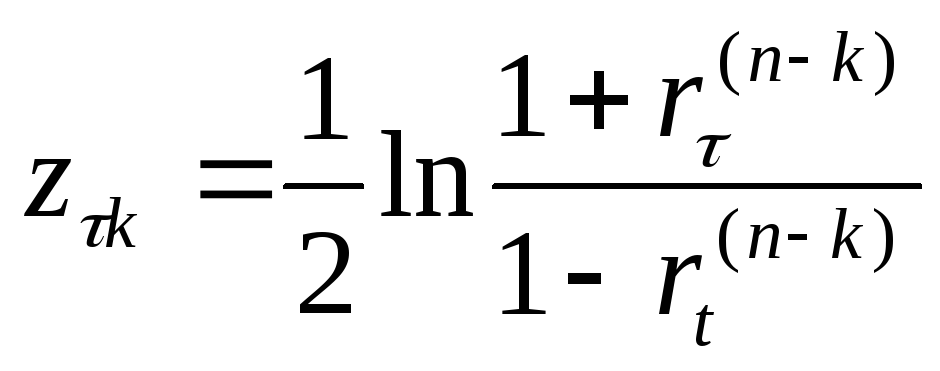 ,
затем рассчитывают для каждой группы
,
затем рассчитывают для каждой группы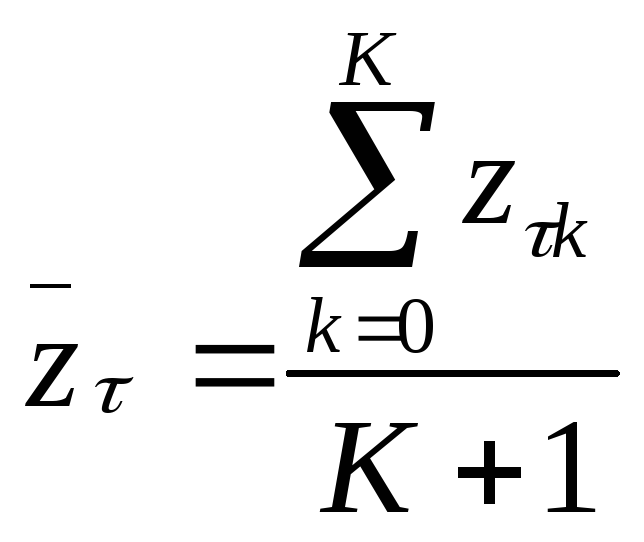 .
Далее для каждой группы рассчитывается
значение
.
Далее для каждой группы рассчитывается
значение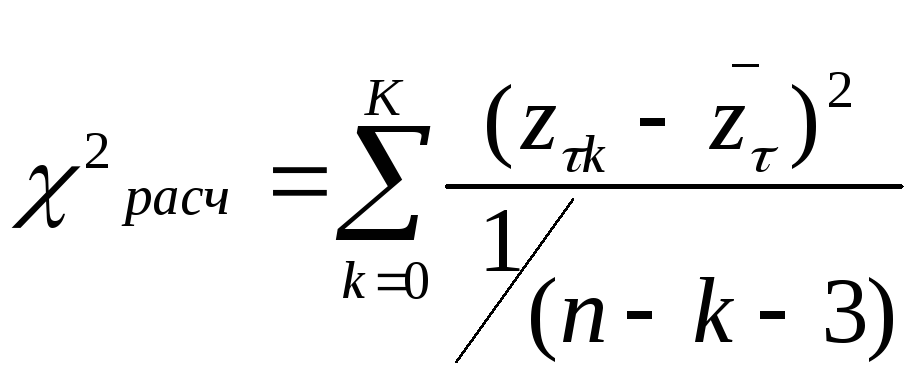 ,
которое сравнивается табличным2
(K).
,
которое сравнивается табличным2
(K).
Если 2расч < 2 (K), то гипотеза об однородности -й группы не отвергается. Если гипотеза об однородности не отвергается для всех групп, то можно принять, что автокорреляционная функция зависит не от начала отсчета, а только от разности ti – tj = , т.е. случайный компонент представляет собой стационарный в широком смысле случайный процесс.
Таблица коэффициентов автокорреляции.
|
|
=1 |
=2 |
=3 |
=4 |
=5 |
=6 |
=7 |
|
30 |
-0,732 |
-0,33 |
-0,125 |
0,02 |
-0,3 |
-0,02 |
0,086 |
|
29 |
-0,735 |
-0,341 |
-0,134 |
0,015 |
-0,308 |
-0,027 |
0,083 |
|
28 |
-0,736 |
-0,34 |
-0,14 |
0,008 |
-0,295 |
-0,029 |
0,118 |
|
27 |
-0,738 |
-0,339 |
-0,138 |
-0,004 |
-0,3 |
-0,061 |
0,086 |
|
26 |
-0,74 |
-0,343 |
-0,136 |
-0,005 |
-0,292 |
-0,051 |
0,122 |
|
25 |
-0,739 |
-0,338 |
-0,135 |
0,004 |
-0,28 |
-0,012 |
0,153 |
|
24 |
-0,741 |
0,338 |
-0,144 |
-0,007 |
-0,314 |
-0,048 |
0,146 |
|
23 |
-0,736 |
-0,345 |
-0,16 |
-0,07 |
-0,372 |
-0,085 |
0,104 |
|
22 |
-0,71 |
-0,296 |
-0,008 |
0,046 |
-0,332 |
0,025 |
0,183 |
|
21 |
-0,703 |
-0,504 |
-0,248 |
0,009 |
-0,401 |
-0,127 |
0,166 |
Z-критерий
|
-0,4749 |
-0,2094 |
-0,0490 |
-0,1682 |
-0,1413 |
0,0313 |
0,0450 |
|
-0,4840 |
-0,2186 |
-0,0554 |
-0,1765 |
-0,1479 |
0,0265 |
0,0433 |
|
-0,4835 |
-0,2217 |
-0,0615 |
-0,1708 |
-0,1440 |
0,0415 |
0,0628 |
|
-0,4834 |
-0,2202 |
-0,0666 |
-0,1803 |
-0,1627 |
0,0116 |
0,0450 |
|
-0,4870 |
-0,2205 |
-0,0663 |
-0,1751 |
-0,1543 |
0,0327 |
0,0651 |
|
-0,4829 |
-0,2181 |
-0,0613 |
-0,1622 |
-0,1295 |
0,0652 |
0,0830 |
|
-0,1316 |
0,1285 |
-0,0708 |
-0,1919 |
-0,1611 |
0,0447 |
0,0789 |
|
-0,4874 |
-0,2354 |
-0,1105 |
-0,2664 |
-0,2026 |
0,0087 |
0,0549 |
|
-0,4437 |
-0,1337 |
0,0185 |
-0,1782 |
-0,1310 |
0,0967 |
0,1011 |
|
-0,6168 |
-0,3466 |
-0,1063 |
-0,2517 |
-0,2365 |
0,0170 |
0,0908 |
Приведем результаты расчетов 2расч .
|
|
= 1 |
= 2 |
= 3 |
= 4 |
= 5 |
= 6 |
= 7 |
2(0.05, 10) |
|
2расч |
3,19 |
2,86 |
0,22 |
0,29 |
0,23 |
0,13 |
0,09 |
18.3 |
Таким образом, можно предположить, что отклонения от линейного тренда являются стационарным в широком смысле случайным процессом.
Для наглядности построим коррелограмму, которая в будущем может использоваться для выбора глубины авторегрессионной модели.
ОПРЕДЕЛЕНИЕ НАЛИЧИЯ АВТОКОРРЕЛЯЦИИ В ИСХОДНОМ РЯДУ С ПОМОЩЬЮ КРИТЕРИЯ ДАРБИНА-УОТСЕНА
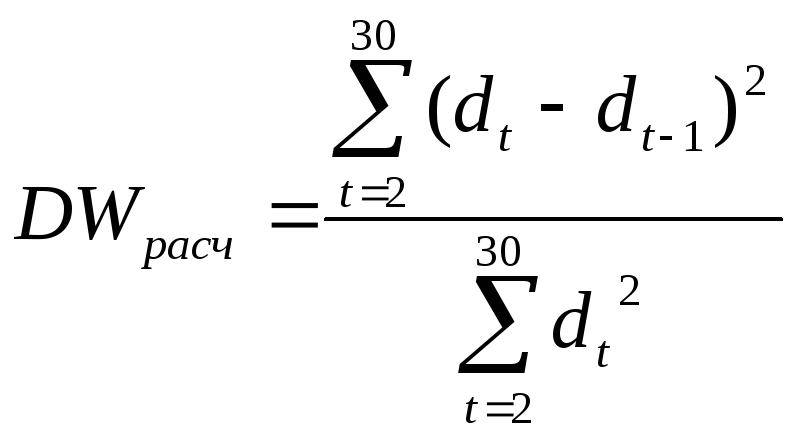 ,
где dt
=
yt
- ytp.
Из данной формулы с помощью преобразований
можно получить, что DW[0;4].
Причем при
DW =
0 – положительная
автокорреляция, DW
= 2 – нет
автокорреляции, DW
= 4 –
отрицательная автокорреляция.
,
где dt
=
yt
- ytp.
Из данной формулы с помощью преобразований
можно получить, что DW[0;4].
Причем при
DW =
0 – положительная
автокорреляция, DW
= 2 – нет
автокорреляции, DW
= 4 –
отрицательная автокорреляция.
Полученное значение сравнивается с табличными верхним dh и нижним dl значениями, выбираемыми при уровне значимости , числе факторов в модели и числе членов временного ряда n.
Могут иметь место следующие случаи:
DW < dl – положительная автокорреляция;
dh < DW < 4 - dh – отсутствие автокорреляции;
DW > 4 – dl – отрицательная автокорреляция;
dl < DW < dh или 4 - dh < DW < 4 – dl – нет статистических оснований принять или отвергнуть гипотезу об отсутствии автокорреляции.
В результате расчетов получили, что DW = 3.265; при = 0.05, = 1,
n = 30 - dl = 1.35 , dh = 1.39. Тогда 4 – dl = 2.65, 4 – dh = 2.61.
В рассматриваемом случае DW > 4 – dl – отрицательная автокорреляция, поэтому можно переходить к построению авторегрессионной модели.