

Глава 11 Пространственные распределения
До сих пор наше путешествие фокусировалось на характеристиках наблюдаемых объектов. Но для правильной оценки окружения нам нужно знать также отношения между отдельными элементами, которые мы видим, и пространством между ними. Теперь мы будем рассматривать не объем пространства, занимаемый объектом, или его форму, а расположение объектов в пространстве, которое может характеризоваться количеством объектов в определенной области, тем, как они распределены - равномерно или группами. Мы рассмотрим отношения удаленности между самими объектами и их связь с общим размером занимаемой области.
Распределения могут наблюдаться во многих ситуациях. Мы знаем, например, что некоторые распределения человеческого населения характеризуются большой разбросанностью, подобно фермам в сельской местности. Другие распределения населения больше сконцентрированы в то, что мы называем городами. Растения и животные могут быть распределены равномерно или тоже в более плотные группы. Даже природные объекты, такие как типы отложений и формы рельефа — реки и холмы, горы и долины, - могут встречаться как отдельно стоящие так и в больших группах. Антропогенные объекты, такие как дороги, ограждения, дома, также могут быть определенным образом расположены. По мере развития нашего географического фильтра мы будем видеть еще больше. Видение того, что существуют различия в пространственном расположении объектов, позволяет нам формулировать вопросы о том, каковы картины этих распределений, как они могут быть классифицированы, и что они могут поведать нам о процессах, их создавших.
Если мы повторно посетим места, где впервые наблюдали расположение объектов, будь то в реальном мире или в мире ГИС, то мы увидим, что наблюдаемая картина изменилась. Регионы, которые прежде имели разрозненные распределения, теперь могут демонстрировать признаки группирования. Объекты, которые были когда-то организованы в пространстве случайным образом, теперь встречаются в регулярных, повторяющихся паттернах. Одни паттерны могут проявлять расширение и рост упорядоченности, другие - сжатие или деструктуризацию. Области могут сливаться, отдельные линейные объекты - соединяться в сети, установившиеся дюны — перемещаться и рассеиваться. Во всех этих случаях время является важной составляющей частью в нашем понимании расположения в пространстве. И вскоре мы задаёмся вопросом: что за процессы вызывают переход от одного распределения к другому? Мы можем задаваться вопросами: каковы могут быть направления изменений, существуют ли движущие силы, которые мы можем понять, каковы могут быть верхние и нижние пределы этих сил, и т.д.
В данной главе мы будем заниматься главным образом распределениями объектов одного покрытия. Это, конечно, ограниченный подход, и по моему опыту я могу сказать, что вы вскоре сами увидите методы, в которых используются данные других покрытий. Немного терпения, и вы узнаете, как распределения объектов могут сравниваться друг с другом. А там уже недалеко и до сравнения объектов разных покрытий, что является темой Главы 12.
ПРОСТРАНСТВЕННЫЕ РАСПРЕДЕЛЕНИЯ
Пространственное распределение это расстановка, порядок, концентрация или рассеянность, соединенность или бессвязность многих объектов в пределах заключающего их географического пространства. До сих пор рассматриваемые нами методы имели дело главным образом с отдельными объектами или наборами объектов, когда они могли быть определены как регионы, окрестности или представлены как статистические поверхности. Мы лишь очень кратко касались взаимодействия объектов, регионов, поверхностей и окрестностей с аналогичными объектами других покрытий. Но большинство объектов, встречающихся в одном покрытии тоже имеют определимые характеристики пространственного расположения, которые могут указывать на механизмы их возникновения.
По традиции, термин "пространственное распределение" обычно относится к простому картографическому отображению пространственно распределенных объектов. Исходя из парадигмы сообщения, мы могли бы сказать, что карта показывает, где объекты находятся и каковы очертания занимаемой ими области. Можно было бы сказать, что этого достаточно. Но интуитивно мы понимаем, что есть что-то ещё, помимо того, что может быть использовано для описания взаимодействий каждого отдельного объекта с его соседями и отношения всех этих объектов ко всему пространству, в котором они расположены. И, конечно, если мы сможем найти способы измерения этих отношений, то сможем найти пути выявления и понимания возможных механизмов, которые создают эти распределения.
Одни из рассматриваемых методов - вычислительно просты, другие -очень сложны и требуют много машинного времени. Одни применяются
очень часто, другие, хотя и чрезвычайно полезны, не получили широкого признания, так как о них редко рассказывают, за исключением аспирантур. Эту тему можно было бы проигнорировать, но я чувствую себя обязанным дать вам возможность пораньше узнать об этих методах анализа распределения объектов в пределах одного покрытия.
РАСПРЕДЕЛЕНИЯ ТОЧЕК
Возможно, наиболее распространенные методы анализа пространственных распределений применяются к точечным паттернам. Точечными объектами могут быть отдельные деревья, дома, животные, фонари и даже города, в зависимости от масштаба (Рисунок 11.1а). Как мы увидим в дальнейшем, точечные объекты могут также представляться в виде линий и областей (Рисунок 11.1b).
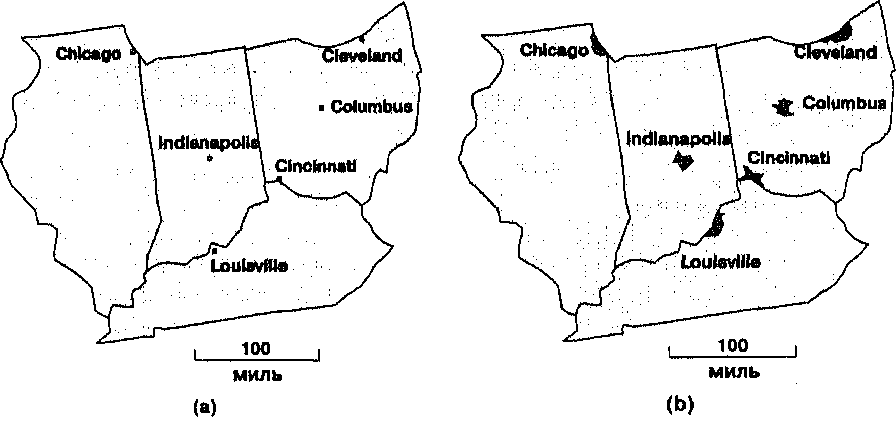
Рисунок 11.1. Точечное и площадное представление городов. Площадные объекты, в данном случае города, могут рассматриваться как точки (а) или как области (b), в зависимости от масштаба, в котором они представлены. Это указывает на связанность аналитических методов, которые могут применяться.
Простейшей мерой точечного распределения является плотность (density) точек. Она определяется как результат деления числа точек на общую площадь, на которой они расположены. Плотности населения, застройки, деревьев и т.д. широко используются как меры компактности точек. Сравнивая плотности подобных объектов в разных областях, мы можем сравнивать механизмы, которые действуют в этих областях. Или мы могли бы сравнивать точки в том же месте, но в разные моменты времени, чтобы увидеть изменения плотности во времени. Например, мы могли бы обнаружить, что плотность населения в городской местности со временем растёт, или что растёт плотность застройки, или что плотность деревьев снижается по мере их развития и роста конкуренции за пространство и солнечный свет. Даже этот простой статистический показатель, легко вычисляемый на растре и векторах, может дать нам множество полезных идей о наших данных.
Помимо общей плотности распределения, нас может интересовать еще и его форма. Точечные паттерны встречаются в одном из четырех возможных вариантов, характеристик. Распределение является равномерным (uniform), если число точек на единицу площади в каждой малой подобласти такое же, как и в любой другой подобласти. Если точки расположены в узлах сетки, разделенные одинаковыми интервалами по всей области, то равномерное распределение называется регулярным (regular), подобно рассмотренной ранее регулярной сетке отбора точек данных на поверхности. В других случаях равномерно распределенные точки располагаются в случайном (random) порядке по всей рассматриваемой области.
Бывают случаи, когда точки собраны в тесные группы, такое распределение называется сгруппированным или кластерным (clustered) (см. Рисунок 2.8).
Анализ квадратов
Равномерные точечные распределения определяются на основе отношений между одинаковыми подобластями, называемыми квадратами (quadrats). Это очень распространенный метод анализа дискретных зоологических и агрономических данных. Точками здесь могут быть отдельные растения, муравейники и т.д. Если каждый квадрат содержит примерно одинаковое число точек, то распределение является равномерным. Равномерные распределения редко встречаются среди биологических явлений, так как живым организмам свойственно мигрировать в сторону большей концентрации питательных веществ, лучшего орошения, определенного типа почвы и т.д. Если распределение действительно равномерное, то мы можем предположить, что нет существенного механизма, управляющего расположением объектов.
В стандартном методе анализа квадратов (quadrat analysis) [для равномерного распределения] мы предполагаем, что примерно одно и то же число объектов будет находиться в каждой подобласти, равное общему числу объектов, поделённому на количество подобластей. Для проверки равномерности распределения может использоваться относительно простой статистический показатель, который называется критерием х2 (хи-квадрат)
(chi-square test) и выражается формулой:
X2 = S[(Q-E)/E],
где Q - наблюдаемое число точек в квадрате, Е - ожидаемое число точек в
квадрате; суммирование проводится по всем квадратам.
Результат этого вычисления может быть сравнен с табулированными критическими величинами. Если полученное число незначительно отличается от ожидаемого, то распределение является равномерным; заметное отличие говорит о некоторой неравномерности, что может означать наличие какого-то процесса, лежащего в основе неравномерности. Хотя этот метод может считаться чисто статистическим, он может быть реализован в некоторых ГИС, особенно в растровых. Такой анализ могут выполнять и многие специализированные программы. Если вы не знакомы со статистикой, особенно применительно к пространственным данным, то можете заглянуть в какую-нибудь простую книгу на данную тему, например, [McGrew and Monroe, 1993]. Сейчас же достаточно помнить, что чем больше значение X2, тем ниже равномерность распределения.
Хотя результатом анализа в ГИС обычно считается карта, в данном случае результатом является одно лишь число. Здесь уместен такой вопрос: "Если распределение не равномерно, то какой механизм может быть ответственен за это?"
Чаще всего наблюдаемые нами точечные паттерны связаны с другими показателями (покрытиями) карты той же области исследования. Эти возможно связанные покрытия могут быть не только точечными, но и площадными. В нашем примере с биологией это могли бы быть параметры почв. Это приведет нас к сравнению точек одного покрытия с полигонами другого, что является уже темой следующей главы.
Помимо информации о равномерном распределении анализ квадратов может дать кое-что ещё. Например, отношение дисперсии к среднему (математическому ожиданию) (variance-mean ratio (VMR)), [McGrew and Monroe, 1993]. Здесь также используется критерий x2, который вычисляется как произведение отношения дисперсии к среднему на число подобластей за вычетом одной. Высокие значения x2 указывают на большой разброс между числом точек в каждой области и средним для всей области, то есть на то, что мы имеем кластерное (групповое) распределение [McGrew and Monroe, 1993]. И наоборот, малые значения x2 означают, что распределение более равномерное. Промежуточные значения указывают на то, что распределение более тесно связано с некоторым случайным процессом, где некоторые квадраты имеют несколько большее, а другие - несколько меньшее число, чем среднее.
Как и раньше, результаты анализа говорят, что если распределение не является статистически случайным (т.е. если оно либо равномерное, либо кластерное), то вы можете попытаться определить возможную причину, разумно выбрав набор показателей для сравнения с вашим точечным покрытием. Например, равномерные распределения могут быть регулярными, как плодовые деревья в саду, или случайными, что более свойственно деревьям в лесу. В первом случае в каждой подобласти будет встречаться одинаковое число точек, во втором случае числа будут разными.
Анализ ближайшего соседа
До сих пор мы описывали точечные распределения количеством точек в пределах подобластей. Другими словами, мы рассматривали распределение точек посредством сравнения областей, которые они занимают. Однако, также поучительно рассмотреть локальные отношения внутри пар точек. Чаще всего это делается другим методом анализа точечных распределений - анализом ближайшего соседа (nearest neighbor analysis), общепринятой процедурой определения расстояния от каждой точки до ее ближайшего соседа (РБС) и сравнения этой величины со средним расстоянием между соседями. Вычисление этого статистического показателя включает определение среднего РБС среди всех возможных пар близколежащих точек (такие точки определяются как ближайшие к выбранной).
Среднее РБС дает меру разреженности точек в распределении. Это ценно само по себе, так как в некоторых случаях точечные объекты могут конфликтовать, если они расположены слишком близко друг к другу. Например, мы знаем, что многим животным требуется определенное жизненное пространство, и когда оно перекрывается с пространством другого представителя того же вида, возможен конфликт.
Но, как и в анализе квадратов, мы можем сравнить среднее РБС с тремя возможными распределениями - регулярным, случайным и кластерным. Этот метод может быть описан в общем [детально - см. McGrew and Monroe, 1993] для каждого из этих случаев как вычисление индекса, с которым вы можете сравнить свои результаты, как это указано далее. Для индекса случайного распределения поделите 1 на удвоенный квадратный корень из плотности точек (число точек на единицу площади). Если вам нужен критерий максимальной рассеянности (dispersion) (регулярное распределение), то поделите 1.07453 на квадратный корень из плотности точек. Наконец, для критерия максимальной сгруппированности, когда точки расположены одна под другой, мы можем просто принять, что величина получается делением на ноль (the value is of the divisor 0). В результате мы получаем некоторое неотрицательное значение индекса.
Простое сравнение вашего среднего РБС с тремя индексами даст вам понятие о том, в каком месте диапазона они находятся.
Давайте рассмотрим, как это работает на примере данных Таблицы 11.1 и Рисунка 11.2. У нас есть шесть точек, данных в пределах площади в 25 квадратных единиц. Среднее РБС этих данных составляет примерно 1.4. Для случайным образом распределенных данных индекс составит (единица, поделенная на удвоенный корень из плотности точек (6 точек на 25 единиц площади = 0.24), т.е. 1/(2 ^0.24) = 1.02. Наше среднее РБС несколько больше, чем этот индекс.
Таблица 11.1. Вычисление расстояния до ближайшего соседа
|
Точка |
Координаты |
Ближайший |
РБС | |
|
|
X |
Y |
сосед |
|
|
А |
0.7 |
1.0 |
b |
1.6 |
|
В |
1.25 |
3.0 |
С |
1.4 |
|
С |
2.5 |
3.7 |
D |
1.3 |
|
D |
3.3 |
2.75 |
С |
1.3 |
|
Е |
4.0 |
4.0 |
С |
1.34 |
|
F |
3.8 |
1.0 |
D |
1.5 |
|
|
|
|
|
8.44 |
|
Среднее РБС |
|
|
1.4 | |
|
Случайное среднее РБС |
|
1.02 | ||
Критерий максимальной рассеянности точек составит 1.07453, поделенное на квадратный корень из плотности точек, т.е. округленно 2.19. Таково было бы значение, если бы наше распределение точек было идеально равномерным. Наше среднее РБС намного меньше этого, но и намного больше, чем 0, который соответствует идеально сгруппированному распределению. Таким образом, мы нашли, что наше распределение несколько более рассеянное, чем случайное, или где-то между истинно равномерным и случайным. Другими словами, оно начинает принимать более регулярную конфигурацию, но пока все еще довольно случайное.
РБС является абсолютным статистическим показателем, следовательно, он не может непосредственно сравниваться с РБС других точечных распределений. Индекс ближайшего соседства может быть нормализован для выполнения таких сравнений [McGrew and Monroe, 1993], но это уже выходит за рамки данной книги. Существуют также и другие методы определения кластеризации, основанные на других статистических показателях [Davis, 1986; Griffiths, 1962, 1966; Ripley, 1981], но это также выходит за рамки данной книги.
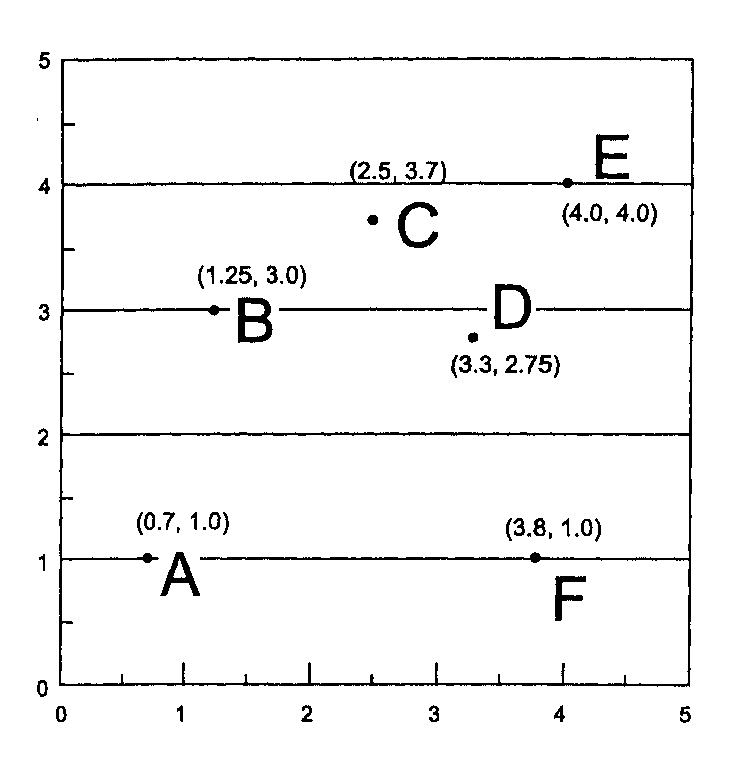
Рисунок 11.2. Координаты точек для определения РБС. Каждая точка (например, точка А) имеет своего ближайшего соседа (в данном случае, точка В). Расстояния определяются с помощью теоремы Пифагора (см. Таблицу 11.1).
ПОЛИГОНЫ ТИССЕНА
Точечные распределения могут также характеризоваться с помощью полигонов Тиссена (Thiessen polygons) (называемых также диаграммами Дирихле (Dirichlet diagrams) и диаграммами Вороного (Voronoi diagrams)). Они основаны на идее, что мы можем нарастить полигоны вокруг точек, чтобы показать их возможные зоны влияния на другие точки покрытия. Например, как мы увидим при работе с моделью гравитации, можно считать, что между точками действуют силы притяжения.
Вдобавок, размер точки - например, города - часто напрямую связан с силой такого влияния. Мы ограничимся случаем равной величины всех точек, что упрощает описание.
Создание полигонов Тиссена довольно просто концептуально, но может стать запутанным, если количество точек велико. Чтобы понять, как их строить, давайте вначале разберемся, что эти фигуры должны представлять. Если у нас есть несколько точечных объектов, таких как города (опять же, одного размера), мы можем представить себе, что каждая точка окружена одиночным неправильным многоугольником. Но многоугольник имеет одно важное свойство - любая точка внутри него находится ближе к очерченной точке, чем любая другая точка покрытия. И наоборот, каждая точка вне полигона ближе к некоторой иной, нежели к очерченной. Другими словами, граница каждого полигона дает окружаемой точке наименьшую возможную область влияния. Каждая точка покрытия будет иметь свой собственный полигон Тиссена, показывающий область исключительно ее влияния [Clarke, 1990]. Теперь давайте подумаем, как мы могли бы сделать это.
Возьмем простой набор точек (Рисунок 11.3). Образование полигонов Тиссена можно представить как результат роста мыльных пузырей с центром в каждой из точек. В конце концов границы пузырей превращаются в прямые линии, а сами пузыри - в многоугольники. Стороны этих многоугольников ориентированы перпендикулярно линиям, соединяющим соседние точки. Причем длины двух отрезков, получившихся с обеих сторон границы, одинаковы.
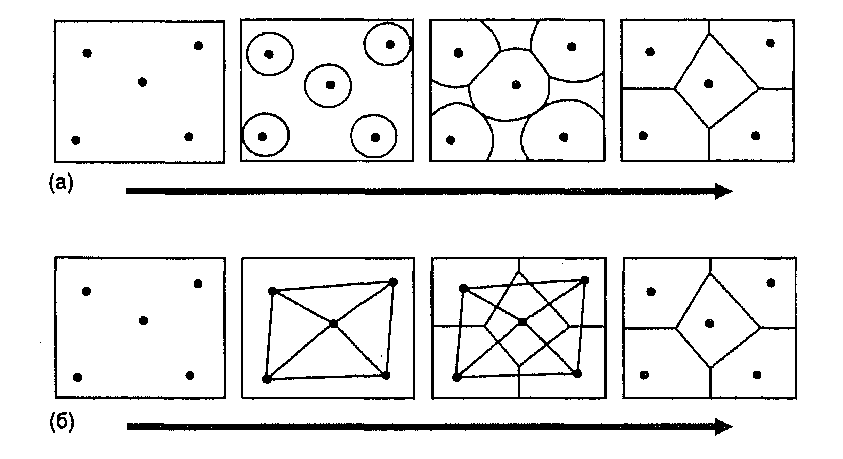
Рисунок 11.3. Создание полигонов Тиссена. а) расположение точек; b) построение связанных с ними полигонов Тиссена.
Алгоритмы создания полигонов Тиссена разрабатывались на протяжении десятилетий как для систем компьютерной картографии, так и для ГИС, как векторных [Brassel and Reif, 1979], так даже и на структуре данных
Пространственные
распределения
квадродерева [Mark, 1987].
Зачем же нужны полигоны Тиссена? Они названы в честь климатолога Тиссена (А.Н. Thiessen), который пытался проинтерполировать сильно неравномерные распределения климатических данных. Иначе говоря, он пытался описывать и анализировать точечные данные с помощью площадных символов и аналитических методов. Таким образом, если у нас есть несколько разбросанных точек, и мы хотим охарактеризовать регионы, основанные на этих точках, то используем полигоны Тиссена. Поскольку мы считаем, что в каждом полигоне влияние очерченной точки абсолютно, мы можем обращаться с этими данными как с полигональным покрытием.
Большинство случаев применения полигонов Тиссена связано с определением влияния точечных данных, представляющих торговые центры, фабрики или другие объекты экономики. Если мы изменим положение общей границы смежных полигонов в зависимости от размера или иного параметра очерчиваемых ими точек, то полученное разбиение будет еще лучше представлять реальное влияние объектов на окружающее пространство. Имея такую информацию, специалист по экономическому размещению может определить, например, какая часть населения города (на основе близости) скорее всего будет регулярно посещать планируемый торговый центр. Полигоны Тиссена используется не только в экономической географии, но и, например, при выявлении пространственных распределений растительности [Hutchings and Discombe, 1986]. На самом деле, использование этой методики скорее всего будет расти с расширением функциональных возможностей ГИС и известности среди пользователей.
РАСПРЕДЕЛЕНИЯ ПОЛИГОНОВ
Мы можем начать анализировать распределения областей во многом подобно тому, как мы делали это с точками - через определение плотности полигонов на единицу площади нашей области изучения. Однако, при определении меры плотности полигонов мы должны вначале измерить площадь полигонов каждого класса, из тех, что интересуют нас. Затем мы делим суммарную площадь каждого типа полигонов (т.е. каждого региона) на общую площадь покрытия. Это дает относительную долю полигонов, а не число их на единицу площади. Возможно, конечно, подсчитать число полигонов (или групп ячеек растра) на единицу площади, но из-за возможности широкого варьирования их размеров данный подход вряд ли будет полезен.
Опять же, помимо плотности полигонов, нас может интересовать расположение и формы распределений, создаваемые группами полигонов, которые могут подсказать причины таких расположений. Примерами потенциально взаимодействующих полигонов могут быть усовершенствования в методах вспашки в некоторых хозяйствах, города, поселки и перемещение товаров и услуг внутри них и между ними, и даже водные источники, распределенные по территории, которая могла бы предоставить хорошие места для зимовки птиц. Но перед тем, как рассматривать взаимодействия полигональных объектов, мы должны узнать кое-что о том, как они могут быть расположены. Как и точки, области могут быть сгруппированы, рассеяны (регулярно), или случайным образом разнесены по отношению друг к другу (см. Рисунок 2.8). Кроме этого, площадные объекты могут быть соединены друг с другом, или удалены на некоторые определимое расстояние.
Статистик соединений
При работе с полигональными покрытиями мы будем нередко создавать бинарные карты (binary maps), т.е. такие, на которых имеются только две категории полигонов, - чаще всего таких, которые характеризуют некоторый показатель как хороший или плохой для искомого решения. Например, могут быть плохие и хорошие почвы для пропашных культур, хорошие и плохие уклоны для строительства, хорошие и плохие аспекты для установки солнечных батарей. Возможность определения распределений некоторых из этих показателей может пригодиться, возможно, потому, что мы должны размещать дома, растения или солнечные батареи одной большой группой (что характерно для кластерных распределений), а не разрозненно. Мы можем также интересоваться выявлением распределения объектов определенной области, таких как размытые поверхности, сорная растительность или типы заселения для выяснения какой-нибудь возможной причины образования наблюдаемых примеров.
Мы уже познакомились с понятием непосредственной окрестности на основе смежности, определяемой как условие контакта полигональных объектов друг с другом (Глава 9). Но, хотя простая мера смежности может быть полезна для рассмотрения размеров соединенных полигонов одного типа, она мало что говорит нам о распределении, образуемом этими региональными полигонами. Для этого применяется статистический показатель (статистик) соединений (общих границ). Он не связан только лишь с бинарными картами, но так как они лучше его иллюстрируют, и относительно просто перейти от многокатегориальных карт к бинарным [McGrew and Monroe, 1993] (что является обычной практикой), мы ограничимся только случаем бинарных полигональных карт.
Соединение - это общая граница двух смежных полигонов. Статистик соединений подсчитывает количество соединений в полигональном распределении и характеризует структуру соединений каждого покрытия [McGrew and Monroe, 1993]. Посмотрите на Рисунок 11.4а, показывающий область с пятнадцатью полигонами, и имеющимися между ними соединениями.
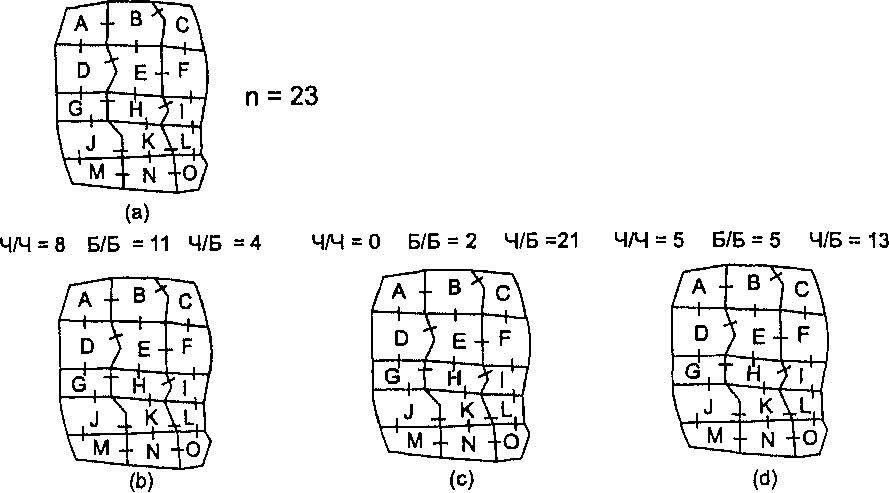
Рисунок 11.4. Статистик соединений для области из 15 полигонов: а) 23 возможные соединения, b) кластерное распределение, с) разреженное распределение, d) случайное распределение.
Всего между полигонами имеются 23 соединения (т.е. общих участков границ). На Рисунке 11.4b среди них: 8 соединений между заштрихованными полигонами, 11 - между белыми и 4 - между заштрихованными и белыми. Эти числа показывают, что между заштрихованными и белыми полигонами имеется мало соединений, большинство белых полигонов соединены друг с другом, и большинство заштрихованных полигонов соединены друг с другом. Другими словами, полигоны сгруппированы, подобно тому, что мы прежде наблюдали с точками. Рисунок 11.4с показывает совершенно другой набор чисел; здесь большинство соединений (21 из 23) - между полигонами разных классов, т.е. мы имеем разреженное распределение. Рисунок 11.4d -промежуточный случай: оба числа соединений однородных полигонов низки, но не так, как на Рисунке 11.4с. Число разнородных соединений также не настолько высоко, как в случае разреженного распределения. Таким образом, здесь мы имеем дело со случайным распределением.
Теперь обратимся к вопросу об использовании результатов Данного вида анализа.
Мы определили числа однородных и неоднородных соединений и можем выделить три различных класса распределений. Но как в действительности сравнить результаты анализа одной БД с тем, что можно было бы ожидать при кластерном, разреженном и случайном распределениях? Главным образом, нас интересует случайность, она говорит о том, что расположение полигонов скорее всего не зависит от какой-либо причины. И наоборот - в двух других случаях такая причина наверняка существует.
При анализе точечных распределений для оценки случайности мы обращались к критерию х2. Но этот показатель подразумевает, что мы знаем, каким должно быть ожидаемое распределение в условиях случайности. Если бы мы знали подобные распределения для полигонов (на основе числа соединений), то могли бы сравнивать их точно таким же способом.
Но как мы узнаем ожидаемое случайное распределение соединений, с которым могли бы сравнить имеющиеся значения? Имеются два подхода к решению этой задачи. Первый, называемый свободным отбором (free sampling), предполагает, что мы можем определить ожидаемую частоту соединений внутри категорий и между ними либо на основе теоретического знания моделируемой ситуации, либо исходя, из известных распределений для больших областей исследования. В первом случае, например, мы могли бы знать, что вследствие определенных зональных установлений в городе, торговые центры или объекты промышленности встречаются с определенной регулярностью по сравнению с другими типами землепользования. И тогда мы могли бы сравнить эти распределения с регулярностью торговых областей в другом городе, чтобы увидеть, используется такое же зонирование или другое, приводящее к существенно другому распределению торговых центров и объектов промышленности по сравнению с другими типами землепользования. Во втором случае, т.е. при использовании известного распределения на большей изучаемой области, могут быть выполнены подобные же сравнения. Скажем, нам известно распределение полигональных соединений нашего округа из анализа сельхозкультур. Тогда мы могли бы рассмотреть распределение их в отдельном пригородном районе и сравнить число соединений в этой подобласти с числом соединений для всего округа, чтобы увидеть, имеется ли сходство.
Второй подход, называемый несвободным отбором (nonfree sampling), применяется более часто. Он не делает теоретических предположений о распределении и не полагается на сравнение чисел соединений подобласти и всей области. В нем сравниваются числа соединений оценочного случайного распределения с числом соединений наблюдаемого распределения полигонов. Другими словами, мы создаем случайное распределение, исходя только из самих полигонов. Тогда мы можем сравнить имеющиеся результаты со случайным распределением, имея в виду отклонения от случайности, говорящие о действии некоторого причинного механизма.
Как свободный, так и несвободный отбор могут дать понимание распределения, но эти вычисления выполняются чаще опытными пользователями ГИС, нежели новичками. Поэтому мы не будем здесь рассматривать детали вычислений сравнительных показателей.
Впрочем, вы можете обратиться, например, к исследованиям, показывающим, как это делается по отношению к губернаторским местам Республиканцев и Демократов в восточной части США [McGrew and Monroe, 1993].
Другие меры распределений полигонов
Анализ распределений полигонов может быть весьма сложным, и связи ГИС с другим программным обеспечением дают возможность выполнять его [Baker and Cai, 1992; McGarigal and Marks, 1994]. Ландшафтные экологи часто используют эти методы, обычно рассматривая полигоны как островки (patches), особенно по отношению к большему, более однородному окружению (background), так называемой матрице (matrix). Вы можете в дальнейшем обратиться к соответствующей книге [Forman and Godron, 1986} за обзором некоторых из этих методов. В общем случае вы найдете меры полигональной изолированности (polygonal isolation), меры доступности (accessibility), взаимодействий полигонов (polygon interactions) и рассредоточенности (dispersion). Поскольку многие из этих мер заимствованы из литературы по географии, биогеографии, экологии, лесоводства и других дисциплин, примеры будут достаточно разнообразны, чтобы дать вам представление о возможностях использования этих дополнительных мер.
РАСПРЕДЕЛЕНИЯ ЛИНИЙ
Мы встречаем линейные паттерны постоянно, но часто и пропускаем их. Улицы и шоссе образуют узнаваемый паттерн, который мы относим к сетям, создаваемым человеком для перемещения людей и вещей между пространственно распределенными точками, называемыми городами. Нам встречаются ограждения, также имеющие определенные конфигурации и количества в зависимости от размеров полей, участков, форм полигонов, которые они окружают [Simpson et al., 1994]. Полосы на открытых участках коренной породы показывают параллельные линии перемещения камней под ледником, проходившем тысячи лет назад. Механизмы, вызвавшие образование каждого из этих линейных паттернов, лучше всего могут быть поняты, если мы прежде определим конкретные параметры соответствующих распределений.
Плотность линий
Поскольку линии в отличие от точек имеют пространственную протяженность, анализ их распределений несколько сложнее. Одни исследователи изучали распределения длин линий [Aitchison and Brown, 1969], другие рассматривали интервалы между линиями [Dacey, 1967; Miles, 1964], во многом подобно анализу ближайшего соседа в точечных распределениях [Davis, 1986].
Мы рассмотрим эти и другие меры распределений линий в последующих параграфах, и начнем с простейшей меры - плотности линий.
Мы определили плотность безразмерных точек как отношения их числа кзанимаемой ими площади. Плотность двухмерных полигонов определялась как отношение суммарной площади класса к площади всей карты. Подобным же образом, для определения плотности одномерных линий мы будем использовать отношение суммы их длин к площади покрытия. Выражаться оно может в метрах на гектар или километрах на квадратный километр. За исключением сравнения с аналогичными величинами для других регионов или для того же региона в другие моменты времени, мы мало что можем сделать с этой информацией. Поэтому сейчас мы рассмотрим другие показатели распределений линий, аналогично тому, как было с распределениями точек и полигонов.
Ближайшие соседи и пересечения линий
Распределение пар линий может быть определено во многом подобно тому, как мы поступали с точками, хотя вычисления несколько усложняются, так как, в отличие от точек, линии имеют размерность. Может показаться, что следует просто выбрать центр каждой линии и провести анализ ближайшего соседа для этих точек. Однако, вследствие того, что линии имеют различные длины, эта процедура не даст нам правдивой картины распределения самих линий. С точки зрения статистики часто считается полезным делать случайную выборку. Следуя этому подходу, нашей первой задачей в анализе ближайших соседей среди линейных объектов будет выбор случайной точки на каждой линии карты (или на каждом сегменте линии, если они - не прямые). Далее, опускается перпендикуляр из этой точки к ближайшей линии (Рисунок 11.5) [Davis, 1986]. Затем мы измеряем эти расстояния и подсчитываем среднее РБС. Как со всеми РБС, мы должны иметь возможность оценить эту величину по отношению к случайному распределению. Дэйси [Dacey, 1967] определил значения для ожидаемых РБС, дисперсии и стандартной ошибки случайного распределения линий. Эти величины позволяют нам сравнить ожидаемое и наблюдаемое и создать статистический показатель, по которому можно протестировать гипотезу о случайности [Davis, 1986]. По указанной ссылке можно найти описание соответствующих формул.
Этот критерий работает для большинства распределений линий, будь линии прямыми или изогнутыми, но имеет и некоторые ограничения. Если линии очень извилисты, этот подход - менее чем успешен.
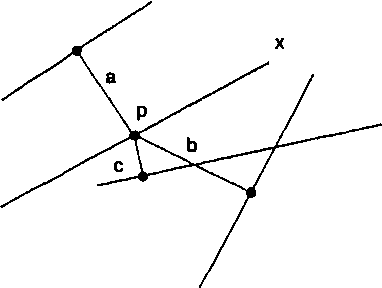
Рисунок 11.5. Расстояние до ближайшего соседа среди линий. Поиск ближайшего соседа между линиями с использованием случайно выбранной точки на одной из них.
Кроме того, чтобы критерий был полезен, линии должны быть по меньшей мере в полтора раза длиннее среднего расстояния между ними. Если количество линий в покрытии мало, оценка плотности, используемая в анализе ближайшего соседа должна быть скорректирована весовым коэффициентом (n-1)/n, где n - число линий распределения. То есть, вместо отношения суммы длин на площадь мы используем формулу
(n-l)L/nA,
где L- сумма длин, а А - площадь. Эта скорректированная плотность линий улучшит качество статистика ближайшего соседа.
Методы пересечения линий являются альтернативой при анализе распределения линий. Один простой подход состоит в том, чтобы преобразовать двухмерный паттерн в одномерную последовательность прочерчиванием выборочной линии через карту и учетом пересечений этой линии с линиями покрытия. Существуют по меньшей мере два способа создания таких линий [Getis and Boots, 1978]. Первый - случайно выбрать пару точек и соединить их линией. Второй метод состоит в проведении луча из случайной точки под случайным углом, откладывании случайного расстояния от начальной точки и проведении перпендикуляра к лучу из этой точки [Davis, 1986]. После того, как линия проведена, может быть рассмотрено распределение интервалов между пересечениями ее с линиями покрытия с использованием стандартных методов анализа наборов данных. Альтернативой одиночной линии является зигзагообразная, которая пересекает покрытие два или три раза. Зигзагообразный путь (часто называемый случайным обходом (random walk)) также создаст серию пересечений, расстояния между которыми опять же могут быть проанализированы любым статистическим методом для последовательностей данных (Рисунок 11.6).
Рисунок 11.6. Метод случайного обхода для оценки распределения линий.
Модификация метода пересечений с использованием зигзагообразной линии для получения точек выборки.
НАПРАВЛЕННОСТЬ ЛИНЕЙНЫХ И ПЛОЩАДНЫХ ОБЪЕКТОВ
Линейные объекты могут характеризоваться не только распределением по ландшафту, но и ориентацией. Такие объекты как осадочные напластования, русла ледников, переносимая водой галька, цепи валунов, оставленные ледниками, ограждения, сети улиц, ветровал деревьев в лесу имеют определенную ориентацию, которая часто указывает на породившую их силу.
Но когда мы анализируем ориентацию, у нас может возникнуть ситуация выбора между двумя встречными направлениями. Если линейный объект является улицей с односторонним движением, то ориентация ее самой не говорит нам о направлении, в котором должен двигаться транспорт. Поэтому, кроме ориентации нам нужно знать и о направленности (directionality). Мы можем также рассматривать распределения линейных объектов либо как двухмерные, либо как трехмерные, с учетом углового направления относительно поверхности сферы [Davis, 1986]. Для простоты мы ограничимся лишь первыми.
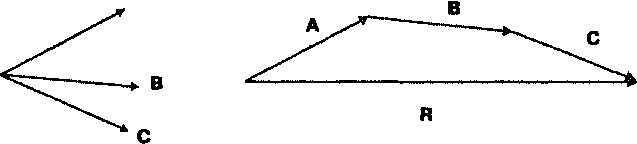
В традиционном статистическом анализе ориентации линий с карты переносятся на диаграмму направлений (rose diagram), где все они прочерчиваются из одной начальной точки. На некоторых диаграммах направлений длиной линий также изображают параметры объектов, такие как сила ветра или длина изгороди. Диаграммы направлений полезны для визуальной оценки, но измерения, получаемые непосредственно поданным покрытия больше подходят для численного анализа. Первым мы рассмотрим равнодействующий вектор (vector resultant). В качестве примера можно вспомнить басню про лебедя, рака и щуку. Зная силы и направления, приложенные к возу, можно определить, в какую сторону и с каким ускорением объект начнет движение.
Для демонстрации двухмерного анализа направлений возьмём большое количество деревьев, поваленных прямолинейным ветром. Каждое дерево может быть отображено как линейный объект покрытия, при этом записываются координаты вершины и основания каждого дерева, давая нам ориентацию каждого дерева (Рисунок 11.7).
Рисунок 11.7. Распределение направлений поваленных деревьев. Карта показывает общую тенденцию и некоторые отклонения от нее.
Метеорологи хотят выяснить общее направление ветра по поваленным деревьям, но эти деревья не имеют единой для всех ориентации, поэтому нашей первой задачей является определение равнодействующего вектора поваленных деревьев.
С каждым деревом ассоциируется вектор с началом в основании дерева и углом Q в сторону вершины. Мы умножаем длину каждого дерева на косинус этого угла для получения Х-составляющен, а также на синус этого угла для получения Y-составляющей. Для вычисления равнодействующего вектора мы складываем эти величины для каждой составляющей, и полученные значения равнодействующего вектора Хг и Yг показывают преобладающее направление вершинных точек деревьев в ветровале. Рисунок 11.8 показывает равнодействующий вектор R, полученный из трех векторов А, В и С.
Мы можем определить среднее направление Q исходя из равнодействующего вектора по формуле: Q = arctan (Yr/Xr).
Три вектора Равнодействующий вектор
Рисунок 11.8. Равнодействующий вектор.
Так как среднее направление наших векторов зависит не только от разброса деревьев, но и от числа наблюдений, мы можем нормализовать эти величины делением координат каждого равнодействующего вектора на число линейных объектов покрытия. Это позволит нам сравнивать две различные области, например, две области ветровала на предмет общего направления ветра*.
*
Следует отметить, что здесь угол
отсчитывается от оси Y,
а не от оси X, как принято в математике.
В формуле вычисления составляющих
длина дерева является весовым
коэффициентом для его направления.
Чтобы каждое дерево вносило одинаковый
вклад, следует приравнять его длину
единице. Тогда среднее направление
будет равно арктангенсу отношения
суммы косинусов к сумме синусов
направлений деревьев. Для данного
примера можно также отметить, что более
длинные деревья скорее всего будут
лучше представлять среднее направление,
так что нормализация будет излишней.
— прим,
перев.
 Длина
равнодействующего вектора (resultant
length)
может быть определена по формуле:
Длина
равнодействующего вектора (resultant
length)
может быть определена по формуле:
![]()
Таким образом, мы имеем не только среднее направление лесовала, но и меру компактности распределения: чем компактнее распределение, тем длиннее эта линия.
Для сравнения длины равнодействующего вектора в данном месте с другим местом, нам следует, опять же, нормализовать данные. Нормализованная длина равнодействующего вектора получается делением длины равнодействующего вектора R на сумму длин образующих его векторов.
Это безразмерная величина в диапазоне от 0 до 1, напоминающая дисперсию в традиционной статистике, так как является мерой пространственного разброса вокруг среднего значения. Правда, она выражает этот разброс "наоборот": большие значения соответствуют более близкой ориентации векторов, меньшие - большему разбросу. Таким образом, большое значение этого показателя в нашем примере с деревьями означало бы значительное преобладание одного из направлений ветра, а малое значение говорило бы о наличии завихрений или отсутствии явно преобладающего направления. Наряду с самой этой величиной можно использовать также и обратную ей величину, называемую круговой дисперсией (circular variance), которая равна единице минус нормализованная длина равнодействующего вектора. Если вы интересуетесь статистикой, то можете увидеть возможность существования дирекционных аналогов стандартного отклонения, моды и медианы, для которых также имеются соответствующие формулы [Gaile and Burt, 1980].
Остается одна проблема, связанная с ориентацией и направлением. Как мы знаем, одни линейные объекты могут иметь определенное направление (деревья), другие же - нет (лесозащитные полосы), хотя определенная ориентация присутствует в обоих случаях. Например, один исследователь, собирающий данные о заграждениях, может указывать, что некоторые из них ориентированы на север, а другой - что на юг. Тогда, при анализе данных, собранных этими исследователями, может оказаться, что при определении длины среднего равнодействующего вектора, исходные векторы будут, так сказать, взаимно уничтожать друг друга.
К счастью, для этого есть остроумное решение. Крумбейн [Krumbein, 1939] обнаружил, что при удвоении значения угла, независимо от исходного направления, записывается одно и то же значение. Допустим, мы имеем объект, ориентированный с северо-запада (315°) наюго-восток(135°). После удвоения мы получим: 315° х 2 = 630° (-360° = 270°) и 135° х 2 = 270°. Такой способ выражения направлений повлияет на формулы для вычисления среднего направления, нормализованной длины равнодействующего вектора и круговой дисперсии, поэтому, чтобы получить действительные значения, их нужно будет модифицировать.
Эти простые меры направленности и разброса могут быть проверены на случайность [Batschelet, 1965; Gumbelet al., 1953] и наличие тренда [Stephens, 1969] стандартными процедурами проверки статистических гипотез. С дирекционными данными покрытия могут сравниваться аналогичные данные других покрытий [Gaile and Burt, 1980; Mardia, 1972]. Эти темы выходят за рамки данной книги, а указанные источники предлагают подробное их рассмотрение.
В контексте ГИС, данные меры главным образом помогают охарактеризовывать распределения внутри покрытия и сравнения их с данными других покрытий в поисках причинных механизмов. Растровые ГИС плохо приспособлены для данного типа анализа, но большинство векторно-топологических систем позволяют определить по меньшей мере некоторые предварительные значения (например, углы отрезков полилиний), которые могут храниться в БД ГИС как атрибуты и передаваться другим программам для обработки, если сам ГИС-пакет не способен вычислять средние показатели направленности.
СВЯЗНОСТЬ ЛИНЕЙНЫХ ОБЪЕКТОВ
Важным аспектом пространственного расположения линий является их способность образовывать сети. Сети имеют самые разнообразные формы, как естественные, так и созданные человеком. Среди них: автомобильные и железные дороги, телефонные линии, реки, даже лесозащитные полосы могут играть роль сети, позволяющей мелким млекопитающим перемещаться по ландшафту, - список можно долго продолжать. И хотя мы можем интересоваться плотностью и ориентацией объектов, образующих сеть, нам нужна также и возможность анализировать реальные связи, образованные этими объектами и степень связанности между различными точками сети. Вы наверняка сталкивались с ситуациями, когда в городе нет прямой дороги от места до места, и приходится ехать кружным путем. Здесь мы сталкиваемся с недостатком связности (connectivity) в сети.
Связность является мерой сложности сети. Имеются несколько методов для определения этой характеристики [Haggett et al., 1977; Lowe and Moryadas, 1975; Sugihara, 1983; Taaffe and Gauthier, 1973]. Наиболее общими являются гамма-индекс (gamma index) и альфа-индекс (alpha index).
Гамма-индекс у является отношением числа существующих связей между парами узлов сети, L, к максимально возможному числу связей в том же наборе узлов, Lmax. Очевидно, что векторно-топологическая модель данных лучше всего подходит для этих вычислений. Определить же не так трудно, как может поначалу показаться, оно однозначно определяется числом узлов V. Например, если мы имеем три узла, то возможны лишь три связи (Рисунок 11.10). Если мы добавим еще один узел, то сможем добавить еще три связи, а всего их будет шесть [Forman and Godron, 1987]. И если мы полагаем, что не образуются новые пересечения, то максимальное число связей будет каждый раз увеличиваться на три. То есть, Lmax= 3(V - 2).
Гамма-индекс тогда определяется как
Y = L/Lmax = L/3(V-2)
Он принимает значения от 0 (нет ни одной связи) до 1 (все возможные связи присутствуют) [Forman and Godron, 1987].
Рисунок 11.10 показывает два варианта сети с 16-ю узлами. На рисунке
имеется 15 связей, что дает связность у = 15 / 3(16-2) = 0.36. На рисунке
имеется 20 связей, поэтому у = 20/3(16-2) = 0.48. Образно говоря, первая сеть связна примерно на треть, а вторая - наполовину.
Большее количество связей в сети облегчает передвижение по ней, что важно, например, для специалистов по транспортному планированию.
Важной характеристикой сетей помимо связности является наличие в ней контуров, позволяющих перемещаться от узла к узлу разными маршрутами. В качестве примера можно привести кольцевые автодороги вокруг крупных городов, позволяющие снизить нагрузку транзитного
транспорта
на уличную сеть.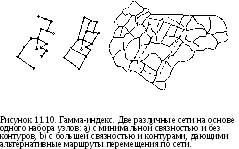 (а) (b) (с)
(а) (b) (с)
В качестве меры соединенности узлов контурами альтернативных маршрутов (circuitry) используется так называемый альфа-индекс (а). Он является отношением имеющегося в сети числа контуров к максимально возможному числу контуров в этой сети. Известно, что сеть без контуров имеет связей на одну меньше, чем число узлов: L = V - 1. На Рисунке 11.10а вы можете видеть такую сеть, - в ней 16 узлов и 15 связей. Она обладает минимальной связностью, в том смысле, что в ней имеется наименьшее возможное число связей при заданном числе узлов, причем каждый узел имеет по меньшей мере одну связь.
Добавление какой-либо связи создает контур, т.е. когда сеть содержит контуры L > V - 1. Число же имеющихся контуров можно определить как L -(V-1) [Forman and Godron, 1987].
Далее, так как максимальное число связей в сети определяется как 3(V -2), а минимальное (без потери связности) как V - 1, то максимальное число контуров будет 3(V - 2) - (V - 1), т.е. 2V - 5. Отсюда альфа-индекс а = (L - (V -1)) / (2V - 5). Диапазон значений альфа-индекса - от 0 (сеть без контуров) до 1 (сеть с максимальным числом контуров).
Теперь мы можем вычислить альфа-индекс для сетей на Рисунке 11.10:
а = (15 - 16 + 1) / (2 х 16 - 5) = 0
а = (20- 16 + 1)/(2х 16 - 5) = 0.19
Таким образом, в сети на Рисунке 11.10а есть только один вариант для перемещения из одной точки в другую, а на Рисунке 11. 10b возможны несколько альтернативных маршрутов разной длины.
Поскольку для создания контуров требуется добавление новых связей, вполне возможно рассматривать альфа-индекс как альтернативную меру связности. Но так как эти два индекса дают разные взгляды на сеть, будет более уместным объединить их некоторым образом для создания общей меры сложности сети (network complexity). Для вычисления данных индексов требуется использование векторной ГИС. Это требование подчеркивается тем обстоятельством, что вся эта статистика имеет топологическую основу теории графов, где гораздо важнее связность узлов, нежели их расположение или длины и формы линий, связывающих их.
Для транспортного моделирования нам нужно знать все-таки больше, чем просто параметры связности. Здесь имеют значение длины связей между узлами, возможные направления движения по этим линиям, значения сопротивления движению (импеданса). Вдобавок, существуют и другие простые индексы, пришедшие из теорий транспортировки и связи, которые также характеризуют связность сетей. Например, возможно определение интенсивности связности (linkage intensity) для каждого узла, числа альтернативных маршрутов между заданными узлами, поиск центрального узла (central place), т.е. такого, который имеет наибольшее число связей, а также построение регионов на основе связности и доступности [Haggett et al., 1977; Lowe and Moryadas, 1975]. И все это можно сочетать друге другом и с другими характеристиками линий - расположением, ориентацией, дисперсией - для получения более полной картины сети.
МОДЕЛЬ ГРАВИТАЦИИ
До сих пор мы не обращали внимание на значимость отдельных узлов, которая может быть неодинаковой. Но подумайте о городах. Крупные города по сравнению с мелкими дают больше возможностей для покупок, для посещения выставок, концертов, спортивных соревнований и т.д. Поэтому они привлекают больше людей. И города - не единственный пример, когда размер имеет значение. Например, большое озеро привлекает больше водоплавающих птиц, нежели маленький пруд.
Оба примера показывают, что более крупные объекты привлекают к себе большую активность, будь то птичью, или человечью. Размер такого притяжения может представляться во многом подобно гравитационному притяжению тел, обладающих массой. Чем больше масса, тем больше сила притяжения между ним и его соседями.
Перенося идею гравитационного притяжения на взаимодействие между узлами покрытия ГИС, мы получим модель гравитации (gravity model), которая в общем виде выражается как:
![]()
где Lij - величина взаимодействия между узлами i и j; Рi - величина узла i; Pj - величина узла j; d - расстояние между узлами; К - константа, определяемая природой взаимодействующих объектов. Величины узлов могут быть представлены такими их параметрами, как потребность в продукции, объем розничных продаж торговых центров города, площадью поверхности водоема для водных птиц.
Мы видим, что чем больше величины узлов, тем больше сила взаимодействия между ними, и что с ростом расстояния между узлами сила взаимодействия уменьшается. На примере города мы можем сказать, что чем больше город, тем более он привлекателен для торговли. С другой стороны, если город находится далеко от вас, вряд ли вы в него поедете, даже несмотря на возможную выгоду от сделки. [Как говорит русская поговорка, "за рекой телушка — полушка, да рупь перевоз".]
Существуют многие варианты данной простой модели притяжения между точками, как в растровых, так и в векторных системах. И хотя большинство из них используется для экономического анализа размещения объектов (также как и полигоны Тиссена), возможно и другое их применение. Исследователи могут использовать их для описания пассажиропотока между городами, объема телефонных вызовов, потоков птиц и семян, которые распространяются птицами между участками леса [Buell et al., 1971; Carkin et al., 1978; McDonnell, 1984; McQuilkin, 1940; Whitcomb, 1977]. В-общем, любые потоки между узлами различной величины могут анализироваться с применением модели гравитации.
МАРШРУТИЗАЦИЯ И АЛЛОКАЦИЯ
Среди наиболее применяемых приложений сетей в ГИС являются родственные задачи маршрутизации и размещения (аллокации) (routing and allocation). Простейший вариант маршрутизации включает поиск кратчайшего маршрута между двумя узлами сети (Рисунок 11.11). Учитывая, что узлам могут присваиваться весовые коэффициенты (как в модели гравитации), возможен вариант маршрутизации от некоторой заданной точки до ближайшей точки с максимальным весом (например, максимальным спросом на товар). Прекрасное описание маршрутизации и размещения можно найти в [Lupien et al., 1987].
Каждой связи в сети может быть присвоено значение импеданса (сопротивления, стоимости), во многом наподобие фрикционной поверхности, но налагаемого только на саму эту линию. Значение импеданса может быть связано, например, с ограничением скорости или даже запретом проезда по некоторым улицам, как, например, в случае закрытия дороги на ремонт. Используя нарастающее расстояние (accumulated distance) (см. Главу 8), с учетом как геометрического расстояния, так и значений импеданса, может строиться наиболее эффективный маршрут (т.е. маршрут наименьшей стоимости), а не просто кратчайший. Узлам также могут присваиваться значения импеданса или стоимости и запреты на их прохождение. Как и при определении функциональных расстояний на поверхности и стоимости передвижения по ней, все это требует априорного знания свойств улиц, перекрестков и других узлов. И нередко бывает так, что веса и импедансы задаются несколько произвольно или по интуиции.
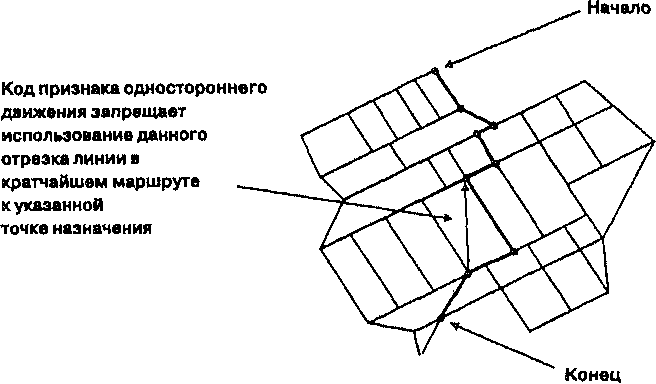
Рисунок 11.11. Кратчайший маршрут в сети. Результат работы алгоритма поиска кратчайшего маршрута в простой дорожной сети.
Хотя маршрутизация в принципе может выполняться на растре, она гораздо легче реализуется в векторной топологической модели данных, поскольку эта модель лучше других воспроизводит характеристики графов. Вам также следует знать, что вследствие наличия контуров в сети, возможны альтернативные маршруты между двумя заданными точками, а с учетом различных ограничивающих факторов, как статических (свойства дороги), так и динамических (наличие уже существующего движения), плюс различные виды оптимизации маршрутов (посещение набора узлов в заданном порядке, оптимизация использования парка транспортных средств, организация работы по обслуживанию множеств поставщиков и потребителей грузов, выравнивание нагрузки на дорожную сеть и т.д.) тема маршрутизации заслуживает отдельной толстой книги.
Аллокация (allocation) это процесс, который может использоваться для
определения, например, положения нового супермаркета, территориального покрытия станции водоочистки, или границ зон обслуживания противопожарных частей. Чаще всего при этом используется сетевая структура в векторной ГИС. Идея состоит в распространении возможностей заданной службы по сети. Каждая связь (или каждый узел) сети имеет определенное число обслуживаемых элементов. Например, каждый отрезок улицы имеет некоторое число домов, к которым подается вода. Каждый дом может рассматриваться также как потенциальный клиент для близлежащей противопожарной части [Lupien, et al., 1987]. Кроме того, каждая служба или каждый торговый центр имеют определенную максимальную нагрузку и предельное расстояние обслуживания, а срочные службы — ограничение по времени на обслуживание одного обращения; все это также учитывается при построении зон обслуживания (Рисунок 11.12). Если бы дорожная сеть была совершенно однородна (без импеданса, запретов, ограничений скорости и т.д.) аллокация была бы просто делом выбора критерия и расширения границ зон обслуживания от центров, пока эти границы не встретятся.
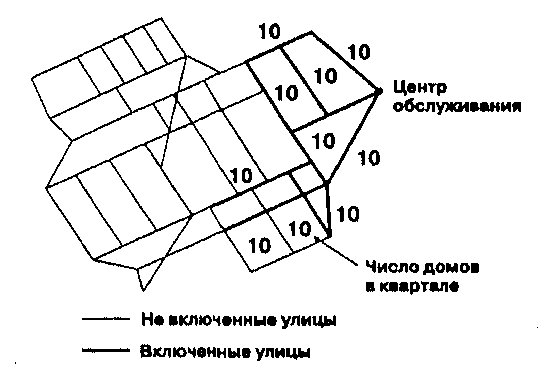
Рисунок 11.12. Аллокация в сети. Приписывание улиц, каждая из которых имеет по 10 домов к центру обслуживания, способному надежно обслуживать только 100 домов.
Например, если бы мы проводили аллокацию для распространителей газет, так чтобы машина каждого проходила только определенное число километров, программе пришлось бы просто подсчитывать километры, когда маршрут расширяется от начальной точки, пока не будет достигнут заданный километраж, после чего улицам будут присвоены соответствующие коды атрибутов распространителей.
Как вы могли догадаться, большинство реальных задач аллокации
Пространственные
распределения
довольно сложны, и на эту тему написаны серьезные труды. Здесь только следует еще упомянуть о связи почтовых адресов с линейными объектами, образующими покрытие уличной сети. Установление такого соответствия называется адресным геокодированием (address matching). Оно позволяет определять почтовый (логический) адрес по географическим или условным координатам объекта или топологическим координатам в сети, а также выполнять обратные преобразования. Его необходимость обусловлена тем, что люди используют логические адреса, в то время как ГИС оперирует координатами и топологией.
НЕДОСТАЮЩЕЕ ЗВЕНО: ПОЧЕМУ НУЖНО ИСПОЛЬЗОВАТЬ ДРУГИЕ ПОКРЫТИЯ
Здесь нужно лишь одно простое замечание. К настоящему моменту мы рассмотрели, как точечные, линейные и площадные объекты могут исследоваться на предмет их распределения, связности и ориентации, образования ими окрестностей. Однако, все эти аналитические операции часто имеют смысл только при соотнесении их с анализом других покрытий, что особенно верно для поиска причинных механизмов рассматриваемых явлений и определения влияния одних объектов на другие. В следующей главе мы займемся этими вопросами, которых и им подобных, на самом деле, гораздо больше, чем можно было бы подумать.
Вопросы
Что мы имеем в виду, когда говорим о распределениях объектов? Чем это знание нам полезно?
Как определяется равномерное распределение? Чем отличается регулярное равномерное распределение от случайного равномерного? Что такое кластерное распределение?
В чем важность регулярного, случайного и кластерного распределения по отношению к процессам, которые могли их вызвать? Приведите примеры каждого из названных распределений с указанием гипотез о причинах их образования.
Какова цель анализа квадратов? Опишите, как он выполняется. Какой статистический критерий мы используем для подтверждения или отклонения полученных результатов?
Каково назначение отношения дисперсии к среднему в точечных распределениях? Чем оно отличается от традиционного анализа квадратов?
Что говорит нам анализ ближайшего соседа в отличие от анализа квадратов? В чем сходство этих методов?
Каково назначение полигонов Тиссена? Изобразите несколько примеров и опишите, как эти полигоны создаются,
Опишите статистик соединений. О чем он говорит? Чем он отличается от простой меры смежности? В чем отличие свободного отбора от несвободного в их применении к проверке результатов подсчета
Опишите процесс анализа ближайшего соседа в линейных паттернах. Что он говорит нам о распределении линий? Опишите некоторые ситуации, в которых статистик ближайшего соседа может давать обманчивые результаты.
Опишите применение метода пересечения линий для анализа распределений линий. Что такое случайный обход?
Что такое равнодействующий вектор? Что он говорит о паттернах линейных объектов? Что такое длина равнодействующего вектора? Как она связана с задачами равнодействующей силы в физике?
Что такое нормализованная длина равнодействующего вектора? Чем она отличается от длины равнодействующего вектора? Когда она используется? О чем говорит большая нормализованная длина равнодействующего вектора? В чем различие между круговой дисперсией и нормализованной длиной равнодействующего вектора?
Как мы можем модифицировать определение среднего направления, нормализованной длины равнодействующего вектора и круговой дисперсии в случае равнозначности взаимно противоположных направлений?
Опишите вычисление гамма-индекса и расскажите, что он нам сообщает о величине связности в нашей сети?
Что такое альфа-индекс, в чем его сходство с гамма-индексом и отличие от него. Приведите некоторые примеры того, как оба эти индекса могут быть использованы для не-дорожной сети.
Опишите в общем модель гравитации. Как на взаимодействие точечных объектов влияют расстояние между узлами и величина узлов. Приведите пример применения модели гравитации.
Опишите типы атрибутов, которые может потребоваться присвоить узлам и дугам между узлами в работе с задачами маршрутизации и аллокации.
![]()
Наложение покрытий
Процесс наложения требует сравнений как графики, так и атрибутов. Техника выполнения наложения может быть довольно сложной, особенно в отношении алгоритмов, связанных с выполнением векторного наложения. Последующие графические описания процесса наложения должны дать вам понимание того, как компьютер выполняет векторное наложение. Данная глава дает общее, на уровне идей, понимание вопроса, она не детализирует все возможные методы логического или математического комбинирования покрытий, но фокусируется на некоторых из них, которые должно быть не трудно понять.
При возможности, вы можете опробовать различные методы на одном и том же наборе данных. Нет замены опыту, который даст вам понимание того, какой из методов наиболее пригоден для ваших задач. Опыт, приобретенный даже на простейшей ГИС, легко может быть распространен на более мощную систему. Время, затрачиваемое на освоение большой системы, может быть существенно сокращено, если вы уже знакомы с тем, как наложение выполняется, - вам потребуется только просмотреть страницы документации, относящиеся к слову "overlay" и определить, какие кнопки нажимать для запуска известных вам алгоритмов.
КАРТОГРАФИЧЕСКОЕ НАЛОЖЕНИЕ
К наиболее мощным возможностям современных ГИС относится их способность комбинировать картографическое представление тематической информации одной выбранной темы с другой. Этот процесс, называемый наложением (overlay), настолько интуитивно очевиден, что его применение за десятилетия предшествовало появлению современных компьютерных геоинформационных систем.
Давайте рассмотрим такой пример. Новичок начинает работать в ГИС с десятками тематических покрытий на территорию своего округа. Среди них - стоимость земли, зонирование, типы почв, землепользование, дороги, естественная растительность, больницы, противопожарные станции, школы и т.д. Узнав, как выполнять наложение, он хочет попробовать его в действии, и вот, просматривая покрытия, он обнаруживает почти полное пространственное совпадение наиболее дешевых земель с распределением старовозрастных дубовых лесов. Отсюда можно сделать вывод, что этот вид лесов создает почвы низкого качества, что, в свою очередь, обуславливает их низкую ценность. Хотя это может быть действительно так, на самом деле рассматриваемая корреляция может быть обусловлена совсем другими факторами.
И когда наш новичок создает наложение из покрытий стоимости земли и типов землепользования, он обнаруживает, что определенная категория землепользования, в данном случае - лесоводство, почти точно совпадает с областью старовозрастного леса. Не удивительно, что хотя эта земля имеет ценность для лесозаготовительной компании, ее стоимость гораздо ниже, чем стоимость земли в расположенных поблизости промышленных, торговых и жилых зонах.
В этих покрытиях можно найти и многие другие корреляции, например, между стоимостью земли и транспортной инфраструктурой, землепользованием и зонированием, между пересечениями дорог и расположением заправочных станций. Однако, следует помнить о рискованности выносить суждения о причинно-следственных связях на основе обнаружения только лишь визуальной корреляции. И поскольку карту очень легко принять за истинную картину реальности, тем более важно получить доказательства реального существования таких связей, прежде чем они будут использованы.
Теоретическая основа пространственной корреляции различных феноменов уже разработана для некоторых категорий картографических данных, но, конечно, не для всех. Например, Сойер [Sauer, 1925] создал модель взаимосвязи общих категорий данных о земле в своей работе по морфологии ландшафтов. Его исследование выявило существование значительной корреляции между человеческой активностью, формами ландшафта и другими физическими параметрами. Хотя он не формализовывал эти связи для применения на картах, очевидно, что он увидел связи между распределениями этих феноменов на земной поверхности. В дальнейшем исследователи формализовали эту разработку в виде широкого спектра подходов, названных, например, sieve mapping [Tyrwhitt, 1950; Hills et al., 1967].
Среди наиболее влиятельных разработчиков этого направления был Ян МакХарг (lan McHarg), работа которого, связанная с окружающей средой, породила целую школу мысли среди сегодняшних архитекторов ландшафтов, которая позволяет значительную часть работы выполнять при помощи компьютера, по сравнению с тем, что было возможно на основе полевых наблюдений и картографии одного покрытия [Simpson, 1989]. Он
использовал некомпьютерный метод наложения с использованием прозрачной пластиковой пленки [McHarg, 1971], на отдельных листах которой отображались параметры окружающей среды: чем темнее участок пленки, тем выше чувствительность среды.

уклон
Зона 1 свыше 10%.
Зона 2 менее 10% и более 2.5%.
Зона 3 менее 2.5%.
ПОВЕРХНОСТНЫЙ сток
Зона 1 Водные поверхности реки, озера,
водохранилища.
Зона 2 Каналы естественного стока и области ограниченного стока.
Зона 3 Отсутствие водной поверхности или выраженных каналов стока.
ПОЧВЕННЫЙ СТОК
Зона 1 Солончаки, болота и другие
низменности с плохим стоком.
Зона 2 Области с высоким уровнем грунтовых
вод.
Зона 3 Области с хорошим внутренним стоком.
ПОРОДЫ ОСНОВАНИЯ
Зона 1 Заболоченные территории, наименьшее
сопротивление сжатию.
Зона 2 Меловые отложения: пески, глины,
галечник, глинистый сланец.
Зона 3 Кристаллические породы: серпентинит
и диабаз.
ПОЧВЫ
Зона 1 Глина и суглинок, низкая стабильность
и низкое сопротивление сжатию.
Зона 2 Суглинки от мелкопссчаных до
крупнопесчаных.
Зона 3 Гравий или бурый суглинок и суглинок от гравийного до каменистого.
ПОДВЕРЖЕННОСТЬ ЭРОЗИИ
Зона 1 Все участки с уклоном более 10% с песчаной почвой.
Зона 2 Почвы из песка и гравия или бурого суглинка и области с уклоном более 2.5% на суглинке от гравийного до каменистого. Зона 3 Прочие области мелкоструктурной почвы и малого уклона.
Рисунок 12.1. Наложение пленок для определения чувствительности окружающей среды. Пример использования наложения пленок при ручном выполнении процесса наложения для демонстрации повышения чувствительности с ростом числа перекрывающихся категорий физических параметров.
При наложении листов с покрытиями друг на друга чувствительность по разным параметрам складывается. В результате создавалось новое, суммарное, покрытие, которое могло быть использовано для рассмотрения альтернатив и принятия решений (Рисунок 12.1) [Steinitz et al., 1976].
Мы далеко не всё еще знаем о причинных связях пространственных феноменов. Эта тема является значительной частью того, чем занимаются географы. Геоинформационные системы дают теперь возможность легко выполнять процедуры наложения, благодаря чему могут возникнуть новые гипотезы, теории и даже законы об этих корреляциях.
Многие специалисты из разных областей могут получить ценные сведения о пространственных корреляциях, которые ранее не наблюдались или даже не могли наблюдаться без применения компьютеров. По мере развития этого процесса мы будем получать все более детализированный набор правил о допустимости наложения покрытий и выводе утверждении о причинно-следственных связях. А пока нам следует быть внимательными, ибо современные ГИС позволяют использовать не один-единственный простой метод наложения, а десятки. Эти развитые возможности наложения легко могут привести к большому числу ошибок при сравнении не связанных покрытий и ошибочным выводам в результате.
Следует заметить, что это также усиливает нашу способность сознательно искажать информацию на картах, причем в существенно большей степени, чем до того, как ГИС стали использоваться для сравнения пространственных феноменов [Monmonier, 1991].
ТОЧКА В ПОЛИГОНЕ" И "ЛИНИЯ В ПОЛИГОНЕ"
Традиционно, как с использованием пленок, так и с применением компьютеров, наложение рассматривается как метод сравнения полигональных покрытий. Но существуют и другие типы наложений, использующие точечные и линейные данные. Рассмотрим пару примеров.
Допустим, некий детектив пытается обнаружить пространственную связь между некоторыми районами города и участившимися случаями уличного воровства. Он не имеет возможности сбора данных на месте, но должен полагаться на записи сотрудников полиции о подобных случаях за последние годы. Он может также взять записи по преступности из имеющихся архивов и отметить адреса этих инцидентов на карте города, где также имеются границы районов. Это значит, что, отмечая по адресу точки происшествий, он тем самым помещает их в полигоны, представляющие районы города. Вдобавок, он отображает на карте статистику преступности за каждый месяц. Этот утомительный процесс был бы намного проще, если бы данные уже были включены в некоторую ГИС.
Исследовав точечное распределение, он обнаруживает, что в районе Плезэнтфилд совершено гораздо больше уличных краж, чем где-либо еще. Это удивительно, ибо Плезэнтфилд - район не бедный, где можно было бы найти много нуждающихся в мелких суммах денег. Это также не богатый район, где жители могли бы носить с собой крупные суммы денег. Плезэнтфилд - район среднего класса, жители которого имеют средние доходы, скромные дома и семейные автомобили*. Возможно, в этом районе следует просто усилить полицейское патрулирование, но детектив не нашел еще главную причину повышенной концентрации здесь случаев уличного воровства.
Тогда он начинает рассматривать годовые данные помесячно и обнаруживает повышенное количество краж в декабре. Зная, что в этом месяце имеет место активная предрождественская торговля, он решает сравнить данные этих месяцев с остальными за несколько лет. Двигаясь год за годом назад, он обнаруживает сохранение тенденции вплоть до 1983 года, до которого случаи уличного воровства имели большую рассеянность по районам города в противоположность концентрации в Плезэнтфилде. Год же 1983-й является годом завершения строительства торгового центра в Плезэнтфилде. Уже теплее! Далее он рассматривает точечные отметки случаев уличных краж на более подробной карте района и обнаруживает, что эти точки концентрируются вдоль дорог с интенсивным движением к торговому центру и от него. Это показывает на повышенное значение некоторых линейных объектов (улиц) внутри полигонов (районов).
Наш детектив продемонстрировал сильную корреляцию между точечными и полигональными объектами, и мы видим, насколько полезным может быть сравнение между этими объектами. Он также установил определенную связь между данными в пределах одного покрытия. Анализируя карты, он обнаружил не только то, что в одном из полигонов оказалось больше точек, чем в других, но и то, что сами точки находились поблизости друг от друга (сгруппированное распределение) и от линейных объектов.
*
т.е. не персональные на каждого взрослого
члена семьи, что обычно для богатых
районов США — прим.
перев.
Тогда вы составляете набор карт с участием наиболее заметных линейных объектов городской среды — транспортных сетей. Вы составляете карту железных дорог, карту со старыми трамвайными линиями, карту со скоростными шоссе. После переноса этих карт на пленки вы накладываете их на карты архитектурных периодов, чтобы разглядеть возможные соответствия. К вашей радости, вы обнаруживаете, что через полигоны раннего периода роста проходят крупные железнодорожные линии, которые существовали в то время. Затем вы накладываете слой с трамвайными линиями и видите аналогичное сходство для второго периода роста. Наконец, после наложения пленки с шоссе вы опять обнаруживаете пример сильной пространственной корреляции между доминирующими транспортными сетями и расширением городской территории [Adams, 1970] (Рисунок 12.2).
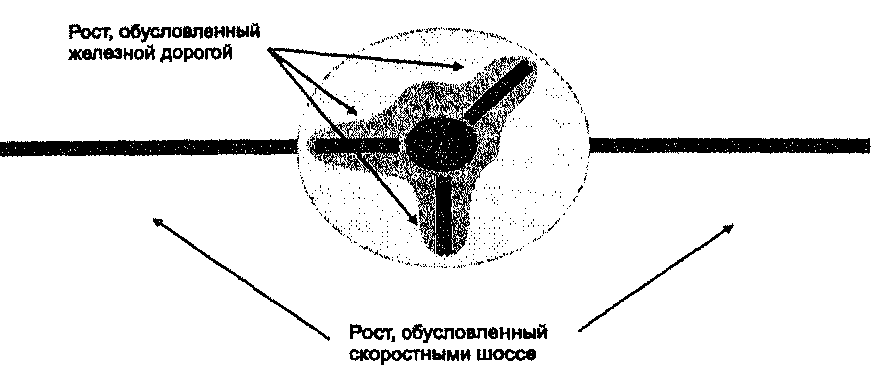
Рисунок 12.2. Линия в полигоне. Так могло бы выглядеть наложение "линия в полигоне", показывающее связь между полигонами расширения города и линиями доминирующих транспортных сетей.
Результаты наложения помогут доказать, что наблюдаемые сходства пространственных распределений демонстрируют действие некоторого реального причинно-следственного механизма. Однако, при выполнении работ без применения ГИС потребуется немало времени на составление карт и рассмотрение многих покрытий. Кроме того, если вы хотите рассмотреть вдобавок к упомянутым еще и другие показатели, для них вам также придется составлять и накладывать слои карты. Если же в вашем распоряжении имеется ГИС с большим числом тематических слоев, то вы могли бы легко выполнить наложение любого набора из этих показателей, чтобы рассмотреть другие гипотезы о картине пространственного изменения города. К тому же, если вы сможете доказать существование функциональной зависимости между наблюдаемыми паттернами, это знание могло бы использоваться при планировании управляемого роста города. Компьютеризация этих простых методов географического анализа приносит как концептуальные, так и практические плоды.
НАЛОЖЕНИЕ ПОЛИГОНОВ
Как уже упоминалось, исторически сложилось так, что сравнение полигональных покрытий является наиболее распространенным подходом к выполнению наложения, вследствие чего разработчики геоинформационных систем изначально развивали именно этот тип наложения. Поэтому существуют различные подходы к выполнению наложения полигонов, ориентированных на определенные потребности пользователей. Рассмотрим пример использования наложения полигонов.
Планировщик регионального уровня должен подготовить план контролируемого роста населения в сельской местности, которая должна подвергнуться интенсивной урбанизации в течение ближайших двадцати лет. При разработке плана рост может допускаться в тех областях, где имеются почвы, пригодные для строительства домов с фундаментами. При этом следует везде, где возможно, сохранять почвы высшего качества для ведения сельского хозяйства. Кроме того, следует предотвратить застройку земель, находящихся в собственности федерального правительства, земель, которые уже используются в качестве сельхозугодий, земель, на которых производятся археологические раскопки, а также земель, где находятся области обитания охраняемых видов животных. Следует также учесть, что нормативные акты позволяют местной администрации запрещать урбанизацию областей, предназначенных для других целей.
Рассмотрев эти требования, планировщик собирает карты с названными темами и готовит пленки, каждая из которых содержит затемненные участки, соответствующие запрету урбанизации по соответствующему тематическому критерию, и прозрачные участки, где данный критерий разрешает застройку. После наложения всех этих пленок друг на друга затемненными окажутся участки, на которых нельзя вести строительство, так как они находятся на почвах, не пригодных для домов с фундаментами, или их почвы имеют большой агрономический потенциал, или они используются для сельского хозяйства, или там ведутся археологические раскопки, или на них расположены места обитания охраняемых видов животных, или они
принадлежат федеральному правительству (Рисунок 12.3). Вы можете отметить, что все названные ограничения соединены союзом "или", выделенным жирным шрифтом, означающим в алгебре логики операцию "или" (дизъюнкцию), а в теории множеств - операцию объединения, в результате которой мы получаем покрытие, объединяющее все названные ограничения.
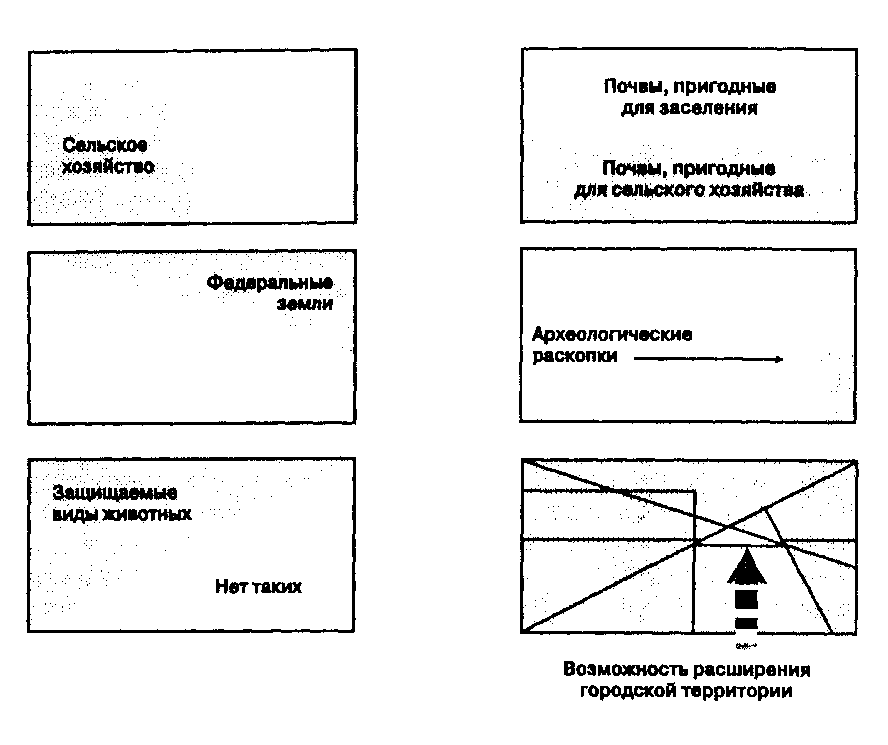
Рисунок 12.3. Наложение полигонов. После наложения затемненными будут те участки, на которых действует хотя бы одно из ограничений.
Этот же пример можно рассматривать как применение логической операции "и" или операции пересечения множеств (это должно быть для вас очевидным, если вы знаете законы Де Моргана). Здесь мы обращаем внимание уже на прозрачные участки пленок, соответствующие отсутствию ограничений (отмечено словом "не"). То есть, в результате наложения останется прозрачной та часть карты, на которой можно вести строительство, так как там находятся почвы, пригодные для домов с фундаментами, и они не имеют значительного агрономический потенциала, и они не используются
для сельского хозяйства, и они не содержат археологических раскопов, и на них не расположены места обитания охраняемых видов животных, и они не находятся в собственности федерального правительства.
В данном примере все показатели имели равные веса и поэтому могут быть названы исключающими переменными (exclusionary variables), т.е. каждый из них может запретить строительство. Но этот подход, хотя и распространен, все же ограничен бинарными данными шкалы. Реальность обычно более разнообразна.
Например, свойства почв по отношению к строительству домов, как правило, выражаются набором ранжированных классов, от строгого запрета - через умеренные ограничения - до отсутствия ограничений. Это дает планировщику дополнительную гибкость решения через возможность использования почв с умеренными ограничениями. В конце концов, если современные строительные технологии позволяют преодолевать прежде установленные ограничения, планировщики вполне могут рассматривать урбанизацию этих областей, если они не имеют ограничений по другим параметрам.
Мы можем изменить анализ, перейдя от бинарных показателей к более высоким шкалам измерений, назначая большей степени ограничения большее затемнение на пленке. Такой подход называется математическим наложением (mathematically based overlay). В данном примере мы могли бы, например, области с непригодными для строительства почвами полностью затемнить, участки с ограничениями разной степени сделать более или менее светлыми, а участки без ограничений оставить прозрачными. Аналогичным образом мы можем поступить с агрономическим потенциалом почвы. А в покрытии с археологически ценными участками мы могли бы создать многослойные буферы для каждого из них (см. Главу 9), в которых имеется переход от полного запрета строительства на самом участке и через разные степени ограничения - до полного отсутствия ограничений по данному параметру вне буфера. Это позволит, например, разрешить строительство отдельных коттеджей вблизи от этих участков, но не плотную застройку многоквартирными домами, которая будет возможна только вне буфера.
Хотя все это можно сделать вручную, занятие сие утомительно и требует много времени. Как мы скоро увидим, нужный эффект может быть легко получен как в растровых, так и в векторных ГИС.
Остается еще один вопрос - о степени влияния каждого фактора на принятие решения о застройке. Для этого каждому показателю присваивается вес, показывающий его важность по сравнению с другими показателями. Данная процедура легко реализуется тем же математическим наложением, при котором вычисляются значения весовой функции, представляющей собой сумму значений показателей, умноженных на соответствующие им весовые коэффициенты.
Сложение - не единственная математическая операция, которая может использоваться для комбинирования покрытий, могут также использоваться вычитание, умножение, деление, возведение в степень, выбор большего или меньшего значения, усреднение и другие операции. Понятно, что большинство из них требует применения компьютера. Кроме того, существует набор методов для комбинирования покрытий на основе математических операций над покрытиями, действующими как статистические поверхности. Мы их рассмотрим несколько позже.
Существует еще одна категория наложений, возможная без использования компьютера. Мы назовем их селективными (selective) в противоположность математическим. На самом деле, селективное наложение - не обязательно отдельная категория, а скорее объединение и расширение рассмотренных методов. Во многих случаях мы имеем набор правил, позволяющих нам решать, какие из факторов можно использовать для выполнения наложения. Этот подход, иногда называемый наложением с правилами комбинирования (rules-of-combination overlay) [Chrisman, 1995], позволяет нам использовать исключающую логику, взвешивание и математические операции одновременно. Набор таких правил может выглядеть как алгоритм с использованием конструкции "если-то-иначе". Наш последний пример мог бы использовать такие правила комбинирования:
если
(умеренные или нет ограничений на застройку по почвам) и (умеренные или нет ограничений по сельскому хозяйству) или (удаление от археологических площадок превышает 200 м)
то
установить минимальные значения покрытия
иначе
установить максимальные значения покрытия.
Чтобы построить такой алгоритм, наш планировщик должен заранее знать, каковы возможные комбинации условий.
Для этого было бы полезно свести в таблицу все возможные значения каждого показателя, а такая табуляция требует другой формы наложения, называемого идентифицирующим наложением (identity overlay), которое может выделять любые из этих значений и сохранять всю их описательную информацию. Поскольку идентифицирующее наложение обычно выполняется в рамках селективного наложения, я не выделяю его как отдельную категорию, хотя другие авторы находят достаточно аргументов для такого выделения. В любом случае, идентифицирующее наложение, как и селективное, слишком сложно для выполнения вручную. Поэтому сейчас мы вновь пройдемся по рассмотренным методам, но уже с точки зрения их компьютеризации и того, как она может расширить их возможности.
КОМПЬЮТЕРИЗАЦИЯ ПРОЦЕССА НАЛОЖЕНИЯ
Процесс наложения может быть очень сложным, практически невозможным при использовании традиционных карт. Различные веса параметров, сложные математические процедуры, правила комбинирования, — все они вносят вклад в усложнение процесса. Теперь мы посмотрим, как компьютер помогает реализовать все эти методы.
Растровые наложения "точка в полигоне" и "линия в полигоне"
В растровых ГИС ячейки растра, представляющих статистику преступности, места обитания птиц или любую другую точечную информацию, могут сравниваться с помощью присваивания этим точкам, как и полигонам, легко отличимых чисел или категорий; таким образом, становится сразу же очевидно, какие ячейки расположены в пределах интересующих нас полигонов. Например, у нас есть одно покрытие с одним полигоном, скажем, лугом, представленным числовым значением 1. Окружающий фон мог бы иметь значение 0 - "область не классифицирована". В другом покрытии ячейки со значением 1 представляют положения больших сорняков, остальные ячейки содержат значение 0. При наложении этих двух покрытий с помощью сложения мы получим ячейки со значением 2, представляющие сорняки на лугу (Рисунок 12.4).
Вы можете заметить, что мы использовали одно и то же число для полезной травы в первом покрытии и для сорняков — во втором. Это привело к тому, что в результирующем покрытии мы не можем различить ячейки луга без сорняков от ячеек сорняков, растущих вне луга. Если бы мы обозначили сорняки существенно большим числом, скажем, 10, то легко могли бы распознать все случаи; на результирующем покрытии число 10 обозначало бы сорняки на неклассифицированном фоне, а 11 - сорняки среди травы, что являлось результатом наложения "точка в полигоне". Конечно, если бы наша ГИС могла хранить дополнительные атрибутивные данные или поддерживала легенду, то мы могли бы идентифицировать эти точки корректно в любом случае. Хотя большинство ГИС имеют возможности обеспечения этих функций, следует помнить об этом простом примере, ибо любые математические операции, которые мы могли бы выполнить в дальнейшем над этим покрытием, могли бы создать нам серьезные
трудности.
Сохранять видимое разделение категорий
важно также и потому, что такая же
проблема встретится нам при растровом
наложении полигонов. Как
видите, в растре наложение "точка в
полигоне" не требует явной информации
о координатах как точек, так и полигонов.
В простейших системах нужно помнить о
различимости категорий после выполнения
наложения, в более сложных такое
различение может производиться по
меткам (таким, как "сорняки" +
"трава"). Системы, связанные с СУБД,
будут иметь записи атрибутов, показывающие
одновременное присутствие двух или
более различных атрибутов в одной ячейке
растра.
Как
видите, в растре наложение "точка в
полигоне" не требует явной информации
о координатах как точек, так и полигонов.
В простейших системах нужно помнить о
различимости категорий после выполнения
наложения, в более сложных такое
различение может производиться по
меткам (таким, как "сорняки" +
"трава"). Системы, связанные с СУБД,
будут иметь записи атрибутов, показывающие
одновременное присутствие двух или
более различных атрибутов в одной ячейке
растра.
Поскольку в растровой модели данных линии представляются цепочками прилежащих ячеек растра, которые сами по себе являются точками, становится очевидным, что операция наложения "линия в полигоне" по сути не отличается от операции "точка в полигоне".
Растровое наложение полигонов
Процесс растрового наложения полигонов по сути так же прост, как и наложение точек, поскольку в растре полигоны являются группами точек с одинаковыми наборами числовых значений. Растровым наложениям свойствен недостаток пространственной точности, но при этом они обладают высокой гибкостью и скоростью выполнения вследствие своей простоты. Общепризнанно, что в общем случае растровое наложение предпочтительно вследствие его вычислительной легкости [Burrough, 1983].
Поскольку каждая ячейка растра одного покрытия обязательно совмещена с такой же ячейкой в других покрытиях, компьютеру не приходится тратить ресурсы на вычисление координатных взаимоотношений объектов разных покрытий*. Вместо этого все ресурсы тратятся на сравнение атрибутивных данных, что, конечно, повышает скорость выполнения данной операции. Эти операции, чем-то похожие на матричную алгебру, обычно называют картографической алгеброй или алгеброй карт (map algebra) [Tomlin and Berry, 1979].
Простота растрового наложения дает также большую гибкость этой операции; мы легко можем выбирать из огромного числа возможных комбинаций логических, математических и условных операций над числовыми значениями ячеек растра. Мы уже рассматривали переклассификацию ячеек растра с помощью простых решающих правил, характеристик размера, формы и смежности, уклона и экспозиции склона, и многих других. Каждая из получаемых окрестностей является полигоном и легко может сравниваться с полигонами других покрытий с использованием все тех же перечисленных операций.
НАЛОЖЕНИЕ В ВЕКТОРНЫХ СИСТЕМАХ
Операции векторного наложения дают те же преимущества, что и основанная на векторах компьютерная картография — они создают картографические продукты, напоминающие традиционные, рисованные от руки карты гораздо больше, чем созданные из растровых карт. Это сходство напоминает нам о ручном наложении, так как карты, созданные в результате векторного наложения предлагают потенциальные решения некоторых графических проблем, связанных с ручным наложением. Даже простое наложения полигонов с помощью пленок ограничено использованием очень простых распределений и минимума категорий. Допустим, например, что у нас есть 15 факторов чувствительности окружающей среды, как в упоминавшемся проекте Яна МакХарга. Использование карт в градациях серого означает, что можно получить до 15 классов чувствительности окружающей среды. Хотя каждая из категорий может быть важна, наше зрение не способно различать более 8-10 категорий одновременно.
*
На самом деле это не всегда так: если
два покрытия имеют различное разрешение
или их ячейки смещены друг относительно
друга из-за различий в географической
привязке, то операция наложения потребует
некоторого способа совмещения,
установления соответствия между не
совпадающими ячейками растра. — прим.
перев.
Зная ценность и частоту реализации векторного наложения среди коммерческих ГИС, не будет излишним вопрос о том, является ли система, не способная создавать новые покрытия в результате векторного наложения (хотя и отображающая их на экране), действительно тем, что следует называть "ГИС". Этот вопрос не является чисто теоретическим, так как на самом деле любые ограничения векторного наложения уменьшают полезность системы для пользователя.
ТИПЫ НАЛОЖЕНИЙ
Наложение САПР
Первый и простейший метод компьютерного векторного наложения очень похож на традиционный метод в том, что мы просто располагаем символы отображения классифицированных данных на одной поверхности. Такие данные могут включать картограммы населения, распределения видов растений, землепользования, линейные символы для отображения дорожной сети, точечные символы, показывающие места археологических раскопок. Процесс графического наложения похож на метод тематического объединения, используемого для создания общегеографических карт. Такие карты позволяют пользователю видеть разнообразные факторы на одной графической основе и могут использоваться для графической демонстрации наличия или отсутствия пространственной связи между этими факторами. Для выполнения этой относительно простой операции в компьютере требуется, чтобы все отображаемые объекты находились в одной системе координат.
*
Колориметрия утверждает, что человеческий
глаз в норме способен различать более
ста градаций серого и порядка 300 ООО
цветовых оттенков. Указанные автором
ограничения часто обусловлены как
несовершенством и неправильной
настройкой оборудования, так, по-видимому,
и традицией использования четырехбитной
кодировки, дающей эти самые 15 градаций.
В общем случае важен вопрос надежного
различения,
для которого иногда приходится
ограничиваться всего лишь тремя-шестью
категориями. — прим.
перев.
Вопрос довольно важен, и даже опытные пользователи ГИС иногда в нем путаются. Давайте рассмотрим пример с использованием системы автоматизированного проектирования (САПР). Допустим, мы оцифровали карту дорог, создав два слоя: собственно дороги и гидрография.
Далее мы отобразили их на экране, чтобы определить, как проехать к некоторому озеру. Это вполне нам удается визуально, и мы сохраняем карту для других случаев. Позднее другой человек пытается использовать эту карту для поиска дорог, идущих вдоль береговой линии на расстоянии до ста метров от нее. Хотя визуально это довольно просто сделать, сама программа не сможет нам ответить на такой простой вопрос, так как она не знает, как названия дорог связаны с их графическими изображениями. У нее нет БД, а надписи являются такими же графическими элементами, помещаемыми рядом с объектами, как и сами эти объекты. Она не может также определять меру близости или наличие соединения. То есть, то, с чем мы здесь имеем дело, не является покрытием ГИС. В принципе, мы можем переслать эту карту в настоящую ГИС, построить топологию и БД с именами и атрибутами объектов, после чего получить ответ на наш вопрос. Усовершенствованная таким образом карта станет более чем графикой. Теперь это настоящее покрытие, пригодное для анализа.
Наложение САПР очень полезно в своих аналитических пределах. Не всегда нужно выполнять сложные в вычислительном отношении запросы для определения соседства или пространственного сходства между объектами. Это легко можно сделать визуально. Преимущества наложения данного типа - простота и быстрота выполнения. Многие системы управления инженерными сетями и промышленными объектами (AM/FM) действуют на такой же основе, и обеспечивают пользователей тем, что им нужно. То есть, они достаточно быстро создают карты нужных объектов, которые можно взять с собой на место работ, где графика может быть прочитана и интерпретирована вручную. Лишь когда сложность БД или запросов значительно возрастает, ручная интерпретация компьютерным образом выполненных карт становится проблемой. Например, у вас есть карта подземных газопроводов, наложенная на карту улиц (с названиями), наложенную в свою очередь на карту строений и на карту населения. Кто-то в этом районе сообщает о запахе газа. Вы смотрите на карту, чтобы понять, где может быть утечка, но линии всех этих карт расположены слишком плотно. Вы знаете, где расположены несколько задвижек, но их мелкие значки скрыты сложной объединенной картой. Здесь требуется операция наложения, которая может проследить несколько атрибутов объектов и подсветить нужные задвижки и здания. Все это можно сделать, имея достаточно времени. Может оказаться более легким использование отдельных карт на каждую из тем, чтобы символы не накладывались и не мешали. Короче говоря, в данной ситуации нужно нечто большее, чем то, что может дать простое наложение САПР.
Топологическое векторное наложение
Топологическая структура данных, представленная в Главе 4, позволяет программе отслеживать пространственные связи между объектами.
Она также определяет метод наложения полигональных покрытий, обеспечивающий передачу многих атрибутов объектов полигонам результирующего покрытия. Этот топологический результат, известный как наименьшая географическая единица (least common geographic unit (LCGU)) [Chrisman and Puecker, 1975], придуман для показа того, как изменения полигональных объектов могут достичь пункта, за которым невозможно дальнейшее деление. С этими наименьшими единицами деления связывается набор атрибутов, который также не может далее делиться на категории. По сути, это деление имитирует описанный выше метод МакХарга, когда упомянутый набор атрибутов определяет степень черноты области, соответствующей уровню чувствительности окружающей среды.
Далее мы увидим, как топология помогает проводить наложение векторных покрытий, рассмотрим несколько примеров, после чего сравним выполнение наложения в векторных и растровых системах.
Векторные наложения "точка в полигоне" и "линия в полигоне"
Хотя большинство векторных ГИС ориентированы на выполнение операции наложения полигонов, мы можем рассмотреть некоторые шаги по компьютеризации векторных наложений "точка в полигоне" и "линия в полигоне". При этом мы будем подразумевать, что покрытия имеют общую систему координат. Программа должна уметь определять положения точек или линий относительно границ полигонов, с которыми мы их сравниваем. Рисунок 12.5 иллюстрирует определение принадлежности точки с координатами (2.3, 3.45) изображенному полигону.
Такое наложение может выполняться с целью создания нового покрытия, состоящего только из тех полигонов, которые содержат указанные точки*.
*
Или другой вариант - только из тех точек,
что принадлежат указанным полигонам.
Говоря в общем, операция наложения
разнородных объектов несимметрична в
алгебраическом смысле. —
прим. перев.
Это ограничение является обычно следствием того, как система хранит связанную с графикой табличную информацию, впрочем, техническое объяснение не подходит для данного курса, и часто причины не так уж важны для пользователя. В качестве выхода из этой ситуации можно предложить создание очень маленьких буферов (выглядящих как точки на выходной карте), которые становятся крошечными полигонами. Это покрытие можно сохранить, и точки будут представляться его микрополигонами.
Наложение "линия в полигоне" заключается в соотнесении координат концевых и промежуточных точек линии с границей полигона с целью определения принадлежности этих точек полигону, то есть, по сути оно сводится к выполнению нескольких точечных наложений. Дополнительным моментом является то, что линия может пересекать границу полигона. В простейшем случае можно считать, что если хотя бы одна точка линии принадлежит полигону, то и вся линия принадлежит ему. Но более корректным подходом является определение точек пересечения линии с границей полигона и создание в них узлов, что позволит разделить атрибуты внутренних и внешних по отношению к полигону частей линии. Например, если лесозащитная полоса как линейный объект пересекает границу между пашней и лугом, мы сможем сказать, какая часть полосы принадлежит каждой из областей, а также создать таблицу, показывающую это отношение.
Как видите, векторные наложения "точка в полигоне" и "линия в полигоне" являются вопросом не только графического отношения объектов, но и отношения атрибутов. В конце концов, объекты карты представляют часть реального мира.
Векторное наложение полигонов
Для векторного наложения полигонов, подобно случаю "линия в полигоне", программа должна определить точки пересечения границ полигонов одного покрытия с границами полигонов другого покрытия.
Эти точки пересечения становятся узлами, и программа отслеживает передачу атрибутов в новое покрытие.
Поскольку многие векторные ГИС связаны с СУБД, не удивительно, что булева логика, используемая в запросах к БД, используется также и для пространственных запросов. На самом деле булево наложение (Boolean overlay) является широко распространенным подходом. Его легко понять, особенно если вы уже знакомы с операциями над множествами. Эти операции часто иллюстрируются так называемыми диаграммами Венна (Рисунок 12.7).
В случае булева векторного наложения мы сравниваем не сами атрибуты, а пространство, занимаемое каждым из двух наборов атрибутов. Допустим, у нас есть простое покрытие, имеющее только два типа полигонов землепользования — сельское и городское, плюс к этому другое покрытие, показывающее, находится ли земля в собственности или арендуется. И когда нам нужно найти находящиеся в собственности сельские участки, мы выполняем операцию наложения с пересечением, которая показывает только такие участки земли.
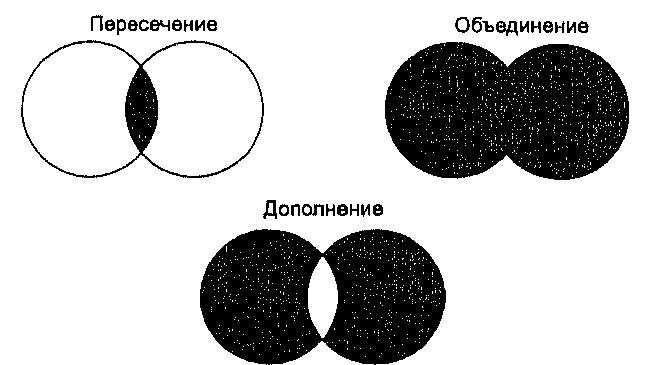
Рисунок 12.7. Булевы операции. Диаграммы Венна, показывающие пересечение, объединение и дополнение.
Программа геометрически определяет пересечения полигонов, после чего выбираются только те полигоны, которые удовлетворяют заданному критерию по атрибутам. Другими словами, выполнение операции пересечения над двумя покрытиями равносильно созданию диаграммы Венна для двух областей с однородными наборами атрибутов. В результате мы можем определить собственников сельских участков.
Если же мы выполним операцию наложения с объединением, то получим все элементы обоих множеств. То есть, используя те же покрытия, мы получим покрытие, состоящее из одной категории полигонов, которые представляют городские или сельские, или в собственности или арендуемые участки. То есть эта новая категория объединяет все названные категории, а соответствующее покрытие - площади обоих исходных (Рисунок 12.8).
Операция наложения больших покрытий может быть довольно долгой, поэтому прежде, чем прибегать к использованию наложения, следует подумать, нельзя ли выполнить ту же задачу более простыми средствами. В одних случаях может оказаться достаточным выполнить переклассификацию, в других можно упростить операцию наложения предварительной переклассификацией, например, чтобы не интересующие нас полигоны не удлиняли процедуру наложения. Этого можно достичь, уменьшив число классов полигонов. Помимо ускорения выполнения
наложения
это позволяет сделать результат
наложения более простым и контролируемым. В
заключение данной темы вернемся к идее
идентифицирующего наложения. В этом
случае мы можем получить результаты,
сходные с ранее приведенными примерами,
за исключением того, что при использовании
булевых операций для выполнения реального
картографического наложения мы помним
об атрибутах. Таким образом, получающиеся
в результате полигоны показывают
комбинации всех пересекающихся полигонов.
Другими словами, мы выполняем наложение
графических фигур и заносим в таблицу
все комбинации категорий. Так, например,
если у нас есть четыре различные
категории, пересекающиеся в пространстве
(скажем, землепользование, типы почвы,
сообщества животных и типы растительности),
то все они будут занесены в таблицу.
Следовательно, мы можем иметь полигон,
который содержит фруктовый сад
(землепользование), чернозём (тип почвы),
мыши-полевки (сообщество животных) и
орех-пекан (тип растительности). Имея
все эти тематические наборы данных и
зная соотношения между ними, мы легко
можем определить численность представителей
одной категории из других. Многие
операции наложения выполняются для
получения такой статистики.
В
заключение данной темы вернемся к идее
идентифицирующего наложения. В этом
случае мы можем получить результаты,
сходные с ранее приведенными примерами,
за исключением того, что при использовании
булевых операций для выполнения реального
картографического наложения мы помним
об атрибутах. Таким образом, получающиеся
в результате полигоны показывают
комбинации всех пересекающихся полигонов.
Другими словами, мы выполняем наложение
графических фигур и заносим в таблицу
все комбинации категорий. Так, например,
если у нас есть четыре различные
категории, пересекающиеся в пространстве
(скажем, землепользование, типы почвы,
сообщества животных и типы растительности),
то все они будут занесены в таблицу.
Следовательно, мы можем иметь полигон,
который содержит фруктовый сад
(землепользование), чернозём (тип почвы),
мыши-полевки (сообщество животных) и
орех-пекан (тип растительности). Имея
все эти тематические наборы данных и
зная соотношения между ними, мы легко
можем определить численность представителей
одной категории из других. Многие
операции наложения выполняются для
получения такой статистики.
Замечание об ошибках при наложении
Простые булевы и идентифицирующие наложения, созданные главным образом для данных номинальной шкалы, малопригодны для данных других шкал измерения. Нам же часто приходится иметь дело с числовыми данными, которые дают больше возможностей наложения, обеспечиваемых теми же математическими операциями, что и в алгебраическом растровом наложении. Любая полнофункциональная СУБД позволяет выполнять алгебраические действия над данными таблиц атрибутов, связанных с графикой карты. Благодаря этому процесс наложения даже более лёгок, чем в простейших растровых системах, и практически идентичен реализации в растровых системах, использующих СУБД.
Алгебраическое наложение в векторных системах выполняется во многом так же, как и в растровых, если не считать добавочные операции с векторными графическими фигурами. Это сходство окажется очень полезным, когда мы будем рассматривать картографическое моделирование в следующей главе. Но результаты наложения в растре и векторах могут выглядеть по-разному: в векторной системе могут неожиданно оказаться десятки и даже сотни мелких полигонов, особенно вдоль границ пересекающихся полигонов. Эти визуально незначительные расхождения могут существенно влиять на результаты анализа.
 В
качестве примера рассмотрим сравнение
двух равномасштабных покрытий
землепользования, созданных на основе
двух аэрофотоснимков одного участка
земной поверхности в моменты времени
Т1
и Т2.
При сравнении двух внешне одинаковых
покрытий оказывается, что они совпадают
не точно, что приводит к образованию
осколочных полигонов вдоль границ
накладываемых полигонов (Рисунок 12.9).
Перед нами встает вопрос: вызвано ли
это реальными изменениями в промежуток
между двумя моментами съемки или причина
кроется в погрешностях съемки и/или
оцифровки? Интуиция подсказывает, что
столь малые изменения землепользования
маловероятны, особенно учитывая то, что
сами полигоны выглядят столь похожими,
а даже небольшие изменения в самом
землепользовании дали бы гораздо более
значительные изменения картины.
В
качестве примера рассмотрим сравнение
двух равномасштабных покрытий
землепользования, созданных на основе
двух аэрофотоснимков одного участка
земной поверхности в моменты времени
Т1
и Т2.
При сравнении двух внешне одинаковых
покрытий оказывается, что они совпадают
не точно, что приводит к образованию
осколочных полигонов вдоль границ
накладываемых полигонов (Рисунок 12.9).
Перед нами встает вопрос: вызвано ли
это реальными изменениями в промежуток
между двумя моментами съемки или причина
кроется в погрешностях съемки и/или
оцифровки? Интуиция подсказывает, что
столь малые изменения землепользования
маловероятны, особенно учитывая то, что
сами полигоны выглядят столь похожими,
а даже небольшие изменения в самом
землепользовании дали бы гораздо более
значительные изменения картины.
Игнорируя микроскопические изменения в землепользовании, мы пытаемся разобраться в причинах несовпадения полигонов.
Сами полигоны могут быть одинаковой формы, но при этом чуть-чуть повернутыми. Мы можем попытаться устранить этот поворот, однако даже при самом тщательном исполнении редко удается достичь полного совпадения. К тому же, такой поворот зачастую может привести к рассогласованию других полигонов. Короче говоря, здесь нет простого решения, и некоторые пользователи даже прибегают к растровым ГИС, жертвуя точностью, чтобы избежать частых утомительных подгонок изображений.
Как вы можете догадаться, данная проблема обостряется, если мы пытаемся сравнивать разнородные покрытия. Например, наложение покрытий почв и растительности вообще не позволяет предполагать совпадение каких-либо двух полигонов. Целью наложения может быть именно обнаружение расхождений, и мы сталкиваемся с необходимостью отделения реальных различий полигонов от ошибок.
К сожалению, несмотря на продолжающиеся исследования по определению величины погрешности образуемых в результате наложения покрытий, есть очень мало общих принципов и еще меньше ответов на этот вопрос, особенно если покрытия приходят из разных источников [Chrisman, 1987]. Чаще всего вам придется полагаться на собственные опыт и интуицию. Ваши решения должны основываться на вашем собственном знании данных, их качества, качества их ввода и даже о полевой работе, давшей их. Ваши действия в значительной степени зависят от того, насколько точны должны быть результаты для решаемой задачи. Логично предположить, что если вы имеете несколько покрытий, то результат наложения будет иметь погрешность наихудшего из них, хотя на самом деле это не обязательно так, о чем тоже следует помнить. Если веса покрытий в наложении неодинаковы, то и вклады ошибок будут разными. Кроме того, значимость покрытий для целей анализа может быть различной даже при равном их участии в самом процессе наложения. Поэтому, перед выполнением наложения следует хорошенько изучить данные, чтобы понять, какая величина погрешности может быть приемлема.
Дасиметрическое картографирование
В завершение темы наложения следует рассмотреть один старый картографический метод детализации полигональной информации на основе других показателей.
Этот метод, называемый дасиметрическим картографированием (dasymetrtc mapping), основан на идее картограмм, рассмотренной в Главе 3, и позволяет понять некоторый подходы, уже использующиеся в ГИС, как и другие, которые еще не используются. Он может применяться к числовым данным, существующим в виде статистической поверхности. Первое документированное применение дасиметрического картографирования относится к улучшению классификации плотности населения с помощью так называемого очерчивания зон плотности (density zone outlining) [McCleary, 1969]. Этот метод, известный также как плотность частей, использовался для достижения большей детальности плотностей не входящих в выборку (unresampled) областей на основе более точного знания некоторых меньших подобластей, которые входили в выборку (resampled) [Wright, 1936]. Есть прекрасный пример использования плотности частей [Robinson et al., 1995], тесно связанный с оригинальным методом Райта 1936 года. Этот метод позволяет улучшить качество количественных данных полигонального покрытия посредством сравнения с более подробными данными другого покрытия.
Мы уже рассматривали один из методов дасиметрического картографирования, не обозначая его как такового: настоящая дасиметрия, впервые примененная Хаммондом [Hammond, 1964] в его работе о формах рельефа, включает очерчивание или классификацию областей геоморфологических типов на основе переклассификации топографических данных. Топографические поверхности прекрасно подходят для этого метода, который требует непрерывных распределений бесконечного числа точек. Рассматривая переклассификацию непрерывных поверхностей, мы создавали окрестности взаимной видимости, южных склонов, крутых склонов и других посредством группировки выбранных интервалов наших наборов данных. Это была измененная форма дасиметрического картографирования. Еще раз мы можем увидеть, что современные методы имеют корни в докомпьютерных временах.
Могут оказаться полезными несколько других форм дасиметрического картографирования; среди наиболее мощных - использование других регионов с предположением корреляции, со значительным вовлечением некоторой формы картографического наложения. Посмотрев на пример с плотностью частей, мы могли бы сказать, что это тоже сравнение показателей между картами, но подход с предположением корреляции существенно отличается. Вместо обособления участков области, для которых подробное исследование улучшает информационное содержание, и использования этой информации для улучшения наших знаний об остальном, здесь мы используем либо ограничивающие показатели, либо связанные показатели, содержащиеся в других покрытиях.
Мы использовали вариант дасиметрического картографирования с ограничивающими переменными (limiting variables) при обсуждении исключающих факторов в наложении. В качестве примера применения для улучшения качества полигональных данных и моделей, создаваемых на их основе, допустим, что мы имеем дело с картой численности населения штата Миннесота по округам. У нас есть также карта, содержащая в качестве полигональных атрибутов площади округов. Наложив два покрытия и поделив население на площадь, мы получим карту плотности населения для каждого округа штата. Однако, Миннесота - "страна десяти тысяч озер", что подразумевает наличие значительных площадей, на которых люди не живут, если только не в плавучих домах. Чтобы улучшить результат, мы должны для каждого округа "исключить" из покрытия площадей водную поверхность. Если бы мы не применили этот "ограничивающий показатель" для покрытия площадей округов и использовали результат для создания покрытия плотности населения, то плотность населения округов с крупными водоёмами оказалась бы меньше реальной.
Эти методы могут часто использоваться совместно с картографическим наложением для изоляции и отсева областей, вносящих систематические отклонения в количественные полигональные данные.
Наш последний пример дасиметрического картографирования, использующий связанные переменные (related variables), очень близок математическому наложению, как растровому, так и векторному. Показатели полигональных покрытий часто объединяются при помощи операций более сложных, чем простое исключение. Статистические подходы, такие как корреляция и регрессия, часто используются для демонстрации того, что географически рассеянные феномены связаны друг с другом, и того, как эти отношения позволяют нам предсказывать вариации одного в зависимости от изменений другого. Это верно и при использовании ГИС. Например, если мы знаем, что существует сильная корреляция между процентом пахотной земли и процентом уклона, то мы можем предсказать количество пахотной земли на основе этой корреляции. Имея такую информацию, мы можем создать подробное предсказательное покрытие процента пахотной земли на основе одного только уклона. И наоборот, имея покрытия существующих процентов пахотной земли и уклона, через картографическое наложение мы могли бы создать покрытие, показывающее реальное отношение между этими двумя показателями в определенной области. Потом мы могли бы наложить это покрытие на покрытие предсказываемого процента пашни и визуально обнаружить расхождения, численные значения которого можно использовать для оценки предсказательной модели. Далее области расхождений могут сравниваться с другими покрытиями для выработки гипотез о причинах расхождения. Это прекрасный пример того, как ГИС могут использоваться для выработки гипотез в научных применениях ГИС, или создания предсказательных геоинформационных моделей для принятия решений в коммерческих приложениях ГИС.
Дасиметрическое картографирование имеет большой потенциал улучшения использования ГИС как в академической, так и в коммерческой среде. Но этот вопрос всё ещё недостаточно освещен в литературе по ГИС. В растровых ГИС легко могут выполняться многие формы дасиметрического картографирования, а некоторые его методы используются каждый день даже без осведомленности пользователей об этом. Векторные ГИС также реализуют многие, если не все, подобные методы, но очень не многие пытались оценить их потенциал серьезным, систематическим образом [Gerth, 1993]. Осведомленность о дасиметрии как о потенциальном наборе методов картографического наложения, скорее всего, приведет к значительному усовершенствованию доступных сегодня пользователям инструментов наложения в ГИС.
НЕСКОЛЬКО ПОСЛЕДНИХ ЗАМЕЧАНИЙ О НАЛОЖЕНИИ
Вследствие визуальной привлекательности и интуитивной природы картографического наложения этот набор методов часто считается тем, что собственно и есть ГИС. Такое понимание ограничивает число потенциальных пользователей ГИС и может даже привести к снижению продаж коммерческих продуктов. Вдобавок, это мешает многим пользователям в их освоении других эффективных методов, уже имеющихся в ГИС. Вам следует помнить, что, несмотря на силу картографического наложения, есть множество альтернативных методов решения геоинформационных задач. Наложение часто оказывается гораздо более полезным при объединении с другими методами пространственного анализа, нежели при использовании его в одиночку. В следующей главе мы займемся комплексными картографическими моделями, которые потребуют выбора адекватных методов и объединения их рациональным образом для получения полезных результатов.
Постоянно помните о том, что никакая ГИС не сможет сама решить, являются ли используемые вами покрытия функционально связанными. Прежде чем слепо налагать покрытия, выясните, какие пространственные факторы могут быть связанными и почему. Можно даже сделать выборку и проверить гипотезу для обоснования вашего решения.
Часто оказывается полезным статистический подход с использованием интегрированных единиц местности (integrated terrain units (ITUs)) [Dangermond, 1976]. Во многом подобно физико-биологическим единицам картографирования, они отражают положение о том, что все данные интегрированы наземной поверхности, и что используемые методы, такие как расшифровка аэрофотоснимков, требуют извлечения этих взаимодействующих показателей из одного источника информации. Это гарантирует, что используемые вами показатели связаны пространственно, а возможно и логически. Если вы не имеете возможности использования интегрированных единиц местности и не можете найти логическое, или, по меньшей мере, статистическое основание, которое указывало бы на связь между вашими показателями, то, возможно, вам следует пересмотреть способ решения вашей задачи. Так же проводится и проверка соответствия между спутниковыми ДДЗ и объектами на земной поверхности, которые они должны представлять.
Вопросы
Каковы некоторые очевидные ограничения выполняемого вручную наложения? Какие преимущества дает компьютеризация этого процесса?
Каковы преимущества растрового наложения перед векторным? Каковы недостатки?
Почему наложение является одной из наиболее развитых операций в большинстве современных коммерческих ГИС?
Приведите пример возможного использования наложений "точка в полигоне" и "линия в полигоне" из ваших собственных исследований.
Каковы ограничения наложения типа САПР? Приведите пример того, как такое наложение может сделать невозможным дальнейший анализ результата.
Что такое дасиметрическое картографирование? Как оно может применяться в векторных ГИС? Как - в растровых?
В чем отличия связанных переменных и ограничивающих переменных в дасиметрическом картографировании? Приведите примеры использования тех и других.
Какие проблемы могут возникнуть при сравнении нескольких векторной покрытий? Есть ли подходы к их решению? Что можно сделать перед наложением, чтобы ослабить их?
Приведите примеры того, как элементы дасиметрического картографирования могут быть применены в существующих растровых или векторных ГИС. Почему до сих пор так мало внимания уделяется использованию дасиметрического картографирования в наложении?
Картографическое
моделирование![]()
![]()
В нашем рассмотрении подсистемы анализа мы двигались шаг за шагом среди разных возможностей моделирования, имеющихся в современных ГИС. Принятая здесь классификация достаточно проста, но не всякая книга по ГИС следует той же схеме, как и не всякий поставщик геоинформационных систем. Некоторые даже не предпринимают попыток к такой классификации; одни дают немало подробностей, другие - лишь общее описание. Но какую бы систему вы ни использовали, и какую бы книгу ни читали, вы обнаружите, что большинство подходов легко сопоставимы с теми, что описаны здесь. Не следует слишком много внимания уделять тому, как именно методы называются, или тому, как они сгруппированы. Функции большинства команд очевидны из их имён.
По мере развития вашего знакомства с ГИС вы быстро обнаружите ограничения использования лишь небольшого подмножества методов для решения более сложных задач. На последующих страницах мы рассмотрим подсистему анализа как упорядоченный набор взаимодействующих операций с картами, которые, совместно, могут использоваться для выполнения очень сложных задач моделирования. Ключ — в том, чтобы увидеть эти сложные модели состоящими из более мелких и простых компонентов. Отдельные компоненты могут реализовываться относительно небольшим числом аналитических операций. Затем они могут объединяться с другими для образования более крупных модулей, дальнейшее объединение которых позволит сконструировать всю модель. Как и любая сложная система, пространственная модель почти всегда может быть разбита на составляющие части.
Данная глава подчеркивает значение блок-схем для моделирования. Хотя их выполнение может казаться скучным, оно требует от вас тщательного обдумывания номенклатуры покрытий и элементов данных, которые нужны для выполнения анализа. Оно помогает выявлять недостающие покрытия или многократно используемые покрытия еще до завершения модели. По моему мнению, построение блок-схем картографических моделей должно быть обязательным предварительным шагом. Оно позволит точно определить цели работы и спецификации конечного продукта.
Исследуйте модели и блок-схемы, приведенные в книге, сравните их с их описаниями. При тщательном рассмотрении вы наверняка найдете пути улучшения подходов или усовершенствования моделей. Рассматриваемые модели не следует считать ни полными, ни единственными решениями предложенных задач, более того, вам стоит подумать об альтернативных путях их решения и соответствующих блок-схемах для каждой. Ваш вариант может оказаться более легким для реализации или более точным по отношению к тому, что моделируется. Практика очень важна как для умения составлять блок-схемы, так и для моделирования.
КАРТОГРАФИЧЕСКАЯ МОДЕЛЬ
Термин "картографическое моделирование" (cartographic modeling) [CD. Tomlin and J.K. Berry, 1979] обозначает процесс использования комбинаций команд для ответов на вопросы о пространственных феноменах. Более формально, картографическая модель - это набор взаимодействующих, упорядоченных операций с картами, которые используют как "сырые", так и обработанные данные для моделирования процесса принятия решений о пространственных объектах [Tomlin, 1990]. Рассмотрим это определение подробнее.
Первое условие определения говорит о том, что картографические операции должны взаимодействовать друг с другом. Каждая операция над покрытием должна иметь результат (обычно другое покрытие), который может использоваться следующей операцией.
Допустим, что у вас есть карта типов ландшафта изучаемой области, и вы хотите узнать, имеется ли достаточно большое непрерывное природное пастбище в собственности государства, чтобы ходатайствовать о разрешении выпаса на таковом вашего крупного рогатого скота. Вашей первой операцией является переклассификация покрытия для создания нового покрытия под названием "землепользование" с целью выделения типов землепользования, связанных с типами ландшафта (переклассификация всех луговых полигонов либо как пастбищ, либо как природных лугов). Вы также создаете покрытие под названием "чей_лут", показывающее пастбища, находящиеся в собственности государства, и пастбища в частном владении. Это может потребовать еще одной переклассификации, хотя вы могли сделать эту работу во время первой переклассификации. Следующей операцией будет еще одна переклассификация, создающая покрытие "бол__гос", выделяющее государственные природные пастбища непрерывной площадью не менее 25 га. Эта переклассификация потребует агрегирования ячеек растра для обособления полигонов площадью 25 га и больше (Рисунок 13.1), и вам нужно будет объединить эту операцию с функцией, выделяющей непрерывные полигоны.
Таким образом, вы действуете либо с первоначальными данными, т.е. с исходной картой типов ландшафта, либо с покрытиями, полученными после первой и последующих операций, как с покрытием "бол_гос". Вы также можете видеть, как каждый шаг добавляет данным информационное наполнение посредством установления контекста, с которым они связаны.

|
1 |
0 |
0 |
1 |
0 |
0 |
0 |
2 |
3 |
2 |
2 |
1 |
1 |
1 |
1 |
2 |
|
1 |
1 |
0 |
1 |
0 |
0 |
2 |
2 |
2 |
2 |
2 |
2 |
1 |
1 |
2 |
2 |
|
1 |
1 |
1 |
1 |
1 |
0 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
1 |
2 |
2 |
|
1 |
1 |
1 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
2 |
2 |
1 |
1 |
2 |
0 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
0 |
0 |
1 |
1 |
3 |
|
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
2 |
2 |
0 |
0 |
0 |
0 |
3 |
3 |
|
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
3 |
3 |
0 |
0 |
3 |
3 |
0 |
|
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
3 |
3 |
3 |
3 |
0 |
3 |
0 |
0 |
|
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
3 |
3 |
0 |
0 |
2 |
2 |
2 |
|
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
2 |
2 |
2 |
2 |
2 |
2 |
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
|
0 |
0 |
0 |
0 |
0 |
0 |
3 |
3 |
3 |
3 |
2 |
2 |
2 |
2 |
2 |
0 |
|
1 |
1 |
0 |
0 |
0 |
3 |
3 |
3 |
2 |
2 |
2 |
2 |
2 |
2 |
0 |
0 |
|
1 |
1 |
1 |
0 |
3 |
3 |
3 |
3 |
2 |
2 |
2 |
2 |
2 |
0 |
0 |
0 |
|
1 |
1 |
1 |
1 |
3 |
3 |
3 |
2 |
2 |
2 |
2 |
2 |
0 |
0 |
0 |
0 |
|
1 |
1 |
1 |
1 |
1 |
1 |
3 |
2 |
2 |
2 |
2 |
0 |
0 |
0 |
0 |
0 |
Исходные значения, представляющие различные типы природных пастбищ. Каждая ячейка представляет 1 га земли
Новые значения, представляющие ранжирование непрерывных участков пастбищ в зависимости от размера: 0=менее 25 га, 1-28 га, 2=41 га, 3=42 га, 4= 44 га.
Рисунок 13.1. Переклассификация областей по размеру. Агрегирование ячеек растра для выделения полигонов площадью 25 га или более.
Наше первоначальное покрытие "землепользование" было не очень специфично. Оно относилось ко всем возможным типам ландшафта в изучаемой области, безотносительно к возможным вопросам. После обработки мы создали покрытие "с добавленной стоимостью" (value-added), с конкретными атрибутами, которые могут сказать, содержит ли это покрытие государственные пастбища достаточной площади.
Мы подходим к последней части рассматриваемого определения. Наши действия с исходными и промежуточными данными направлены на моделирование процесса принятия решения о том, содержит ли рассматриваемое покрытие достаточно большие пастбища в собственности государства. Отрицательный ответ ведет к новым поискам, положительный - к процедуре получения разрешения на выпас скота. Положительный ответ
Картографическое
моделирование
означает, что нужная площадь имеется. Но если вы захотите расширить свое стадо, то вам снова потребуется рассмотреть покрытие "бол_гос". Ранжирование полигонов этого покрытия приведет вас к определению комбинаций, которые позволят вам расширить стадо. Эти шаги добавляют информацию к каждому из предьщущих покрытий инкрементным образом.
Теперь давайте подумаем о том, какие подсистемы ГИС мы использовали в этой простой модели решения. Первый шаг - ввод покрытия "тип_ландшафта" с помощью подсистемы ввода. Далее следуют сохранение карты и устранение ошибок. После окончания проверки мы должны произвести выборку карты для анализа, обращаясь к подсистеме хранения и редактирования. Последующая переклассификация покрытия задействует подсистему анализа.
Результат переклассификации сохраняется как картографическое покрытие, что также является использованием подсистемы хранения и редактирования, а также подсистемы вывода, хотя выходная карта и не печаталась на бумаге. Затем, для решения вашей задачи, вы произвели выборку нового покрытия для продолжения анализа. И в любой момент вы могли бы при желании просмотреть карту.
Очевидно, что описанный процесс не является линейным - мы не шли от ввода через хранение и выборку к выводу, как в картографии с применением компьютеров. Вместо этого мы шли от ввода через сохранение, выборку, анализ, снова сохранение, и вывод нашего первого промежуточного покрытия. Далее мы снова шли через выборку, вывод (отображение на экране), анализ с созданием второго промежуточного покрытия, и т.д. Короче говоря, процесс картографического моделирования является цикличным, а не линейным (Рисунок 13.2). Цикличная природа картографического моделирования дает наибольшую гибкость в переходе от одной подсистемы к другой при преобразованиях данных, необходимых для создания конечного пространственно-информационного продукта.
МОДЕЛИ В ГЕОГРАФИИ
Перед началом подробного рассмотрения картографического моделирования важно обратиться к корням идеи географического моделирования, которая привела, в конечном счете, к созданию ГИС. Пространственные модели много лет были оплотом географических исследований и приложений, задолго до числовой революции 1950-х и 60-х годов. Карта сама является моделью реальности, позволяющей нам оценивать одним взглядом пространственные отношения между различными факторами. С развитием количественных описаний, исходная парадигма сообщения начала заменяться аналитической парадигмой. Тем
не
менее, карта как средство представления
долго служила в качестве средства
формулирования гипотез. Исследование
наблюдаемых паттернов и порождающих
их процессов использовалось для
объяснения, например, отношений между
сельскохозяйственной деятельностью и
транспортными расходами. Наиболее
известная из этих моделей, разработанная
Хайнрихом фон Туненом (Heinrich
von
Thunen)
в 1910 году, теперь называется моделью
изолированного состояния (isolated
state
model)
[Isard,
1956]. Она описывает площадные распределения
сельскохозяйственной деятельности как
последовательность концентрических
кругов, расходящихся от центрального
рынка. Модификации этой модели, включающие
доступность транспортных маршрутов,
наличие нескольких рынков, стоимость
земли, качество почвы, издержки
производства и рыночные цены, всё ещё
используются сегодня для предсказания
жизненности определенных видов
сельскохозяйственной деятельности.
Примерно в то же время Альфред Вебер
(Alfred
Weber)
разрабатывал другой набор географических
моделей [Weber,
1909]. Созданные первоначально для
предсказания пространственных
распределений точечных объектов
промышленности, модели Вебера были
модифицированы для поиска оптимальных
местоположений объектов торговли и
услуг. Эти модели, известные сегодня
как модели
размещения и назначения (location-allocation
models),
составляют часто применяемый набор
методов ГИС, имеющихся во многих
коммерческих системах.
Исследование
наблюдаемых паттернов и порождающих
их процессов использовалось для
объяснения, например, отношений между
сельскохозяйственной деятельностью и
транспортными расходами. Наиболее
известная из этих моделей, разработанная
Хайнрихом фон Туненом (Heinrich
von
Thunen)
в 1910 году, теперь называется моделью
изолированного состояния (isolated
state
model)
[Isard,
1956]. Она описывает площадные распределения
сельскохозяйственной деятельности как
последовательность концентрических
кругов, расходящихся от центрального
рынка. Модификации этой модели, включающие
доступность транспортных маршрутов,
наличие нескольких рынков, стоимость
земли, качество почвы, издержки
производства и рыночные цены, всё ещё
используются сегодня для предсказания
жизненности определенных видов
сельскохозяйственной деятельности.
Примерно в то же время Альфред Вебер
(Alfred
Weber)
разрабатывал другой набор географических
моделей [Weber,
1909]. Созданные первоначально для
предсказания пространственных
распределений точечных объектов
промышленности, модели Вебера были
модифицированы для поиска оптимальных
местоположений объектов торговли и
услуг. Эти модели, известные сегодня
как модели
размещения и назначения (location-allocation
models),
составляют часто применяемый набор
методов ГИС, имеющихся во многих
коммерческих системах.
Хотя эти модели сложны в реализации, по своей сути они просты. Они разрабатываются для минимизации пути от точки обслуживания до ее клиентов. Возьмем в качестве примера приписывание учеников к школам
(определение зон обслуживания). Скажем, маленький городок имеет две школы примерно одной вместимости, расположенные на противоположных его концах. Нужно определить, кому из школьников в какую школу ездить. Здесь требуется не просто разделить школьников поровну, но и выбрать для каждого ближайшую из школ.
Задача меняется, если существует только одна школа и нужно определить место для новой школы, которая должна быть размещена с учетом минимума общего расстояния от нее до большинства учеников, которые будут ее посещать. Обычно это делается итеративно: школа помещается на некотором гипотетическом месте, затем подсчитывается число приписанных учеников и вычисляются расстояния, а результаты рассматриваются для определения степени удовлетворения каждого местоположения установленному критерию. Процесс продолжается до тех пор, пока не будет найден наилучший ответ. Математическая сложность задачи чаще всего приводит к приближенному решению даже при использовании современной вычислительной техники. Многие из сегодняшних ГИС имеют возможность поиска такого приближенного решения.
В предыдущем примере мы подразумевали, что ученики будут посещать именно назначенную школу. Однако в сфере торговли и обслуживания клиентура свободна в выборе, её нужно привлекать. Решение стать постоянным клиентом является отчасти функцией расстояния, но могут действовать и другие факторы. В этом случае для определения оптимальной точки обслуживания могут использоваться модели гравитации (gravity models), где притяжение обратно пропорционально функциональному расстоянию (см. Главу 8) от потенциальной точки обслуживания [Abler et al., 1971].
В отличие от физики, где сила притяжения убывает обратно пропорционально квадрату расстояния, здесь мы имеем дело со взаимодействием людей и служб, причем люди принимают решения на основе функционального расстояния и желают быть постоянными клиентами, причем взаимодействия эти осуществляются на двухмерной поверхности. Сюда еще следует добавить возможную конкуренцию со стороны близлежащих аналогичных служб. Модели гравитации широко используются в теории экономического размещения (economic location theory) и прочно заняли свое место в коммерческих ГИС.
Несколько других географических моделей также нашли свое место в ГИС, другие же еще ждут своего часа. Одни разрабатывались для исследования изменений плотности населения в городах [cf. Casetti, 1969]; другие показали, что сами города действуют как региональные иерархии, проявляя различную силу притяжения к региональной торговле [Christaller, 1966; Brush, 1953]; третьи создавались для планирования транспортных сетей в зависимости от скоростей, типов дорог и других факторов; четвертые рассматривали распространение идей в пространстве [Hagerstrand, 1967] -такие модели распространения новшеств (innovation diffusion models) сейчас широко используются среди экологов для отслеживания движения растений и животных по географическим пространствам.
Возможно, среди наиболее сложных пространственных моделей находятся те, что недавно разработаны экологами ландшафтов для исследования отношений между структурой и функцией больших частей биосферы [Forman and Godron, 1987]. Параметры, рассматриваемые в них, включают размер области, связность ландшафта, разнообразие участков, их взаимодействие и форма. Эти ученые полагают, что структура ландшафта напрямую связана с его функциональными возможностями и общим качеством окружающей среды. Корни многих из этих методов прямо или косвенно находятся в географии, а их использование сегодня показывает растущую потребность исследования пространственных отношений; немало этих методов реализовано как в коммерческих, так и в свободно распространяемых (public domain) ГИС [Baker and Cai, 1992; McGarigal and Marks, 1994].
Можно упомянуть гораздо больше моделей, но нашей целью является не представление подробного их списка, а иллюстрация того, что многие решения уже разработаны, проверены и реализованы. Небольшое библиографическое исследование вопроса перед началом моделирования часто может сохранить вам многие часы и позволит избежать разочарования. С другой стороны, ваши собственные решения сложных задач могут пригодиться следующему поколению специалистов по картографическому моделированию, которые, возможно, смогут использовать их в своих приложениях.
ТИПЫ КАРТОГРАФИЧЕСКИХ МОДЕЛЕЙ
Есть сильное сходство между разделением статистических методов на описательные (descriptive) и аналитические (inferential) и классификацией основных типов картографических моделей. Томлин [Tomlin, 1990] подобным же образом делит последние на соответственно описательные и предписательные.
Описательные картографические модели (descriptive models) описывают и, при некоторых обстоятельствах, объясняют некоторые распределения и взаимосвязи, полученные в результате анализа. Простейшие описательные модели просто иллюстрируют существующую ситуацию обособлением некоторых феноменов и показом результатов в форме, позволяющей пользователю одним взглядом охватить эти феномены и их взаимосвязи. Это не намного отличается от парадигмы сообщения в картографии, собственно, тем, что описательные (атрибутивные) данные хранятся в компьютерной БД. Несмотря на свою простоту, модели этого типа всё еще широко используются, так как они предлагают достаточно простой путь получения легко узнаваемых представлений пространственных объектов и явлений. Часто встречаются жалобы опытных ГИС-профессионалов, выполняющих работу для неподготовленных в геоинформатике специалистов на то, что новые пользователи никогда не выполняют моделирование. Вместо этого они просят: "сделайте мне карты того-то и того-то", что, конечно, можно было бы сделать в рамках системы компьютеризованной картографии или даже САПР. Все же, не стоит отчаиваться, а лучше отнестись к этому как к отправной точке для более сложных моделей, которые могут быть предложены пользователю.
Вполне естественно от чистого описания перейти к моделям, которые предсказывают, как имеющиеся условия могут воздействовать на расположение промышленных объектов, на изменение со временем естественной растительности, описывают результаты перекрытия плотиной реки (показывая области затопления выше плотины и защищаемые от наводнений области ниже ее), показывают области потенциального роста города на основе знаний о прежнем росте и обнаружения пространственных феноменов, способных играть прогностическую роль.
Последний случай следует рассмотреть подробнее, так как он указывает на предсказательный потенциал описательных картографических моделей. Предсказательные модели (predictive models) позволяют пользователю определить, какие факторы важны в функционировании области исследования, и как эти факторы связаны друг с другом пространственно. Конечно, предсказания на основе таких связей могут быть очень ненадежными. Они требуют, чтобы факторы имели ясную и подтверждаемую причинную связь. Как мы видели в Главе 12, пространственная ассоциация различных картографических показателей не диктует сама по себе причинно-следственные отношения, а только указывает на пространственное совпадение. Знание моделируемой среды важно в прогностическом картографическом моделировании, также как и в аналитической статистике, например, в регрессионном анализе.
Предсказательное моделирование чаще всего ассоциируется со вторым главным типом моделирования, определенным Томлин [Tomlin, 1990], предписательным моделированием. Однако, как мы скоро увидим, не существует четкого разделения между описательными и предписательными моделями (prescriptive models). Если представить себе весь спектр картографического моделирования, то предсказательные модели находятся ближе к предписательным, чем к описательным. Возьмем следующий пример предсказания, основанный на чисто описательной методике моделирования.
Допустим, владелец очень большого ранчо желает оценить потенциал выносливости своей территории с точки зрения выпаса скота на лугах и пригодности для обитания представителей естественных видов, таких как перепел. Эта модель требует создания БД со всеми типами растительности на территории ранчо. Кроме того, требуется знание наземной биомассы лугов, местоположения больших участков ядовитых для скота растений и значительных скоплений кустарников, необходимых перепелам для укрытия и питания. С учетом этих показателей, создаваемая модель покажет области обитания, необходимые для поддержания приемлемой популяции перепелов. Она также будет включать покрытие, показывающее нагрузку со стороны скота. Эта модель является описательной в том смысле, что она показывает, где владелец ранчо мог бы разместить свой скот, и где могли бы также выжить перепела. Теперь он может выгнать скот на соответствующие участки, ограничив движение скота в области обитания перепелов с помощью ограждений и других средств.
Предположим, однако, что владелец ранчо хочет не просто успешного выпаса скота, но выпаса только на лучших с этой точки зрения землях, чтобы животные набирали вес наиболее быстро. Такая обработка базы данных вполне может быть названа предсказательной, так как она, по сути, предсказывает, Что области с наибольшей производительностью дадут наиболее эффективное использование земли для выпаса. Эта модель лишь немного сложнее исходной, но она несет элемент предписания, так как она "предписывает" наилучшее использование земли.
Предписывание может также показать пользователю модели то, как анализ описательной информации может улучшить ситуацию в целом. Например, некоторые лучшие пастбища могут содержать множество кустарников, что делает их также и наилучшей средой обитания для перепелов. Хозяин ранчо может решить насадить (или пересадить) кустарники в области, меньше подходящие для пастьбы, удаляя при этом ядовитые растения, если таковые есть, на наиболее производительных землях.
ГИС может быть использована для "предписания" наилучших мест для высадки кустарника, а также мест работ с ядовитыми растениями. Таким образом, ГИС теперь используется для предложения действий с имеющейся территорией с целью обеспечения наилучшего решения исходной задачи. Различие между этой в высокой степени предписательной моделью и сценарием размещения школы в том, что первая требует гораздо больше предсказательных способностей, нежели второй. Это наиболее развитая форма предсказательной модели, так как пользователь должен определить взаимодействие многих факторов во времени, и требуется гораздо большая степень предсказательности.
Вы, наверное, заметили, что все эти модели требуют прежде всего описания имеющихся условий. То есть, разрабатывая предписательные модели, вы вначале описываете, а затем предписываете. Нет особой нужды задерживаться на терминологии, если вы помните, что деление картографических моделей на описательные и предписательные является, как и многие другие классификации, произвольным. Если вы помните, что движение от одного типа к другому является плавным переходом от чистого описания без каких-либо действий к большей предсказательной мощности и растущей предписательной активности, то у вас не должно быть проблем с пониманием данного вопроса.
В любом случае, природа и сложность задачи будут диктовать тип применяемой модели, независимо от того, как вы ее назовете.
ИНДУКТИВНОЕ И ДЕДУКТИВНОЕ МОДЕЛИРОВАНИЕ
С какими бы моделями вы ни работали, описательными или предписательными, есть два метода формулирования моделей. Они включают в себя те же логические подходы, что используются в любом научном исследовании. Первый, называемый индуктивным методом, основан на движении от конкретных элементов к общему утверждению.
В этом случае эмпирические пространственные данные исследуются путем проб и ошибок. Различные покрытия сравниваются и проверяются на соответствие с элементами других покрытий для выявления сходных пространственных распределений или ассоциаций, которые могли бы указать на происходящий в области исследования процесс. Пример индуктивного метода не из области ГИС: допустим, вы отправились в бакалейную лавку, чтобы приобрести чего-нибудь для приготовления обеда. Вы делаете множество покупок, выбирая каждую потому, что она вам нравится или потому, что выдумаете, что неплохо было бы иметь это сегодня. Вернувшись домой, вы обнаруживаете, что, хотя все приобретенное съедобно, вам трудно преобразовать это в нечто похожее на обед. Вы купили достаточно пищи, чтобы заполнить меню, но вы собираетесь приготовить блюда, которые не включают некоторые из приобретенных товаров. Эти вещи оказались ненужным непосредственно в данный момент, хотя они и могут пригодиться в дальнейшем.
Как показывает приведенный пример, метод проб и ошибок может использоваться для внесения порядка в набор элементов, полученных без тщательного планирования. То же самое можно сказать и о существующих БД ГИС. Если имеется достаточно подходящих показателей, и если есть корреляции между показателями различных покрытий, то вполне возможно создание моделей, которые будут полезны для принятия некоторых решений.
Возможно, вы обнаружите, что покрытия, на создание которых вы потратили сотни часов, так и не использованы. Многие подобные проекты внесли свой вклад в научные исследования, однако из-за недостаточного проектирования такой подход к картографическому моделированию оказывается неэффективным для многих коммерческих приложений. В то время как наука пытается только лишь исследовать данные, приложения реальной жизни часто гораздо более определенны в своих целях и поэтому должны продумываться скорее дедуктивным образом.
По сравнению с индуктивными, дедуктивные модели движутся в противоположном направлении.
То есть, вы начинаете с конкретного рецепта или формулировки, относящейся к вполне определенным вопросам. В случае с приобретением продуктов, вы выбираете блюдо, которое будете готовить, определяете необходимые ингредиенты и покупаете только их. Затем вы их объединяете, так что у вас не остается ненужных компонентов. Преимущества дедуктивного подхода очевидны, - вам не приходится тратить время и деньги на создание ненужных покрытий, благодаря чему вы можете сконцентрироваться на подготовке только действительно нужных данных.
СОСТАВЛЕНИЕ БЛОК-СХЕМ МОДЕЛЕЙ
Какой бы подход вы ни использовали — дедуктивный или индуктивный - очень полезной методикой, помогающей сформулировать модель и определить нужные покрытия, является составление блок-схемы (flowchart) модели. Оно требует обособления каждого элемента (покрытия), который должен использоваться в вашей модели. Каждое покрытие должно иметь конкретную, уникальную тему, представляющую один фактор или группу факторов в вашей модели.
Блок-схема позволяет определить, имеете ли вы все необходимые покрытия, а также проверить единственность каждого покрытия. Если есть некоторые избыточные покрытия, представляющие уже имеющиеся темы, то вы сможете сократить их и уменьшить общее время ввода.
На Рисунке 13.3 изображена блок-схема простой дедуктивной картографической модели, цель которой - определить наилучшее место для горного домика. Задача исследования вполне ясна, и по меньшей мере четыре аспекта должны учитываться при принятии решения. Начнем с инфраструктуры. Нам нужно знать о наличии электричества, газа, водопровода, канализации, дорог для подъезда и других удобств. Далее идут административно-правовые факторы. Нужно узнать, не подана ли другая заявка на отведение этого участка земли, и не принадлежит ли он кому-нибудь, и если да, то можно ли его приобрести. Наверняка вам понадобится
Рисунок 13.3. Блок-схема простой картографической модели горного домика.
Показаны элементы модели и промежуточные покрытия для выработки окончательного решения.
разрешение на строительство, так как этот участок может оказаться в зоне, где запрещено строительство жилья. Если участок оказывается в сейсмически активной области, то возможны ограничения на конструкцию и методы строительства. Пожароопасные зоны требуют применения огнестойких материалов. Обе эти группы факторов влияют как на выбор места, так и на стоимость строительства.
Третья группа факторов, включенных в картографическую модель -эстетические. В конце концов, вы, скорее всего, строите горный домик для отдыха от города, поэтому наверняка не хотите видеть город из окна (но при этом быть в разумном удалении, чтобы иметь возможность ездить в город на машине). Кроме того, нужен открытый вид гор и, возможно, определенная ориентация, чтобы вы могли наблюдать закат с террасы.
Четвертая группа факторов выбора места это физические факторы. Требуется уклон не более заданной величины, чтобы не пришлось предпринимать дорогие меры против сползания дома по склону. Чтобы снизить стоимость строительства, следует выбрать место с низкой плотностью деревьев, лучше всего опушку леса. Инженерные характеристики почвы также должны оцениваться, ибо нельзя располагать дом на нестабильной почве, особенно с большим содержанием глины, которая сильно меняет свои свойства в зависимости от влажности. Предполагая возможное отсутствие канализации, вам может потребоваться создание канализационного отстойника, для чего следует внести в расчеты инфильтрационные параметры почвы.
Теперь перейдем к реальной модели, тщательно рассматривая выбор покрытий для представления отдельных факторов. Мы можем начать с инфраструктуры. Для первого фактора - доступности водопровода - нам нужно покрытие ("водопровод"), показывающее все муниципальные линии водоснабжения в рассматриваемой области, которое создается в результате оцифровки соответствующей бумажной карты. Аналогично создаются покрытия с линиями электропередачи ("электричество"), газоснабжения ("газоснабжение") и проезжими дорогами ("дороги").
Далее, мы переходим к административно-правовым факторам. Во-первых, с кадастровых карт (показывающих принадлежность земли) мы создаем покрытие "собственность". Оно позволит выявить свободные участки или тех, к кому обращаться за приобретением земли.
Затем мы берем карту зонирования и создаем покрытие "зонирование", чтобы определить области, доступные для строительства коттеджей на одну семью. Нужно также знать места, представляющие опасность из-за землетрясений и пожаров. Вполне вероятно, что такие данные будут получены из других источников, например, от национальной геологической службы. Так мы создадим покрытие "сейсмичность". Карты угрозы пожаров, из которых будет создано покрытие "пожароопасность", можно получить в лесохозяйственной организации. Хотя последние два покрытия можно отнести к физическим факторам, они могут быть связаны с административными ограничениями, поэтому и отнесены к дан ному-разделу.
Оценка эстетических качеств потребует карты близлежащих застроенных территорий ("поселения"). Топографические карты ("топография") дают информацию о высотах, которые могут загораживать вид с потенциального места. Карты типа леса обычно не включают информацию о высоте деревьев, так что вам придется создавать собственную карту лесного покрытия ("растительность"), либо по результатам измерений на наиболее подходящих местах, либо через использование аэрофотосъемки.
Последнюю группу составляют физические параметры. Величину уклона можно узнать из уже имеющегося покрытия "топография". Хотя уклон является самостоятельным фактором, он может быть получен из имеющихся данных. Таким образом мы не нарушаем правило выбора уникальных элементов. Другой элемент физических параметров, который может быть получен из имеющегося покрытия, показывает области с редкой лесной растительностью или с растительностью, содержащей подходящее чистое место (опушки, поляны). Имеющееся покрытие "растительность" поможет нам получить данную информацию.
Два параметра почв также могут быть получены из одного покрытия ("почвы"). Любая подробная карта почв обычно содержит как инженерные характеристики, так и параметры инфильтрации; и те и другие будут либо явно закодированы как отдельные карты, либо они будут связаны базой данных друг с другом и с областями различных типов почв. Методы отслеживания различных свойств почв будут сильно зависеть от используемой ГИС. В частности, мы могли бы просто оцифровать полигоны и сохранить бумажную копию отчета об исследовании почв, из которого мы получили информацию о почвенных участках. Такие отчеты об исследованиях связывают разнообразные параметры почв с каждым из участков (Таблица 13.1).
Проработка модели
Посмотрите внимательно на блок-схему модели размещения горного домика: все нужные покрытия и элементы включены, и они "втекают" в конечную точку модели.
Однако кое-чего не хватает. Как из начальных данных создавались промежуточные покрытия? Чтобы завершить нашу блок-схему, нам нужно указать, какие функциональные возможности ГИС мы используем для перехода от одной ветви к другой. Этот шаг важен не только в моделировании, он поможет в определении функциональности, требуемой от любого программного ГИС-пакета для данного проекта. Давайте рассмотрим дополненную таким образом версию блок-схемы (Рисунок 13.4).
Вместо реальных названий команд, которые могут различаться от системы к системе, здесь использованы общие мнемоники, которым вы сможете сопоставить реальные команды вашей системы. Начнем с инфраструктуры - дорог, электро-, газо- и водоснабжения. Весьма вероятно, что ничего из перечисленного не окажется на вашем участке. Но нужно знать, как близко они находятся (скажем, до 500 м), чтобы было возможным сделать ответвление в вашу сторону. Нетрудно создать буферы (команда BUFFER) шириной 500 м с каждой стороны соответствующих линий, и в результате мы получим покрытие "есть-электричество", которое показывает места, в которых есть или может быть получен доступ к электроэнергии. Аналогично строятся покрытия "есть-газ" и "есть-вода" (буферы по 250 м). Для буфера "есть-проезд" можно взять большее значение, скажем, 750 м, так как у нас есть автомобиль повышенной проходимости, позволяющий пробраться на такое расстояние и по бездорожью.
Теперь у нас есть четыре отдельных покрытия, представляющие факторы инфраструктуры. Поскольку нам нужны все эти элементы, а не один или два, то для получения результирующего покрытия "инфраструктура" нужно наложить их так, чтобы получить пересечения всех представленных на них областей. Для этого используется наложение "логическое и" (команда INTERSECT), в результате которого мы получаем области, удовлетворяющие всем четырем критериям.
Сейчас вполне закономерен вопрос: "Что делать, если ни одна область не удовлетворяет всем четырем критериям?". Такая ситуация вполне возможна. В этом случае стоит обратить внимание на фактор, наиболее удаленный от остальных. Например, если линии электропередачи расположены слишком далеко, то мы могли бы увеличить размер буфера для этого фактора (скажем, до 1000 м). Таким образом, мы ослабляем ограничения, чтобы получить решение для нашей модели, что является достаточно распространенной практикой в картографическом моделировании. Мы думаем таким же образом, когда решаем купить машину, которую можем себе позволить, а не роскошную модель, которую хотели бы.
Если ослабление ограничений невозможно, - например, если электроэнергетическая компания не желает тянуть кабель на 1000 м от существующих сооружений, - то вам может помочь снижение важности одного или более факторов.
Создавая буферы, мы исходили из равной важности значения всех

Продолжение Таблицы 13.1
|
Местные дороги и улицы |
аналиэационный отстойник Поля орошения |
Области земляных канализацион- ныX отстойников |
Спортплощадки |
|
Сильно: замерзание |
Умеренно: наводнения |
Умеренно: инфильтрация |
Умеренно: наводнения |
|
Слабо |
Сильно: мелкие камни |
Сильно: инфильтрация, мелкиекамни |
Сильно: мелкие камни |
|
Сильно: замерзание |
Слабо |
Умеренно: инфильтрация |
Слабо |
|
Сильно: наводнения, замерзание, низкая прочность |
Сильно: наводнения, влажность |
Сильно: наводнения, влажность |
Умеренно: наводнения |
|
Сильно: изменение объема, низкая прочность |
Сильно: просачивание |
Слабо |
Сильно: влажность |
|
Сильно :низкая прочность, изменение объема |
Сильно: просачивание |
Умеренно: уклон |
Умеренно: глинистость, просачивание |
|
Умеренно: изменение объема |
Сильно; просачивание |
Умеренно; уклон |
Умеренно : просачивание |
|
Умеренно: изменение объема |
Сильно: просачивание |
Сильно:уклон |
Сильно: уклон |
|
Сильно: изменение объема |
Сильно: глубина до камней, просачивание |
Сильно : глубина до камней |
Умеренно: просачивание, глинистость, глубина до камней |
|
Сильно: изменение объема |
Сильно: просачивание |
Умеренно: уклон |
Умеренно: просачивание |
|
Сильно: изменение объема, низкая прочность |
Сильно: просачивание |
Умеренно: уклон |
Умеренно: просачивание |
|
Сильно: глубина до камней, уклон |
Сильно: глубина до камней, уклон |
Сильно : глубина до камней, уклон |
Сильно : глубина до камней, уклон |
|
Слабо |
Слабо |
Сильно : инфильтрация |
Сильно:уклон |
|
Умеренно: глубина до камней |
Сильно: глубина до камней |
Сильно: глубина до камней |
Сильно: глубина до камней |
|
Сильно: влажность, наводнения, изменение объема |
Сильно: просачивание, наводнения, влажность |
Сильно: наводнения, влажность |
Сильно: влажность, наводнения, просачивание |
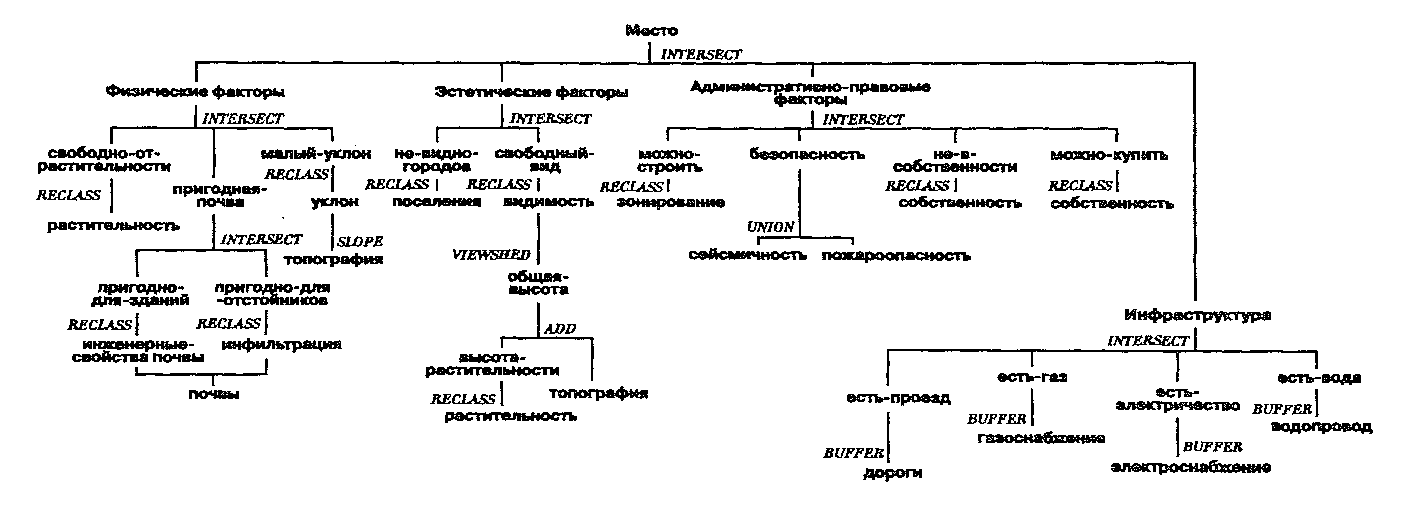
Рисунок 13.4. Детализированная блок-схема картографической модели горного домика. Эта блок-схема показывает также и операции, необходимые для перехода от каждого исходного или промежуточного покрытия к следующему для получения решения на выходе модели.
факторов, что случается довольно редко. Иначе говоря, нам следует взвесить факторы инфраструктуры. Дороги должны сохранить высокую значимость, так как, даже если вы собираетесь вести жизнь отшельника, вам нужно иметь возможность ездить за продуктами, медицинской помощью и т.д. Газ, конечно, нужен для обогрева дома и приготовления пищи, но можно воспользоваться газовыми баллонами. Аналогично можно поступить с водой. Электроэнергия остается проблемой номер один. Но в конце концов, можно снизить требования и пожертвовать телевизором, или использовать приборы на аккумуляторах. То есть, веса некоторых факторов можно свести к нулю.
Учтя ограничения подмодели инфраструктуры, мы можем перейти к административно-правовым факторам. Области, в которых допускается строительство односемейных домов, могут быть получены переклассификацией зонального покрытия, при которой устраняются все области, не удовлетворяющие этому ограничению. Аналогично может быть создано покрытие с территорией, не имеющей зарегистрированного собственника ("не-в-собственности") и еще одно - с землевладениями, которые могут быть проданы ("можно-купить"). Оба промежуточных покрытия основаны на одном и том же исходном ("собственность"), и оба создаются переклассификацией (команда RECLASS), Остаются еще сейсмо-и пожароопасность. Опасные зоны могут быть объединены операцией "или" (команда UNION), а результирующее покрытие покажет области, не подверженные опасности пожаров или землетрясений.
Полученные четыре промежуточных покрытия объединяются в общее административно-правовое покрытие операцией наложения с пересечением. При этом нужно следить за тем, чтобы пересечению подвергались лишь пригодные области. Если в пересечение войдут противоположные категории, например, сейсмо- и пожароопасные, то вы можете оказаться в весьма рискованной ситуации.
Третья подмодель, эстетические факторы, имеет меньше компонентов, чем другие, но их труднее исчислить. Начнем с покрытия населенных пунктов. Вряд ли вам удастся полностью избежать близости населенных пунктов, к тому же, вам наверняка понадобится какое-то поселение неподалеку в качестве источника припасов. Разумно ограничить размер поселений, скажем, численностью в 1000 человек. Посредством переклассификации вы можете создать покрытие ("нет-городов"), содержащее только небольшие поселки, без крупных городов. Однако, это не совсем то, что нужно, так как вам нужно знать, где находятся большие города, чтобы определить, видимы ли они с возможного места для домика. Это покрытие будет скомбинировано со следующим для исключения таких объектов из области видимости.
Вторая часть эстетической подмодели определяет возможности обзора.
На местности есть растительность которая добавляет свою высоту к высоте поверхности земли. Работая с картами, мы часто забываем, что растительность это отнюдь не плоская покрашенная зеленью поверхность. Чтобы учесть это, нам нужно ввести в модель среднюю высоту леса, которая может быть получена из ботанических или лесоводческих справочников для каждого из типов леса. Тогда мы сможем переклассифицировать покрытие "растительность" (номинальная шкала) в покрытие "высота-растительности" (шкала отношений). Данные этого покрытия и значения топографической высоты (тоже шкала отношений) можно сложить (команда ADD) для образования покрытия "общая-высота", которое нужно для определения зон видимости (команда VIEWSHED), после чего мы получим покрытие "свободный-вид", показывающее области видимости долины внизу. Теперь нужно учесть города. Комбинируя через пересечение это покрытие и покрытие "города" (свыше 1000 жителей), мы получим как видимые области с городами, так и видимые области без городов. Эти последние и будут объединены, в конечном счете, с тремя остальными подмоделями.
Завершая модель, мы обращаемся к трем физическим факторам: растительности, почвам и уклону. Из рассматривавшегося уже покрытия "растительность" мы можем путем переклассификации выделить области густого леса (которые нам не подходят) и такие, которые содержат другую растительность или редкие деревья и могут быть расчищены ("свободно-от-растительности"). Нужно помнить, конечно, что масштаб большинства карт растительности довольно мал, так что любое решение на основе таких данных должно проверяться на месте.
Среди наиболее сильных физических ограничений - величина уклона. Слишком большая крутизна либо сделает выполнение проекта невозможным, либо значительно увеличит его стоимость. Величина уклона до 15 градусов была бы идеальна. Чтобы найти все области, удовлетворяющие данному критерию, нужно взять топографическое покрытие и выполнить процедуру построения окрестностей, разделяющую области с уклоном до 15 градусов и области с большим уклоном, получив таким образом покрытие "малый-уклон".
Инженерные характеристики почвы определяют способность почвы выдерживать такое строение, как горный домик, и способность к инфильтрации, необходимая для сооружения канализационного отстойника.
Оба этих параметра определяются непосредственно по исходной почвенной карте; они либо переклассифицируются для удовлетворения заданным критериям, либо выбираются из связанной таблицы атрибутов. Полученные покрытия ("пригодно-для-зданий" и " пригодно-дляотстойников") могут быть подвергнуты пересечению для создания более полного покрытия "пригодная-почва". В результате операции наложения с пересечением мы получаем конечное покрытие подмодели "Физические факторы".
Как вы могли уже догадаться, окончательное решение состоит в пересечении покрытий с физическими, эстетическими, административно-правовыми и инфраструктурными факторами, так как все их ограничения должны быть удовлетворены. Если модель работает, как запланировано, то мы должны получить хотя бы один участок, подходящий по всем критериям.
В действительности не всё так просто. Мы рассмотрели проблему слишком сильных ограничений, которые приходится ослаблять. Но возможна и другая ситуация, - когда на многих участках почвы хороши для строительства, уклоны малы, прекрасные горные виды, нет проблем с зонированием и земельной собственностью, инфраструктура прекрасно развита. Это выглядит маловероятным, но все-таки возможно. В этом случае мы получили большие площади, удовлетворяющие нашим требованиям, и можем строить домик практически где угодно. То есть, эти замечательные результаты показывают, что наша модель оказалась не очень-то полезной в принятии решения. Конечно, ГИС в этом не виновата, она не может заменить человека, принимающего решения.
В такой ситуации мы можем усилить ограничения, чтобы выбрать наилучшее место из возможных. Как и в случае ослабления ограничений, здесь мы можем идти двумя путями. Первый - изменение критериев. Например, мы могли бы потребовать наилучших почв для строительства дома и канализационного отстойника. Мы можем также ограничить уклон величиной 7 градусов, а не 15, уменьшить допустимый размер поселений, попадающих в зону видимости, изменить другие факторы. На самом деле, легче создать набор значений для каждого фактора, и получить ранжированные ответы вместо просто "да" и "нет" (см. Главу 9).
Другой подход основан на том, что четыре группы факторов нашей модели не равнозначны. Ограничения по почве или уклону весьма существенны, однако, если нет зон, в которых возможно строительство, то физические параметры просто не имеют никакого значения. То есть, есть факторы, которые можно назвать абсолютными ограничениями, в то время как другие могут быть преодолены изменением пределов или согласием вложить в проект больше денег.
Определение того, какие факторы абсолютны, а какие могут быть взвешены, поможет выполняющему картографическое моделирование скорректировать решение в реальной ситуации. Нужно проявлять гибкость и внимание к воздействию этих весов на конечный результат. В литературе можно найти примеры использования взвешивания для улучшения модели и удовлетворения требований пользователей-максималистов (Davis, 1981; DeMers, 1986; Lucky and DeMers, 1987].
Разрешение конфликтов
Взвешивание не всегда дает результаты, удовлетворяющие всем выбранным условиям. Рассмотрим задачу создания картографической модели, включающей два по сути противоречащих друг другу взгляда на проблему, - скажем, лесозаготовка и сохранение пятнистых сов, защищаемых федеральным законом.
Как мы могли бы подойти к такой трудной задаче? Давайте рассмотрим один из имеющихся методов, предложенный Д. Томлин [Tomlin and Johnston, 1988]. Хотя этот метод - не единственный, он показывает, что конкурирующие части задачи могут быть концептуально разделены, и достигнут приемлемый компромисс, без использования редкого программного обеспечения или дорого оплачиваемых переговорных групп. Этот метод, называемый ORPHEUS, состоит в создании двух раздельных моделей - каждой для своей стороны задачи. После оценки всех факторов вы начинаете изменять веса факторов с обеих сторон, давая небольшие уступки каждой стороне. Продолжая изменять веса на двухсторонней основе, вы должны, в конце концов, получить на выходных картах области сосуществования конкурирующих групп требований. Процесс требует некоторого времени для совершенствования, и опыт здесь незаменим. Попробуйте сами создать небольшую БД, скажем на площадь 1 кв.км, включающую данные по почвам со связанными таблицами. Затем выберите 6-8 типов землепользования для размещения в этой области, задав ограничения размера для одних типов, местоположений для других, близость к очагам загрязнения для третьих и т.д. Даже если вы не получите сразу положительных результатов, этот опыт будет очень полезен.
Примеры картографических моделей
Теперь давайте рассмотрим три типичных примера моделей и их блок-схем. Это примеры на разные темы, которые используют разные подходы как к моделированию, так и к составлению блок-схем, что даст вам представление о некоторых из имеющихся возможностей.
Начнем с описательной модели качества среды обитания оленей (Рисунок 13.5) [Carlson and Fleet, 1986]. Она основана на наличии/отсутствии некоторых факторов, существенно важных для выживания оленей: доступности питьевой воды, растительности для пастьбы и укрытия. Первый фактор использует покрытие с данными по гидрологии, второй - по
растительности. Олени употребляют в пищу древесные растения, которые имеют листья близко к земле. Таким образом, факторы пищи и укрытия получаются переклассификацией растительности на кустарники и деревья как пригодные и травы как непригодные типы растительности. Модель не уточняет, какие именно типы растительности нужны, и какая именно вода может употребляться, - нетрудно представить, как эти параметры можно получить из имеющихся покрытий при наличии знаний по зоологии и поведению оленей.
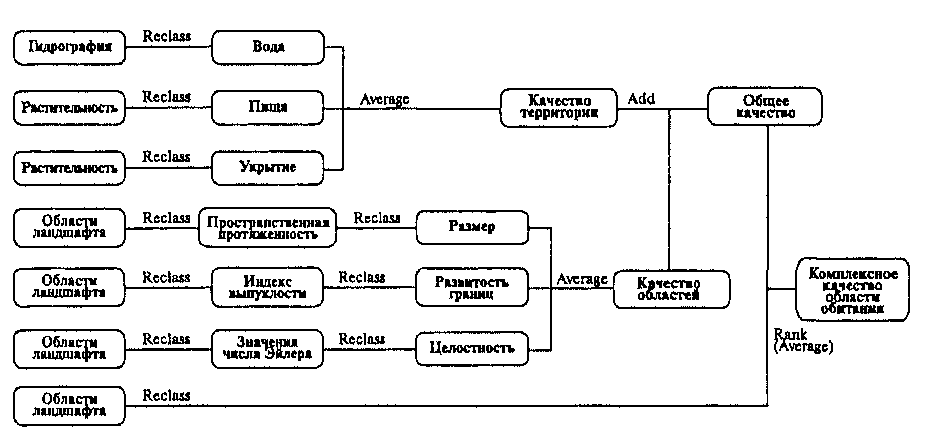
Рисунок 13.5. Блок-схема простой модели области обитания оленей. Основана на наличии/отсутствии важнейших факторов выживания: укрытия, пищи и воды и пространственной конфигурации ландшафта с учетом размера, длины границ и целостности/фрагментации ландшафта.
Вторая часть модели относится к качеству среды обитания с точки зрения пространственной конфигурации элементов ландшафта. Основные параметры здесь - размер и длина границ каждой области, а также ее целостность (см. Рисунки 8.2 и 8.3)..Эта часть должна напомнить вам об использовании в картографическом моделировании упоминавшихся экологических единиц ландшафта. Кроме того, это хороший пример ландшафтных пространственных показателей в их применении к области обитания одного вида. Конечный результат этой части модели объединяет параметры ландшафта с помощью ранжирования, в данном случае через усреднение, для получения общего качества области обитания. Должно быть очевидным, как части модели могут быть объединены для получения всей модели области обитания оленей.
Второй пример показывает предписательную модель определения областей, которые получают достаточно ветровой энергии для
Картографическое
моделирование
функционирования ветроэлектрогенератора (Рисунок 13.6) [Carlson and Fleet, 1986]. Используются только два исходных покрытия: топография и растительность. Первое позволяет определить ориентацию склонов, которой присваиваются порядковые категории от лучшей к худшей (с точки зрения работы генератора). Наилучшим случаем будет, конечно, горизонтальная поверхность как не создающая препятствий, в случае же уклона оптимальным является северо-западное направление, связанное с преобладающим направлением ветра, другие направления менее полезны*.
Найти направление уклона нет уклона = 1 (наилучший) С-3 = 2 (хороший) С,3 = 3 (удовлетворительный) Ю, Ю-3 = 4 (плохой) другие = 4 (не пригодный)
Найти расстояние до препятствий d
Найти высоту препятствий h
Операции
Ориентация
Radiate
Переклассифицировать (Топография + Растительность)
Найти высоты генераторов: r=(h-h')/d, таким образом, h' = h-rd выбрать корректное г найти гd найти /V
Вычесть, Переклассифицировать
Умножить
Вычесть
Устранить влияние высоты вышек
Отобразить все ранжированные места независимо от высот вышек
Отобразить места как функцию f(аспект, высота_вышки)
Вычесть
Переклассифицировать, Отобразить
Табулировать, Переклассифицировать, Отобразить
*
На самом деле, плоская поверхность -
не всегда самый лучший случай, так как
Другим фактором, который мы должны рассмотреть, является расстояние до препятствий, в данном случае деревьев и склонов, которое может быть получено использованием операции определения функционального расстояния; в данном примере используется команда "Radiate". Модель подразумевает, что вышки будут не выше 25 метров, через вычитание этой величины из топографических высот и ранжирование местоположений уже независимо от высот вышек. Наконец, модель перекомбинирует экспозиции склонов для получения мест для размещения генераторов. Блок-схема данной модели существенно отличается от той, что дана на Рисунке 13.4; на самом деле она является больше алгоритмом, чем блок-схемой.
Независимая X Коэффициент = Взвешенная
переменная регрессии = переменная

Рисунок 13.7. Предсказательная модель лесозаготовки с использованием линейной регрессии. Эта блок-схема показывает использование методов дасиметрического картографирования с подстановкой в следующее уравнение регрессии для обычной практики лесоповала:
Y= 1.670 х1 + 0.424 х2 - 0.007 х3 -1.120 х4 - 5.090 х5 - 2.490
определенный рельеф способен концентрировать потоки ветра, правда, расчет в этом случае будет сложнее. — прим. перев.
Некоторым этот "рецептурный" подход может показаться более удобным, хотя на самом деле классическую блок-схему и алгоритм относительно легко можно преобразовывать друг в друга.
Вы можете попробовать следующий пример, представляющий статистический метод моделирования. Если вы знакомы с регрессией, то эта модель будет хорошим примером того, как дасиметрические методы могут применяться с использованием коэффициентов уравнения регрессии для изменения значений полигонов.
Основываясь на предсказательном статистическом методе, известном как регрессия, данная модель пытается предсказать объем лесозаготовок (Рисунок 13.7) [Berry and Tomlin, 1984]. Данная величина нужна лесозаготовительным компаниям при попытке определения их финансового итога. В данной модели независимыми переменными (покрытиями или картами) являются процент уклона, диаметр деревьев, высота деревьев, объем деревьев и процент дефектных деревьев. Каждый фактор имеет измеримое влияние на предсказываемый объем лесозаготовки, которое отражается коэффициентами регрессии. Перемножая каждую независимую переменную на соответствующий коэффициент, модель создает взвешенные покрытия, которые при сложении друг с другом и прибавлении некоторой константы дают искомый объем заготовок. Поскольку эта модель использует проверенные, статистически значимые коэффициенты для каждой независимой переменной, результаты оказываются высоко надежными и легко проверяемыми.
ПРОВЕРКА РАБОТОСПОСОБНОСТИ МОДЕЛИ
Рассматривая картографические модели, мы исходили из того, что всё будет идти по плану, и результаты будут соответствовать ожиданиям. Так как ввод данных занимает значительную долю времени работы с системой, имеет смысл выбрать небольшую часть области исследования для проверки работоспособности модели, и лишь после этого вводить все данные. Этот подход полезен и для верификации модели, о чем пойдет речь чуть позже.
Используя подмножество изучаемой области и блок-схему модели, мы начинаем с нижнего уровня каждой подмодели и, выполняя ее действия, отвечаем на следующие вопросы:
Если мы переклассифицируем категории, то сконфигурирована ли наша БД для выборки соответствующих значений? Или, если мы переклассифицируем категории в растровой системе без БД, имеет ли значение порядок переклассификации?
Если есть альтернативные методы или альтернативные комбинации методов, то какие из них скорее дадут нам корректный ответ при наименьших затратах труда?
Есть ли у нас абсолютная уверенность в том, что выбранные операции действительно представляют функционирование моделируемой среды?
Что мы будем делать с недостающими переменными в каждом покрытии, если таковые обнаружатся?
Конечно, есть множество и других вопросов, но и этих должно быть достаточно, чтобы понять, о чем речь. Выполняя операции над частью БД, легче оценить, что происходит на каждом шаге. Вдобавок, появляется возможность проверки промежуточных результатов вручную, что пригодится при верификации модели.
Другим важным аспектом прогона модели является определение того, какие покрытия необходимы для продолжения моделирования, а какие должны быть сохранены для верификации модели. На практике, многие считают, что если покрытие создано, то его следует на всякий случай сохранить. Однако, дисковое пространство всегда ограничено, и вы легко можете растратить все свободное место. Вот еще одна причина для использования только части БД, - это позволит выявить промежуточные покрытия, которые могут систематически удаляться, а также понять, не нужно ли увеличить объем дисковой памяти для полного набора данных. Здесь же вы можете решить, для каких покрытий следует делать резервные копии; по крайней мере, для исходных данных это просто необходимо.
Прогон модели может даже пробудить азарт, так как позволяет попробовать различные модификации, — просто чтобы увидеть, что получится. Однако, следует помнить, что ГИС может запросто создавать совершенно бессмысленные результаты. А многочисленные эксперименты могут забить диск ненужными или малоценными покрытиями, при массовом удалении которых могут пострадать действительно ценные данные.
*
Информация может иметь немалую
стоимость, так что планирование защиты
данных
и
определение прав
доступа,
также
как и ведение протокола
работы,
являются
важными сторонами серьезного проекта,
позволяющими предотвратить или
минимизировать ущерб от непреднамеренных
или умышленных разрушительных действий,
а также восстановить и проанализировать
последовательность событий в случае,
если такие действия произойдут. —
прим.
перев.
ВЕРИФИКАЦИЯ МОДЕЛИ
Карты являются удобным средством сообщения информации. Их визуальное воздействие таково, что люди принимают изображенное как истинное, не задаваясь вопросами о данных, на основе которых эта карта построена, или методах моделирования, использованных при ее создании. Поэтому не должен вызывать удивления и тот факт, что многие, даже большинство, моделей принимаются как должное, подобно картам. Такое отношение может быть очень опасно для клиента, который может потерять деньги, престиж и даже весь свой бизнес, принимая решения на основе некачественных данных или некорректных комбинаций корректных данных. Это может быть опасно и для поставщика ГИС или консультационной фирмы, которым придется тратить больше времени и средств на судебные тяжбы, чем на создание картографических моделей.
Решением является верификация модели (model verification). Существует не так много примеров верификации моделей в практических приложениях и литературе. Это не должно вас удивлять, так как пользователи ГИС не имеют иммунитета против силы графического документа. Часто просто красивая карта выглядит ничуть не хуже, чем корректная карта. Оказавшись на демонстрации приложений ГИС, вы тут же подвергнетесь атаке широким спектром цветов, символов, шрифтов, картинок типографского качества. Не удивительно, что мы тратим гораздо больше времени на создание, нежели на верификацию. Кроме того, нужно немало труда, чтобы получить простой картографический продукт из сложной модели. Все-таки, несмотря на редкость верификации, мало кто не согласится с важностью ее проведения.
Итак, определение. Я определяю термин "верификация" достаточно свободно, для описания не только корректных, но и полезных моделей. В конце концов, если результаты анализа корректны, но бесполезны, их нельзя назвать продуктом. В пределах этого определения должны получить ответы три вопроса:
Действительно ли используемые в модели данные отражают условия, которые мы пытаемся смоделировать?
Корректно ли мы скомбинировали факторы модели для представления их реального взаимодействия? Правильно ли описываем или предписываем таким образом процесс принятия решения?
Является ли конечный результат приемлемым и/или полезным для пользователей в качестве средства для принятия решений?
Первый вопрос должен рассматриваться еще на стадии ввода данных, но это не всегда возможно. Одной из причин составления блок-схемы модели является выявление недостающих переменных, определение возможности получения адекватного решения на основе имеющихся покрытий. Иногда бывает так, что используемые факторы не дают ожидаемого результата, что может свидетельствовать о неполноте модели или о том, что используемые факторы неадекватно представляют ограничения модели. В этом случае может помочь прогон модели на небольшом подмножестве БД, типичном для всего содержания.
Блок-схема будет очень полезной при поиске недочетов модели, в том числе и для рассмотрения подмоделей, в одной из которых может таиться недостаток, делающий некорректным общий результат. Иногда таким недостатком могут быть устаревшие данные, о чем также следует помнить.
Очень хорошим примером оценки представительности данных является проведение переписи кустарниковых соек для проверки точности представления местонахождений этих птиц при помощи модели их области обитания во Флориде [Duncan et al., 1995]. Это исследование особенно ценно тем, что показывает недостаточность простого сравнения распределений в качестве основы для принятия решений. Вместо этого для оценки результатов авторский коллектив использовал статистическую проверку, приведшую к дискуссии о возможных причинах обнаружившегося несоответствия.
Другой проблемой соответствия элементов модели реальному миру являются недостающие переменные. Всё-таки, ГИС может быть реализована и при отсутствии некоторых переменных [Williams, 1985]. Они могут быть просто недоступны, и потому должны быть исключены из модели, при этом окончательный вариант модели должен указывать, каких факторов не достает, и явно признавать, что модель не является полной картиной реальности.
В некоторых случаях переменные не отсутствуют, а слишком неясны или плохо определены (для их использования). Они также могут оказаться непространственными по определению, что не позволит поместить их в явно пространственный контекст при отсутствии пространственных представителей [DeMers, 1995].
Вторым вопросом верификации является правильное комбинирование факторов. Прежде всего нужно выяснить, дают ли аналитические функции ГИС должные результаты на основе известных входных данных. Поставщики многих систем не сообщают конкретной информации о том, как эти результаты достигаются. Исследование разнообразных ГИС показало, что разные системы дают несколько отличающиеся результаты при выполнении аналогичных операций на одной и той же исходной БД [Fisher, 1993]. Возможно, вам тоже понадобится подобное тестирование, хотя в реальной обстановке это вряд ли возможно из-за высокой стоимости приобретения и поддержки нескольких систем, различающихся программно и даже аппаратно. В качестве альтернативы можно предложить создание специальной контрольной БД с известными параметрами для проверки выполнения каждой аналитической операции на приемлемость результатов. Этот подход, как и предыдущий, требует немало времени, поэтому его можно рекомендовать в основном тогда, когда ваши данные очень чувствительны к используемым алгоритмам. На счет составления такой испытательной БД практически нет общих указаний, вам следует полагаться на ваше собственное знание данных и того, как программа должна их обрабатывать. Несомненно, это еще одна причина для приобретения концептуальных знаний функционирования ГИС.
Другая ситуация: вы убеждены в правильной работе всех нужных функций ГИС, но не имеете полной уверенности в том, что все шаги выполняются в правильной последовательности. Чтобы проверить это, вы можете использовать подход обращения процесса, похожий на проверку деления умножением (когда вы умножаете частное на делитель, чтобы получить делимое). В случае картографического моделирования вы можете взять простую БД, и, следуя по блок-схеме от результата к исходным данным, должны получить те покрытия, с которых начинали [Tomlin, 1990]. Любой шаг, который производит отличающиеся покрытия, становится очевидным. Здесь может пригодиться сохранение промежуточных покрытий, пока результаты модели не получат подтверждения; их можно также использовать, чтобы не запускать модель каждый раз с самого начала.
Намного сложнее вторая часть вопроса: взаимодействуют ли сами факторы таким образом, чтобы адекватно моделировать происходящее в реальности. Здесь нет простого рецепта, можно только сослаться на опыт и интуицию разработчиков. Во многих случаях они знакомятся с моделируемой средой и представляющими ее данными настолько, что любые несоответствия между данными и моделью становятся им сразу же видны. То же можно сказать и о правильном выборе факторов. Если модель противоречит интуиции, то есть немалая вероятность того, что "здесь что-то не так".
Если отрицается возможность плохих данных или некорректных функций ГИС, то остается только некорректность самой модели. Между прочим, некорректные или неестественные результаты должны, как и в статистическом анализе, приводить к дальнейшему исследованию реального функционирования моделируемой среды. В таком случае ГИС оказывается полезным инструментом для развития науки, а также внедрения в практику ее достижений.
Третья сторона верификации модели связана с полезностью модели в качестве инструмента принятия решений. Здесь важно представление выходной информации, о чем пойдет речь в Главе 15, но несколько слов нужно сказать об этом и в контексте верификации, а именно о том, что неадекватная картографическая форма может легко повести пользователя в ложном направлении. Это может случиться, например, когда модель использует цвета, которые обычно подразумевают повышенную значимость или опасность (например, красный) для обозначения малозначительных объектов. Даже если не было намерения присвоить значительный вес неправильно понятому фактору, результатом может стать анализ, приводящий к принятию неправильного решения. Возможен и такой случай: в результате классификации вы выделяете небольшую область повышенной опасности со стороны радиоактивных отходов, игнорируя при этом множество других областей, которые не намного менее опасны, чем эта.
Важным вопросом является соответствие представления информации задачам клиента. Возможны различные формы вывода, не только карта. В некоторых случаях таблица может оказаться более полезной. Например, если клиентом является владелец газеты, пытающийся увеличить тираж, то полученный в результате список местных жителей, не являющихся подписчиками, будет более полезным для прямого маркетинга, нежели карта распределения тиража. Другим случаем большей полезности таблицы может быть распределение больных определенным заболеванием по территориальным единицам страны или региона. Некоторым пользователям полезнее будет список территориальных единиц, отсортированный в порядке убывания числа или процента таких больных, нежели карта хороплет. Причиной может быть незнакомство с картографическими методами одних пользователей или желание других иметь численные данные, на основе которых такая карта могла бы быть построена, чтобы обнаружить критические значения.
Возможны и другие формы вывода. Например, при использовании ГИС в службах экстренного реагирования, помимо создания карты с кратчайшим маршрутом к месту происшествия, система может посылать электронный сигнал непосредственно в то отделение службы, которое должно принять вызов. Хотя сегодня это может быть для ГИС несколько экзотической формой вывода, по мере развития техники и спектра клиентов ГИС, она может стать вполне обычной.
Последний рассматриваемый вопрос верификации модели -приемлемость результатов для пользователя. Возможно, клиенту нужен вполне определенный результат, соответствующий его пониманию, предубеждению или политической ориентации. Если клиент дает данные для включения в модель, то ответственность за их качество и качество принятия решений на их основе ложится на клиента. Следует понимать, что ваша работа может использоваться для оправдания принятых решений "задним числом". Поэтому, если вы обнаруживаете негативную оценку клиентом корректных результатов, вы можете попытаться объяснить ему, в чем его взгляд не соответствует действительности, возможно, используя для этого блок-схему и объяснение работы модели. Согласие заказчика будет положительным результатом этой части верификации модели. Если же он настаивает на получении заданных им результатов, то это уже вопрос профессиональной этики: будете вы "играть заказанную им музыку" или будете более щепетильны в выборе клиентов.
Вопросы
1. Имея столько команд и опций в ГИС, как можно построить модель?
Что мы имеем в виду, говоря, что процесс картографического моделирования является циклическим? Создайте сценарий в вашей области интересов, иллюстрирующий это утверждение.
Какое преимущество имеет дедуктивное картографическое моделирование перед индуктивным? Где индуктивное моделирование могло бы больше всего пригодиться?
В чем разница между явными и скрытыми переменными? Между неявно и явно пространственными переменными? Что такое пространственные представители и как они используются в картографическом моделировании?
Какова цель составления блок-схем картографических моделей? Какие преимущества они дают?
Что вы будете делать, если ограничения вашей модели не позволяют получить приемлемое решение? Каковы два возможных пути решения этой проблемы?
Что вы будете делать, если ограничения вашей модели слишком слабы, приводя к результатам, слишком неопределенным, чтобы помочь вам в принятии решения?
Почему веса факторов так важны при создании картографических моделей? Почему некоторые факторы являются абсолютными, а не просто с более высоким по сравнению с другими весом? Приведите примеры.
Каковы три основные вопроса верификации картографической модели? Предложите способы решения каждого из них.
Приведите примеры, когда картографический вывод может быть не так полезен, как другие формы вывода результатов пространственного анализа.
Почему важно прогонять модель на прототипе БД перед реализацией полной БД?
12. О чем мы должны помнить при начале реализации модели? Почему при этом не стоит полагаться лишь на экспериментирование или интуицию?
ВЫВОД
В
ГИС
Вывод
результатов анализа![]()
![]()
Вывод результатов - конечный продукт любого анализа. И если он не понятен пользователю, то мы не справились с нашей задачей. В конце концов, целью является не просто анализ сам по себе, а и представление результатов. Здесь мы рассмотрим как технику вывода ГИС, так и некоторые требования дизайна для создания качественного, понятного выходного продукта. Обе стороны важны, так как техника физически ограничивает наши возможности создания изображений, а пользователи имеют физические и психологические ограничения и особенности восприятия, влияющие на интерпретацию результатов.
Вопросам дизайна вывода ГИС уделено относительно мало места в литературе, хотя в области традиционной картографии — предостаточно. Здесь вам может также помочь литература по графическому дизайну, которой тоже немало. Ценность этих знаний обусловлена еще и тем, что качественный вывод делает пользователей довольными, а довольный пользователь это клиент, который к вам еще вернется.
Техническая сторона играет большую роль, при этом техника постоянно меняется. А ценность качественного вывода всегда остается в силе, и хотя знание технических особенностей оборудования может быть полезным, гораздо важнее соотношение техники и качества вывода.
Есть много возможностей увидеть примеры хорошего и плохого вывода ГИС: выставки, конференции, Интернет, рекламно-информационные материалы поставщиков систем, презентации и т.д. Наблюдая их, вам следует не только восхищаться возможностями систем, но и посмотреть на их вывод критически, попытаться выразить словами его достоинства и недостатки. Это поможет не только понять, что следует делать, а что - нет, но и освоить лексикон данной дисциплины и более четко формулировать требования к представлению результатов аналитических процедур.
ВЫВОД: ОТОБРАЖЕНИЕ РЕЗУЛЬТАТОВ АНАЛИЗА
Вывод результатов анализа может быть постоянным (permanent) и временным (ephemeral), в зависимости от типа выходного устройства. К первой категории мы относим вывод на бумагу, пленку или магнитные
носители - все они могут хранить результат долгое время. Вторая категория - вывод, обычно на экран монитора или проекционный экран, с целью демонстрации результатов анализа или предварительного просмотра файлов при решении об использовании их в анализе или о постоянном выводе.
Вывод может быть также разделен на человеко- и машинно-ориентированный [Burrough, 1986]. Машинно-ориентированные вывод чаще всего используется для сохранения материала на компьютерных носителях информации; он возвращает нас от подсистемы вывода ГИС к подсистеме хранения и редактирования. Человеко-ориентированный вывод предназначен для восприятия людьми. Машинно-ориентированные формы требуют решений о структуре данных, носителе информации и совместимости с другими программами и компьютерными системами, принять которые проще, чем решения о человеко-ориентированном выводе, поскольку люди больше различаются по опыту и уровню понимания графических средств коммуникации. По этой причине мы уделим больше внимания именно человеко-ориентированному выводу.
Поскольку сейчас в выводе ГИС преобладает картографическое представление, и это состояние, по-видимому, сохранится на несколько лет или даже десятилетий вперед, большая часть главы будет посвящена именно этой форме. Но мы рассмотрим и другие формы и основания для их использования вместе с картографическим выводом или вместо него.
КАРТОГРАФИЧЕСКИЙ ВЫВОД
Карты всё еще остаются наиболее компактным способом представления географической информации.
ГИС позволяют создавать самые разнообразные карты, однако сегодня большинство ГИС-аналитиков имеют очень ограниченный опыт в картографическом производстве и дизайне. По этой причине, и потому, что количество пользователей карт постоянно растет, требования эффективного представления становятся все более насущными.
Целью изготовления карты является создание у пользователя представления о том, как выглядит соответствующее реальное окружение [Robinson et al., 1995]. Эта цель в значительной степени является функцией назначения карты и связана с предполагаемой аудиторией. Общегеографические карты (general reference maps) стремятся отобразить одновременно широкий спектр различных географических феноменов. Но поскольку большинство карт на выходе ГИС относятся к тематическим картам (thematic maps), выделяющим структурные отношения в рамках выбранной темы, мы сконцентрируем наше внимание именно на них. В случае ГИС слово "тема" можно заменить на "решение", так как такие карты
чаще всего являются результатом решения определенной задачи или ключом к завершению процесса принятия решения.
Помимо размещения на тематической карте исследуемых объектов, на ней должна также присутствовать некоторая система координат, чтобы была возможность определения положений этих объектов в географическом пространстве [Robinson et al., 1995]. В некоторых случаях, например, при отображении данных, полученных со спутников, координатная система становится особенно важной, поскольку пользователь может быть не знаком с представлением наземных объектов в псевдоцветах и не сможет прочитать карту без координатной сетки или очертаний знакомых объектов. Кроме того, координатная сетка позволяет оценивать пространственную протяженность и площадь объектов.
Первое правило при составлении тематической карты гласит, что она должна быть читаема, анализируема и интерпретируема [Muehrcke and Muehrcke, 1992]. А проще: "устраните все ненужные объекты". Каждый помещаемый на карту объект должен что-то говорить на тему этой карты. Не должно быть ничего лишнего и всяких украшений вроде тех, что помещают на карты спрятанных пиратских сокровищ.
Даже после того, как вы устраните лишние объекты, нужно будет принять множество решений о выборе, обработке и генерализации выходных данных, а затем - об использовании соответствующих символов для отображения этих данных таким образом, чтобы пользователь легко мог их понять [Robinson et al., 1995]. Этот процесс состоит из своего рода смеси науки и искусства, и, чтобы достичь наилучшего результата, следует выполнить несколько предварительных набросков перед началом реальной компиляции карты.
Дизайн карты может быть очень сложным, особенно при широких возможностях современных компьютерных программ. Однако логические (интеллектуальные) и графические (визуальные) цели картографического дизайна часто конфликтуют. Разрешение этих проблем почти всегда происходит путем компромисса [Robinson et al., 1995]. Например, если вы располагаете символы домов на карте, то и логика, и эстетика диктуют согласованный подход, скажем, расположение символов в точных координатах домов. Но если там же имеется линейный символ, представляющий дорогу, проходящую очень близко от этих домов, то либо символ дроги, либо символы домов должны быть смещены. При некоторых обстоятельствах вам может потребоваться смещение как символов домов, так и символа дороги в сторону от их точных положений (Рисунок 14.1).
Выбор, сделанный на Рисунке 14.1, отражает важнейшее положение о том, что графические объекты не абсолютно точно указывают реальное положение физических объектов, которые они представляют. Картографам приходилось решать огромное множество подобных проблем, поэтому они создали подробный набор соглашений (conventions) и традиций, которые являются результатом проб и ошибок, а главное, - проверки среди пользователей карт. Эти результаты содержат самые эффективные методы достижения компромисса, они должны быть для вас руководством для ваших собственных картографических решений. Отклонений от установленных норм почти всегда приводит к созданию карты, менее эффективной в сообщении результатов вашего анализа, чем она могла бы быть.
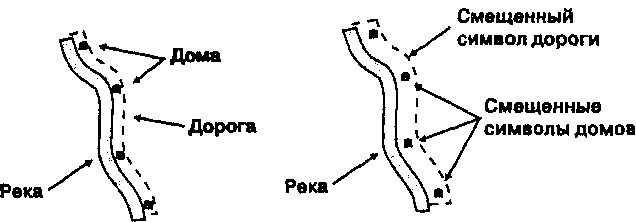
Рисунок 14.1. Компромисс размещения символов. Участок карты, иллюстрирующий компромисс, необходимый для размещения символа реки вблизи символов домов. Некоторые объекты должны быть физически смещены, чтобы дать место другим.
Процесс дизайна
Первый шаг состоит в выборе типа карты, которую вы собираетесь создать, размещаемых на ней объектов и общего ее вида. Эта стадия интуитивна, результат ее - общий план вашей карты. Может быть полезен набросок, сделанный от руки, прежде чем вы сядете за компьютер (Рисунок 14.2).
Далее вы выбираете символы для отображения объектов, интервалы классов, цвета, типы линий и другие графические элементы. Это тоже можно сделать на эскизе. При этом обычно отмечаются размеры объектов и расстояния между ними, которые потом могут быть введены в программу (Рисунок 14.2b).
Заключительная стадия процесса дизайна состоит в точной настройке того, что было сделано на предыдущей стадии. Здесь в общий план карты могут вноситься только небольшие изменения. Главное — создание прототипа на экране монитора перед выводом на печать, так как принтеры и плоттеры намного медленнее экрана монитора. При этом следует учитывать возможные различия изображений на экране монитора и на бумаге, обусловленные использованием специальных языков управления периферийными устройствами. При выводе текста нередко получается так,
что шрифты в компьютере и в принтере немного различаются, что приводит к наложению или сдвигу надписей, чего не наблюдалось на экране, или замене некоторых символов (особенно символов национального алфавита и специальных), коды которых различаются в компьютере и принтере (Рисунок 14.3)*. Другая часто встречающаяся проблема - несоответствие цветов: заметно различающиеся на экране компьютера цвета могут оказаться практически одинаковыми на бумаге. Здесь можно порекомендовать вывести уменьшенную копию карты или ее часть, чтобы оценить соответствие и, если нужно, внести коррективы перед печатью всей карты**.
Рисунок 14.2. Предварительная компоновка карты. Составленные от руки (а) и на компьютере (b) наброски, показывающие основные объекты, их размещение и общую композицию карты. На компьютерном варианте указаны размеры объектов, что полезно для завершения компоновки.
Роль символов в дизайне
При создании карты вы должны варьировать вид графических примитивов, представляющих точечные, линейные и площадные объекты, чтобы эти объекты были различимы.
Основные параметры, которые могут изменяться, это форма, размер, ориентация и цвет [Robinson et al., 1995]. Кроме этого, для заполнения
* Эта проблема радикально решается установкой в драйвере периферийного устройства (например, принтера) флажка требования выводить всё, включая текст, в виде графики. При этом возможно некоторое замедление вывода, зато соответствие всегда будет полным.
**Более надежный путь - калибровка оборудования с использованием специальных калибровочных программ (обычно используемых в издательском деле) для достижения максимального соответствия изображений на экране и бумаге. После калибровки учет всех различий и их корректировка производятся программой автоматически в процессе вывода. — прим. перев.
Вывод
результатов анализа
площадных объектов могут использоваться штриховки (patterns), которые характеризуются организацией (arrangement) - регулярной или случайной, частотой следования элементов (texture), позволяющей делать их светлее или темнее, и ориентацией (orientation) этих элементов [Robinson et al., 1995].
Рисунок 14.3. Окончательная композиция карты. Изображение карты на экране компьютера (а) и то, что можно обнаружить на бумаге (b). Заметны наложения, отсутствовавшие на экране компьютера.
Все эти параметры могут изменяться для улучшения графического представления объектов и их групп. Поскольку карты воспринимаются как единое целое (в отличие текста, воспринимаемого последовательно, слово за словом), необходимо также уделять внимание таким характеристикам дизайна, как разборчивость (legibility), визуальный контраст (visual contrast), отношение основного изображения и фона (figure-ground) и иерархическая структура (hierarchical structure).
Графические символы должны быть прежде всего разборчивыми: отдельные линии - разделимыми, цвета - различимыми, формы -узнаваемыми [Robinson et al., 1995]. Размеры символов должны учитывать расстояние, с которого карта рассматривается и которое может меняться от десятков сантиметров при индивидуальной работе до нескольких метров при демонстрации в коллективе. При этом нужно помнить и о физических ограничениях оборудования и человеческого глаза.
Другим фактором разборчивости является видимость самих символов. Например, линии замечаются легко, поэтому нет нужды делать их особенно широкими. Одни сочетания цветов помогают различению (как черные буквы на белом фоне), другие - мешают (те же черные буквы на темно-синем фоне). Наконец, использование легко узнаваемых символов и их комбинаций помогает разборчивости, - классическим примером являются фигуры, используемые на дорожных знаках, - они позволяют передать сообщение без использования текста.
Визуальный контраст также необходим для различения графических символов и текста на имеющемся фоне, а также при их близком расположении. Если некоторые элементы выглядят почти одинаково из-за сходства размера, формы, штриховки или других параметров, то может быть полезным внести дополнительные вариации, чтобы увеличить контраст (Рисунок 14.4). При этом нужно не "перегибать палку", так как слишком большой контраст может привести к утомлению зрителя при длительном рассматривании.
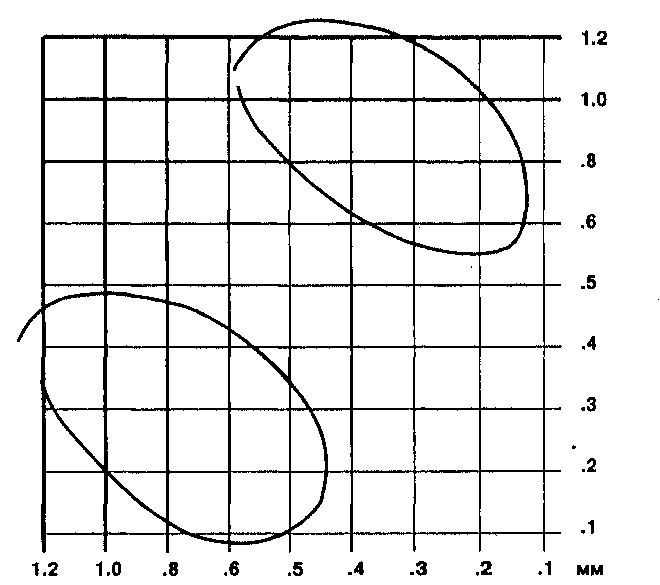
Рисунок 14.4 Ширина линий и скука. Пример изображения, скучного вследствие одинаковой ширины линий. Обведенные области кажутся более заметными и привлекают больше внимания по сравнению с областями меньшего контраста.
Принципы графического дизайна
Компонуя карту, вам придется размещать ее элементы на ограниченной площади. Многие карты выглядят неинтересными вследствие того, что на них слишком много или слишком мало белого фона. Посмотрите на карту штата Калифорния (Рисунок 14.5). Специфичное очертание его границ дает большие пустоты в левом нижнем и правом верхнем углах. В них легко можно разместить масштаб, указатель северного направления, легенду и другие компоненты, для каждого из которых нужно подобрать размер и толщину линий, чтобы заполнить свободное пространство. В данном случае мы имеем дело с соотношением основного изображения и фона. Карта, которая полностью состоит из основного изображения, менее желательна, чем карта с некоторым аморфным фоном, обособляющим основное изображение и дающим ощущение принадлежности суше (Рисунок 14.6). Фон поднимает также контраст и визуальную привлекательность. Карта, на которой слишком много фона, уменьшает значение основного изображения и может вызвать у зрителя подозрение о том, что она не полна.
Рисунок 14.5. Баланс карты. Компоновка карты штата Калифорния, использующая особенности его очертания для расположения вспомогательных компонентов карты, дающая в результате более сбалансированную карту и лучшее соотношение основного изображения и фона.
Но отношение рисунок-фон содержит больше, чем только соотношение размеров. Если суша и водные поверхности имеют один цвет, то зритель легко может их перепутать. Добавление названий, знакомых очертаний границ, картографической сетки и штриховки позволит пользователю легко различать изучаемую область и не анализируемые участки карты (Рисунок 14.7).
Отношение фигура-фон содержит также аспект, называемый "хороший контур". Например, иногда, чтобы разместить на карте надпись, требуется разорвать какую-нибудь находящуюся под ней линию. Это не нарушает логической целостности, так как зритель воспринимает подразумевающуюся линию, хотя на карте она и разорвана, но при этом надпись также будет возможно прочесть. Другие примеры включают логическую дифференциацию суши и воды, границ и дорог, растительности и построек. Нужно рассматривать как можно больше таких соотношений с точки зрения отношения фигура-фон, учитывая при этом возможные ограничения на использование одного или более из этих параметров.
Рисунок 14.6. Соотношение рисунок-фон. Две карты одной области показывают, как контраст фона и рисунка позволяет облегчить различение того, какие области являются сушей, а какие - водой.
При этом целью остается создание полезной карты, а не просто применение как можно большего числа принципов дизайна.
Последним принципом графического дизайна является иерархическая организация. Все графические элементы, присутствующие на карте, должны быть организованы таким образом, чтобы подчеркнуть то, что наиболее важно. Этот принцип слабо применяется на общегеографических картах, так как их цель - дать возможность различным по интересам пользователям фокусироваться на важных для них элементах, поэтому все элементы такой карты должны иметь равное значение. А тематические карты, наиболее распространенные в среде ГИС, должны подчеркивать конкретные объекты или результаты анализа. Это может быть сделано посредством иерархической организации, или разделения элементов по уровням визуальной значимости.
Существуют три основных метода достижения иерархической организованности. Стереограммный (stereogrammic) метод требует выбора и модификации графических приемов с тем, чтобы позволить наиболее значимым элементам выглядеть расположенными выше, чем менее важные элементы. Это полезный метод улучшения соотношения фигура-фон. Ключами к восприятию глубины могут быть использование трехмерных объектов, различия в толщине линий, цвете, яркости или размере.
Второй метод иерархической организации называется расширительным (extensional), он чаще всего используется для ранжирования линейных или точечных объектов. Например, главные дороги должны выглядеть более заметными, чем второстепенные. Здесь мы можем варьировать толщину линий, их яркость или внутреннюю структуру (прерывистость, длину штриха и т.п.), а также комбинации этих свойств для показа значимости каждого линейного объекта. Некоторые ГИС имеют весьма ограниченные возможности изменения символов, но как правило, имеющимися средствами вполне возможно достичь желаемого результата.
Рисунок 14.7. Стереограммная иерархия. Использование сетки и штриховки создает ощущение глубины, известное как стереограммная иерархия.
Последний метод создания иерархической графической организации, называемый методом подразделительной иерархии (subdivisional hierarchy), применяется главным образом для показа различий во внутреннем устройстве областей (Рисунок 14.8). Так, например, пастбища могут делиться на активно-, умеренно- и малоиспользуемые. Этот же метод используется при обозначении границ государств жирными линиями, в то время как
Рисунок
14.8. Подразделигельная иерархия.
Использование подразделительной
иерархии для разделения областей.
Более высокий уровень иерархии
использует более интенсивную штриховку
или заливку.
ВНЕШНИЕ ФАКТОРЫ КАРТОГРАФИЧЕСКОГО ДИЗАЙНА
Все принципы дизайна, которые мы рассмотрели, зависят от некоторого числа внешних факторов, определяющих природу создаваемой карты, типы используемых графических элементов и применяемые принципы дизайна.
Первым и наиболее важным фактором является назначение (purpose) карты, в то время как сущностная задача (substantive objective) связана с природой информации, которую вы пытаетесь отобразить. Тематические карты, создаваемые в ГИС, предназначены для изображения конкретных результатов анализа. Здесь очень важна простота: чем более сфокусирован вывод, тем легче его понять. Вследствие низкой стоимости создания карт в среде ГИС по сравнению с традиционной ручной картографией нет нужды создавать малое число особенно сложных карт. С другой стороны, большой объем данных и широта возможностей отображения создают тенденцию перегружать карты. Результаты отдельных аналитических процедур вполне могут представляться на отдельных картах, которые, в конце концов, можно разместить и на одном листе, сохраняя тем самым их общую целевую ориентацию.
Другой аспект назначения карты, эргономическая задача (affective objective), имеет в виду не столько то, что отображается, сколько то, как это делается. Решив, что вы изобразите на карте, вам нужно также выбрать форму представления, которая сможет адекватно передать ваше сообщение. Если карта показывает опасные зоны, то ее дизайн должен недвусмысленно демонстрировать их важность; ее приятная наружность может иметь некоторую художественную ценность, но посылать при этом зрителю не то сообщение, которое вы предполагаете.
Вторым фактором является реализм (reality), означающий, что каждая область имеет собственные характеристики, налагающие ограничения на применимость критериев дизайна. В географическом анализе обычно участвуют области со сложными физическими, транспортными, социальными или экономическими структурами, ведь именно они требуют пространственного анализа. Эта сложность может существенно ограничивать возможности размещения названий, размеры и стили символов, типы штриховки и т.д. Такие ограничения неизбежны, и помочь здесь может только практическое знание области изучения и природы данных о ней. Априорное знание ограничений поможет выбрать оптимальную стратегию дизайна заранее, а не на последних стадиях, когда изменения вносить может быть намного труднее.
Третьим фактором является наличие данных (available data) - вопрос не только подготовки карт, но и проведения пространственного анализа,. Большинство БД ГИС имеют значительный объем - таковы требования анализа; кроме того, анализ часто проводится для больших территорий.
Вполне возможна, например, карта с сотней категорий землепользования; создать же сто различимых цветов весьма проблематично. В этом случае следует изменить процедуру дизайна для включения подразделительной иерархии с различными цветами и типами штриховки для каждого подразделения (Рисунок 14.9). С наличием данных может быть связана встречная проблема: данных либо недостаточно для анализа и отображения, либо они старые и собирались на иных принципах, либо для них использовалась слишком редкая выборка. Например, нелегко будет сравнивать данные вековой давности по растительности и современные ДДЗ. Первые будут, скорее всего, содержать лишь несколько общих категорий, часто находящихся под воздействием личного опыта сборщика данных, в то время как ДДЗ будут иметь большое число категорий, полученных по компьютерным алгоритмам классификации.
Рисунок 14.9. Проблемы с категориями. Карта с большим числом категорий. Из-за недостатка подразделительной иерархии может быть трудно понять, к какой категории относится каждый полигон.
Представление также зависит отчасти от масштаба карты. Его уменьшение уменьшает детальность карты и пропорционально уменьшает ее символы. Но в некоторый момент дальнейшее уменьшение символов становится невозможным из-за потери их различимости. Поэтому при дизайне карты приобретают важность выбор объектов, упрощение и обобщение (генерализация).
Следующим фактором является целевая аудитория (audience). Многие пользователи выходных документов ГИС не имеют знаний и опыта в географии и картографии [Robinson et al., 1995]. В таких условиях карта должна восприниматься как можно легче, благодаря сохранению лишь наиболее важных объектов и названий и применению общеизвестных символов. В то же время, более опытные пользователи смогут извлечь дополнительную информацию из более плотного представления с более абстрактными символами [Robinson et al., 1995]. Значение может иметь также и возраст, ибо пожилым людям и детям труднее воспринимать мелкие символы и текст. В случае проблем с цветовосприятием у пользователя может даже потребоваться монохромное изображение.
Условия использования играют важную роль в дизайне карты. Сюда входят не только варианты карты-плаката или настольного документа. Если карта будет использоваться в условиях плохого освещения, то нужно увеличивать контраст и размер символов. Если карта будет использоваться в полевых условиях, то ее нужно ламинировать. Например, во время войны в Персидском заливе 1993 года Национальное географическое общество США изготовило для военных сотни ламинированных карт. Весь набор условий работы с картой должен учитываться перед принятием окончательного варианта дизайна.
Наконец, на дизайн карты влияют технические пределы оборудования. Очевидно, что на черно-белом принтере нельзя напечатать цветную карту. Дешевые цветные принтеры часто имеют лишь небольшое число воспроизводимых цветов. Существенно также пространственное разрешение устройства вывода, ограничивающее размер символов и уровень детализации. Все эти факторы должны быть учтены.
НЕТРАДИЦИОННЫЙ КАРТОГРАФИЧЕСКИЙ ВЫВОД
Традиционно, тематические карты создаются главным образом в их ортографической (orthographic) форме, когда зритель как бы смотрит на землю сверху. Такие карты рассчитаны на близкое к реальности воспроизведение форм и соотношений. Но существуют и другие картографические формы, имеющиеся во многих коммерческих ГИС.
Среди первых возможностей векторного графического отображения для нетрадиционного представления тематических карт были проволочные диаграммы (fishnet maps, wire-frame diagrams). Теперь это одна из наиболее распространенных картографических форм, создающая впечатление трех измерений.
Хотя такие карты малоценны с точки зрения анализа, они очень эффективны в представлении результатов анализа, особенно представляемых в виде поверхностей. При этом должны учитываться дополнительные параметры дизайна: расстояние, азимут и угол зрения [Imhof, 1982; Kraak, 1993], а также расположение источника освещения [Moellering and Kimerling, 1990] и влияние разрешения ЦМР. Поскольку современные программы позволяют визуально накладывать на эти трехмерные поверхности данные других покрытий, пользователь легко может идентифицировать связи между топографией и другими факторами.
Сегодня некоторые системы позволяют наблюдать карты этого и других типов не только статически, но и с эффектами анимации. Для двухмерных карт анимация позволяет наблюдать динамические системы так, как они действуют в реальном мире [Moellering, n.d.], или демонстрировать процессы, которые не воспринимались бы из-за их слишком медленного развития в реальности [Tobler, 1970]. При этом движение может быть замедлено, ускорено, приостановлено или обращено, что дает возможность лучшего понимания этих явлений. Сейчас существуют и системы с трехмерной анимацией [Moellering, 1980], создающие впечатления пролета над местностью. Не следует преуменьшать мощь этих приемов, ибо зрение человека гораздо лучше замечает движущиеся объекты, чем неподвижные, что безусловно помогает выявлению взаимодействий объектов и их распределений.
Если ресурсов компьютера недостаточно для анимации, вы можете прибегнуть к другим способам визуализации, например, затенению. Оно особенно эффективно для визуализации топографических поверхностей без выполнения трехмерных карт, и создается моделированием освещенности склонов источником, находящимся в заданной точке. Такая карта выглядит как фотография сверху. Для иллюстрации отношений между нанесенными на карту показателями и фотографическим изображением можно использовать в качестве фона космические и аэрофотоснимки. Для топографии и подземных феноменов могут использоваться сечения земной поверхности с выбираемыми пользователем параметрами. Список таких возможностей и их комбинаций практически неограничен.
*В
русскоязычной
литературе по картографии принято
иное терминологическое деление типов
карт. Здесь же под картограммами
подразумеваются собственно картограммы,
картодиаграммы и картосхемы. - прим.
перев.
Например, в автобусах и поездах можно встретить схемы маршрутов. На них остановочные пункты располагаются на прямой линии, а не в двухмерном пространстве, причем расстояние между ними также обычно не соответствует реальному. Эти условности упрощают карту до уровня схемы, оставляя только наиболее важные пространственные характеристики - состав и последовательность остановок и возможности пересадок (Рисунок 14.10). В дорожных атласах можно встретить линейные маршрутные картограммы (routed line cartograms), на которых показаны еще и расстояния между населенными пунктами и примерное время в пути.
Картограммы изменяют географическое пространство, преобразуя его в легко понимаемые модели реальности. Другая форма картограммы, линейная картограмма центральной точки (central point linear cartogram), может использовать как эвклидово, так и функциональное расстояние (Рисунок 14.11) [Bunge, 1962]. Среди наиболее используемых видов картограмм находятся площадные картограммы (area cartograms), которые варьируют размер каждой нанесенной на карту области в зависимости от некоторого параметра этой области. В классическом примере использования данного метода [de Blij and Muller, 1994] размер каждой страны пропорционален численности ее населения, а не ее площади. Площадные картограммы могут быть как непрерывными, когда все области соприкасаются, так и с разрывами, когда соприкосновения нет (Рисунок 14.12) [Campbell, 1991].
Интерпретация картограмм может потребовать некоторого времени на выработку навыка у пользователя, не знакомого с этой формой. Но когда он сможет легко в них разбираться, результаты обычно стоят этого. В то же время, многие пользователи хотят получать и традиционные картографические формы, чтобы сравнивать с ними этот радикально отличающий способ графического представления.
Вполне вероятно, что вам не будут часто встречаться картограммы в качестве вывода из ГИС на конференциях и выставках. Отчасти это потому, что большинство членов ГИС-сообщества либо не знакомы с этими формами, либо еще не привыкли к их использованию. Другой причиной может быть малое количество систем, позволяющих легко строить картограммы в компьютерной среде. Как бы то ни было, использование картограмм в качестве альтернативы традиционному картографическому выводу будет расти по мере роста осведомленности о них разработчиков и пользователей ГИС.
Рисунок 14.10. Линейная картограмма. Линейная картограмма городского транспорта Чикаго.
Рисунок 14.11. Картограмма центральной точки, а) Обычное представление времени движения от центра Сиэтла с интервалом в 5 минут. b) Картограмма, показывающая функциональное расстояние с интервалом в 5 минут.
НЕКАРТОГРАФИЧЕСКИЙ ВЫВОД
Несмотря на преобладание карт среди выходных документов ГИС, некоторые данные лучше представляются в иных формах, когда карта не создается вовсе, или как дополнение к карте (когда, например, карта не может быть непосредственно воспринята целевой аудиторией).
Интерактивный вывод
Возможно, классическим примером замены картографического вывода альтернативной формой является использование ГИС в службе спасения. Если вызов требует тушения пожара, то ГИС позволяет одновременно с принятием вызова оператором определить ближайшую к указанному адресу пожарную часть и направить в нее электронный сигнал тревоги. То есть, в данном случае выводом ГИС будет не карта, а электронный сигнал. Кроме того, та же ГИС может определить кратчайший маршрут для пожарной машины и нанести его на карту, а саму карту дополнить маршрутным листом, в котором перечислены улицы, перекрестки и иные отметки, позволяющие пройти маршрут без помощи карты. Хотя эксплуатируемые сегодня системы не так интеллектуальны, технические возможности вполне позволяют реализовать описанный сценарий, в котором альтернативный вывод может как дополнять карту, так и заменять ее.
Рисунок 14.12. Сплошные картограммы и картограммы с разрывами.
Таблицы и графики
Существуют многие альтернативные виды вывода из ГИС [Garson and Biggs, 1992], но более других распространены таблицы и графики, которые, помимо прочего, не требуют для вывода дорогостоящего оборудования.
Таблицы и графики могут существенно улучшить понимание картографических результатов. Представьте себе, что вы анализируете изменение распределения типов землепользования в процессе вытеснения жилой застройкой естественной среды и сельскохозяйственных угодий. Серия карт показывает области наиболее существенных изменений. Вы можете прямо в легенды карт вставить таблицы процентов по типам землепользования на каждый момент времени. Кроме того, под каждой картой можно поместить столбчатую диаграмму распределения классов землепользования, а также изменения с предыдущего момента. Можно также создать матрицу, показывающую изменения "от" и "до" для всех моментов времени. Такая таблица поможет понять, какие типы землепользования в основном поглотили естественную среду, какие - сельхозугодия.
Как и в случае с картами, в дизайне не картографического вывода также есть свои принципы. Таблицы в ГИС чаще всего встречаются в легендах карт для связывания атрибутивных данных с графическими объектами карты и как распечатки значений атрибутов объектов. К ним может также прилагаться содержимое словаря данных для детального описания данных и дополнения легенды карты.
Вопросы дизайна текстового вывода включают общие идеи назначения, читабельности и целевой аудитории, знакомые вам из раздела о картографическом дизайне. В вопросе назначения следует подумать о том, насколько эффективно текст и таблицы могут дополнить или полностью заменить картографический вывод.
Текст и таблицы понятны практически всем, и вопросы читабельности достаточно общеизвестны, вспомним основные. Используемый шрифт должен быть простым, без украшательств. Цвет и яркость символов и фона должны образовывать хороший контраст. Таблицы и текст желательно отделять от карты рамкой. Не следует злоупотреблять сокращениями, - чем меньше таблица требует объяснений, тем она удобнее. Для групп близких по смыслу строк или столбцов можно использовать дополнительное выделение, например, цветом. В общем, как и с картами, здесь следует полагаться на здравый смысл и чувство визуального баланса.
Рассматривая создаваемые таблицы с точки зрения целевой аудитории, следует использовать терминологию, понятную клиенту. Информация, которая содержится в таблицах, не должна быть избыточной, - избыток не только не интересен, но и может породить путаницу. Поэтому перед созданием табличного вывода следует выяснить, что именно нужно пользователю, и как это лучше представить. Вряд ли будет полезен монстр с полусотней столбцов и не меньшим числом строк. Наверняка его можно было бы заменить серией графиков и диаграмм, которые в изобилии имеются в программах электронных таблиц и деловой графики*.
*Например, ГИС-продукты компании ESRI поддерживают связи с такими программами и статистическими системами. Во многих случаях можно также использовать стандартные механизмы передачи данных между приложениями, подобные DDE и Clipboard в Windows. — прим. перев.
Обычно графики строятся в декартовых координатах; реже встречается другой тип координат - полярные, в которых координатами являются угол и длина вектора, проведенного из начальной точки. На простых графиках данные изображаются точками, которые часто соединяются прямыми отрезками или плавной кривой. Довольно часто используется другой вид графиков - гистограммы, в которых вместо точек используются столбцы, расположенные вертикально или горизонтально; они лучше подходят для изображения небольшого количества дискретных данных.
Следует отметить еще один интересный тип графиков - аддитивный. В нем одновременно показываются значения нескольких параметров, причем столбцы строятся не на общей оси и не на отдельных осях, а прямо друг на друге, что отражает аддитивный характер этих показателей. Например, такими параметрами могут быть процентные содержания песка, ила и глины в почве, которые в сумме составляют сто процентов.
Построение графиков благодаря компьютеру стало почти что тривиальной задачей. Сами программы их построения предлагают много дополнительных возможностей: использование цветов, объемных букв, линий и фигур, занимательных символов и т.д. На самом деле, такие украшательства в большинстве случаев не нужны, они только ухудшают читабельность вывода и напрягают зрение.
Все решения о графическом представлении должны следовать основному критерию - простота и разборчивость. Значимые линии должны выделяться на общем фоне. Координатная сетка не должна быть слишком частой и заслонять собой сам график. Координатные оси должны доходить до максимальных значений изображаемых величин, желательно также наносить на оси максимальные и минимальные значения координат. При совмещении нескольких графиков следует позаботиться о том, чтобы масштаб для каждого показателя не вводил зрителя в заблуждение, что малые величины больше, чем они есть в реальности, и наоборот.
В настоящее время имеется большой объем литературы по деловой графике и графическому представлению, к которой и следует обращаться для детального изучения этого вопроса [Cleveland and McGill, 1988; Holmes, 1984; Meilach, 1990; Robertson, 1988; Sutton, 1988; Tufte, 1983; Zelazny, 1985].
Наконец, следует упомянуть новую возможность некартографического вывода, становящуюся все более популярной - фотоснимки. Недаром говорят, что лучше один раз увидеть, чем сто раз услышать. Эти изображения могут быть получены сканированием обычных фотографий, съемкой цифровыми фотоаппаратами, оцифровкой отдельных кадров видеосъемки. Они позволяют показывать здания, характер местности, образцы растений и животных. Такие изображения, хранимые в атрибутивной БД, помогают существенно улучшить понимание того, что представлено на карте. Как и в прочих случаях, не стоит злоупотреблять этой возможностью, так как для хранения снимков требуется нередко значительное дисковое пространство, а сами изображения по своей природе способны отвлекать внимание зрителя от карты, к которой они являются всего лишь иллюстрациями. То есть, использовать их нужно лишь тогда, когда они действительно добавляют нечто уместное и важное к основному выводу.
Вопросы
Почему важно знакомство с картографическим дизайном в ГИС? Почему это даже более важно для ГИС, чем для традиционной картографии?
Какова главная забота при создании карты в результате анализа в ГИС? Чем это дело отличается от карты как формы искусства?
Приведите отличный от приведенного в книге конкретный пример того, как могут конфликтовать интеллектуальные и эстетические соображения. Укажите, как можно было бы решить эту задачу.
Почему, несмотря на доступность компьютера и графических программ, процесс дизайна карты следует начинать с карандаша и бумаги?
Продемонстрируйте на конкретных примерах три основных принципа дизайна.
Покажите на примерах, какие ограничения дизайна возможны в картографическом выводе ГИС.
Приведите пример того, как слишком большой объем данных может создать проблемы в дизайне карты. Приведите примеры проблем при недостатке данных.
Какие параметры дизайна влияют на создание качественного трехмерного картографического вывода?
Приведите как можно больше примеров полезного применения анимации картографического вывода.
Что такое картограммы? Почему сегодня они не являются общеупотребительными в среде ГИС? Когда они могут оказаться полезными в качестве вывода результатов анализа в ГИС? Приведите примеры.
Перечислите некоторые типы некартографического вывода. Подумайте о том, когда вы могли бы принять решение о замене или дополнении имеющейся карты.
Каковы основные вопросы дизайна для создания и использования графиков в качестве вывода ГИС?

Проектирование
ГИС
![]()
![]()
Наше путешествие в мир геоинформатики подходит к концу. Мы прошли путь от представления географических объектов в цифровой форме до организации их в сложные модели, от ответов на простейшие вопросы до комплексного анализа множественных покрытий. Наш географический фильтр расширился, - теперь мы имеем гораздо больше возможностей для концептуализации, регистрации и анализа нашего окружения и представления результатов этого анализа. И теперь мы не только можем сами использовать полученные знания, но и показывать другим полезность компьютеризованной географии в широком спектре исследований. Эти знания пригодятся нам в новых путешествиях, в серьезных приложениях реального мира, и в данной главе мы рассмотрим, как следует планировать каждый проект, чтобы он был успешным.
Главная тема главы - проектирование: выбор инструментария, определение объектов и их отношений, выбор области исследования, оценка данных, — все, что нужно для построения работоспособной ГИС. Важность хорошего проектирования очевидна: большинство проблем с неработоспособными или плохо работающими ГИС проистекают из некачественной разработки. Система не даст ожидаемых результатов при плохо организованных данных, некорректных моделях данных или ограничениях функциональности программного обеспечения; иногда менеджеры системы недооценивают временные затраты, необходимые для создания БД.
С другой стороны, качественно спроектированная система может использоваться не на полную мощность, либо из-за ее сложности, либо просто из-за незнания персоналом всего потенциала системы. Первоначально полезные системы могут потерять свою актуальность из-за старения программного и аппаратного обеспечения, данных или методики работы, которые снижают гибкость системы в изменяющихся условиях. Наконец, возможны случаи провала из-за изменения организационной структуры в связи с внедрением новой технологии в среду, основанную на ручной работе. Многое из того, что мы можем сказать о хороших системах, узнается на опыте неудачных систем, - подобно тому, как успех в бизнесе зависит от способности учиться на чужих ошибках.
Хотя некоторые ГИС создаются для внутреннего использования организацией-разработчиком, большинство систем создается на заказ, для других организаций, использующих их в своей работе. По этой причине мы уделим основное внимание организационной стороне проектирования ГИС. Другая причина в том, что успешность системы в научно-исследовательском окружении во многом основана на тех же критериях, что и успех в коммерческой среде. Если вы можете создать систему, работоспособную в условиях финансово-чувствительной коммерческой среды, то сможете достичь успеха и в других обстоятельствах. Успех проекта зависит не только от знания моделей данных и алгоритмов, но и от умения организовать работу для сборки их в нечто единое и подчиненное конечной цели системы, в чем знание теории бизнес-ориентированных систем и исследования операций может быть не менее ценным, чем навыки географа. Так что, закончив эту главу, следует не почивать на лаврах, а продолжать начатое путешествие.
ЧТО ТАКОЕ ПРОЕКТИРОВАНИЕ ГИС?
Первые ГИС стали появляться в 1960-х годах. Одни из них создавались в целях эксперимента в университетах, другие - как оперативные системы, подобно большинству создаваемых сегодня систем. Большинство из них не имели успеха: в одних случаях они вообще не работали как аналитический инструмент, в других - давали ошибочные результаты, в третьих - просто зависали.
Такие системы не выжили главным образом потому, что были плохо спроектированы как программные системы. Однако сегодня можно наблюдать все большее число успешно работающих пространственно-аналитических средств, которые могут и не быть чисто географическими информационными системами, но выполняют свои задачи эффективно и за умеренную цену.
Большинство проблем, связанных с ГИС сегодня, - не технические. На самом деле, современный уровень возможностей программ существенно превосходит требования сообщества пользователей, особенно в коммерческих приложениях. Главная проблема - частое несоответствие возможностей программного обеспечения и нужд пользователей: в данных, в анализе, в обучении, в признании пользователями.
К сожалению, проблемам разработки до сих пор уделяется недостаточно внимания. Поэтому мы и рассмотрим проектирование ГИС, в основном как вариант общей разработки программного обеспечения, который может быть полезным для создания успешной ГИС.
НЕОБХОДИМОСТЬ ПРОЕКТИРОВАНИЯ ГИС
Проектирование не является гарантией успеха, недостижение которого может быть следствием и других причин, например, неадекватного маркетинга. Но в большинстве случаев оно позволяет увеличить шансы на успех.
Конечно, ошибки в программах обычно не так опасны, как ошибки в ракетных двигателях, но действие их может быть незаметным, а поэтому более коварным, как в смысле обнаружения их присутствия, так и поиска того места программы, в котором кроется ошибка. Ошибки могут приводить к зависанию компьютера и потере данных. Воздействие даже одной простой ошибки может быть существенно усилено огромным количеством последующих операций над испорченными данными, и это распространение может продолжаться довольно долго, пока не будет обнаружено явное расхождение ожидаемого и получаемого. Значение проектирования геоинформационных систем особенно велико, поскольку они относятся к разряду наиболее сложных коммерческих программных систем.
Даже если вычислительная точность соблюдена и данные введены без ошибок, нельзя забывать о существовании различных групп потенциальных пользователей и специфике задач, решаемых этими группами.
В связи с этим мы должны понимать, что, особенно в многопользовательской организации важно учесть потенциальных пользователей на стадии проектирования. Так, например, системы в общественном секторе создаются для ответов на запросы о довольно больших территориях, таких как районы, области, регионы. Тем не менее, вы можете обнаружить, что многие государственные организации разрабатывают крупные базы данных без особой консультации или взаимодействия с другими заинтересованными сторонами. Такой близорукий подход дублирует усилия, приводя к ненужному расходу времени и денег [DeMers and Fisher, 1991). Проблема - в незнании других потенциальных пользователей тех же самых БД. Многие ГИС разрабатывались без предварительной оценки использования системы или вообще без указания потенциальной клиентуры. В качестве примера можно привести Региональную программу оценки окружающей среды на основе спутниковых данных, запущенную в штате Северная Дакота в 1970-х годах, когда стала очевидной полезность в оценке окружающей среды с применением данных со спутников LANDSAT. Хотя идея имела хорошее научное обоснование, клиентуры для использования результатов программы не существовало, что привело в конце концов к прекращению государственного финансирования этой программы.
Касаясь второго вопроса - удовлетворения системой потребностей пользователей, - мы рассматриваем главным образом возможности программного обеспечения, требования к данным и соответствие задачам организации. Первые два пункта указывают на то, что знание функциональных возможностей системы и конструирования баз данных очень важно для долговременного функционирования ГИС. Перед тем, как будет приобретена ГИС с ее моделью данных и аналитическими способностями, должны быть четко определены потребности клиента в обработке пространственных данных. Например, задачи учета земель легче решаются с использованием векторной модели данных, тогда как задачи поверхностного моделирования или постоянного обновления данных на основе космоснимков могут быть легче удовлетворены системой с растровой моделью данных. В обоих случаях требования обработки данных диктуют тип используемой системы и ее аналитические возможности.
Иметь соответствующие задачам организации данные и программы - еще не всё. Система должна также соответствовать профилю работ организации и ее персоналу. Как сами ГИС различаются по тому, что и как они делают, так и организации, использующие ГИС, различаются в своей деятельности. Университетская среда будет скорее всего местом сложных экспериментов на грани возможностей ГИС. Кроме того, там часто меняются исследуемые вопросы, а данные системы и аналитические потребности весьма переменчивы или едва определены [Burrough, 1986]. Частая смена персонала с различным уровнем подготовки, бюджетные ограничения, сроки выполнения исследовательских программ, - все это требует определенных параметров от университетской ГИС. Напротив, коммерческие организации имеют больше денег, более стабильный персонал, более определенные и более узкие рамки приложений. Кроме того, аналитические возможности могут быть менее широкими по сравнению с институтами. Организации, финансируемые государственными органами, имеют потребности в данных и анализе, вытекающие из их полномочий.
Бэрроу [Burrough, 1987] дает отличный набор общих идей, связанных с работой ГИС в этих различных средах. И хотя такие обобщения создают хороший фундамент для принятия решений, немногие организации полностью вписываются в данную структуру. Следует учитывать, что каждая организация уникальна и должна рассматриваться именно так для наилучшего использования ГИС. Эта точка зрения позволяет нам также считать организацией наш собственный проект, особенно если он выполняется группой людей, занятых лабораторной работой, независимым исследованием или работой по гранту.
ВНЕШНИЕ И ВНУТРЕННИЕ ВОПРОСЫ ПРОЕКТИРОВАНИЯ ГИС
Прежде всего нам нужно договориться о терминах. Рисунок 15.1 показывает, что процесс проектирования в целом распадается на две основных составляющих - системное проектирование и проектирование программного обеспечения.
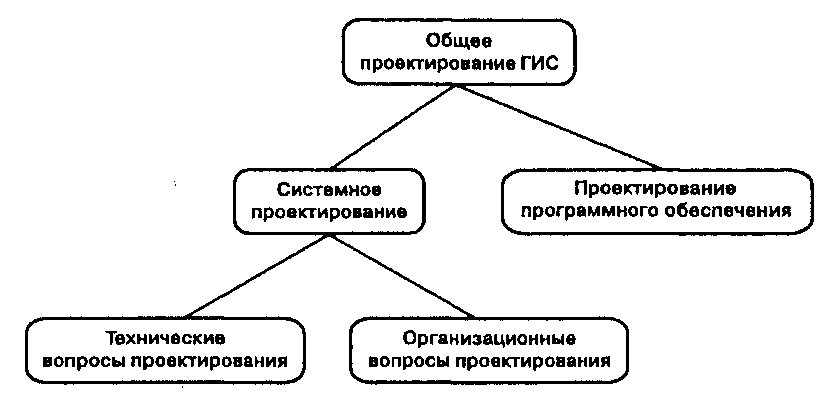
Рисунок 15.1. Процесс проектирования ГИС.
Проектирование программного обеспечения требует досконального знания структур данных, моделей данных и программирования. Эта работа относится к наиболее высоко оплачиваемым в данной профессии и требует соответствующей компьютерной технической или научной степени вдобавок к знанию основ ГИС. Но нашим главным интересом является второй вопрос.
Системное проектирование рассматривает взаимодействие отдельных людей, групп людей и компьютеров внутри организаций [Yourdon, 1989]. Этот аспект расширяет определение того, что такое ГИС. Это не только вычисления. Это также влияние внедрения системы на людей, на то как они выполняют свою работу, и как это, в свою очередь, влияет на функционирование самой организации. Автомобильная промышленность прошла путь от индивидуальной сборки автомобилей через конвейерное производство до внедрения роботов. Геоинформационные системы, как многообещающая технология, могут оказать сходное влияние на коммерческие, государственные и научные организации. Подобно тому, как компьютерные программы редактирования текста и справочные системы библиотек радикально изменили способ написания научных статей, так и ГИС фундаментально изменяют работу организаций, специализирующихся
Проектирование
ГИС
на анализе пространственных данных. Внедрение новой технологии требует дополнительного обучения персонала, денег на приобретение программного и аппаратного обеспечения, оно изменяет потоки информации внутри организации и, следовательно, изменяет структуру самой организации. И теперь, когда появляется всё больше крупных БД, мы должны уделять больше внимания целостности и качеству данных, а доступ к ним многих пользователей поднимает актуальность мер безопасности и контроля качества внутри организации.
Системное проектирование ГИС может быть разделено на две взаимодействующие части: техническое проектирование (technical design) (внутренние вопросы) и организационное проектирование (institutional design) (внешние вопросы). Внутренние вопросы чаще всего относятся к функциям системы и БД: Будет ли система работать так, как это требуется? Сможем ли мы получить ответы на вопросы, на которые нам нужно получить ответ? Имеются ли у нас данные в нужном формате? Есть ли у нас сотрудники, имеющие должную подготовку для эксплуатации системы? Сможет ли она меняться при изменении наших потребностей? Таковы некоторые наиболее общие вопросы технического проектирования. Организационные вопросы включают следующие: Имеем ли мы достаточно финансирования для обеспечения длительного функционирования системы? Можем ли мы получить данные за приемлемую цену? Нужно ли нам привлекать прикладных программистов для адаптации программного обеспечения? Получим ли мы достаточную поддержку от поставщиков программ? Будем ли мы нести ответственность на основании закона за ошибки в нашем анализе? Учтены ли цели, находящиеся за пределами окончания выполнения анализа в ГИС? Все эти вопросы важны для организационного проектирования.
Техническая сторона проектирования не может быть отделена от организационной. Даже прекрасная с технической точки зрения работа ГИС должна считаться неудачей, если мы теряем поддержку нашей организации или внешнего спонсора. Причины Могут быть самыми разными, в том числе и мнение руководства о чрезмерности расходов на ГИС. И конечно, если ваша система не может дать ответы на задаваемые вопросы, поддержка организации может быть очень быстро утрачена.
РАЗРАБОТКА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Новая дисциплина, называемая разработкой программного обеспечения (ПО) (software engineering), появилась в информатике относительно недавно. Проблемы в создании различных программ часто аналогичны тем, что возникают на стадии реализации ГИС. Целью разработки ПО является создание программ, успешно решающих или помогающих решать задачи, которые прежде выполнялись вручную. В качестве примера можно привести текстовый редактор. Он должен позволять набирать и редактировать текст, проверять правописание, вставлять в текст иллюстрации, изменять шрифт, выводить текст на печать. Ранние программы имели лишь часть этих функций, в то время как сегодня все они являются стандартными для большинства программ редактирования текста. Как показывает этот пример, главная задача - не просто написать хороший программный код, но прежде всего знать, что именно кодировать.
При реализации ГИС, перед началом процесса, мы также должны понять потребности пользователя, включая потребности в анализе, обучении, соответствии применяемых аналитических методов общим целям организации. Перед началом написания программного кода мы, как проектировщики ГИС, должны подготовить информацию по структурам данных и моделям, программам, имеющим нужные аналитические возможности при наименьшей цене, системе, наиболее соответствующей целям организации, и требованиям обучения персонала.
Принципы проектирования систем
Среди первых идей, возникших в области проектирования систем была идея жизненного цикла проекта (project life cycle). В большинстве организаций одновременно выполняются несколько проектов. Для каждого проекта мы должны решать, что и когда должно делаться, и кто ответственен за исполнение. Поскольку каждый проект имеет начало, середину и окончание (как мы надеемся ;-), мы можем сказать, что он имеет жизненный цикл, который, в свою очередь, диктует действия и организационную структуру, ведущие к успешному завершению. Если вы работаете над одним-единственным проектом, главные принципы остаются теми же, хотя детали и различаются.
Возможен существенно иной подход к реализации проекта, с иным стилем руководства, иными задачами и другим типом участвующего персонала. Жизненный цикл такого проекта часто развивается в очень гибкой обстановке. Это в особенной степени относится к исследовательским проектам, в которых цели могут меняться в зависимости от промежуточной информации. Организации, больше ориентированные на бизнес, обычно используют более формальный и структурированный подход. При большой длительности проекта или частой смене персонала может быть полезным изменение структуры жизненного цикла проекта для учета нужд новых работников, их роли в проекте.
Выполняете ли вы проект самостоятельно, внутри небольшой группы или внутри большой организации, должна быть установлена методика выполнения, обеспечивающая успешное завершение работы. В качестве простого примера жизненного цикла проекта можно привести курсовую работу. Она может потребовать полевой работы, вычислений, анализа, обзора литературы, подготовки результатов, написания. Вы не начинаете (я надеюсь) с написания, пока не завершите подготовительных этапов, - нужен определенный порядок выполнения для достижения конечного результата. Если вы выполняете работу в одиночку, то может быть достаточным определение подзадач и порядка их решения. В условиях многих взаимосвязанных проектов должны быть решены две другие задачи, которые вместе с первой можно формализовать так:
Определить действия в проекте и последовательность их выполнения.
Согласовать данный проект с другими проектами организации.
3. Определить точки принятия решений о запуске и остановке отдельных этапов проекта.
Важно отметить, что жизненный цикл проекта - только общая его основа, главные решения принимает руководитель. Многие важные аспекты работы организации (внешняя конкуренция, поддержка работников, обеспечение здоровой атмосферы и т.д.) относятся, в принципе, к компетенции руководителя. Жизненный цикл проекта обеспечивает ориентиры для поддержки принятия правильных решений в должное время [Yourdon, 1989].
Линейная модель разработки системы
Среди первых методов реализации жизненного цикла проекта была линейная модель (waterfall model) проектирования системы [Boehm, 1981; Royce, 1970] (Рисунок 15.2). Возможны различные состав и число шагов, которые в целом покрывают: определение требований пользователя, определение функциональных потребностей, системный анализ, детальное проектирование, тестирование отдельных модулей, подсистем и системы в целом.
Линейная модель обеспечивает упорядоченное движение от анализа требований до ввода информационной системы в эксплуатацию. Обычно она проходит от концептуального проектирования через проектирование программ и написание кода до отладки и окончательного тестирования. При разработке ГИС с использованием линейной модели имеются некоторые проблемы. Поскольку модель требует завершения каждого этапа перед началом следующего, любая задержка на одном этапе замедлит создание всей системы [Yourdon, 1989]. То есть, в контексте ГИС, мы не сможем начать ввод данных, пока не получим все требования пользователя. Хотя это требование кажется вполне обоснованным, новые требования часто обнаруживаются в самом конце этапа их определения, и многие дни или недели, которые могут использоваться для ввода данных, будут потеряны в ожидании абсолютной уверенности, что все требования известны.
Рисунок 15.2. Линейная модель жизненного цикла системы.
Другой проблемой данного метода является его линейность. Хотя нам желательно последовательное развитие нашей ГИС, почти каждая реализация сталкивается с трудностями. И, как оказывается, легче внести поправки в несовершенную систему, которую уже видели в работе, чем предсказать все возможные проблемы до начала реализации проекта. Вы, конечно, знаете, что гораздо легче написать черновик и отредактировать его, чем сразу написать целую курсовую работу. Кроме того, клиенты часто пренебрегают важными деталями до начала работ или открывают новые применения ГИС по мере наблюдения за реализацией системы.
Может также измениться ситуация с финансированием, в результате чего к проекту могут быть предъявлены иные требования или урезаны дорогостоящие части системы. Следуя линейной модели, мы будем скорее всего иметь завершенную или почти завершенную систему как раз тогда, когда обнаружим, что нужно добавить что-то еще или устранить сделанные на прежних этапах ошибки.
Мифический человеко-месяц
Ошибки, обнаруживаемые после завершения системы могут показаться не такими уж важными. Но допустим, что мы создали работоспособную систему для внешнего заказчика, и теперь занимаемся другими проектами. Через несколько месяцев звонит клиент и сообщает, что ГИС не позволяет преобразовывать дорожные мили в мили расстояния на карте. Оказывается, что мы забыли включить в программное обеспечение функцию, выполняющую эту операцию. А тем временем, люди, занятые в этом проекте, точнее наши эксперты по транспорту, сменили место работы. Но наша компания остается ответственной за обеспечение недостающей функции. Подумайте о возможных последствиях этой ситуации, которая легко подпадает под заголовок идеи "мифический человеко-месяц", выдвинутой Бруксом [Brooks, 1975].
В простейшей форме эта идея утверждает, что ошибка в одну денежную единицу на первом этапе обойдется в сумму от 400 до 4000 единиц на пятом этапе.
Другими словами, ошибки, которые могли быть легко исправлены вначале, вызывают значительные трудности на более позднем этапе. Наиболее распространенным ответом на такое несчастье является "денежное вливание". Таким образом, ответом на недостачу транспортного модуля для ГИС нашего клиента могло бы быть выделение большой группы людей на решение этой задачи. Однако, как предсказывает Брукс, это просто не сработает, эти люди скорее всего не будут знакомы с данным проектом, и ни один из них не будет иметь опыта построения транспортных модулей. Следовательно, нужно потратить время на обучение. Это не только неэффективный способ работы с людьми, но и приостановка других проектов. И пока мы пытаемся срочно повысить компетенцию работников для разработки транспортного модуля, клиент не может выполнять некоторые задачи, для решения которых ГИС приобреталась.
Концепция мифического человеко-месяца может применяться и в научных приложениях. Поскольку цели в таком случае часто плохо определены, а также из-за быстрой смены работников-студентов, строго модульный и линейный подход к проектированию часто оказывается неэффективным. Ниже мы рассмотрим возможную альтернативу.
Некоторые общие характеристики систем
Имеем ли мы дело с программной системой или ГИС-проектом, чем более они специализированы, тем менее приспособляемы для решения новых задач. Разрабатывая, например, ГИС для работы с ДДЗ, вы скорее всего воспользуетесь моделями данных и методами, специфичными для растра. Если же в дальнейшем вы решите включить модель гравитации, использующую векторные данные, инструментарий вашей системы не будет соответствовать новым задачам, и вам придется добавить к ней возможности работы с векторными данными и провести обучение пользователей. Это в чем-то похоже на создание новой системы и помещение ее рядом с уже существующей.
Размер системы тесно связан с количеством используемых ресурсов, — чем больше система, тем больше ресурсов нужно для ввода данных, их анализа и администрирования, устройств для вывода результатов, управляющего персонала, следящего за многими этапами анализа.
К счастью, системы могут быть разбиты на составляющие части, каждой из которых можно управлять по отдельности, подобно отдельному проекту. Это другая характерная черта систем, имеющая первостепенную важность для крупных систем. С ней сильно связана также идея о том, что многие системы, возможно даже, большинство, имеют тенденцию расти.
Поэтому, даже если ваша ГИС первоначально выполняла лишь несколько аналитических задач, по мере роста знаний, мастерства персонала и признания полезности системы управляющим звеном и клиентами, система должна будет расти для соответствия изменившимся условиям. В действительности, чем успешнее ее работа, тем больше вероятность роста. Нужно помнить и том, что успех проекта часто достигается умением "преподнести" его заказчику и спонсорам. Большинство коммерческих систем служат многим людям, следовательно, имеет значение знание их организационного окружения.
ОРГАНИЗАЦИОННОЕ ОКРУЖЕНИЕ ГИС
Ни одна ГИС не работает "в вакууме". Выполняя свою работу, вам приходится учитывать интересы других пользователей системы, выполняющих свои проекты, или координировать свои собственные усилия с коллегами по проекту. При внешнем финансировании нужно учитывать цели и задачи спонсора. Программное и аппаратное обеспечение часто также поступают со стороны. Как видите, в большинстве проектов имеются многие участники, как внутренние, так и внешние.
Связь между системой и внешним миром
Рисунок 15.3 иллюстрирует упрощенную модель отношений между ГИС (система) и внешним миром. Внутри системы происходит взаимодействие между людьми, ответственными за повседневную работу ГИС, с теми, кто эксплуатирует систему, и теми, кто отвечает за управление проектом. Это показано на рисунке двухсторонней внутренней стрелкой. Остальные стрелки показывают связи с внешним миром. Теперь определим участников и их взаимодействие.
Рисунок 15.3. Внутренние и внешние участники.
Внутренние участники
Система включает три основные группы участников, каждая - со своими задачами.
Пользователи системы - те, кто используют ГИС для решения пространственных задач - обычно хорошо разбираются в ГИС, хотя возможно, в какой-то одной системе. Их основные задачи это оцифровка, проверка ошибок, редактирование, анализ исходных данных, получение ответов на запросы. Пользователям системы обычно требуется дополнительное обучение вследствие значительных изменений как в программном обеспечении, так и в требованиях к системе на выполнение анализа. В большинстве работ эта группа - наименее постоянная, в нее часто входят новые сотрудники, замещающие тех, кто перешел на другие должности.
Операторы системы ответственны за ее ежедневную работу, чаще всего они решают задачи, позволяющие пользователям системы работать наиболее эффективно. В их обязанности входит устранение неполадок при зависаниях программ, или когда сложность анализа требует дополнительных ресурсов. В большинстве случаев они также отвечают за обучение пользователей. Это подразумевает, что операторы системы часто имеют опыт работы пользователей. Они знают как аппаратуру, так и программы, чтобы быть в состоянии производить их обновление. Вдобавок к функциям администраторов системы они часто являются и администраторами баз данных, следя за правами доступа и целостностью БД.
И пользователи и операторы системы действуют в рамках большей организации, часто называемой спонсором системы. Спонсор выделяет финансирование для приобретения аппаратного и программного обеспечения и выплаты зарплаты. Он обеспечивает также политическую жизнеспособность системы. Иными словами, если нет достаточно крупной организации, то, вероятно, нет и ГИС. Спонсором системы может быть исследовательская группа университета, получившая грант для реализации проекта, или государственная организация, которой ГИС требуется для своей работы, или коммерческая организация, которой ГИС нужна для работы с клиентами. Финансирование и обеспечение жизнеспособности системы требуют, чтобы спонсор предпринимал долгосрочное планирование.
Внешние участники
Поскольку в большинстве установленных сегодня систем используется покупное программное обеспечение, нашим первым внешним участником будет поставщик ГИС, специализирующийся на разработке и распространении ПО ГИС одного или нескольких типов, а также его сопровождении и обновлении. Поставщики ПО могут работать совместно с поставщиками аппаратного обеспечения, для создания систем "под ключ". Во многих случаях поставщик обеспечивает и обучение персонала работе с системой, которое может проводиться силами специализированных учебных центров, сотрудничающих с поставщиками.
Поставщики данных, второй внешний участник в мире ГИС, могут быть частными или государственными (общественными) организациями. Частные компании поставляют самостоятельно сгенерированные данные или данные из общедоступных источников, модифицированные для конкретного пользователя (например, преобразованные в нужный пользователю формат). Частные компании чаще всего являются коммерческими, то есть поставляют данные с добавленной стоимостью.
Государственные агентства поставляют данные для больших участков или всей территории страны. Во многих случаях эти данные создаются ими для их же использования, но при этом могут поставляться также и внешним пользователям, обычно за некоторую цену, но для некоммерческого использования данные могут поставляться и бесплатно. Некоторые источники данных можно найти в Приложении 1.
Еще одна группа внешних участников - разработчики приложений -становится все более значимой по мере роста сложности программного обеспечения ГИС. Они являются опытными программистами, создающими пользовательский интерфейс для уменьшения потребности в опытных специалистах по работе с ГИС при выполнении каждодневных задач. Во многих случаях программирование ведется на макроязыках, поддерживаемых поставщиками ГИС для разработки приложений, избавляющими от необходимости использования традиционных языков программирования*. В прошлом большинство разработчиков приложений были внутренними участниками (прикладными программистами), имеющими многолетний опыт работы с ПО ГИС и знающими его аналитические возможности. Сегодня же их функции отходят множеству фирм, специализирующихся на создании приложений на заказ. Помимо прочего, это позволяет снизить расходы на обучение новых пользователей системы за счет более низких требований к знанию того, что скрыто за интерфейсом.
Наконец, есть системные аналитики ГИС. Эти внешние участники специализируются на проектировании систем. Чаще всего они являются частью группы профессионалов, ответственных за определение целей и задач системы внутри организации, "тонкую настройку" системы для обеспечения ею необходимых аналитических методов, гарантированную интеграцию системы в рамках организации. Короче говоря, системные аналитики действуют как штурманы для организаций, использующих ГИС. Обычно они предоставляются консультационной фирмой, специализирующейся на реализации ГИС для заказчиков, но могут быть и работниками компании-поставщика ГИС.
СТРУКТУРИРОВАННАЯ МОДЕЛЬ ПРОЕКТИРОВАНИЯ
Техническое проектирование
В общем виде, мы разделили процесс проектирования ГИС на разработку программного обеспечения и проектирование системы (Рисунок 15.1), которое может быть далее разделено на техническое и организационное проектирование.
*
В настоящее время наблюдается обратная
тенденция - расширение использования
универсальных языков программирования
для создания приложений ГИС, обусловленная
развитием стандартных сред визуальной
разработки приложений. Это избавляет
программистов от необходимости изучать
язык каждой системы, а также облегчает
интеграцию ГИС с другими программными
средствами. — прим.
перев.
образом с выполнением тех видов анализа, которые система должна обеспечивать. БД системы это набор электронных карт и соответствующих компонентов, над которыми интерактивно работают программное обеспечение и персонал для реализации целей проекта.
Рисунок 15.4. Упрощенная модель проектирования ГИС.
Любой проект содержит движение от концептуального уровня к детальному и далее - к уровню реализации (Рисунок 15.4) [Marble, 1994]. При продвижении от этапа концепции к этапу реализации растет уровень знания функциональности и БД, и наоборот, до того, как станут ясны детали, нам нужно выработать концепцию (идею) системы и найти способ ее реализации. Тщательное концептуальное проектирование - важный первый шаг в создании любой хорошей ГИС.
Концептуальное проектирование
Мы начинаем проект, делая самые общие утверждения о том, что система должна делать, какие задачи решать, об общих типах данных и т.д. Хорошее концептуальное представление позволяет планировать дальнейшее развитие и изменение системы. Но в отличие от линейной модели, концепция должна быть достаточно гибкой для учета предстоящих изменений в целях, доступности данных, персонале и требованиях управления. Таким образом, на стадии концептуального проектирования существенной является
Проектирование
ГИС
независимость от конкретного ГИС-пакета, так как выбранное ПО может ограничить нашу свободу в определении целей вследствие собственных ограничений функциональности и используемых в ней моделей данных.
При концептуальном проектировании определяется общий вид всей системы и ее потребности в данных. Если по какой-либо причине требования изменятся, то в это время мы сможем изменить общий вид. Вместо использования концептуального представления как жесткой структуры мы используем его как стартовую точку для выбора начального направления, что позволит нам ставить в дальнейшем адекватные вопросы. Вдобавок к независимости от программного обеспечения, концептуальное представление позволяет нам определить все возможные источники получения данных. Хотя ГИС не должна быть движима исключительно лишь данными, ее функциональность и даже жизнеспособность могут в значительной степени определяться доступностью, ценой и качеством данных для решения поставленных задач. Это значит, что нам может потребоваться использование разнородного ПО или выдвижение предложения об изменении бюджета проекта для приобретения дополнительных данных. Возможно даже, что мы поймем, что ГИС не является практически осуществимым или жизнеспособным решением для данной организации.
Психологические проблемы внедрения ГИС
Главным препятствием при внедрении любой информационной технологии, будь то текстовые процессоры, бухгалтерские системы или ГИС, является психология людей. Они нередко оказываются причиной низкой отдачи от вложений организации в это новшество, что чаще всего обусловлено фундаментальными изменениями в работе. Даже простые текстовые редакторы могут обескуражить людей, не знакомых с работой на компьютере и привыкших к пишущей машинке. Они будут сопротивляться всякой попытке внедрения компьютеров в их работу. Хотя, конечно, есть и такие, кто активно приветствует автоматизацию деятельности. Аналогичная проблема возникает при внедрении покупной бухгалтерской системы, созданной без внимания к людям, которые должны использовать ее ежедневно.
Хотя программа сама по себе может быть пригодна для выполнения возложенных на нее задач, надо учитывать, что с ней должны работать люди. Те же, кто ожидает, что компьютер должен выполнять все основные задачи точно также, как они делали это до его внедрения, могут прибегать к прежним методам, пока система не будет изменена, или пока они не найдут себе другое место работы.
Даже если ПО соответствует потребностям отдельных пользователей, оно не может гарантировать немедленного одобрения. Требуется некоторое время на его освоение, в течение которого возможно снижение производительности работы организации. Таким образом, обучение имеет две стороны: персонал должен иметь желание и возможность учиться использовать систему, а организация должна обеспечить соответствующее обучение.
Наконец, есть еще одна проблема. Часто в организации есть люди или группы людей, знания и опыт которых гарантируют им их место работы. Но, поскольку ГИС, как и любая информационная технология, открывает двери для свободного потока информации и, по сути, позволяет многим другим решать задачи этих людей, они могут воспротивиться ослаблению их власти и, следовательно, внедрению системы. Эта причина часто объясняет трудности внедрения ГИС во многих организациях.
Вопросы стоимости и отдачи
Помимо желания персонала работать с системой необходимо еще желание администрации вкладывать деньги в ее создание и внедрение. Для этого администрация должна быть убеждена, что эффект оправдает вложения. В целом, управленцы считают, что нет надежного способа определения возврата инвестиций. Мало известно заранее о точной стоимости реализации ГИС и еще меньше - об экономическом выигрыше от этой реализации. Это отчасти объясняется тем, что число и сложность карт, которые вводятся в систему, радикально изменяются. Кроме того, поскольку на разработку БД уходит большое время, отдача в начальный период от этих вложений часто минимальна. В этом случае руководство организации должно быть уверено, что долговременные преимущества все-таки существуют. Среди наиболее успешных способов убеждения администрации является указание на положительный опыт внедрения ГИС в подобных же организациях. Другой вариант - узнать требуемое спонсором отношение отдача/цена и попытаться "вписаться" в него [Tomlmson, n.d.]. В таком перестраховочном подходе цена специально завышается, чтобы избежать на стадии реализации превышения объявленной стоимости.
Модели требований к данным и к приложениям
Структурированное техническое проектирование может быть двух видов. Модель потребностей данных (data requirements model) основана на идее, что наличие определенных данных влияет на то, какой анализ можно провести. Модель обычно проходит этапы концептуального, логического (логические связи между данными) и физического проектирования БД. А модель потребностей приложений (application requirements model) основана на той идее, что система движима анализом, который она должна выполнять. Эта модель идет от общего функционального анализа к проектированию приложений более высокого уровня и проработке конкретных деталей выполнения анализа. Но поскольку данные и приложения взаимосвязаны, ГИС лучше представлять движимой обоими этими факторами*.
ФОРМАЛИЗОВАННАЯ МЕТОДОЛОГИЯ ПРОЕКТИРОВАНИЯ
ГИС
Предпринимались несколько попыток создания и совершенствования моделей проектирования ГИС, начиная с той, что была разработана после тщательной оценки реализации одной системы [Calkins, 1982], которая была в дальнейшем усовершенствована в связи с ростом объема литературы по административно-информационным системам (MIS) [Johnson, 1981]. К тому времени были разработаны уже несколько систем поддержки разработки ПО, которые могли сразу же использоваться в области ГИС, с оговоркой, что проектирование ГИС фокусируется не только на программах, но и на базах данных, с которыми программы работают, причем с учетом организационного контекста для тех и других.
Спиральная модель: Быстрое создание прототипов
На основе одного из подходов к разработке ПО [Boehm, 1981,1986,1988] был разработан и реализован гибкий многоуровневый процесс проектирования. Эта спиральная модель [Marble, 1994] выделяет три уровня детальности и три задачи проектирования ГИС: сбор, организацию и анализ информации (Рисунок 15.5). Первый уровень - начальная модель - наиболее общая основа обсуждения реализуемости ГИС. Второй уровень -концептуальная модель - включает анализ потребностей и первые обсуждения проектирования БД. Третий уровень - детальное проектирование - занимается вопросами конкретного ПО для реализации системы.
*
Известная формула Вирта "программы
= алгоритмы + данные" — прим.
перев.
модель
и общие вопросы движения по спирали. Рисунок
15.6 показывает последовательность
принятия решений. На первом шаге
информация от клиента используется
для определения целей организации, ибо
реализация ГИС, не отражающая понимание
общих целей организации, возможно,
выраженное как декларация производимых
продуктов и услуг, не будет принята
администрацией. Второй шаг (1.1.2)
-определение того, что должна делать
ГИС. Часто это трудно сделать для
некоторых потенциальных пользователей,
чей интерес к ГИС происходит от высокой
оценки данной технологии в деловых
кругах. Многие интересуются ГИС лишь
потому, что кто-то еще использует ГИС.
В этот момент мы должны спросить
потенциального пользователя, действительно
ли ему нужен анализ. Вполне возможно,
что ему не нужен сложный анализ и вполне
подойдет САПР или система компьютерной
картографии.
Рисунок
15.6 показывает последовательность
принятия решений. На первом шаге
информация от клиента используется
для определения целей организации, ибо
реализация ГИС, не отражающая понимание
общих целей организации, возможно,
выраженное как декларация производимых
продуктов и услуг, не будет принята
администрацией. Второй шаг (1.1.2)
-определение того, что должна делать
ГИС. Часто это трудно сделать для
некоторых потенциальных пользователей,
чей интерес к ГИС происходит от высокой
оценки данной технологии в деловых
кругах. Многие интересуются ГИС лишь
потому, что кто-то еще использует ГИС.
В этот момент мы должны спросить
потенциального пользователя, действительно
ли ему нужен анализ. Вполне возможно,
что ему не нужен сложный анализ и вполне
подойдет САПР или система компьютерной
картографии.
Задачи всех возможных пользователей должны быть учтены при решении о целях ГИС. Необходимо идентифицировать потребности каждого пользователя. Хорошим методом является выяснение того, какие конечные
Рисунок 15.6. Шаги процесса проектирования. Начальная модель как последовательность решений о продолжении или прекращении внедрения ГИС в организации.
пространственно-информациониые продукты (spatial information products (SIP)) пользователи хотели бы получить от системы. Нам нужно определить отношение между этими пространственно-информационными продуктами, требуемыми каждым пользователем в организации и задачами, которые каждый из них должен реализовывать. Каждый такой продукт требует привлечения определенных исходных данных. Кроме того, переходя от пользователя к пользователю мы объединяем их частные представления (local views) о том, что должна делать ГИС в общее представление (global view), что часто делается администрацией для удовлетворения более крупных целей организации. По завершению данного этапа обычно составляется отчет о требованиях на уровне выходных продуктов для потенциальных пользователей, чтобы подтвердить наше понимание рассмотренных вопросов.
Одновременно с определением целей проводится анализ ограничений разработки (шаг 1.2.1), которые включают бюджет реализации и дальнейшей поддержки проекта, время для достижения конечного результата, доступность и стоимость данных для проекта. Важно различать каждое ограничение как финансовое, временное или связанное с потребностями моделирования. Возможны ограничения и по аппаратному обеспечению (например, организация использует только персональные компьютеры). В случае недоступности данных по финансовым соображениям, например, из-за высокой стоимости снимков со спутников, следует поискать альтернативные источники данных или применить другие методы анализа. Для каждого ограничения, когда оно обнаруживается, мы должны рассмотреть обходные пути, а не просто оставлять его "на потом". Затем мы переходим к шагу 1.2.2, сравнению потребностей пользователей с имеющимися ограничениями. Другими словами, мы решаем, не окажется ли ГИС роскошью, давая ответ на пятьсот долларов к задаче на пять долларов. Продолжение проекта возможно только тогда, когда требуемые информационные продукты, деньги, время и доступность данных позволят использовать ГИС.
Следующие шаги (1.1.3 и 1.2.4) напрямую используют результаты сравнения потребностей и ограничений. Переопределение целей, связанных с ГИС, и/или ограничений разработки (1.1.3) могут потребовать разрешения конфликтов при формировании баланса потребностей и ограничений для определения реализуемости ГИС. Баланс часто трудно достижим, поэтому вам, возможно, придется создать иерархическое представление потребностей и ограничений, присвоив им некоторые приоритеты, включая и стоимость системы в целом. Когда наиболее значимые требования к ГИС являются также и наиболее дорогостоящими при реализации, компромисс может быть достигнут поиском альтернативного, менее дорогого решения или снижением требований для уменьшения стоимости. В некоторых случаях решением может быть отсрочка слишком дорогих работ по ГИС в ожидании возможности ослабления ограничений или упрощения приложений.
Стоимость реализации - очень важное, но не всегда главное ограничение, особенно в коммерческой среде, где более значима возможная прибыль, которая и анализируется на шаге 1.2.4. В затраты входят приобретение данных, аппаратного и программного обеспечения и их сопровождение, обучение и работа персонала, ввод данных (наиболее трудноопределимая статья расходов), выделение помещений и многие другие вопросы [Aronoff, 1989]. Затраты должны также разделяться на начальные инвестиции и эксплуатационные расходы. Отдачу определить гораздо труднее, но в общем случае ее можно выявить по пяти категориям [Aronoff, 1989]:
1. Большая эффективность новых методов по сравнению со старыми.
Новые некоммерческие продукты и услуга, обычно связанные с более высоким качеством продуктов, производившихся до реализации ГИС.
Новые коммерческие продукты и услуги, включая продажу другим организациям знаний и опыта, связанных с ГИС.
Более высокое качество принимаемых решений (основная движущая сила большинства проектов, которую очень трудно определить количественно).
Нематериальные преимущества, включая четкую современную организацию работы, улучшение коммуникаций, внешнего облика компании и внутренней активности.
Анализ цена/отдача не является точной наукой, однако объем литературы на эту тему, в которой можно подыскать ответы, постоянно растет [Goodchild and Rizzo, 1986; Green and Moyer, 1985; Kenney and Hamilton, 1985, 1986; Kevany, 1986; Laroche and Hamilton, 1986]. И хотя такой анализ может дать некоторое финансовое основание для решения, он редко является главным решающим фактором [Aronoff, 1989]. Часто именно понимание потенциала информационных продуктов ГИС движет администрацией в решении о создании системы, а также и в решениях о плане реализации.
ИНФОРМАЦИОННЫЕ ПРОДУКТЫ ГИС
В значительной степени, информационные продукты ГИС являются результатом анализа, выполняемого программным обеспечением. Каковы же они конкретно - зависит от природы организации, ее целей и опыта работы с системой. Хотя многие организации имеют достаточно хорошо структурированный компактный набор продуктов, другие, особенно исследовательские организации, имеют большой постоянно меняющийся набор возможных продуктов, который может быть даже трудно определить
[Rhind and Green, 1988; Wellar, 1994]. Но и там чаще всего имеется общее представление о том, что ГИС может делать, что она может дать организации.
Как информационные продукты влияют на ГИС
Организации, которые имеют в виду определенную цель, когда рассматривают реализацию ГИС, вполне могут иметь некоторое представление о том, как мог бы выглядеть вывод результатов анализа, даже если у них есть лишь смутное представление о том, как этот анализ мог бы быть проведен.
Кроме того, они, скорее всего, имеют общее представление о том, какие данные могли бы быть частью системы. В действительности, многие организации понимают ценность данных в компьютерной форме даже до того, как они смогут увидеть возможную пользу их анализа. Чтобы добиться от пользователей конкретных описаний пространственно-информационных продуктов, мы должны признавать сильную связь между тем, что входит в систему (наличие данных) и тем, что выходит из нее.
Но поскольку пользователи не могут мгновенно стать знатоками ГИС, наша задача - помочь им определить (но не определять за них) их потребности. То есть, системный аналитик должен действовать отчасти как просветитель, чтобы получить описания продуктов у пользователей. Именно поэтому я настаиваю на важности понимания вами аналитических возможностей ГИС, технологий создания баз данных и управления ими.
Действуя как просветители, мы должны потратить немало времени на выяснение того, как ГИС могла бы наилучшим образом помочь каждому пользователю. Это лучше всего делать персонально, а не общим анкетированием, поскольку личное общение позволяет выяснить те задачи, которые пользователь постоянно решает, и всесторонне объяснить функции, которые ГИС могла бы выполнять соответственно этим задачам. Все материалы, показывающие, что именно пользователь создает (образцы карт, письменные ответы на вопросы, отчеты о решениях, официальные распоряжения и т.д.), будут полезны в установлении хорошего соответствия между существующими продуктами и теми, что будут получены от ГИС. Собирая эту информацию, вам следует помнить, что пользователю более интересно, что может быть получено, нежели как это может быть произведено. Последний вопрос более уместен при приближении этапа реализации системы.
Организация частных представлений
Работая со многими потенциальными пользователями, имеющими различные потребности, полезно проследить отношения между каждым
пользователем и каждым пространственно-информационным продуктом. Томлинсон [Tomlinson, n.d.] предлагает использовать матрицу решений (Decision System Matrix), в которой строки соответствуют пользователям, а столбцы - продуктам; Рисунок 15.7 показывает сильно упрощенную версию.
Рисунок 15.7. Таблица решений. Организация отдельных пользовательских представлений о ГИС в матрицу.
Рисунок 15.8. Объединение представлений. Использование организационной диаграммы для показа частных представлений пользователей о ГИС.
Этот прием позволит не только зарегистрировать пространственно-информационные продукты для каждого пользователя, но и даст информацию для объединения частных пользовательских представлений в более крупное общее представление. Альтернативой матрице решений может быть организационная диаграмма, подобная показанной на Рисунке 15.8. Общее представление в нижней части диаграммы показывает потребности организации в целом, следующий ярус - частные представления пользователей, наверху - продукты, разнесенные по пользователям.
Диаграмма такого типа, как и матрица решений, полезна для объединения частных представлений в общее; обе они могут использоваться также для определения наиболее важных продуктов, в зависимости от частоты упоминания пользователями.
Ошибки проектирования
Ошибки проектирования (design creep) обычно обусловлены отсутствием предварительного изучения системы в организации. Результатом таких ошибок может стать система с возможностями, большими, чем требуется, или наоборот - система, не имеющая всех необходимых функций. Рисунок 15.9а показывает линейный подход к проектированию ГИС, идущий от исследования реализуемости системы через стадию проектирования к реализации системы. Как вы можете видеть, изучение в организации начинается довольно поздно, когда система уже спроектирована, и начата ее реализация. Таким образом, пользователи вынуждены изучать и эксплуатировать систему, которая может не соответствовать их нуждам.
Рисунок 15.9b соответствует более гибкой спиральной модели [Marble, 1994], в которой изучение системы продвигает ее разработку. По мере того, как пользователи лучше узнают возможности системы, они могут описать свои требования к системе задолго до начала ее реализации. Вы можете также видеть, что чем более тщательно организационное изучение, тем более развитой становится система, причем кривая изучения всегда преобладает над кривой проектирования.
Короче говоря, пользователи направляют проектирование ГИС, а не следуют тому, что есть в уже установленной системе. Этот подход позволяет избежать ошибок проектирования, он позволяет системе расти в своей сложности по мере роста потребностей организации.
ОБЪЕДИНЕНИЕ ПРЕДСТАВЛЕНИЙ
В организациях, имеющих много пользователей необходимо учитывать потребности каждого. Эти отдельные наборы потребностей называются частными представлениями (local views) о том, что и как ГИС должна будет делать. После этого мы должны провести объединение частных представлений (view integration), для которого можно использовать весьма удобный метод, заключающийся в проведении парного группирования сходных пользователей или групп. Это может быть легко выполнено с помощью матрицы решений или организационной диаграммы. Наиболее общие потребности (которые актуальны для большинства пользователей) дадут нам набор приоритетов, которые могут сравниваться с главными целями
организации.
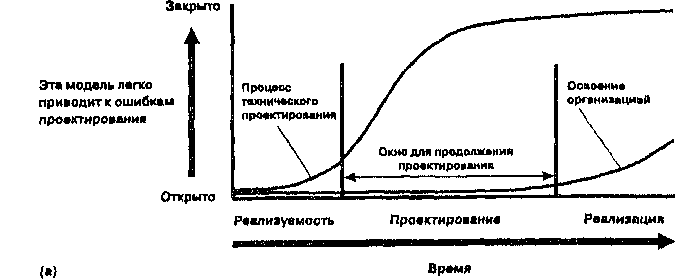
Когда между частными представлениями существуют противоречия, потребуется дополнительное обсуждение для выявления нестыковок. Их разрешение может потребовать проведения экспертизы, модификации и даже переопределения частных представлений для достижения соответствия с общими целями организации.
Может понадобиться нескольких итераций, чтобы объединить отдельные частные представления в группы. Это объединение гарантирует, что в основном потребности пользователей будут удовлетворены. Окончательное решение по определению общего представления обычно возлагается на администрацию, рассматривающую потребности отдельных пользователей как часть общих потребностей.
ПРОЕКТИРОВАНИЕ БД: ОБЩИЕ СООБРАЖЕНИЯ
Изучаемая область
Помимо основной идеи пространственно-информационных продуктов существуют и другие стороны проектирования ГИС для организации. Когда имеются несколько проектов, необходимо рассматривать соответствующие изучаемые области по отдельности. Они чаще всего основываются на формальном решении о том, почему область подвергается изучению. Так, для исследования городского уровня, весь город будет областью исследования. Для исследования, связанного с природными явлениями или объектами, как, например, загрязнение реки, весь водосборный бассейн реки может быть выбран в качестве области изучения, поскольку загрязнение может приходить с любой территории, дающей сток в один из притоков реки. Короче говоря, область изучения может выбираться на основе политических и административных границ, физических границ, границ собственности, или отражать, главным образом, финансовые ограничения или ограничения по данным, обнаруживаемые на ранних стадиях процесса проектирования.
Если для некоторой части предполагаемой области изучения имеются более подробные данные, чем для остальной части, они не должны диктовать размер области изучения. Это обстоятельство можно использовать таким образом, что небольшая часть с более подробными данными может играть роль прототипа для детального анализа всей области изучения, в расчете на то, что в дальнейшем и на всю область можно будет получить данные такой же подробности. Кроме того, они могут пригодиться для улучшения знания о всей области изучения.
Когда планируется использовать какой-либо вид интерполяции, граница области изучения должна быть расширена в достаточной степени, чтобы обеспечить корректные результаты интерполяции на ее краях. И, наконец, чем больше область изучения, тем больше денег и времени потребуется на создание базы данных, Часто именно вопросы стоимости являются главным ограничителем в установлении границ области изучения. Помимо этого, расширение области изучения повышает вероятность недостатка данных для всех покрытий, необходимых для проведения анализа. Выбор меньшей области изучения в качестве начального прототипа - хороший способ продемонстрировать организации полезность системы. Если это сделано достаточно эффектно, то спонсор наверняка согласится выделить больше денег на расширение области изучения.
Масштаб, разрешение и уровень детальности
Существует связь между размером изучаемой области и масштабом вводимых карт. Как вы помните, чем мельче масштаб карты, тем выше степень генерализации, тем менее точно представление объектов реального мира. На выбор масштаба влияет важность соответствующего покрытия для моделей анализа. Хотя не существует общих указаний для определения подходящего масштаба, большинство профессионалов используют подход "наилучших доступных данных", считая, что лучше больше подробностей, чем меньше.
Растровые данные имеют особенность: с уменьшением размера ячеек растра быстро возрастает объем данных. И хотя современные компьютеры имеют достаточно емкие устройства хранения, большой объем данных значительно замедляет выполнение операций над покрытиями, использующих поиск по окрестности; В одних случаях размер ячеек растра может диктоваться наименьшим представляемым объектом, в других -требованиями модели [DeMers, 1992], в третьих - вопросами совместимости с другими цифровыми данными, например, с ДДЗ со спутников.
Классификация
При проектировании ГИС мы должны рассматривать не только имеющиеся источники данных, но и систему классификации, удовлетворяющую требованиям моделирования. Решение о последней лучше принимать после рассмотрения видов вводимых данных. Использование более подробной классификации часто предпочтительно по двум причинам: она дает пользователю больший объем сведений, и при сравнении с данными другого покрытия меньшей подробности всегда можно агрегировать некоторые классы, в то время как обратный процесс либо затруднен, либо вовсе невозможен.
Но классификация - больше чем просто выбор должного уровня детальности. Нужно учесть, что мы делаем сравнения между покрытиями, и, таким образом, между классификациями. Кроме того, часто необходимо иметь возможность проводить согласованную классификацию в пределах одного покрытия данных из разных источников. Допустим, вам нужно покрытие с классами почв регионального охвата, созданное на основе различных исследований почв более детального окружного уровня. Если эти исследования проводились на значительном временном удалении друг от друга, то будет необходимо переработать их, чтобы добиться однородности классификации. Более подробное обсуждение проблем классификации, особенно в их связи с ошибками, дано Бэрроу [Burrough, 1986].
Система координат и проекция
Выбор проекции определяется площадью области изучения и доступными данными. Здесь также нет жестких правил, только здравый смысл. При этом следует учитывать, что преобразования проекций вносят дополнительную погрешность в данные. На выбор проекции влияет также то, какие характеристики земной поверхности должны сохраняться (обычно те, что наиболее важны для анализа). В общем, и по отношению к системе координат, и по отношению к проекции, пространственная и временная совместимость очень важны для корректности процесса принятия решений.
Выбор программного обеспечения
Выбрать подходящее для организации программное обеспечение всегда бывает трудно. Во многих случаях решение принимается разработчиком системы даже до начала процесса проектирования. Этот "перевернутый" подход - реальность для многих организаций и отдельных лиц. Руководства в этой области [например, Burrough, 1986] быстро устаревают из-за постоянного совершенствования как программного, так и аппаратного обеспечения. Выбор модели данных основывается на тех видах анализа, которые нужны, а они, в свою очередь, определяются пространственно-информационными продуктами проекта. Многие современные ГИС поддерживают более одной модели данных или могут использовать набор различных аналитических модулей. Выбор аппаратной платформы и периферийных устройств диктуется финансовыми ограничениями, требованиями по точности, условиями обучения и даже личными предпочтениями.
Так как же мы решаем для самих себя или для клиента, какой ГИС-пакет приобрести? Разумным подходом является подготовка документа, содержащего аналитические потребности, ограничения по стоимости, необходимая точность, потребности в обучении. Затем эти спецификации предлагаются большому числу поставщиков для получения конкурирующих предложений контракта. Возможно, к списку требований полезно будет прибавить запрос списка клиентов компании, как тех, что удовлетворены ее работой, так и тех, кто столкнулся с проблемами. Полученные ответы скажут вам о типах организаций, использующих систему (давая вам представление об их потребностях в моделировании) и позволят вам получить впечатления о системе из первых рук. Только после этого должно приниматься окончательное решение по выбору ГИС-пакета.
ПРОВЕРКА И УТВЕРЖДЕНИЕ
С точки зрения эксплуатации, методология проектирования хороша лишь настолько, насколько хороши результаты, полученные от реализации. Главный вопрос, на который нужно получить ответ: будет ли ГИС решать нужные организации задачи своевременно и корректно? Если процесс проектирования проводился должным образом, то в результате мы получим продукт, соответствующий всем потребностям организации, основанным на потребностях отдельных пользователей. Эти потребности должны быть достаточно конкретными и детальными, чтобы поставщик мог установить соответствие рассматриваемой системы этим требованиям. Известно, что лучше сразу сделать хорошо, чем потом переделывать. Нередки случаи, когда организации приходится связываться с другим поставщиком (разработчиком) после того, как обнаруживается, что система не удовлетворяет выдвинутым требованиям. Часто такие неудачи являются промахом не разработчика, а самой организации или ее системного аналитика, не давших полных спецификаций. Стоимость переделки может быть намного больше, чем стоимость разработки правильной системы на основе систематического, полного и хорошо организованного анализа потребностей организации.
Вопросы
В чем была причина большинства неудач ГИС в 1960-х годах? Каковы причины большинства неудач сегодня?
Почему мы должны рассматривать системное проектирование для ГИС? Почему не удовлетворяются потребности некоторых пользователей? Почему важно знать аналитические возможности ГИС, когда мы проектируем систему для третьих лиц?
Что такое система? Как этот объект проектирования расширяет наше определение ГИС? В чем различие между техническим и организационным проектированием?
В чем идея жизненного цикла системы? Каково ее назначение? Почему линейная модель жизненного цикла системы не подходит для проектирования и реализации ГИС в организациях?
Что такое "мифический человеко-месяц" ? Что эта концепция говорит нам о стоимостной эффективности правильного выполнения работы с первого раза?
Кто является внутренним участником в организационном окружении? Какие задачи они решают?
Кто является внешним участником в организационном окружении? Какую роль они играют в реализации ГИС?
Что такое концептуальное проектирование ГИС? Почему его недостаточно для проектирования ГИС для организации? Каковы некоторые трудности с ГИС, создаваемые "человеческим фактором"? Что такое анализ цена/отдача и какую роль он играет в проектировании ГИС?
Опишите и изобразите спиральную модель проектирования ГИС. Какие преимущества она имеет перед линейной моделью жизненного цикла системы?
Опишите шаги начального проектирования ГИС с использованием спиральной модели проектирования.
Перечислите и опишите возможные плюсы внедрения ГИС в организацию. Придумайте для примера некоторую организацию и расскажите о возможных преимуществах, вносимых ГИС в работу этой организации.
Что такое пространственно-информационные продукты? Как они связанны с вводом данных в ГИС? Как они управляют реализацией ГИС?
Опишите и изобразите матрицу решений системы для организации частных представлений ГИС. Сделайте то же для организационной диаграммы. Расскажите, как эти методы могут использоваться для последующего объединения представлений.
Что такое ошибки проектирования? Опишите и изобразите, как спиральная модель проектирования ГИС препятствует их возникновению.
Какие главные соображения по проектированию БД мы должны учесть при проектировании ГИС? Определите некоторые общие правила для каждого из них.
16.Что означают "проверка" и "утверждение" в контексте проектирования ГИС в противоположность ГИС-моделированию?
Приложение 1
НЕКОТОРЫЕ ПОСТАВЩИКИ ПО ДЛЯ СОЗДАНИЯ GIS
ARC/INFO, ArcView GIS, MapObjects, SDE
123242, Москва, Большая Грузинская, 10 Телефоны: (095)254-65-65, 254-93-35 Факс: (095)254-88-95 E_mail: market@dataplus.msk.su Spans GIS
InteraTYDAC Technologies Inc. 1500 Carling Ave, Ottawa, Ontario K1Z 8R7 Canada(613)722-7508
MicroStation GIS Environment (MGE)
Integraph Corporation Huntsville, AL 35894 (205) 730-2000
ERDAS IMAGINE
ERDAS, Inc.
2801 Buford Highway Atlanta, GA 30329 (404) 248-9000 GRASS
GRASS Information Center USACERL
ATTN: CECER-ECA P.O. Box 9005 Champaign, IL 61826-9005
Atlas CIS
Strategic Mapping Inc. 4030 Moorpark Avenue San Jose, CA 95117-4103 (408) 985-7400 GisPIus
Caliper Corporation 1172 Beacon Street Newton, MA 02161 (617) 527-4700 Maplnfo
Maplnfo Corporation 200 Broadway Troy, NY 12180-3289 (518) 274-6000 IDRISI
The Clark Labs for Cartographic Technology and Geographic Analysis Clark University 950 Main Street Worcester, MA 01610 (508) 793-7526 MapGrafix
ComGraphix, Inc. 620 E Street Clearwater, FL 34616 (813) 443-6807 OSU Map-for-the-PC Duane Marble
Department of Geography The Ohio State University Columbus, OH 43210
ПОСТАВЩИКИ ДАННЫХ В США
U.S. DEPARTMENT OF AGRICULTURE (USDA) Soil Conservation Service (SCS)
National Cartographic and Geographic Information Systems Center
USDA-Soil Conservation Service
P.O. Box 6567
Fort Worth, TX 76115
(817) 334-5559
FAX: (817) 334-5290
U.S. DEPARTMENT OF COMMERCE Bureau of the Census Customer Services Bureau of the Census Washington Plaza, Room 326 Washington, DC 20233 (301) 763-4100 FAX: (301) 763-4794 National Oceanic and Atmospheric Administration (NOAA) National Environmental Satellite, Data, and Information Service (NESDIS) NOAA
National Climatic Data Center Climate Services Division NOAA/NESDIS Е/ CC3 Federal Building Asheville NC 28801-2696 (704) 259-0682 FAX: (704) 259-2876
National Geophysical Data Center (NGDC)
National Geophysical Data Center Information Services Division NOAA/ NESDIS E/GC4 325 Broadway Boulder CO 80303-3328 (303) 497-6958 FAX: (303)497-6513
National Oceanic Data Center (NODC)
National Oceanographic Data Center User Services Branch NOAA/NESDIS E/OC21 1825 Connecticut Avenue, NW Washington DC 20235 (202) 606-4549 FAX: (202) 606-4586
National Ocean Service (NOS)
Coast and Geodetic Survey National Ocean Service, NOAA 1315 East-West Highway, Station 8620 Silver Spring MD 20910-3282 (301) 713-2780
U.S. DEPARTMENT OF THE INTERIOR U.S. Geological Survey (USGS)
Earth Science Information Center
U.S. Geological Survey
507 National Center
Reston VA 22092
(703) 648-5920
FAX: (703) 648-5548
Toll Free: 1-800-USA-MAPs
or
Sioux Falls ESIC U.S. Geological Survey EROS Data Center Sioux Falls SD 57189 (605) 594-6151 FAX: (605) 594-6589
ПОСТАВЩИКИ ДАННЫХ В КАНАДЕ
Topographic Surveys Division Surveys and Mapping Branch Energy, Mines and Resources
Canada 615 Booth Street Ottawa, Ontario K1AOE9 (613) 992-0924
Environmental Information Systems Division State of the Environment Reporting Branch Environment Canada
Ottawa, Ontario K1A OH3 (613) 997-2510
CanSIS Project Leader
Land Resource Research Centre
Agriculture Canada, Research Branch
K.W. Neatby Building
Ottawa, Ontario K1A OC6
(613)995-5011
Canada Centre for Remote Sensing
2464 Sheffield Road Ottawa, Ontario K1A OY7 (613) 952-2171
Canada Centre for Remote Sensing Prince Albert
Receiving Station Prince Albert, Saskatchewan S6V5S7 (306) 764-3602
User Summary Tapes
Electronic Data Dissemination Division
Statistics Canada
9th Floor, R.H. Coates Building
Ottawa, Ontario K1A OT6
(613)951-8200
![]()