

3.1. Диаграммы потоков данных
DFD – средство моделирования функциональных требований к программному обеспечению. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных.
Это позволяет продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между процессами.
Для изображения DFD традиционно используются две различные нотации: Йодана/ДеМарко (Yourdon/DeMarco) и Гейна–Сарсона (Gane & Sarson). Основные символы DFD, применяемые в этих нотациях, изображены на рис. 7.
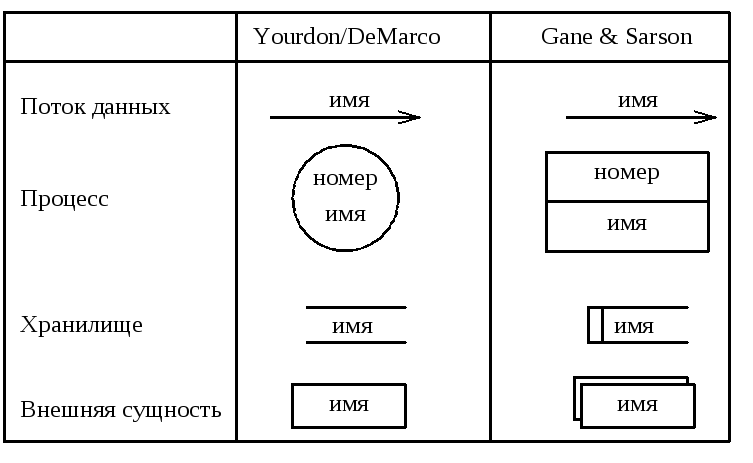
Рис. 7. Основные символы диаграмм потоков данных
На диаграммах функциональные требования представляются с помощью процессов и хранилищ, связанных потоками данных.
Потоки данных являются механизмами, использующимися для моделирования передачи информации из одной части системы в другую. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации. Если информация возвращается в свой источник после обработки, то такая ситуация может отражаться или двумя различными однонаправленными стрелками, или одной двунаправленной.
Процесс предназначен для представления процедуры переработки информации, поставляемой входными потоками, в информацию, передаваемую выходными потоками, в соответствии с действием, задаваемым его именем. Это имя должно содержать глагол в неопределённой форме с последующим дополнением. Кроме того, каждый процесс имеет уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во все модели.
Хранилище данных позволяет на определённых участках определять данные, которые будут сохраняться в память между процессами. Фактически хранилище представляет "срезы" потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища идентифицирует его содержимое и является существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме.
Внешняя сущность представляет сущность вне контекста системы, являющуюся источником или приёмником системных данных. Её имя должно содержать существительное. Объекты, представленные такими узлами не должны участвовать ни в какой обработке.
Декомпозиция DFD осуществляется на основе процессов: каждый процесс может раскрываться с помощью DFD нижнего уровня.
Важную специфическую роль в DFD имеет специальный вид DFD – контекстная диаграмма, моделирующая систему наиболее общим образом. Она отражает интерфейс системы с внешним миром, а именно: информационные потоки между системой и внешними сущностями. Она идентифицирует эти внешние сущности, а также, как правило, единственный процесс, отражающий главную цель системы. Каждый проект должен иметь только одну контекстную диаграмму, при этом нумеровать ее единственный процесс нет необходимости.
DFD первого уровня строится как декомпозиция процесса из контекстной диаграммы.
Построенная диаграмма первого уровня имеет множество процессов, которые, в свою очередь, могут быть декомпозированы DFD нижнего уровня и т.д. Этот процесс декомпозиции повторяется до тех пор, пока процессы не могут быть эффективно описаны с помощью коротких (до 1 страницы) миниспецификаций обработки (спецификаций процесса). В итоге получается иерархия DFD с контекстной диаграммой в корне дерева.
Для указания соотношения процессов смежных уровней используются структурированные номера процессов.
Кроме декомпозиции процессов DFD допускают структурирование и декомпозицию данных.
Индивидуальные данные в системе часто бывают независимыми. Однако иногда необходимо иметь дело с несколькими независимыми данными одновременно. Потоки, объединяющие несколько потоков, получили название групповых. Формальное определение группового потока, состоящего из нескольких элементов – потомков, выполняется в словаре данных с помощью формы Бэкуса–Наура (БНФ).
Обратная операция (расщепление потоков на подпотоки) осуществляется с помощью группового узла, позволяющего расщепить потоки на любое число подпотоков. При расщеплении также необходимо формально определить каждый подпоток в словаре данных.
Аналогичным образом осуществляется декомпозиция потоков данных через границы диаграмм, позволяющая упростить детализацию DFD. Если имеется групповой поток, входящий в детализируемый процесс и состоящий из нескольких подпотоков,. то детализирующей DFD этот групповой поток может отсутствовать, а вместо него быть подпотоки, так как будто они переданы из детализируемого процесса.
Применение этих операций над данными позволяет обеспечить структуризацию данных, увеличивает наглядность и читабельность DFD.
Для обеспечения декомпозиции данных и некоторых других сервисных возможностей к DFD добавляются следующие типы объектов:
групповой узел, который предназначен для расщепления и объединения потоков (может вырождаться в точку слияния/расщепления потоков);
узел–предок, который позволяет увязывать входящие и выходящие потоки между детализируемым процессом и детализирующей DFD;
узел изменения имени, позволяет неоднозначно именовать потоки, при этом их содержимое эквивалентно;
текст в свободной форме в любом месте диаграммы.
Возможный способ изображения этих узлов приведен на рис. 8.
-
Групповой узел

Узел-предок

Узел изменения имени

Рис. 8. Расширения диаграммы потоков данных
Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями.
Размещать на каждой диаграмме от 3 до 7 процессов.
Не загромождать диаграмму не существенными на данном уровне деталями.
Декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов.
Выбирать ясные, отражающие суть дела, имена процессов и потоков данных для улучшения понимаемости диаграмм, при этом стараться не использовать аббревиатуры.
Однократно определять функционально идентичные процессы на самом верхнем уровне, где такой процесс необходим, и ссылаться на него на нижних уровнях.
Отделять управляющие структуры обрабатывающих структур (процессов), а также локализовать управляющие структуры.
В соответствии с этими рекомендациями процесс построения модели разбивается на следующие этапы.
Расчленение множества требований и организация их в основные функциональные группы.
Идентификация внешних объектов, с которыми система должна быть связана.
Идентификация основных видов информации, циркулирующей между системой и внешними объектами.
Предварительная разработка контекстной диаграммы, на которой основные функциональные группы представляются процессами, внешние объекты – внешними сущностями, основные виды информации – потоками данных между процессами и сущностями.
Изучение предварительной контекстной диаграммы и внесение в нее изменений по результатам ответов на возникающие вопросы по всем её частям.
Построение контекстной диаграммы путем объединения всех процессов предварительной диаграммы в один процесс, а также группирования потоков.
Формирование DFD первого уровня на базе процессов предварительной контекстной диаграммы.
Проверка основных требований по DFD первого уровня.
Декомпозиция каждого процесса текущей DFD с помощью детализирующей диаграммы или спецификации процесса.
Проверка основных требований по DFD соответствующего уровня.
Добавление определений новых потоков в словарь данных при каждом их появлении на диаграммах.
Параллельное (с процессом декомпозиции) изучение требований (в том числе и вновь поступающих), разбиение их на элементарные и идентификация процессов или спецификаций соответствующих этим требованиям.
После построения двух-трех уровней проведение ревизии с целью проверки корректности и улучшения понимаемости модели.
Построение спецификации процесса в случае, если некоторую функцию сложно или невозможно выразить комбинацией процессов.
Для моделирования взаимодействия процессов на DFD в реальном времени используются специальные средства: управляющие процессы, управляющие хранилища и управляющие потоки. Для изображения этих элементов диаграмм используются символы представленные на рис. 9.
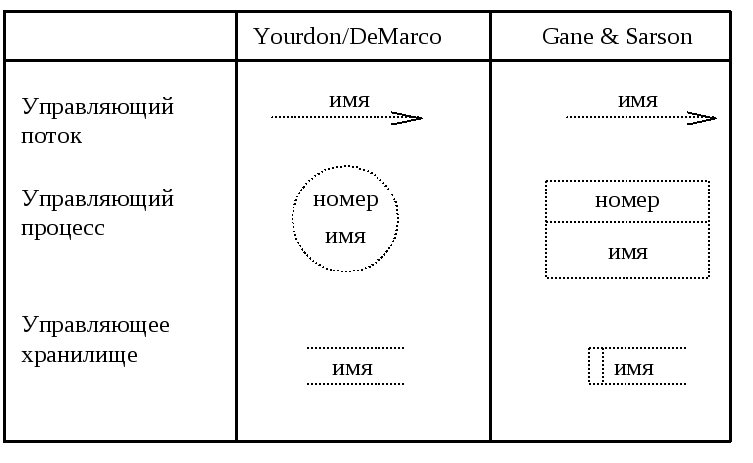
Рис. 9. Расширения реального времени в диаграммах потоков данных
Управляющий процесс – интерфейс между DFD и спецификациями управления, модифицирующими и документирующими аспектами реального времени. Его имя указывает на тип управляющей деятельности. Фактически управляющий процесс представляет собой преобразователь входных управляющих потоков в выходные управляющие потоки; при этом такое описание этого преобразования должно задаваться в спецификации управления. Имя управляющего процесса должно быть существительным.
Управляющее хранилище – срез управляющего потока во времени. Имя управляющего хранилища должно идентифицировать его содержимое и быть существительным.
Управляющий поток моделирует управляющую информацию. Его имя не должно содержать глаголов, а только существительные и прилагательные.
Управляющий процесс реагирует на изменение внешних условий, передаваемых ему управляющими потоками, и управляет в соответствии со своей внутренней логикой выполняемыми процессами операции. При этом режим выполнения процесса зависит от типа управляющего потока.
Различают управляющие потоки следующих типов.
Т-поток (trigger) – поток управления процессом, который включает процесс одной короткой операцией.
А-поток (activator) может изменять выполнение отдельного процесса. Он используется для обеспечения непрерывности выполнения процесса до тех пор, пока поток "включен" (т.е. течет непрерывно), с "выключением" потока выполнение процесса завершатся.
Е/D-поток (enable/disable) переключает выполнение процесса. Течение по линии Е вызывает выполнение процесса, которое продолжается до тех пор, пока не возбуждается течение по линии D.