

7.2.6. Структура диалога пользователя в системе statistica
Структура диалога пользователя в каждом статистическом модуле имеет общие черты:
После выбора из переключателя модулей (рис.7.1) открывается стартовая панель выбранного статистического модуля.
Далее необходимо открыть файл данных и выбрать переменные для анализа из открытого файла.
Затем выбирается метод анализа и конкретная вычислительная процедура с соответствующими параметрами расчета из меню в стартовой панели модуля.
Далее запускается вычислительная процедура. Если процедура итерационная, то система дает возможность на каждом шаге просмотреть результаты в появившемся на экране окне и при необходимости добавить число итераций для увеличения точности оценок.
Используя графические возможности и специальные таблицы вывода с вычисленными разнообразными статистиками, осуществляется всесторонний просмотр и анализ результатов.
Выбирается следующий шаг анализа.
В сложном проекте следует работать с различными модулями, последовательно переключаясь между ними.
7.2.7. Примеры использования системы statistica
Расчет основных характеристик случайных величин
Запускаем систему STATISTICAи выбираем статистический модульBasicStatistics/Tables (Основные статистики и таблицы). Создаем новый файл исходных данных, выбирая из меню пунктFile/New data, и присваиваем ему произвольное имя, например,exampl1.sta.
 Исходные
данные для анализа возьмем из примера
3.11, в котором приведены результаты
обработки 50 проб передельного чугуна
на предмет содержания в них кремния
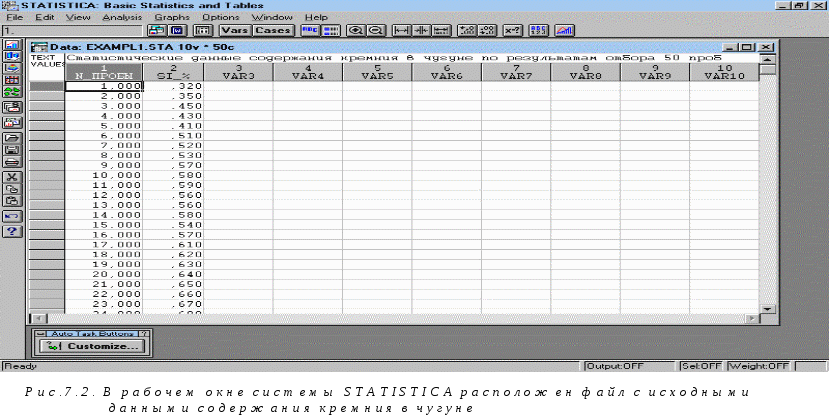
(табл.3.6). Заполним таблицу в системеSTATISTICAс исходными
данными как показано на рис.7.2. Для этого
создаем две переменные: первая содержит
номер пробы чугуна (N_ПРОБЫ), вторая –
процентное содержание кремния в чугуне
для соответствующей пробы (SI_%). Размер
таблицы в системе по умолчанию принят
10 на 10 (10 переменных с именами VAR1, VAR2, …,
VAR10 и 10 случаев). Чтобы изменить имя
переменной необходимо выбрать пункт
менюEdit/Variables/Current Specsили нажать комбинацию клавиш [Ctrl]+[F2], а
затем в диалоге указать нужное имя.
Исходные
данные для анализа возьмем из примера
3.11, в котором приведены результаты
обработки 50 проб передельного чугуна
на предмет содержания в них кремния
(табл.3.6). Заполним таблицу в системеSTATISTICAс исходными
данными как показано на рис.7.2. Для этого
создаем две переменные: первая содержит
номер пробы чугуна (N_ПРОБЫ), вторая –
процентное содержание кремния в чугуне
для соответствующей пробы (SI_%). Размер
таблицы в системе по умолчанию принят
10 на 10 (10 переменных с именами VAR1, VAR2, …,
VAR10 и 10 случаев). Чтобы изменить имя
переменной необходимо выбрать пункт
менюEdit/Variables/Current Specsили нажать комбинацию клавиш [Ctrl]+[F2], а
затем в диалоге указать нужное имя.
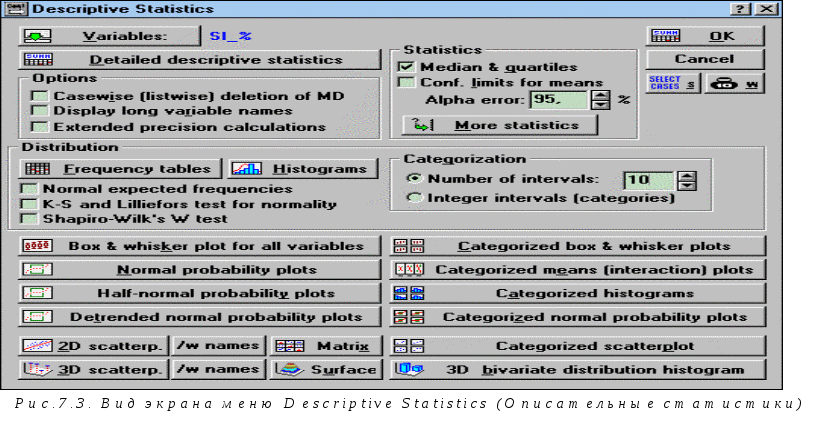
После того, как подготовлен файл исходных данных, выбираем пункт меню Analysis/Descriptive Statistics(Описательная статистика). В появившемся диалоговом окне, вид которого показан на рис.7.3, следует выбрать переменную для анализа нажатием кнопкиVariables. Мы выбрали переменную, содержащую данные о процентном содержании кремния в чугуне, имя выбранной переменной отражается рядом с кнопкойVariables. ДиалогОписательная статистикапозволяет:
в
 ычислить
разнообразные выборочные характеристики
(Statistics):Median&quartiles– медиана и квартили,Conf.
Limits for means– доверительные границы
для среднего. В строкеAlpha
error– можно задать требуемый уровень
значимости. Напомним, что уровень
значимости – это вероятность неправильного
отвержения гипотезы, когда она верна
(подробнее см. параграф 3.2). Более
расширенный набор статистик для расчета
можно выбрать нажатием кнопкиMore
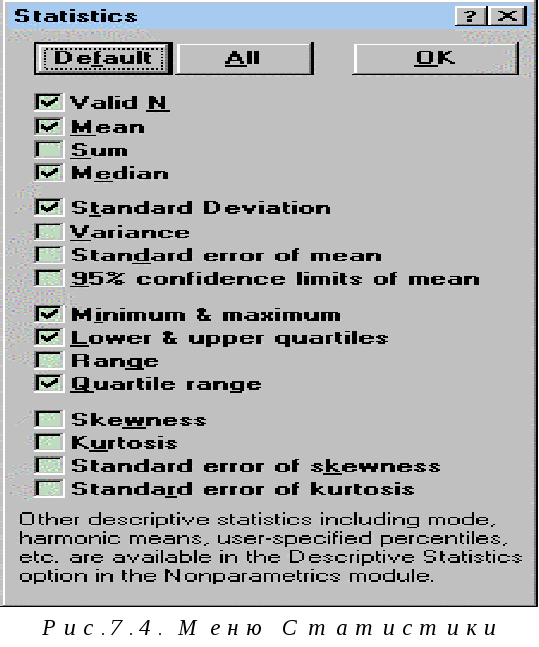
statistics(рис.7.4):Mean– среднее арифметическое,Sum– сумма,Median–
медиана,Standard Deviation– стандартное отклонение,Variance– дисперсия,Minimum&maximum– минимум и максимум,Range– размах, т.е. разность между максимумом
и минимумом,Skewness– коэффициент асимметрии,Kurtosis– коэффициент эксцесса,
ычислить
разнообразные выборочные характеристики
(Statistics):Median&quartiles– медиана и квартили,Conf.
Limits for means– доверительные границы
для среднего. В строкеAlpha
error– можно задать требуемый уровень
значимости. Напомним, что уровень
значимости – это вероятность неправильного
отвержения гипотезы, когда она верна
(подробнее см. параграф 3.2). Более
расширенный набор статистик для расчета
можно выбрать нажатием кнопкиMore
statistics(рис.7.4):Mean– среднее арифметическое,Sum– сумма,Median–
медиана,Standard Deviation– стандартное отклонение,Variance– дисперсия,Minimum&maximum– минимум и максимум,Range– размах, т.е. разность между максимумом
и минимумом,Skewness– коэффициент асимметрии,Kurtosis– коэффициент эксцесса,
построить для выборки таблицу частот (Frequency Tables)и гистограмму частот(Histograms);отметив пунктNormal expected frequencies, можно нанести на гистограмму кривую нормального распределения и визуально оценить соответствие исходных данных нормальному закону распределения;
проверить гипотезу о нормальности распределения наблюдаемых случайных величин с использованием критериев Колмогорова–Смирнова и Шапиро–Уилкса, выбирая их в разделе Distribution.
 Для
визуализации результатов имеется
возможность построения разнообразных
графиков, вызываемых нажатием
соответствующей кнопки в нижней части
экрана.
Для
визуализации результатов имеется
возможность построения разнообразных
графиков, вызываемых нажатием
соответствующей кнопки в нижней части
экрана.
Результаты статистического анализа выводятся в специальное окно. Для данных из примера вид окна с результатами показан на рис. 7.5, из которых следует, что среднее арифметическое (математическое ожидание) содержания кремния в чугуне составляет 0,6504%; выборочная дисперсия 0,0185%; максимальное и минимальное значения равны соответственно 0,32% и 0,95%; действительное содержание кремния в чугуне с вероятностью 95% лежит в интервале от 0,6117% до 0,6891%. Заметим, что эти данные близки к результатам, полученным ранее в примере 3.11 с помощью пакета Microsoft Excel, небольшие расхождения объясняются точностью представления результатов.
Проверка нормальности распределения
Рис.7.5.
Вид окна с результатами расчета статистик
из примера 3.11
Рис.7.6.
Гистограмма распределения содержания
кремния в чугуне с
результатами
проверки гипотезы о нормальности
распределения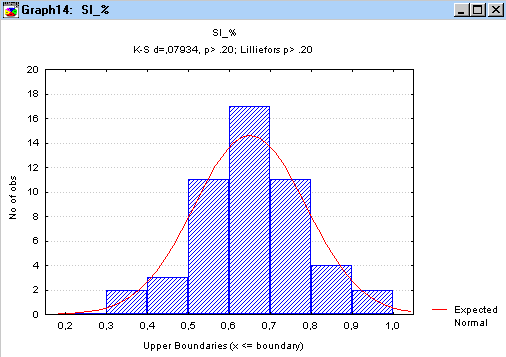
Регрессионный анализ
Применение системы STATISTICAдля регрессионного анализа рассмотрим на примере исследования взаимосвязи среднемесячного удельного расхода кокса и соответствующей величины удельного выхода шлака по данным работы одной из доменных печей завода "Запорожсталь", приведенным в книге В.И.Коробова "Статистические исследования доменного процесса" (М.:Металлургия, 1977. 184с.) и проиллюстрированным в табл. 7.1. Напомним, что задача регрессионного анализа состоит в том, чтобы по наблюдениям входных (X) и выходных (Y) параметров:
построить регрессионную модель (уравнение регрессии), т.е. оценить параметры модели (коэффициенты уравнения) наилучшим образом;
построить доверительные интервалы для коэффициентов модели;
проверить гипотезу о значимости регрессии;
оценить степень адекватности модели и т.д.
Из теории доменного процесса известно, что величина расхода кокса зависит от выхода шлака, а не наоборот. Поэтому зависимой переменной Y будет являться величина удельного расхода кокса, а независимой переменной X – величина удельного выхода шлака. Регрессионный анализ будем проводить в несколько этапов.
Таблица 7.1
Фактические данные о расходе кокса (К) и
выходе шлака (Ш) на одной из доменных печей "Запорожсталь"
|
№ пп |
К, кг/т чугуна |
Ш, кг/т чугуна |
№ пп |
К, кг/т чугуна |
Ш, кг/т чугуна |
№ пп |
К, кг/т чугуна |
Ш, кг/т чугуна |
|
1 |
674 |
841 |
31 |
613 |
763 |
61 |
524 |
645 |
|
2 |
680 |
855 |
32 |
614 |
739 |
62 |
526 |
682 |
|
3 |
698 |
861 |
33 |
611 |
722 |
63 |
536 |
624 |
|
4 |
679 |
817 |
34 |
608 |
748 |
64 |
545 |
665 |
|
5 |
675 |
817 |
35 |
625 |
781 |
65 |
546 |
670 |
|
6 |
637 |
782 |
36 |
613 |
772 |
66 |
558 |
662 |
|
7 |
628 |
757 |
37 |
628 |
796 |
67 |
552 |
664 |
|
8 |
619 |
765 |
38 |
618 |
739 |
68 |
541 |
654 |
|
9 |
633 |
792 |
39 |
618 |
800 |
69 |
525 |
615 |
|
10 |
669 |
792 |
40 |
597 |
758 |
70 |
543 |
607 |
|
11 |
636 |
792 |
41 |
570 |
746 |
71 |
527 |
590 |
|
12 |
642 |
762 |
42 |
562 |
725 |
72 |
523 |
602 |
|
13 |
646 |
844 |
43 |
575 |
737 |
73 |
524 |
608 |
|
14 |
610 |
806 |
44 |
562 |
773 |
74 |
524 |
601 |
|
15 |
608 |
791 |
45 |
556 |
752 |
75 |
541 |
611 |
|
16 |
604 |
772 |
46 |
565 |
746 |
76 |
541 |
684 |
|
17 |
595 |
777 |
47 |
548 |
720 |
77 |
551 |
580 |
|
18 |
597 |
820 |
48 |
546 |
711 |
78 |
527 |
585 |
|
19 |
600 |
833 |
49 |
542 |
686 |
79 |
536 |
621 |
|
20 |
620 |
790 |
50 |
544 |
682 |
80 |
532 |
600 |
|
21 |
642 |
863 |
51 |
511 |
699 |
81 |
529 |
573 |
|
22 |
625 |
822 |
52 |
532 |
697 |
82 |
534 |
577 |
|
23 |
631 |
824 |
53 |
560 |
702 |
83 |
531 |
566 |
|
24 |
628 |
859 |
54 |
562 |
713 |
84 |
520 |
549 |
|
25 |
628 |
839 |
55 |
551 |
733 |
85 |
526 |
577 |
|
26 |
603 |
842 |
56 |
550 |
706 |
86 |
522 |
550 |
|
27 |
611 |
781 |
57 |
550 |
696 |
87 |
519 |
552 |
|
28 |
618 |
760 |
58 |
541 |
656 |
88 |
518 |
575 |
|
29 |
619 |
787 |
59 |
557 |
683 |
89 |
525 |
552 |
|
30 |
618 |
787 |
60 |
552 |
705 |
90 |
546 |
608 |
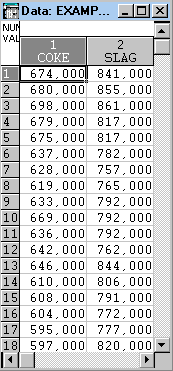 1.
Воспользуемся статистическим модулемNonlinear estimation(Нелинейное оценивание), в котором
создадим новый файл exampl2.sta и занесем в
него данные из табл.7.1. На рис.7.7 показан
файл с исходными данными. Переменные,
содержащие данные об удельных расходе
кокса и выходе шлака, обозначены
соответственно COKE и SLAG.
1.
Воспользуемся статистическим модулемNonlinear estimation(Нелинейное оценивание), в котором
создадим новый файл exampl2.sta и занесем в
него данные из табл.7.1. На рис.7.7 показан
файл с исходными данными. Переменные,
содержащие данные об удельных расходе
кокса и выходе шлака, обозначены
соответственно COKE и SLAG.
Рис.
7.7. Файл исходных данных для
регрессионного анализа
3. Из анализа наблюдений положения данных на графике делаем вывод о пригодности для оценивания полиномиальной регрессионной модели. Отметим в диалоговом окне (см. рис.7.8) модель оценивания Polynomialи нажмем кнопку ОК. В результате появится отдельное окно с графиком, в котором на точечные данные нанесена кривая, подобранная по методу наименьших квадратов и описываемая многочленом 5-го порядка (рис.7.10). Уравнение многочлена представлено в заголовке графика и имеет следующий вид:
![]()
Напомним, что абсолютная величина каждого коэффициента в уравнении регрессии характеризует вклад соответствующей степенной составляющей на параметр отклика y. Поэтому учитывая относительно небольшую величину коэффициентов b4и b5, делаем вывод, что для удовлетворительной точности регрессионной модели достаточно ограничиться полиномом 3-й степени.
Рис.7.9.
Наблюдаемые данные на плоскости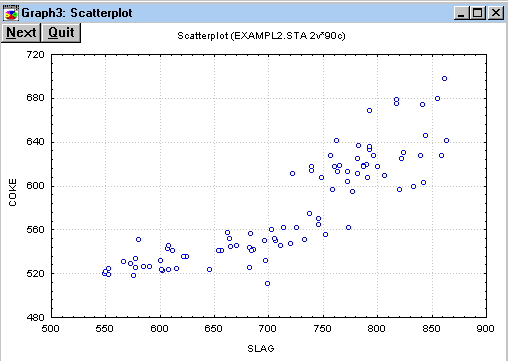

Рис.7.10.
Полиномиальная кривая, рассчитанная
по методу наименьших квадратов
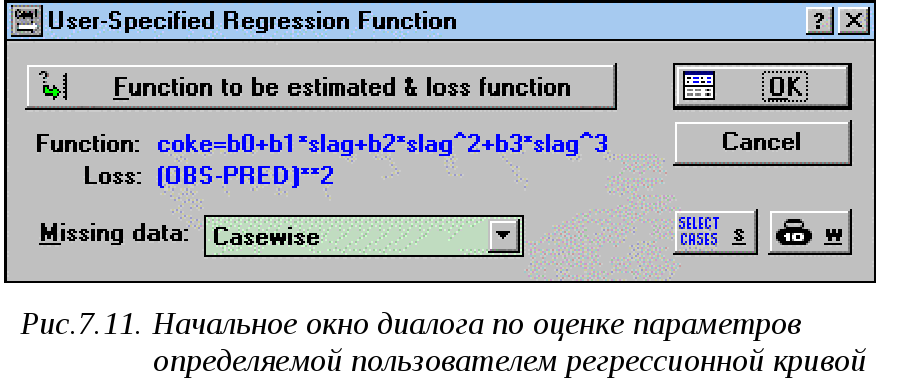 4.
Чтобы проанализировать регрессионную
модель из главного меню системыAnalysis(Анализ)выбираем пунктUser-specified
regression(Определяемая пользователем
регрессия). На экране появляется
начальное диалоговое окно (рис.7.11), в
котором нажатием кнопкиfunction
to be estimated & loss function(функция
оценивания и функция потерь)можно с
помощью формул задать функцию, которую
необходимо оценить, а также определить
функцию потерь. Зададим функциональную
зависимость между удельным расходом
кокса (COKE) и удельным выходом шлака
(SLAG) в виде полинома 3-й степени:
4.
Чтобы проанализировать регрессионную
модель из главного меню системыAnalysis(Анализ)выбираем пунктUser-specified
regression(Определяемая пользователем
регрессия). На экране появляется
начальное диалоговое окно (рис.7.11), в
котором нажатием кнопкиfunction
to be estimated & loss function(функция
оценивания и функция потерь)можно с
помощью формул задать функцию, которую
необходимо оценить, а также определить
функцию потерь. Зададим функциональную
зависимость между удельным расходом
кокса (COKE) и удельным выходом шлака
(SLAG) в виде полинома 3-й степени:
C
Рис.7.10.
Полиномиальная кривая, подобранная по
методу наименьших квадратов
Функция потерь по умолчанию задается в виде квадрата отклонения наблюдаемых от предсказанных с помощью регрессионной модели значений (OBS-PRED)2.
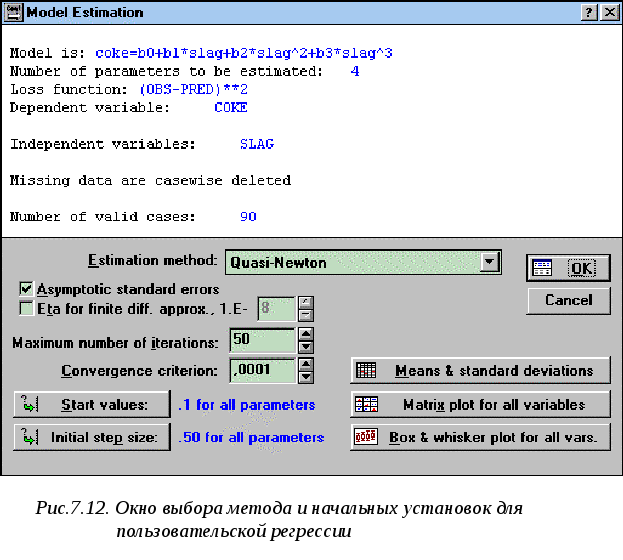 5.
Нажатие клавиши ОК приводит к появлению
окнаModel Estimation(Оценивание модели)для выбора метода
и начальных установок для пользовательской
регрессии (рис.7.12). В качестве метода
оценивания выберем квазиньютоновский.
В методах нелинейного оценивания важно
правильно подобрать начальные приближения.
Неизвестными параметрами модели являются
коэффициенты b0, b1, b2и b3. Нажав кнопкуStart
values(Начальные значения), в появившемся
диалоговом окне введем начальные
значения, предсказанные на основе
графического анализа данных в п.3:
b0=168100, b1=1204 b2=-3 и
b3=0,005. Нажатие клавиши ОК приводит
к появлению окна оценок параметров
модели на каждом шаге итерации. После
того как оценивание завершится внизу
окна появится сообщениеParameter
estimation process converged(Процесс оценивания
параметров сошелся).
5.
Нажатие клавиши ОК приводит к появлению
окнаModel Estimation(Оценивание модели)для выбора метода
и начальных установок для пользовательской
регрессии (рис.7.12). В качестве метода
оценивания выберем квазиньютоновский.
В методах нелинейного оценивания важно
правильно подобрать начальные приближения.
Неизвестными параметрами модели являются
коэффициенты b0, b1, b2и b3. Нажав кнопкуStart
values(Начальные значения), в появившемся
диалоговом окне введем начальные
значения, предсказанные на основе
графического анализа данных в п.3:
b0=168100, b1=1204 b2=-3 и
b3=0,005. Нажатие клавиши ОК приводит
к появлению окна оценок параметров
модели на каждом шаге итерации. После
того как оценивание завершится внизу
окна появится сообщениеParameter
estimation process converged(Процесс оценивания
параметров сошелся).
6. Далее нажимаем кнопку ОК, после чего открывается окно Results(Результаты), показанное на рис.7.13. Окно результатов имеет следующую структуру: верхняя часть окна – информационная, нижняя содержит функциональные кнопки, позволяющие всесторонне просмотреть результаты анализа. Информационная часть содержит краткую информацию о проведенном анализе, а именно:
Model is– вид модели оценивания. В нашем случае COKE=b0+b1*SLAG+b2*SLAG2+ b3*SLAG3
Dependent variable– зависимая переменная. В нашем примере это удельный расход кокса (COKE);
I
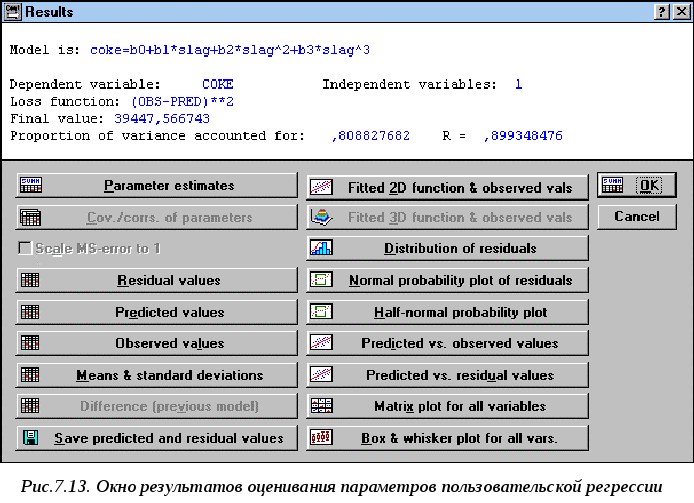 ndependent
variables– количество независимых
переменных. В примере независимая
переменная одна – удельный выход шлака;
ndependent
variables– количество независимых
переменных. В примере независимая
переменная одна – удельный выход шлака;Loss function– вид функции потерь;
Final value– последнее значение параметра, по которому система проводила подгонку модели.
Рис.7.14.
Результаты расчета коэффициентов
регрессионной модели
![]()
8. Далее следует оценить поведение остатков (residuals) модели, т.е. разностей между исходными (наблюдаемыми) значениями зависимой переменной и предсказанными с помощью модели. Исследуя остатки модели, можно оценить степень ее адекватности. С помощью функциональных кнопок в данном окне (см.рис.7.13) можно проанализировать остатки как в графическом виде, так и в электронных таблицах.
Рис.7.15. График
результирующей регрессионной кривой,
наложенной на наблюдаемые исходные
данные
Далее нажмем кнопку Predicted vs. residual values(Распределение остатков)и на экране появится график следующего вида (рис.7.17). Из этого графика видно, что остатки хаотично разбросаны на плоскости и в их поведении нет закономерностей. Нет основания говорить, что остатки коррелированы между собой. Следовательно можно заключить, что регрессионная модель достаточно адекватно описывает данные.
Рис.7.17.
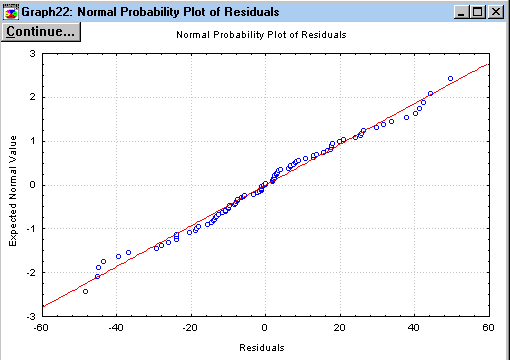
Распределение остатков на плоскости Рис.7.16.
График остатков на нормальной
вероятностной бумаге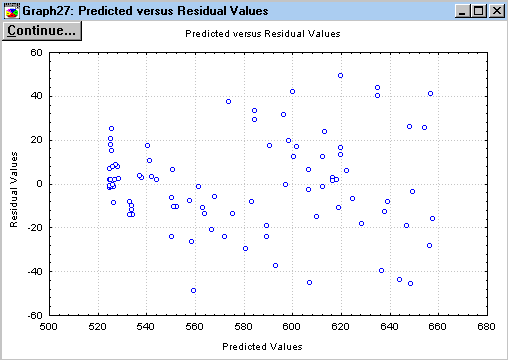
ПОБР(0,05;199;14)=2,
1Боровиков В.П. Популярное введение в программуSTATISTICA. – М.: КомпьютерПресс, 1988. – 267 с.