

Кластерный анализ
Кластеризация может оказаться неадекватной и в том случае, если изначаль- но будет неверно угадано число кластеров. Стандартная рекомендация провести
кластеризацию при различных значениях k и выбрать то, при котором достигается резкое улучшение качества кластеризации по заданному функционалу.
Кластеризация с частичным обучением. Алгоритмы EM и k-means легко приспо- собить для решения задач кластеризации с частичным обучением (semi-supervised learning), когда для некоторых объектов xi известны правильные классифика- ции y* (xi ) . Обозначим через U подмножество таких объектов, U X l . Примером такой задачи является рубрикация текстовых документов, в частно-
сти, страниц в Интернете. Типична ситуация, когда имеется относительно небольшое множество документов, вручную классифицированных по тематике. Требуется опре- делить тематику большого числа неклассифицированных документов. Сходство до- кументов (x, x ) может оцениваться по-разному в зависимости от целей рубрикации и специфики самих документов: по частоте встречаемости ключевых слов, по ча- стоте посещаемости заданным множеством пользователей, по количеству взаимных гипертекстовых ссылок, или другими способами. Аналогичный подход можно использовать и при анализе изображений
Модификация обоих алгоритмов довольно проста: на E-шаге (шаг 3) для всех
x U |
полагаемgiy |
|
* |
(xi ) |
|
для всех остальных |
x X l \U |
скрытые пере- |
y y |
, |
i |
||||||
i |
|
|
|
|
|
|
|
|
менные |
giy вычисляются как прежде. На практике частичная классификация даже |
|||||||
небольшого количества объектов существенно улучшает качество кластеризации.

Кластерный анализ
Более просто алгоритм K-средних можно выразить так
1. Случайным образом выбрать k средних mj j=1,…,k;
2. Для каждого xi i=1,…,p подсчитать расстояние до каждого из mj j=1,…,k,
Отнести (приписать) xi к кластеру j’, расстояние до центра которого mj’ минимально;
3. Пересчитать средние mj j=1,…,k по всем кластерам;
4. Повторять шаги 2, 3 пока кластеры не перестанут
Initial Cluster Centers at Iteration 1
14 |
|
|
|
|
|
|
|
14 |
|
|
|
|
|
|
|
13 |
|
|
|
|
|
|
|
13 |
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
11 |
|
|
|
|
|
|
|
11 |
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
7 |
8 |
10 |
12 |
14 |
16 |
18 |
20 |
7 |
8 |
10 |
12 |
14 |
16 |
18 |
20 |
|
|
Исходные данные |
Случайная инициализация центров кластеров (шаг 1) |
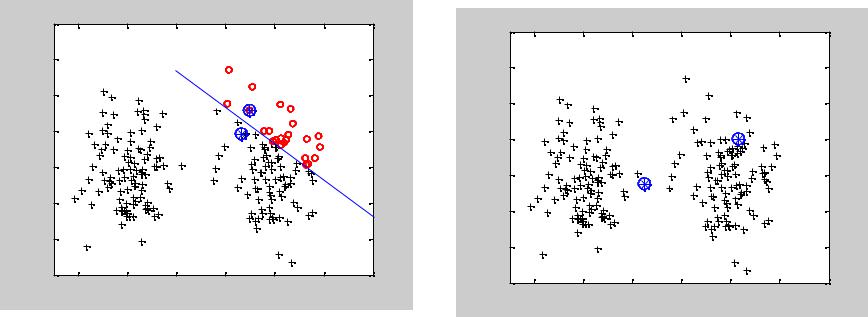
Кластерный анализ
Updated Memberships and Boundary at Iteration 1
|
14 |
|
|
|
|
|
|
|
|
13 |
|
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
Y Variable |
11 |
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
7 |
8 |
10 |
12 |
14 |
16 |
18 |
20 |
|
|
|||||||
|
|
|
|
|
X Variable |
|
|
|
Updated Cluster Centers at Iteration 2
14
13
12
11
10
9
8
7 |
8 |
10 |
12 |
14 |
16 |
18 |
20 |
|
Кластеры после первой итерации (шаг 2) |
Пересчет центров кластеров после первой |
|
|
|
итерации (шаг 3) |

Кластерный анализ
Updated Memberships and Boundary at Iteration 2
|
14 |
|
|
|
|
|
|
|
|
13 |
|
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
Y Variable |
11 |
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
7 |
8 |
10 |
12 |
14 |
16 |
18 |
20 |
|
|
X Variable
Кластеры после второй итерации (шаг 2)
Updated Memberships and Boundary at Iteration 4
|
14 |
|
|
|
|
|
|
|
|
13 |
|
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
Y Variable |
11 |
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
7 |
8 |
10 |
12 |
14 |
16 |
18 |
20 |
|
|
X Variable
Стабильная конфигурация после четвертой итерации
Кластерный анализ
.
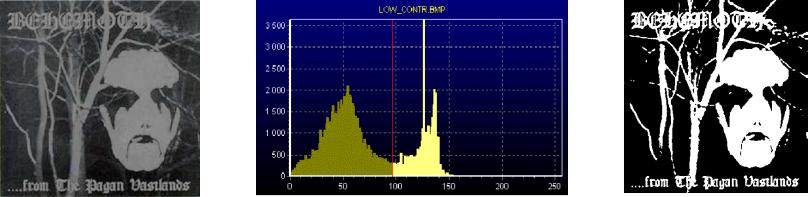
Примеры сегментации изображения с использование кластеризации
Рассматриваем одномерное пространство яркостей пикселей и производим в нем кластеризацию с помощью k-средних. Это дает автоматическое вычисление яркостных порогов
(Для получения бинарного изображения k=2)

Кластерный анализ
|
20 |
|
|
|
|
40 |
|
|
|
|
60 |
|
|
|
|
80 |
|
|
|
|
100 |
|
|
|
k = 2 |
120 |
|
k = 3 |
|
20 40 60 80 100 120 |
||||
|
||||

Кластерный анализ
20 |
|
|
|
|
|
40 |
|
|
|
|
|
60 |
|
|
|
|
|
80 |
|
|
|
|
|
100 |
|
|
|
|
|
120 |
|
|
|
|
|
20 |
40 |
60 |
80 |
100 |
120 |
k-средних k=2 |
Порог по средней яркости |
|

Кластерный анализ

Кластерный анализ
objects in cluster
objects in cluster
objects in cluster |
objects in cluster |