

2-1 Криптография / ЛБ_2 / ЛБ4 МОКр Исследование способов представления информации
.pdfПолученный код: A – 11, B – 101, C – 100, D – 00, E – 011, F – 010.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне может ухудшить варианты разбиения на следующем уровне и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути еще не гарантирует оптимальности всей совокупности действий. Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты.
Кодирование Хаффмана. Кодирование Хаффмана является простым алгоритмом для построения кодов переменной длины, имеющих минимальную среднюю длину. Этот весьма популярный алгоритм служит основой многих компьютерных программ сжатия текстовой и графической информации. В криптографии такой тип кодирования может быть использован для предварительного сжатия исходного текста с целью увеличения эффективной скорости преобразования данных. Многие программы используют непосредственно алгоритм Хаффмана, а другие берут его в качестве одной из ступеней многоуровневого процесса сжатия. Метод Хаффмана производит идеальное сжатие (т.е. сжимает данные до уровня их энтропии) если вероятности символов точно равны отрицательным степеням числа 2. Алгоритм начинает строить кодовое дерево снизу вверх, затем скользит вниз по дереву, чтобы построить каждый индивидуальный код справа налево (от самого младшего бита к самому старшему).
Алгоритм начинается составлением списка символов алфавита в порядке убывания их вероятностей. Затем от корня строится дерево, листьями которого служат эти символы. Это делается по шагам, причем на каждом шаге выбираются два символа с наименьшими вероятностями, добавляются наверх частичного дерева, удаляются из списка и заменяются вспомогательным символом,
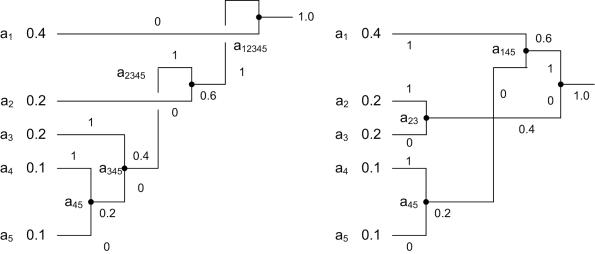
представляющим эти два символа. Вспомогательному символу приписывается вероятность, равная сумме вероятностей, выбранных на этом шаге символов. Когда список сокращается до одного вспомогательного символа, представляющего весь алфавит, дерево объявляется построенным. Завершается алгоритм спуском по дереву и построением кодов всех символов.
|
Проиллюстрируем этот алгоритм на простом примере. Пусть имеются пять |
|||||||||
символов с заданными вероятностями. |
|
|
|
|
|
|
|
|||
|
Символы объединяются в пары в следующем порядке: |
|
|
|
|
|||||
1) |
объединяется с , и оба заменяются комбинированным символом |
с |
||||||||
|
вероятностью 0.2; |
|
|
|
|
|
|
|
|
|
2) |
Осталось четыре символа, |
с вероятностью 0.4, |
а также |
, |
и |
с |
||||
|
вероятностями по 0.2. Произвольно выбираем |
|
и |
, объединяем их и |
||||||
|
заменяем вспомогательным символом |
с вероятностью 0.4. |
|
|
|
|||||
3) |
Теперь имеется три символа |
, |
и |
с вероятностями 0.4, |
0.2 |
и 0.4, |
||||
|
соответственно. Выбираем |
и |
объединяем |
символы |
и |
|
во |
|||
|
вспомогательный символ |
с вероятностью 0.6. |
|
|
|
|
|
|||
4) |
Наконец, объединяем два оставшихся символа |
и |
|
и заменяем на |
|
|||||
с вероятностью 1.
5)Дерево построено. Для назначения кодов мы произвольно приписываем бит 1 верхней ветке и бит 0 нижней ветке дерева для каждой пары. В результате получаем следующие коды: 0, 10, 111, 1101 и 1100. Распределение битов по краям – произвольное.
Средняя длина этого кода равна бит/символ. Очень важно, что кодов Хаффмана бывает много.
Некоторые шаги алгоритма выбирались произвольным образом, поскольку было больше символов с минимальной вероятностью. На рис. ХХХб показано, как можно объединить символы по-другому и получить иной код Хаффмана (11, 01, 00, 101 и 100). Средняя длина равна
бит/символ как и предыдущего кода.
Декодирование Хаффмана. Перед тем как начать сжатие потока данных, кодер должен построить коды. Это делается с помощью вероятностей (или частот) появления символов. Вероятности или частоты следует записать в файл, содержащий преобразованные данные, чтобы декодер Хаффмана мог произвести процесс декодирования. Это легко сделать, так как частоты являются целыми числами, а вероятности также можно представить целыми числами. Обычно это приводит к добавлению нескольких сотен байтов в сжатый файл.
Алгоритм декодирования очень прост. Следует начать с корня и прочитать первый бит сжатого файла. Если это нуль, следует двигаться по нижней ветке дерева; если это единица, то двигаться нужно по верхней ветке дерева. Далее читается второй бит и происходит движение по следующей ветке по направлению к листьям. Когда декодер достигнет листа дерева, он узнает код первого несжатого символа. Процедура повторяется для следующего бита, начиная опять из корня дерева.
Арифметическое кодирование. Метод Хаффмана является простым и эффективным, однако он порождает наилучшие коды переменной длины тогда, когда вероятности символов алфавита являются степенями числа 2, т.е. равны , , и т.д. Это связано с тем, что метод Хаффмана присваивает каждому
символу алфавита код с целым числом битов.
Теория информации предсказывает, что при вероятности символа, скажем 0,4, ему в идеале следует присвоить код длины 1,32 бита, поскольку
. А метод Хаффмана присвоит этому символу код длины 1 или 2 бита. Арифметическое кодирование решает эту проблему путем присвоения кода
всему, обычно большому передаваемому файлу, вместо кодирования отдельных символов (входным файлом может быть текст, изображение или данные любого вида). Алгоритм читает входной файл символ за символом и добавляет биты к сжатому файлу.
Чтобы понять метод, полезно представлять себе получающийся код в виде полуинтервала . Таким образом, код «9746509» следует интерпретировать как число 0,9746509, однако часть 0, не будет включена в передаваемый файл.
На первом этапе следует вычислить, или, по крайней мере, оценить частоты появления каждого символа алфавита. Наилучшего результата можно добиться, прочитав весь входной файл на первом проходе алгоритма сжатия, состоящего из двух проходов. Однако, если программа может получить хорошие оценки частот символов из другого источника, первый проход можно опустить.
Пример 1. Пусть имеется три символа , |
и с вероятностями |
, |
|
и |
, соответственно. Интервал |
делится между этими тремя |
|
символами на части, пропорционально их вероятностям.
Порядок следования подынтервалов не существенен. В нашем примере
трем символам будут соответствовать подынтервалы |
, |
и |
. |
|
||
Чтобы |
закодировать строку « |
», начинаем |
преобразования |
с |
||
интервала |
. |
|
|
|
|
|
|
Первый символ сокращает его, отбросив 40% в начале и 10% в конце. |
||||
Результатом будет интервал |
. |
|
|||
|
Второй символ |
сокращает интервал |
в той же пропорции до |
||
интервала |
. Третий символ |
переводит его в |
. |
||
|
Наконец, символ |
отбрасывает от него 90% в начале, а конечную точку |
|||
оставляет без изменения. Получается интервал |
. |
||||
|
Окончательным кодом этого метода будет служить любое число из этого |
||||
интервала. |
|
|
|
|
|
|
Здесь легко понять шаги алгоритма арифметического кодирования: |
||||
1) |
Задать «текущий интервал» *0,1). |
|
|
||
2) |
Повторить следующие действия для каждого символа |
входного файла. |
|||
3) Разделить текущий интервал на части пропорционально вероятностям
каждого |
символа. |
4) Выбрать |
подынтервал, соответствующий символу и назначить его новым |
текущим интервалом.
5) Когда весь входной файл будет обработан, выходом алгоритма объявляется любая точка, которая однозначно определяет текущий интервал (т.е. любая точка внутри этого интервала).
После каждого обработанного символа текущий интервал становиться все меньше и меньше, поэтому требуется все больше битов, чтобы выразить его, однако окончательным выходом алгоритма является единственное число, которое не является объединением индивидуальных кодов последовательности входных символов.
Среднюю длину кода можно найти, разделив размер выхода (в битах) на размер входа (в символах).
Пример 2. Продемонстрируем шаги сжатия для строки «SWISS MISS»
Символ |
Частота |
Вероятность |
Область |
S |
5 |
5/10=0.5 |
[0.5, 1.0) |
W |
1 |
1/10=0.1 |
[0.4, 0.5) |
I |
2 |
2/10=0.2 |
[0.2, 0.4) |
M |
1 |
1/10=0.1 |
[0.1, 0.2) |
пробел |
1 |
1/10=0.1 |
[0.0, 0,1) |
Процесс кодирования начинается инициализацией двух переменных Low и Hig и присвоением им значений 0 и 1 соответственно. Они определяют интервал *Low, Hig ). По мере поступления и обработки символов, переменные Low и Hig начинают сближаться, уменьшая интервал.
С каждым поступившим символом переменные Low и Hig пересчитываются по правилу:
NewHig = OldLow + Range×Hig Range(X)
NewLow = OldLow + Range×LowRange(X)
где Range = OldHigh – OldLow, а HighRange(X) и LowRange(X) обозначают верхний и нижний конец области символа .
Символ |
|
Вычисление переменных Low и Hig |
|
S |
L |
0.0+(1.0-0.0)×0.5=0.5 |
|
H |
0.0+(1.0-0.0)×1.0=1.0 |
||
|
|||
W |
L |
0.5+(1.0-0.5)×0.4=0.70 |
|
H |
0.5+(1.0-0.5)×0.5=0.75 |
||
|
|||
I |
L |
0.7+(0.75-0.70)×0.2=0.71 |
|
H |
0.7+(0.75-0.70)×0.4=0.72 |
||
|
|||
S |
L |
0.71+(0.72-0.71)×0.5=0.715 |
|
H |
0.71+(0.72-0.71)×1.0=0.72 |
||
|
|||
S |
L |
0.715+(0.72-0.715)×0.5=0.7175 |
|
H |
0.715+(0.72-0.715)×1.0=0.72 |
||
|
|||
Пробел |
L |
0.7175+(0.72-0.7175)×0.0=0.7175 |
|
H |
0.7175+(0.72-0.7175)×0.1=0.71775 |
||
|
|||
M |
L |
0.7175+(0.717525-0.7175)×0.1=0.717525 |
|
H |
0.7175+(0.717525-0.7175)×0.2=0.717550 |
||
|
|||
I |
L |
0.717525+(0.717550-0.717525)×0.2=0.717530 |
|
H |
0.717525+(0.717550-0.717525)×0.4=0.717535 |
||
|
|||
S |
L |
0.717530+(0.717535-0.717530)×0.5=0.7175325 |
|
H |
0.717530+(0.717535-0.717530)×1.0=0.7175350 |
||
|
|||
S |
L |
0.7175325+(0.7175350-0.7175325)×0.5=0.71753375 |
|
H |
0.7175325+(0.7175350-0.7175325)×1.0=0.71753500 |
||
|
Контрольные задания и вопросы
1.Дать определение информации и указать ее свойства.
2.Дать определение энтропии и указать ее свойства.
3.Какие возможности по сжатию текстов предоставлют их статистические свойства.
4.Рассчитать значение энтропии для русского и английского алфавитов.
5.Закодировать фразу, заданную преподавателем, с помощью метода равномерного кодирования.
6.Закодировать фразу, заданную преподавателем, с помощью метода кодирования по Шеннону-Фано.
7.Закодировать фразу, заданную преподавателем, с помощью метода Хаффмана.
8.Закодировать фразу, заданную преподавателем, с помощью метода арифметического кодирования.
Рекомендуемая литература
1.Сэломон Д. Сжатие данных, изображений и звука. М.: Техносфера, 2004. – 368 с.
2.Брандт З. Анализ данных. Статистические и вычислительные методы для научных работников и инженеров. – М.: Мир, ООО «Издательство ACT», 2003. – 686 с.
3.Вентцель Е. С., Овчаров Л.А. Прикладные задачи теории вероятностей. – М.: Радио и связь, 1983. – 416с.