

Лекция №13 по курсу
“Теория электрической связи”
Помехоустойчивое кодирование информации
1. Назначение и классификация кодов
Рассмотрим кодирование сообщений, передаваемых в дискретном канале. Дискретный канал образуется из непрерывного путем включения в канал модема. На вход модулятора и с выхода демодулятора поступают дискретные кодовые символы. Обозначим кодовые символы числами 0,1,...,m - 1, где m - основание кода.
Источник выдает некоторое дискретное сообщение а, которое можно рассматривать, как последовательность элементарных сообщений аi(i =1, 2, ..., l). Эти элементарные сообщения будем называть знаками, а их совокупность {ai} - алфавитом источника.
Кодирование заключается в том, что последовательность знаков источника а заменяется кодовым словом, т.е. последовательностью b кодовых символов. Такое преобразование сообщения в кодовое слово является взаимно - однозначным, что и позволяет осуществить декодирование, т.е. восстановить сообщение по принятому кодовому слову.
В простейшем случае, когда объем алфавита источника l равен основанию кода m, можно сопоставить каждый кодовый символ букве источника. Чаще применяют более сложные коды, основное назначение которых заключается в согласовании источника сообщений с дискретным каналом по объему алфавита и по избыточности. Согласование по объему необходимо во всех случаях, когда объем алфавита источника l не совпадает с количеством различных символов m, Чаще всего l > m, так что каждый знак источника кодируется несколькими последовательными кодовыми символами. Например в простейшем телеграфном коде Бодо каждая буква русского алфавита кодируется кодовым словом из пяти двоичных символов (0 и 1); в телеграфном коде Морзе на каждую букву алфавита затрачивается от двух до шести символов, принимающих значения “точка”, “тире” и “пробел”. Остановимся подробнее на согласовании источника с каналом по избыточности.
Пусть случайное сообщение А заменяется кодовой последовательностью В, При этом:
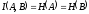 ,
(1)
,
(1)
где I(A,B) - количество информации в кодовой последовательности относительно сообщения H(A) - энтропия сообщения; Н(В) - энтропия кодовой последовательности.
Следует обратить внимание на то, что здесь речь идет об энтропии сообщения источника Н(А) и энтропии соответствующей ему последовательности кодовых символов Н(В), а не об энтропии на один символ, которая изменяется при изменении объема алфавита. Если алфавит содержит 32 буквы, то Н(А) = log 32 = 5 бит. Закодировав их двоичным кодом (m = 2), можно представить каждую букву источника кодовым словом из пяти символов. Энтропия на каждый кодовый символ Н(В) = 1 бит, а на все кодовое слово Н(В) = 5 бит = Н(А). Иначе обстоит дело с избыточностью, определяющей соотношение между энтропией и ее максимальным значением. Избыточность может при кодировании как возрастать, так и уменьшаться.
Пусть, например, избыточность источника велика, т.е. Н(А) << Нmax(A) = log l. Тогда может стоять задача о таком кодировании, при котором избыточность уменьшается (эффективное кодирование). Это позволяет увеличить скорость передачи сообщений по каналу с ограниченной пропускной способностью. В частности, осмысленный русский текст можно передавать, затрачивая всего 1,5 двоичных символов на букву, вместо пяти при примитивном равномерном коде.
При передаче безызбыточных сигналов по каналу с ошибками любая принятая последовательность соответствует возможному сообщению, но полной уверенности в том, что именно это сообщение передано в действительности у получателя нет. Ошибочный прием всего лишь одного кодового символа может изменить до неузнаваемости переданное сообщение. Поэтому эффективное кодирование используют в чистом виде только тогда, когда кодовая последовательность не подвергается воздействию помех.
Если при кодировании не устранять, а вводить избыточность, то должны увеличится возможности обнаружения и исправления ошибок. Такое кодирование называют помехоустойчивым или корректирующим.
При помехоустойчивом кодировании чаще всего считают, что избыточность источника на входе кодера = 0. Для этого имеются следующие основания: во-первых, очень многие дискретные источники обладают малой избыточностью; во-вторых, если избыточность первичных источников существенна, она обычно порождается сложными связями, которые в месте приема трудно использовать для повышения верности. Поэтому разумно в таких случаях по возможности уменьшить избыточность первичного источника путем эффективного кодирования, а затем методами помехоустойчивого кодирования внести такую избыточность в сигнал.
Коды можно классифицировать по различным признакам. Одним из них является основание кода m, или число различных, используемых в нем символов. Наиболее простыми являются двоичные (бинарные) коды, у которых m = 2.
Далее коды можно разделить на блочные и непрерывные. Блочными называют коды. В которых последовательности элементарных сообщений источника разбиваются на отрезки и каждый из них преобразуется в определенную последовательность (блок) кодовых символов {bi}, называемую иногда кодовой комбинацией bl (l = 1, 2, 3, ..., M). Непрерывные коды образуют последовательность символов {bi}, не разделяемую на последовательные кодовые комбинации: здесь в процессе кодирования символы определяются всей последовательностью элементов сообщения.
В настоящее время на практике чаще всего используются блочные коды, равномерные и не равномерные. В равномерных кодах, в отличие от неравномерных, все кодовые комбинации содержат одинаковое число символов (разрядов), передаваемых по каналу элементами сигнала неизменной длительности. Это обстоятельство существенно упрощает технику передачи и приема сообщений
Число
различных блоков М n
- разрядного равномерного кода с
основанием m
удовлетворяет неравенству 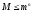 (2)
(2)
Если здесь имеет место равенство, т.е. все возможные кодовые комбинации используются для передачи сообщений, то в этом случае код называется простым или примитивным. Он не является помехоустойчивым.
Избыточностью равномерного кода называют величину:
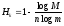 , (3)
, (3)
а относительной скоростью кода:
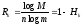 (4)
(4)