

Моделирование случайных непрерывных величин.
Предположим, что случайная величина определена в интервале а<х<b и имеет плотность р(x)>0 при а<х<b. Обозначим через F(x) функцию распределения , которая при а < х < b равна
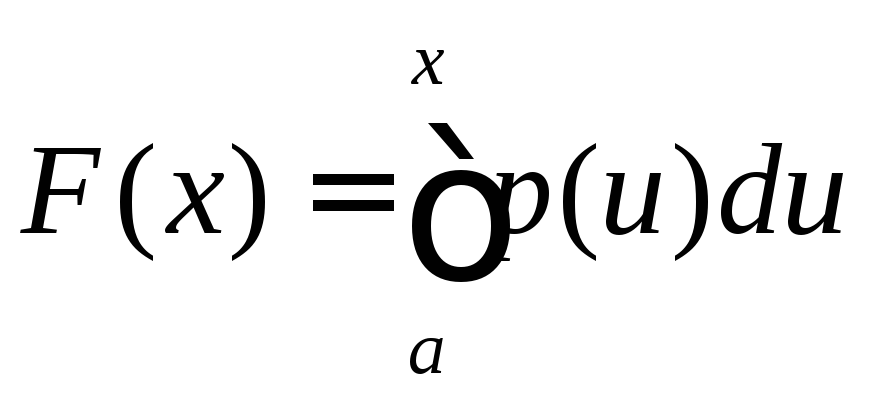
Случай a = – и (или) b = не исключается.
В тех случаях, когда уравнение F() = (4) аналитически разрешимо относительно , получается явная формула = G() для разыгрывания случайной величины , где G(y) – обратная функция по отношению к y = F(x). В других случаях можно уравнение (4) решать численно. Если объем накопителя позволяет, то удобно составить таблицу функции G(y), 0<y<1, и по ней находить значения . Иногда удобно использовать таблицу функции F(x), а < x < b, и находить значения обратной интерполяцией.
П р и м е р. Экспоненциальная случайная величина определена при x0 < x < с плотностью
p(x) = a e – a ( x – x0 ) .
Так
как 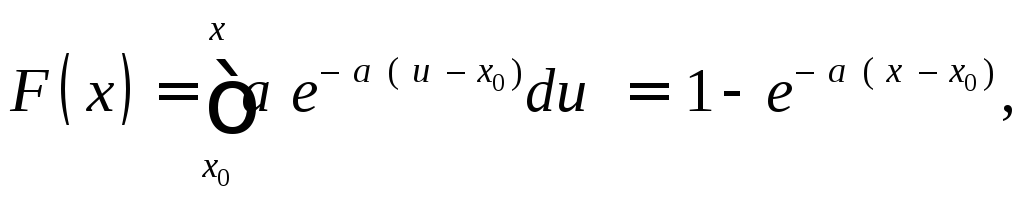 то
уравнение (4) принимает вид
то
уравнение (4) принимает вид
1 – e – a ( – x0 ) = .
Отсюда получаем явное выражение для расчета : = x0 – (1/а)1n(1– ). (5)
Моделирование многомерной случайной точки.
Моделирование n-мерной случайной точки с независимыми координатами. Если координаты n-мерной случайной величины Q=(ξ1, ..., ξn) независимы, то функция распределения
FQ(x1, ..., xn) = F1(x1)... Fn(xn),
где Fi(xi) – функция распределения величины ξi. Естественно ожидать, что в этом случае можно моделировать каждую величину ξi независимо:
Fi(ξi) = γi , i = 1,2, ...,n, (11)
где γi , ..., γn – независимые случайные числа.
Действительно, так как γi независимы, то и ξi определенные формулами (11), независимы. Поэтому их совместная функция распределения равна произведению
n n
Р{ξ1 < x1 ,... ,ξn <хп} = П Р{ ξi < xi} = П Fi(xi) = FQ(x1, ..., xn).
i = 1 i = 1
Поправки к приближенным распределениям.
Предположим, что плотность р(х) случайной величины ξ аппроксимируется снизу достаточно простой линией у(х). Очевидно, в качестве приближения к р(х) можно выбрать плотность
p1(x) = y(x) / c, где
b
c1 = ∫ y(x) dx, и находить приближенные значения ξ по плотности p1(x).
a
Можно, однако, представить р(х) в форме суперпозиции двух плотностей
p1(x) = y(x) / c1 и p2(x) = [p(x) – y(x)] / c2,
и получить таким образом метод для точного моделирования ξ. Алгоритм расчета ξ по плотности р(х) может оказаться весьма сложным; но на времени счета это почти не скажется, ибо р2(х) будет использоваться очень редко: Р{η = 2} = с2 = 1 – c1 << c1.
Итак, метод суперпозиции дает возможность учесть «поправку» p2(x), практически не увеличивая времени счета, а лишь ценою усложнения программы (впрочем, обычно это весьма нежелательно).
Разделение области моделирования случайной величины.
Этот прием иногда используют при моделировании случайной величины, плотность которой резко различна в различных областях.

Пусть р(х)—плотность случайной величины ξ, определенной в интервале а < x < b. Разобьем этот интервал на сумму непересекающихся интервалов ∆k, так что (a, b) = ∆1 + … +∆m (рис. 27) и вероятности попадания ξ в ∆k положительны: сk = ∆k∫ p(x) dx > 0.
Введем в рассмотрение плотности
 p(x)
/ ck при x∆k,
p(x)
/ ck при x∆k,
pk(x) =
0 при x∆k,.
Очевидно, c1 + … +cm = 1 и при всех х из (а; b)
p(x) = c1p1(x) + … + cm pm(x).
Для того чтобы найти значение ξ, можно сперва по числу γ1 разыграть номер области η = k, а затем вычислить ξ из уравнения
 , (21)
, (21)
где ak – левый конец ∆k.
Легко проверить, что с точки зрения количества вычислений этот метод хуже, чем метод обратных функций.

можно решать следующим образом: сперва найдем номер k такой, что
k–1 k
∑ cj ≤ < ∑cj; (22)
j=1 j=1
тогда это уравнение превратится в уравнение
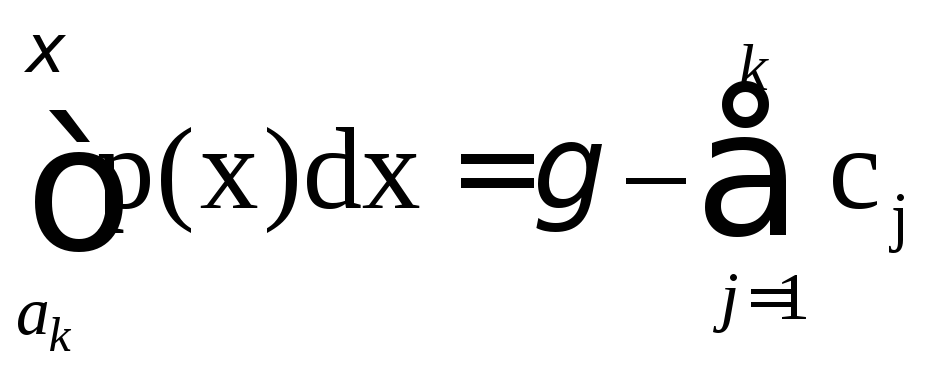 (23)
(23)
решая которое и найдем ξ. Уравнение (23) проще, чем (21), и совпадает с уравнением модифицированного метода суперпозиции для рассматриваемой задачи.
Положение может резко измениться в пользу метода дробления области, если вместо (21) использовать для моделирования ξ с плотностью pk(х), в ∆k какой-нибудь другой способ. Правда, тогда на получение одного значения ξ будет затрачиваться больше двух случайных чисел.
Метод дробления области применим также для моделирования многомерных случайных величин [19].