

БТПп2 / химия 3 семестр . Аналитика / Новая папка / статистическая обработка результатов количественного анализа
.docx1. Статистическая обработка и представление
результатов количественного анализа
Выборка (выборочная совокупность) — совокупность ограниченного числа статистически эквивалентных вариант, рассматриваемая как случайная выборка из генеральной совокупности. Другими словами, выборочная совокупность — это совокупность результатов измерений аналитических сигналов или определяемых содержаний, рассматриваемая как случайная выборка из генеральной совокупности, полученной в указанных условиях.
Объем выборки — число вариант n составляющих выборку.
При статистической обработке результатов количественного анализа используют выборку, описываемую распределением Стьюдента. Распределением Стьюдента предпочтительно пользоваться при объеме выборки п<20
Расчет метрологических параметров.
На практике в количественном анализе обычно проводят не бесконечно большое число определений, а п = 5—6 независимых определений, т. е. имеют выборку (выборочную совокупность) объемом 5—6 вариант. В оптимальном случае (при анализе, например, лекарственных препаратов) рекомендуется проводить 5 параллельных определений, т. е. оптимальный рекомендуемый объем выборки n=5.
При наличии выборки рассчитывают следующее метрологические параметры в соответствии с распределением Стьюдента.
Среднее, т. е. среднее значение определяемой величины, согласно (1.1),
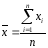 (1.1)
(1.1)
Среднее из конечной выборки отличается от действительного значения а (которое обычно не известно) и зависит от объема выборки
lim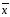 →
а,
при
n→
∞
→
а,
при
n→
∞
Отклонение:
di
= xi
-
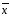 (1.4)
(1.4)
di
— случайное отклонение i-й
варианты xi
от среднего
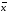 .
.
Дисперсия V (иногда ее обозначают как s2) показывает рассеяние вариант относительно среднего и характеризует воспроизводимость анализа. Рассчитывается по формуле (1.5):
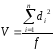
где f= п-1 — число степеней свободы.
Если
известно
действительное значение определяемой,
величины а
(или
истинное значение определяемой величины
µ), например, при работе со стандартным
образцом, то среднее
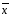 принимают равным а
(или µ); тогда число степеней свободы f
= п.
принимают равным а
(или µ); тогда число степеней свободы f
= п.
Дисперсия
среднего V равна:
равна:
V =
V/n
=
V/n
Стандартное отклонение (или среднее квадратичное отклонение) s — характеристика рассеяния вариант относительно среднего. Она рассчитывается как корень квадратный из дисперсии V, взятый со знаком плюс:
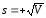
Очевидно, V = s2. Стандартное отклонение s, как и дисперсия V характеризует воспроизводимость результатов количественного анализа.
Стандартное
отклонение среднего s определяется
как
определяется
как
s =
=
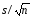
(«старое» название — средняя квадратичная ошибка среднего арифметического).
Относительное стандартное отклонение sr — это отношение стандартного отклонения к среднему значению:
sr
= s/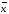
Чем меньше sr тем лучше воспроизводимость анализа.
Доверительный интервал (доверительный интервал среднего) — интервал, в котором с заданной доверительной вероятностью Р находится действительное значение определяемой величины (генеральное среднее):
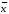 ±
∆
±
∆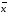 ,
(1.7)
,
(1.7)
где
∆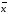 —полуширина
доверительного интервала.
—полуширина
доверительного интервала.
Доверительная вероятность Р — вероятность нахождения действительного значения определяемой величины а в пределах доверительного интервала. Изменяется от 0 до 1 или от 0% до 100%. В количественном анализе при контроле качества препаратов доверительную вероятность чаще всего принимают равной P= 0,95 = 95% и обозначают как Р0,95. При оценке правильности методик или методов анализа доверительную вероятность обычно считают равной Р= 0,99=99%.
Полуширину
доверительного интервала ∆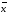 находят по формуле (1.8):
находят по формуле (1.8):
∆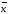 =
=
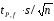 (1.8)
(1.8)
где tP,f — коэффициент нормированных отклонений (коэффициент Стьюдента, функция Стьюдента, критерий Стьюдента), который зависит от доверительной вероятности Р и числа степеней свободы f= п - 1, т. е. от числа проведенных определений.
Численные значения tP,f рассчитаны для различных возможных величин Р и n и табулированы в справочниках.
В табл. 1.1 приведены численные значения коэффициента Стьюдента, рассчитанные при разных величинах п и Р.
Чем больше n, тем меньше tP,f . Однако при n > 5 уменьшение tP,f уже сравнительно невелико, поэтому на практике обычно считают достаточным проведение пяти параллельных определений (п = 5).
Относительная (процентная) ошибка среднего результата ε рассчитывается по формуле (1.9):
ε
= (∆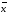 /
/ )∙100%.
;
(1.9)
)∙100%.
;
(1.9)
Исключение грубых промахов.
Некоторые из результатов единичных определений (вариант), входящих в выборочную совокупность, могут заметно отличаться от величин остальных вариант и вызывать сомнения в их достоверности. Для того чтобы статистическая обработка результатов количественного анализа была достоверной, выборка должна быть однородной, т.е. она не должна быть содержать сомнительные варианты — так называемые грубые промахи. Грубые промахи необходимо исключить из общего объема выборки, после чего можно проводить окончательное вычисление статистических характеристик.
Если объем выборки невелик 5< п < 10, то выявление сомнительных результатов анализа — исключение грубых промахов — чаще всего проводят с помощью так называемого Q-критерия (контрольного критерия Q), или Q –теста.
Для этого варианты xi вначале располагают в порядке возрастания их численного значения от x1 до хn где n — объем выборки, т. е. представляют в виде упорядоченной выборки. Затем для крайних вариант — минимальной x1 и максимальной хn — вычисляют величину Q по формулам (1.10):
Q1 =(x2-x1)/R; Qn = (xn – xn-1)/R (1.10)
где х2 и xn-1 — значения вариант, ближайших по величине к крайним вариантам, а R = (xn – x1)
R — размах варьирования, т. е. разность между максимальным хn и минимальным x1 значениями вариант, составляющих выборку.
Рассчитанные значения Q1 и Qn сравнивают с табличными при заданных n и доверительной вероятности Р. Если рассчитанные значения Q1 или Qn (или оба) оказываются больше табличных
Q1 > Qтабл или Qn > Qтабл
то варианты х1 или хп (или обе) считаются грубыми промахами и исключаются из выборки.
Для полученной выборки меньшего объема проводят аналогичные расчеты до тех пор, пока не будут исключены все грубые промахи, так что окончательная выборка окажется однородной и не будет содержать грубые промахи.
В табл. 1.2 приведены численные величины контрольного критерия Q для Р = 0,90—0,99 и п= 3—10.
Таблица 1.1. Численные значения коэффициента Стьюдента tP,f для расчета границ доверительного интервала при доверительной вероятности P, объеме выборки n, числе степеней свободы f= п -1
|
п |
f |
Значение tP,f при доверительной вероятности |
||||
|
0,80 |
0,90 |
0,95 |
0,99 |
0,999 |
||
|
2 |
1 |
3,08 |
6,31 |
12,07 |
63,7 |
636,62 |
|
3 |
2 |
1,89 |
2,92 |
4,30 |
9,92 |
31,60 |
|
4 |
3 |
1,64 |
2,35 |
3,18 |
5,84 |
12,94 |
|
5 |
4 |
1,53 |
2,13 |
2,78 |
4,60 |
8,61 |
|
6 |
5 |
1,48 |
2,02 |
2,57 |
4,03 |
6,86 |
|
7 |
6 |
1,44 |
1,94 |
2,45 |
3,71 |
5,96 |
|
8 |
7 |
1,42 |
1,90 |
2,36 |
3,50 |
5,41 |
|
9 |
8 |
1,40 |
1,86 |
2,31 |
3,36 |
5,04 |
|
10 |
9 |
1,38 |
1,83 |
2,26 |
3,25 |
4,78 |
|
11 |
10 |
1,37 |
1,81 |
2,23 |
3,17 |
4,59 |
|
12 |
11 |
1,36 |
1,80 |
2,20 |
3,11 |
4,49 |
|
13 |
12 |
1,36 |
1,78 |
2,18 |
3,06 |
4,32 |
|
14 |
13 |
1,35 |
1,77 |
2,16 |
3,01 |
4,22 |
|
15 |
14 |
1,35 |
1,76 |
2,14 |
2,98 |
4,14 |
|
16 |
15 |
1,34 |
1,75 |
2,12 |
2,95 |
4,07 |
|
17 |
16 |
1,34 |
1,75 |
2,11 |
2,92 |
4,02 |
|
18 |
17 |
1,33 |
1,74 |
2,10 |
2,90 |
3,97 |
|
19 |
18 |
1,33 |
1,73 |
2,09 |
2,88 |
3,92 |
|
20 |
19 |
1,33 |
1,73 |
2,09 |
2,86 |
3,88 |
|
21 |
20 |
1,33 |
1,73 |
2,09 |
2,85 |
3,85 |
|
22 |
21 |
1,32 |
1,72 |
2,08 |
2,83 |
3,82 |
|
23 |
22 |
1,32 |
1,72 |
2,07 |
2,82 |
3,79 |
|
24 |
23 |
1,32 |
1,71 |
2,07 |
2,81 |
3,77 |
|
25 |
24 |
1,32 |
1,71 |
2,06 |
2,80 |
3,75 |
|
26 |
25 |
1,32 |
1,71 |
2,06 |
2,79' |
3,73 |
|
27 |
26 |
1,32 |
1,71 |
2,06 |
2,78 |
3,71 |
|
28 |
27 |
1,31 |
1,70 |
2,05 |
2,77 |
3,70 |
|
29 |
28 |
1,31 |
1,70 |
2,05 |
2,76 |
3,67 |
|
30 |
29 |
1,31 |
1,70 |
2,05 |
2,76 |
3,66 |
|
31 |
30 |
1,31 |
1,70 |
2,04 |
2,75 |
3,65 |
|
41 |
40 |
1,30 |
1,68 |
2,02 |
2,70 |
3,55 |
|
61 |
60 |
1,30 |
1,67 |
2,00 |
2,66 |
3,46 |
|
121 |
120 |
1,29 |
1,66 |
1,98 |
2,62 |
3,37 |
|
∞ |
∞ |
1,28 |
1,64 |
1,96 |
2,58 |
3,29 |
При проведении Q-mecma доверительную вероятность чаще всего принимают равной Р=0,90 = 90%.
Если из двух крайних вариант х1 и хп только одна вызывает сомнение, то Q-тест можно проводить лишь в отношении этой сомнительной варианты.
Таблица 1.2. Численные значения Q-критерия при доверительной вероятности Р и объеме выборки п
|
|
п |
|||||||
|
|
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
0,90 |
0,94 |
0,76 |
0,64 |
0,56 |
0,51 |
0,47 |
0,44 |
0,41 |
|
0,95 |
0,98 |
0,85 |
0,73 |
0,64 |
0,59 |
0,54 |
0,51 |
0,48 |
|
0,99 |
0,99 |
0,93 |
0,82 |
0,74 |
0,68 |
0,63 |
0,60 |
0,57 |
|
Примечание. В некоторых источниках приводимые численные значения Q слегка отличаются от величин, представленных в табл. 1.2. |
||||||||
Пример. Пусть при проведении 5 параллельных анализов содержание определяемого компонента в анализируемом образце найдено равным, %: 3,01; 3,03; 3,04; 3,05 и 3,11. Установите, имеются ли грубые промахи или же рассматриваемая выборка однородна.
Решение. Очевидно, что сомнительным значением может быть только одно, равное 3,11. Используем Q -тест. Согласно (1.10), можно записать:
Qрассч = (3,11 - 3,05) / (3,11 - 3,01) = 0,60.
Из табл. 1.2 при п = 5 и Р = 0,90 находим Qтa6л = 0,64. Поскольку
Qрассч = 0,60 < Qтабл = 0,64,
то значение варианты 3,11 не является грубым промахом и не отбрасывается.
Как отмечалось выше, обычно при проведении количественного анализа (например, лекарственных препаратов и т. п. образцов) рекомендуется объем выборки (число единичных параллельных определений), равный п = 5. В таких случаях грубые промахи устраняют с использованием Q-теста, как вписано выше.
Если объем выборки равен 3 или 4,. т. е., n < 5, то применение Q-теста не рекомендуется.
Если объем выборки п ≥ 10, то для устранения грубых промахов (для проверки однородности выборки) поступают следующим образом.
Вначале по результатам единичных независимых определений предварительно рассчитывают по формулам (1.1), (1.4), (1.6) среднее значение, отклонения di для всех вариант, стандартное отклонение s. Затем сравнивают абсолютную величину |di|, и численное значение 3s. Если для всех вариант окажется, что
|di| ≤ 3s (1.11)
то грубые промахи отсутствуют; выборка однородна. Если же условие (1.11) выполняется не для всех вариант, то те варианты, для которых это условие не выполняется, признаются грубыми промахами при Р = 0,95 = 95% и исключаются из общей выборочной совокупности. Получают выборку меньшего объема, для которой снова повторяют весь цикл вычислений и с использованием соотношения (1.11) снова выясняют наличие или отсутствие грубых промахов. Так поступают до тех пор, пока не устранят все грубые промахи и выборка окажется однородной.
Объем выборки больше десяти (п > 10) используют чаще всего тогда, когда оценивают воспроизводимость методик или методов анализа.
Представление результатов количественного анализа.
При представлении результатов количественного анализа обычно указывают и рассчитывают следующие статистические характеристики:
xi , — результаты единичных определений (варианты);
п — число независимых параллельных определений (объем выборки);
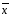 — среднее
значение определяемой величины;
— среднее
значение определяемой величины;
s — стандартное отклонение;
∆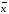 — полуширину
доверительного интервала (с указанием
значения доверительной вероятности
Р);
— полуширину
доверительного интервала (с указанием
значения доверительной вероятности
Р);
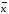 ±
∆
±
∆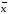 —
доверительный интервал (доверительный
интервал среднего);
—
доверительный интервал (доверительный
интервал среднего);
ε —относительную (процентную) ошибку среднего результата.
Эти характеристики составляют необходимый и достаточный минимум величин, описывающих результаты количественного анализа, при условии, что систематические ошибки устранены или они меньше случайных.
Иногда дополнительно указывают также
дисперсию V = s2,
дисперсию
среднего V
стандартное
отклонение среднего s ,
,
относительное стандартное отклонение sr.
Однако их перечисление необязательно, так как все они легко вычисляются из величин, приведенных выше.
Пример статистической обработки и представления результатов количественного анализа.
Пусть содержание определяемого компонента в анализируемом образце, найденное в пяти параллельных единичных определениях (п = 5), оказалось равным, %: 3,01; 3,04; 3,08; 3,16 и 3,31. Известно, что систематическая ошибка отсутствует. Требуется провести статистическую обработку результатов количественного анализа (оценить их воспроизводимость) при доверительной вероятности, равной Р = 0,95.