

От Шатохина_Статиститка. Орлов, Айвазян / Лекции с прошлого семестра / Лекция № 10
.pdfЛекция № 10. Полиномиальное (мультиномиальное) и нормальное
распределения.
Содержание
1.Полиномиальное (мультиномиальное) распределение.
2.Нормальное (гауссовское) распределение.
3.Логарифмически-нормальное распределение.
1. Полиномиальное (мультиномиальное) распределение.
Полезным обобщением биномиального распределения на случай более чем двух возможных исходов является полиномиальная (мультиномиальная) генеральная совокупность.
Она является бесконечной и содержит |
объекты классов (свойств) |
||
1,2, . . . , l |
(l > 2), представленных соответственно в долях p1, p2,…., |
pl (в |
|
биномиальной генеральной совокупности мы имели l = 2, p 1 =p и р2 =1– |
р). |
||
Таким |
образом, в результате одного |
случайного эксперимента |
|
(случайного извлечения объекта из этой бесконечной совокупности)
объект класса j появляется с вероятностью рj . Нас будет интересовать распределение многомерной случайной величины (ν (p1) (m) , ν (p2) (m) ,…,
ν (pl ) (m) ), порожденной m-кратным случайным экспериментом (т. е. выборкой из т объектов),
где ν (p j ) (m) – число объектов j-го класса, оказавшихся в
l |
l |
этой выборке, а р = (p1, p2,…., pl) (очевидно ∑p j =1 и |
∑ν p( j ) |
j =1 |
j =1 |
(m) = m).
Соответствующее многомерное дискретное распределение описывается выражением (доказывается прямым вероятностным рассуждением)
|
|
|
|
m! |
× p1x |
(1) |
×... × plx |
( l ) |
|
|
P{ν (1) |
(m) = x(1),… , |
ν (l ) (m) = x(l)} = |
|
|
|
|
, |
(1) |
||
x(1) |
!×x(2)!×... × x(l )! |
|
||||||||
p |
|
p |
|
|
|
|
|
|||
где x(1), x(2),… , x(l) –
подчиненные условию
любые
l
∑x( j ) j =1
(заданные) целые неотрицательные числа,
= m , а выражение (1) определяет вероятность
того, что среди т извлеченных объектов оказалось ровно x(1) объектов 1-го класса, x(2) объектов 2-го класса и т. д. Можно также связывать полиномиальную случайную величину с m-кратным случайным экспериментом, каждый из которых может закончиться одним из l возможных исходов А1 , A2,..., Аl , причем вероятность исхода Aj в единичном эксперименте равна рj .

Название распределения объясняется тем, что выражение (1) является общим членом разложения многочлена (полинома) (p1 + p2 +….+ pl)m.
Вектор средних значений ( Eν (p1) (m) , Eν (p2)
(m) ,…, Eν (pl )
(m) ) и ковариации
Si k = E{(ν (pj )
(m) – Eν (pj ) (m) )(ν (pk ) (m) – Eν (pk )
(m) )} компонент исследуемой
многомерной случайной величины определяются соотношениями:
средние Eν (pj ) (m) =трj ; j = 1, 2 |
,…, |
l; |
|
дисперсии Dν p( j ) (m) = Sjj = трj · (1 – p j ), |
j = 1, 2 |
,…, l; |
|
ковариации Sjk = -mp j p k ; j , k = 1, |
2,…, |
l , j ¹ k. |
|
Полиномиальное распределение применяется главным образом при статистической обработке выборок из больших совокупностей, элементы которых разделяются более чем на две категории (например, в различных социологических, экономико-социологических, медицинских и других выборочных обследованиях).
2. Нормальное (гауссовское) распределение.
Это распределение занимает центральное место в теории и практике вероятностно-статистических исследований. В качестве непрерывной аппроксимации к биномиальному распределению оно впервые рассматривалось А. Муавром еще в 1733 г.
Некоторое время спустя нормальное распределение было снова открыто и изучено независимо друг от друга К. Гауссом (1809 г.) и П. Лапласом (1812 г.). Оба ученых пришли к нормальной функции в связи со своей работой по теории ошибок наблюдений.
Идея их объяснения механизма формирования нормально распределенных случайных величин заключается в следующем.
Постулируется, что значения исследуемой непрерывной случайной величины формируются под воздействием очень большого числа
независимых случайных факторов, причем сила воздействия каждого отдельного фактора мала и не может превалировать среди остальных, а
характер воздействия – аддитивный (т. е. при воздействии случайного фактора F на величину а получается величина а + ó(F), где случайная «добавка», ó(F) мала и равновероятна по знаку. Можно показать, что функция плотности случайных величин подобного типа имеет вид
ϕ(x; a, σ |
|
|
|
1 |
|
|
− |
( x−a)2 |
|
|
2 |
) = |
|
|
e |
2σ 2 |
, |
(2) |
|||
|
|
|
×σ |
|
|
|||||
|
2π |
|
|
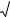
где а и S2 – параметры закона, интерпретируемые соответственно как среднее значение и дисперсия данной случайной величины (в виду особой роли нормального распределения мы будем использовать специальную символику для обозначения его функции плотности и функции распределения).
Соответствующая функция распределения нормальной случайной величины X(а, S2) обозначается Ф (х; а, S2)
и задается соотношением
Ф( x ; а, S2) = Р{ X ( а, S2) < x }= ϕ(x; a, σ 2 ) = |
|
1 |
|
x |
− |
(t −a)2 |
|
(3) |
|
|
∫e |
2σ 2 dt, |
|||||
|
|
|
|
|||||
|
|
2π ×σ −∞ |
|
|
|
|
||
Условимся называть нормальный закон с параметрами а = 0 и S2 = 1 стандартным, а его функции плотности и распределения обозначать соответственно φ(x) = φ(x; 0,1) и Ф(x) = Ф(x; 0,1).
Во многих случайных величинах, изучаемых в экономике, технике, медицине, биологии и в других областях, естественно видеть суммарный аддитивный эффект большого числа независимых причин. Но центральное место нормального закона не следует объяснять его универсальной приложимостью, как это было принято долгое время (по-видимому, под влиянием блестящих работ К. Гаусса и П. Лапласса).
В этом смысле нормальный закон – это один из многих типов распределения, имеющихся в природе, правда, с относительно большим удельным весом практической приложимости.
И потому нам понятна ирония, звучащая в известном высказывании Липмана (цитируемом А. Пуанкаре в своем труде «Исчисление вероятностей», Париж, 1912 г.):
«Каждый уверен в справедливости нормального закона: экспериментаторы – потому, что они думают, что это математическая теорема; математики – потому, что они думают, что это экспериментальный факт».
Однако не следует упускать из виду, что полнота теоретических исследований, относящихся к нормальному закону, а также сравнительно простые математические свойства делают его наиболее привлекательным и удобным в применении.
Даже в случае отклонения исследуемых экспериментальных данных от нормального закона существует по крайней мере два пути его целесообразной эксплуатации:
а) использовать его в качестве первого приближения; при этом нередко оказывается, что подобное допущение дает достаточно точные с точки зрения конкретных целей исследования результаты;
б) подобрать такое преобразование исследуемой случайной величины X, которое видоизменяет исходный «не нормальный» закон распределения,
превращая его в нормальный.
Удобным для статистических приложений является и свойство «самовоспроизводимости» нормального закона, заключающееся в том, что сумма любого числа нормально распределенных случайных величин тоже подчиняется нормальному закону распределения.
Кроме того, закон нормального распределения имеет большое теоретическое значение: с его помощью выведен целый ряд других важных распределений, построены различные статистические критерии и т. п. (χ2-, t- и F-распределения и опирающиеся на них критерии.
Основные числовые характеристики нормального закона:
среднее, мода, медиана ЕX = хтоd = хтed = а; дисперсия DX = S2;
асимметрия β1 = 0; эксцесс β2 = 0.
Двумерный нормальный закон описывает совместное распределение
двумерной случайной |
величины X = (X(1), X(2)) с непрерывными |
компонентами X(1) и X(2), |
механизм формирования значений которых тот же, |
что и в одномерном случае, причем множества случайных факторов, под воздействием которых формируются значения X(1) и X(2), вообще говоря, пересекаются (отсюда возможная зависимость X(1) и X(2)).
Введем в рассмотрение основные числовые характеристики двумерной случайной величины X = (X(1), X(2)):
|
M |
|
m(1) |
|
вектор средних |
1 |
= |
1 |
|
|
m(2) |
|||
|
|
|
|
1 |
ковариационная матрица
где Sjk = E{(X(i) - m1(i ) )(X(k) -
коэффициент корреляции
, где m(i ) = Eξ1
∑ |
σ11 |
σ12 |
|
|
|
|
|
|
= |
|
, |
|
σ21 |
σ22 |
|
m1( k ) )};
r = |
σ12 |
(σ11×σ22 )1/ 2 |
(i) ;
.
Совместная двумерная плотность φ(х (1), х(2)) = fX(х( 1 ) , |
x ( 2 ) ) нормального |
|||||||||||||
закона может быть записана в виде |
|
|
|
|
|
|
|
|
||||||
|
(1) |
|
(2) |
|
|
1 |
|
− |
1 |
|
|
(x(1) |
- m(1) )2 |
|
φ(х |
, х |
) = φ(X) = |
|
|
2 |
|
|
|||||||
|
|
|
|
|
× e |
2(1−r |
) |
|
1 |
- |
||||
|
|
2π[σ11 |
×σ22 (1 - r |
2 1/ 2 |
|
σ11 |
||||||||
|
|
|
|
|
)] |
|
|
|
|
|
|
|||

|
x(1) |
- m(1) |
x( 2) - m(2) |
(x( 2) - m(2) )2 |
|
(4) |
|||||||||||||
- 2r |
|
|
|
|
1 |
|
× |
1 |
+ |
1 |
|
|
|
||||||
|
|
|
1 / 2 |
|
|
1/ 2 |
σ 22 |
||||||||||||
|
|
σ11 |
|
|
|
σ 22 |
|
|
|||||||||||
или в виде |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
1 |
|
|
- |
1 |
×( X -M1 )¢ S−1 ( X -M1 ) |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
φ(х (1), х(2)) = φ(X) = |
|
|
|
|
|
×e 2 |
(5) |
|||||||||
|
|
|
2π |
|
S |
|
1/ 2 |
||||||||||||
|
|
|
|
|
|||||||||||||||
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
где X = |
x |
(2) |
|
, верхний индекс «штрих» означает транспонирование |
|||||||||||||||
|
|
|
|||||||||||||||||
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
матрицы или вектора, |
|
|
Σ |
|
= det( Σ ) – определитель ковариационной |
||||||||||||||||
|
|
|
|||||||||||||||||||
матрицы, а S−1 – матрица, обратная к ковариантной. |
|
|
|||||||||||||||||||
Частные плотности ϕξ (1) |
(x(1) ) и ϕξ ( 2 ) (x(2) ) |
|
могут быть получены из |
||||||||||||||||||
совместной: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
− |
( x(1) −m(1) )2 |
|
|
|
ϕ |
|
|
|
|
|
(1) |
|
|
|
|
|
|
|
1 |
|
|
|||||
|
(1) (x |
) |
= |
|
|
|
|
|
e |
|
2σ11 |
; |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
||||||||||||||
|
|
ξ |
|
|
|
|
|
2π × |
σ11 |
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
− |
|
( x( 2 ) −m( 2 ) )2 |
|
|
ϕ |
|
|
|
|
|
( 2) |
|
|
|
|
|
|
|
1 |
|
|
|||||
ξ |
( 2 ) (x |
) |
= |
|
|
|
|
|
e |
|
2σ 22 |
|
. |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
2π × |
σ 22 |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Эти формулы означают, что частные законы распределения компонент двумерного нормального закона сами являются одномерными нормальными
законами с параметрами соответственно ( m1(1) , S11) и ( m1(2) , S22).
Условные плотности ϕξ (1) (x(1) | X(2) = х(2)) и ϕξ ( 2 ) (x(2) | X(1) = х(1))
получаются с использованием общих формул:
ϕξ (1) (x(1) | X(2) = х(2)) =
ϕξ ( 2 ) (x(2) | X(1) = х(1)) =
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
(1) |
|
|
|
|
1 / 2 |
|
|
|
|
2 |
||||
|
|
|
|
1 |
|
|
- |
|
|
|
|
|
|
× x |
- m(1) |
+r |
σ11 |
|
( x |
( 2 ) -m( 2 ) ) |
|
|
|
|||||||||
|
|
|
|
|
|
2σ |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
11 |
(1-r 2 ) |
|
|
|
1 |
|
σ |
1 / 2 |
|
|
1 |
|
|
|
||||||||||
|
|
|
|
|
|
|
|
e |
|
|
|
|
|
|
|
|
|
|
|
|
22 |
|
|
|
|
|
|
; |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
2π ×σ |
11 (1- r 2 ) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
1 / 2 |
|
|
|
|
2 |
|
|
|
|
|
|
1 |
|
|
- |
|
|
|
|
|
|
× x |
( 2 ) - m( 2 ) +r σ |
22 |
( x |
(1) -m(1) ) |
|
||||||||||||
|
|
|
|
|
|
|
2σ |
|
|
(1-r |
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
22 |
2 ) |
|
|
|
1 |
|
|
σ |
1 / 2 |
|
1 |
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
e |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11 |
|
|
|
|
; |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
2π ×σ |
22 (1- r 2 ) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
Отсюда следует, в частности, что условное распределение компоненты

X(i) при фиксированном значении другой компоненты (X(j) = x(j)) снова описывается нормальным законом, параметр среднего значения которого, как и следовало ожидать, зависит от фиксированного значения x(j):
E(X(i) | X(j) = x(j)) = m1(i ) + r σσ ii (x(j) – m1( j ) ),
jj
и дисперсия которого не зависит от x(j) и равна
D(X(i) | X(j) = x(j)) = Sii(1 – r 2 ).
Многомерный нормальный закон описывает совместное распределение p-мерной случайной величины X = (X(1), X(2),... , X(p)) с непрерывными компонентами X(j), механизм формирования значений каждой из которых тот же, что и в одномерном случае, причем множества случайных факторов, под воздействием которых формируются значения X(1), X(2),... , X(p), вообще говоря, пересекаются (отсюда их возможная взаимозависимость).
Задавшись p-мерным вектор-столбцом М1 средних значений компонент и (р´p)-матрицей ковариации Σ, можно выписать p-мерную совместную плотность многомерного нормального закона:
|
|
|
1 |
|
|
|
- |
1 |
×( X -M1 )¢ S−1 ( X -M1 ) |
|||
|
|
|
|
|
|
|
||||||
φ(х (1), х(2),…, |
х (p)) = φ(X) = |
|
|
|
|
|
|
×e 2 |
(6) |
|||
(2π ) |
p |
S |
|
1/ 2 |
||||||||
|
|
2 |
|
|
|
|
|
|
||||
Здесь, как |
и прежде, Х = |
(х(1), |
|
х(2),…, |
х(p))' – вектор-столбец текущих |
|||||||
переменных, а Σ = det( Σ ) – определитель ковариационной матрицы.
Вырожденность матрицы Σ (т. е. равенство нулю определителя Σ )
делает соответствующее многомерное распределение вырожденным (или несобственным); это означает, в частности, что разброс значений исследуемого многомерного признака сосредоточен в подпространстве меньшей, чем p, размерности. За исключением некоторых специальных случаев мы всегда будем полагать, что нами уже осуществлен переход в это подпространство меньшей размерности, так что в наших рассуждениях
предполагается Σ > 0.
3. Логарифмически-нормальное распределение.
Случайная величина η называется логарифмически-нормально распределенной, если ее логарифм (ln η) подчинен нормальному закону
распределения.
Это означает, в частности, что значения логарифмически-нормальной случайной величины формируются под воздействием очень большого числа взаимно независимых факторов, причем воздействие каждого отдельного фактора «равномерно незначительно» и равновероятно по знаку. При этом в отличие от схемы формирования механизма нормального закона последовательный характер воздействия случайных факторов таков, что случайный прирост, вызываемый действием каждого следующего фактора, пропорционален уже достигнутому к этому моменту значению исследуемой величины (в этом случае говорят о мультипликативном характере воздействия фактора).
Математически сказанное может быть формализовано следующим образом. Если η0 = а – неслучайная компонента исследуемого признака η (т. е. как бы «истинное» значение η в идеализированной схеме, когда устранено влияние всех случайных факторов), a X1, X2,... , XN – численное выражение эффектов воздействия упомянутых выше случайных факторов, то последовательно трансформированные действием этих факторов значения исследуемого признака будут:
η1 = η0 + X1·η0;
η2 = η1 + X2·η1;
………………..
ηN = ηN-1 + XN·ηN-1.
Отсюда получаем, что
N −1 |
η |
|
|
(7) |
|
∑ |
ηi |
i |
= X1 + X2 +... + XN. |
||
i =0 |
|
|
|
|
|
где óηi = ηi+1 – |
ηi. Но правая часть (7) есть результат аддитивного действия |
||||
множества случайных факторов, что при сделанных выше предположениях должно приводить к нормальному распределению этой суммы. В то же время, учитывая достаточную многочисленность числа случайных слагаемых (т. е. полагая N Ø ¶) и относительную незначительность воздействия каждого из них (т. е. полагая óηi Ø 0), можно от суммы в левой части (7) перейти к интегралу
η |
dη |
|
|
∫ |
|
= lnη − lnη0 |
= lnη − ln a . |
η |
|||
|
|
||
η0 |
|
|
|

Это и означает в конечном счете, что логарифм интересующей нас величины (уменьшенный на постоянную величину ln а) подчиняется нормальному закону с нулевым средним значением, т. е.
|
|
1 |
|
ln x |
(t −ln a) 2 |
||
Fη(x) = P{η < x} = P{ln η < ln x} = |
|
|
∫ e− |
|
|
||
|
|
2σ 2 dt, |
|||||
|
|
|
|||||
2π ×σ |
|||||||
|
|
0 |
|
|
|||
откуда дифференцированием по x левой и правой частей этого соотношения получаем
|
|
1 |
|
−(ln x −ln a )2 |
|
|
|
fη(x) = |
|
e |
2σ 2 |
. |
(8) |
||
|
|
|
|
||||
|
|
||||||
|
|
2π ×σ × x |
|
|
|
||
(правомерность использованного при вычислении fη(x) тождества
P{η < x} = P{ln η < ln x}
вытекает из строгой монотонности преобразования ln η).
Указанная схема формирования значений логарифмически-нормальной случайной величины оказывается характерной для многих конкретных физических и социально-экономических ситуаций:
∙размеры и вес частиц, образующихся при дроблении;
∙заработная плата работника;
∙доход семьи;
∙размеры космических образований;
∙долговечность изделия, работающего в режиме износа и старения и
др.
Пример 1. В качестве случайной величины η рассматривается душевой месячный доход (в долларах) семьи некоторой совокупности семей. Обследовано п = 750 семей.
Втабл. 1 и 2 приведены результаты группировки выборочных данных ( xi )
иих логарифмов (ln x i ) соответственно (ширина интервала группирования равна 25 долларам).
На рис. 1, а, б изображены гистограммы и плотности соответственно логарифмически-нормального и нормального законов распределения.

Таблица 1.
Таблица 2.

Рис. 1, а, б. Гистограмма и теоретическая (модельная) плотность,
характеризующие распределение семей по среднедушевому месячному доходу ( а) и по логарифму среднедушевого месячного дохода ( б)