

Лабораторные работы / Ганишев (8 вариант) / Лабораторная работа 8
.docxМОСКОВСКИЙ ЭНЕРГЕТИЧЕСКИЙ ИНСТИТУТ (ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ)
Лабораторная работа №6
«Линейный регрессионный анализ»
по дисциплине «Теория вероятности
и математическая статистика».
Выполнил: .
Студент группы А-13-08
Ганишев Василий
Проверил: .
Тигетов Д.Г.
Задание 1.
В таблице приведены данные по 45 предприятиям легкой промышленности по статистической связи между стоимостью основных фондов(founds, млн руб.) и средней выработкой на 1 работника(product, тыс. руб.); z – вспомогательный признак: z = 1 – федеральное подчинение, z = 2 – муниципальное.
Таблица 1
|
fonds |
product |
z |
fonds |
product |
z |
fonds |
product |
z |
|
6,5 |
18,3 |
1 |
9,3 |
17,2 |
2 |
10,4 |
21,4 |
2 |
|
10,3 |
31,1 |
1 |
5,7 |
19,0 |
2 |
10,2 |
23,5 |
2 |
|
7,7 |
27,0 |
1 |
12,9 |
24,8 |
2 |
18,0 |
31,1 |
2 |
|
15,8 |
37,9 |
1 |
5,1 |
21,5 |
2 |
13,8 |
43,2 |
2 |
|
7,4 |
20,3 |
1 |
3,8 |
14,5 |
2 |
6,0 |
19,5 |
2 |
|
14,3 |
32,4 |
1 |
17,1 |
33,7 |
2 |
11,9 |
42,1 |
2 |
|
15,4 |
31,2 |
1 |
8,2 |
19,3 |
2 |
9,4 |
18,1 |
2 |
|
21,1 |
39,7 |
1 |
8,1 |
23,9 |
2 |
13,7 |
31,6 |
2 |
|
22,1 |
46,6 |
1 |
11,7 |
28,0 |
2 |
12,0 |
21,3 |
2 |
|
12,0 |
33,1 |
1 |
13,0 |
30,9 |
2 |
11,6 |
26,5 |
2 |
|
9,5 |
26,9 |
1 |
15,3 |
27,2 |
2 |
9,1 |
31,6 |
2 |
|
8,1 |
24,0 |
1 |
13,5 |
29,9 |
2 |
6,6 |
12,6 |
2 |
|
8,4 |
24,2 |
1 |
10,5 |
34,9 |
2 |
7,6 |
28,4 |
2 |
|
15,3 |
33,7 |
1 |
7,3 |
24,4 |
2 |
9,9 |
22,4 |
2 |
|
4,3 |
18,5 |
1 |
13,8 |
37,4 |
2 |
14,7 |
27,7 |
2 |
Построим диаграмму рассеивания, чтобы убедиться, что предположение линейности регрессионной зависимости не лишено смысла:
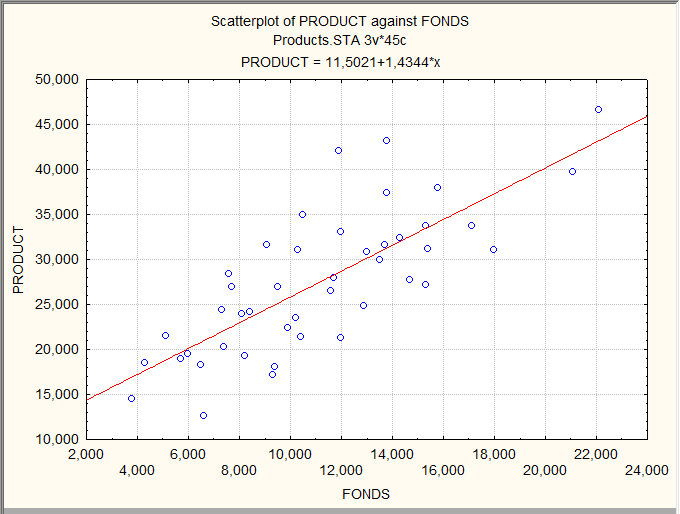
Выполним регрессионный анализ:
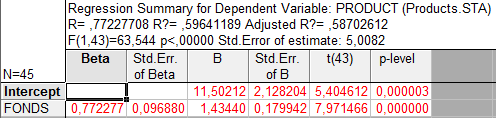
Так как значения уровня значимости p-level очень малы, гипотезы о нулевых значениях коэффициентов отклоняются с высокой значимостью.
Построим регрессию выработки по фондам для более однородной совокупности – для предприятий федерального подчинения.
Диаграмма рассеивания:
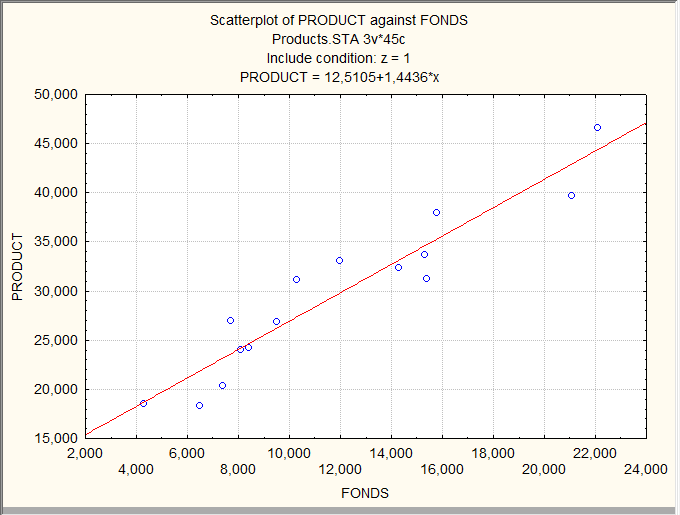
Регрессионный анализ:
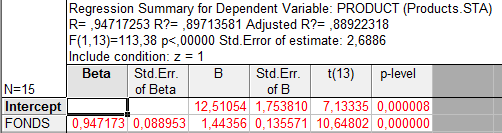
Коэффициент детерминации увеличился с 0.597 до 0.897, значения Std. Errors of estimate уменьшилось с 5.01 до 2.68, значит подгонка улучшилась.
Задание 2.
Исследуется зависимость урожайности у зерновых культур (ц/га) от ряда факторов (переменных) сельскохозяйственного производства, а именно,
Х1 – число тракторов на 100га
Х2 – число зерноуборочных комбайнов
Х3 – число орудий поверхностной обработки почвы
Х4 – количество удобрений, расходуемых на гектар
Х5 – количество химических средств защиты растений на гектар
Исходные данные для 20 районов области приведены в таблице. Здесь мы располагаем выборкой объема 20; число независимых переменных (факторов) k = 5. Матрица X должна содержать 6 столбцов размерности 20; первый столбец состоит из единиц, а столбцы со 2-го по 6-ой представлены соответственно столбцами 3-7 таблицы.
Предварительно визуально оценим имеющиеся данные, построив несколько диаграмм рассеяния:
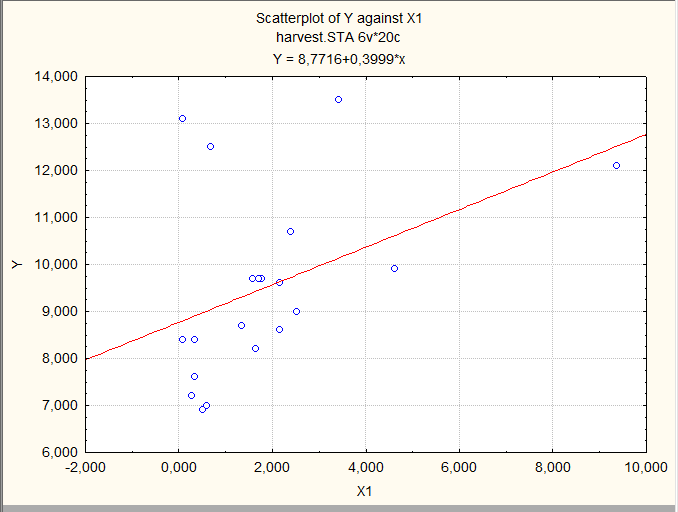
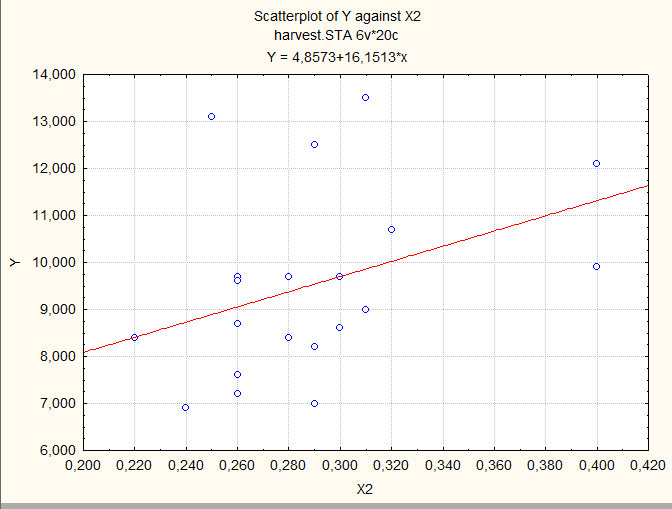
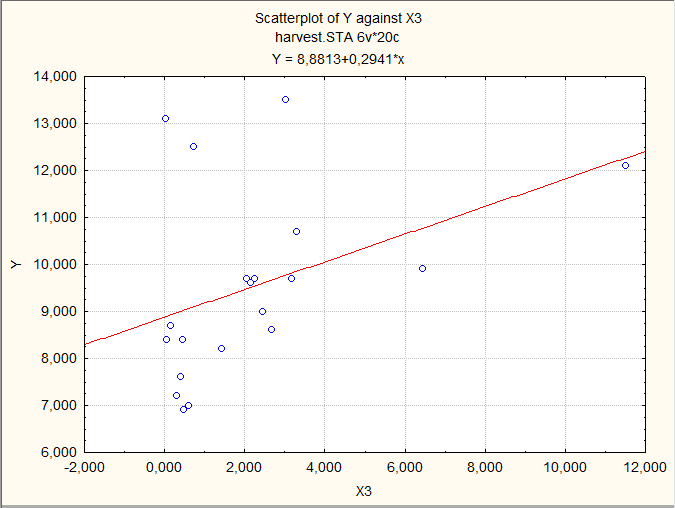
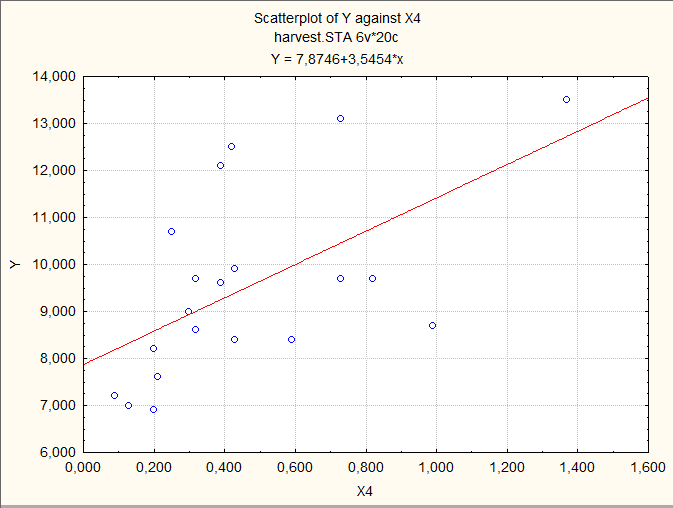
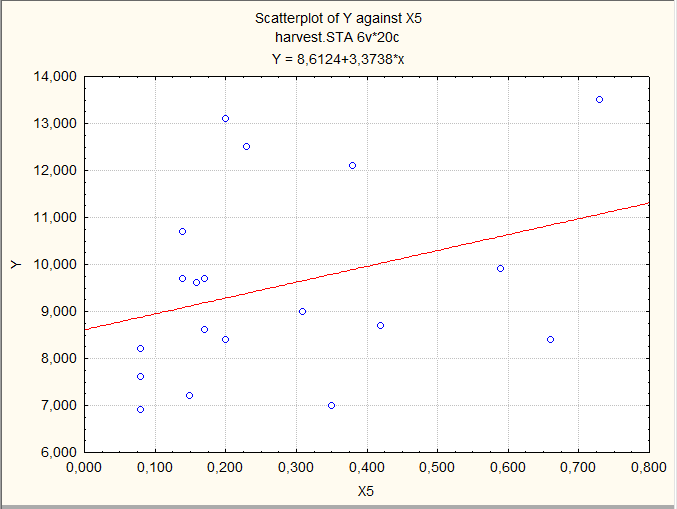
Иногда такой просмотр позволяет увидеть основную зависимость, но не в этом примере.
Регрессионный анализ:

Таким
образом, оценка
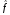 (x)
неизвестной функции регрессии f
(x)
в данном случае:
(x)
неизвестной функции регрессии f
(x)
в данном случае:
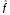 (x)
= 3.51
0.06 x1
+ 15.5
x2
+ 0.11
x3
+ 4.47 x4
2.93
x5
(x)
= 3.51
0.06 x1
+ 15.5
x2
+ 0.11
x3
+ 4.47 x4
2.93
x5
В столбце St. Err. of B указаны стандартные ошибки sj оценок коэффициентов (по (21)); видно, что стандартные ошибки в оценке всех коэффициентов, кроме 4 , превышают значения самих коэффициентов, что говорит о статистической ненадежности последних. В столбце t(14) -значение статистики Стьюдента для проверки гипотезы о нулевом значении соответствующих коэффициентов; в столбце p-level -уровень значимости отклонения этой гипотезы; достаточно малым (0.01) этот уровень является только для коэффициента при x4 . Только переменная x4 - количество удобрений, подтвердила свое право на включение в модель. В то же время проверка гипотезы об отсутствии какой бы то ни было линейной связи между y и (х1 , ..., х5) с помощью статистики:
F = 3.00 , p = 0.048 ,
говорит о том, что следует продолжить изучение линейной связи между y и (х1 , ..., х5), анализируя как их содержательный смысл, так и матрицу парных корреляций.
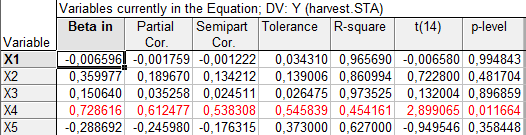
Из матрицы видно, что х1 , х2 и х3 (оснащенность техникой) сильно коррелированы (парные коэффициенты корреляции 0.854, 0.882 и 0.978), т.е. имеет место дублирование информации, и потому, по-видимому, есть возможность перехода от исходного числа признаков (переменных) к меньшему.
Пошаговый отбор переменных.
На первом шаге (k = 1) найдем один наиболее информативную переменную. При k = 1 величина R2 совпадает с квадратом обычного (парного) коэффициента корреляции
R2 = r2 (y, x) ,
из матрицы корреляций находим:
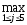 r2
(y,
xj)
= r2
(y,
x4)
=
(0.577)2
= 0.333,
r2
(y,
xj)
= r2
(y,
x4)
=
(0.577)2
= 0.333,
так что в классе однофакторных регрессионных моделей наиболее информативным предиктором (предсказателем) является x4 - количество удобрений. Вычисление скорректированного (adjusted) коэффициента детерминации дает значение 0,296:
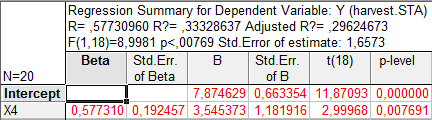
2-й шаг (k = 2). Среди всевозможных пар (х4 , хj ), j = 1, 2, 3, 5, выбирается наиболее информативная (в смысле R2 или, что то же самое, в смысле R2adj ) пара:
вернемся в окно Select dep. And indep. Var. и переберем все различные пары; результат:
 (х4
, х1)
= 0.406,
(х4
, х1)
= 0.406,
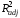 (х4
, х2)
= 0.399,
(х4
, х2)
= 0.399,
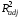 (х4
, х3
)
= 0.421,
(х4
, х3
)
= 0.421,
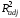 (х4
, х5)
= 0.255,
(х4
, х5)
= 0.255,
откуда видно, что наиболее информативной парой является (х4 , х3 ), которая дает
 (2)
=
(2)
=
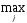
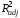 (х4
, хj)
= 0.421
(х4
, хj)
= 0.421

Оценка
уравнения регрессии урожайности по
факторам х3
и
х4
имеет вид
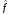 (х3
,
х4)
= 7.29 + 0.28 х3
+ 3.47 х4
(х3
,
х4)
= 7.29 + 0.28 х3
+ 3.47 х4
(0.66) (0.13) (1.07)
Внизу в скобках указаны стандартные ошибки, взятые из столбца Std. Err. of B таблицы Regression Results для варианта независимых переменных (х3 , х4) Все три коэффициента статистически значимо отличаются от нуля при уровне значимости = 0.05, что видно из столбца p-level той же таблицы.
3-й
шаг
(k
= 3). Среди всевозможных троек (х4
,
х3
,хj),
j
= 1, 2, 5, выбираем аналогично наиболее
информативную: (х4
,
х3
,х5),
которая дает
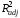
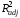 (3)
= 0.404,
(3)
= 0.404,

что
меньше, чем
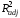 (2)
= 0.421; это означает, что третью переменную
в модель включать нецелесообразно, т.к.
она не повышает значение
(2)
= 0.421; это означает, что третью переменную
в модель включать нецелесообразно, т.к.
она не повышает значение
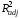 (более того, уменьшает). Итак, результатом
анализа является построенная на прошлом
этапе зависимость.
(более того, уменьшает). Итак, результатом
анализа является построенная на прошлом
этапе зависимость.
Задание 3.
Имеются эмпирические данные о зависимости y - выработки на одного работника доменного производства от x - температуры дутья; данные приведены в таблице в условных единицах.
Построим диаграмму рассеяния:
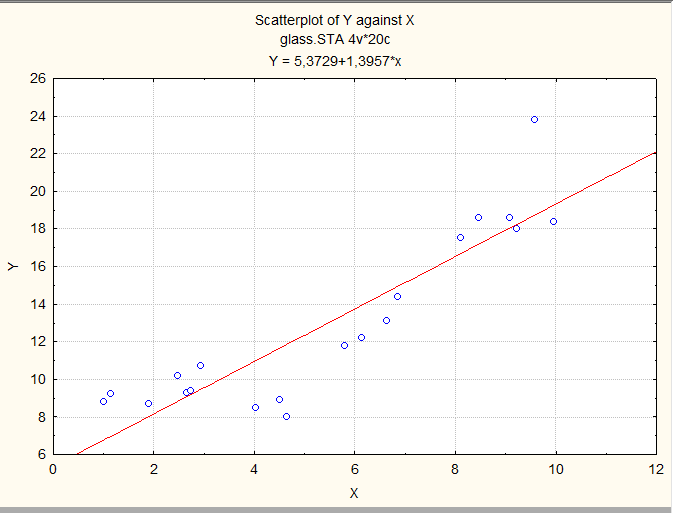
Зависимость возможно нелинейная, построим несколько регрессий:
1) Регрессия первой степени: y = о + 1 x (indep. Var.: x); получим (в скобках указаны стандартные ошибки оценок):
y = 5.37 + 1.40 x
(0.98) (0.16)
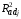 =
0.795, s
=
2.10.
=
0.795, s
=
2.10.
2) Регрессия второй степени: y = о + 1 x + 2 x2 (indep. Var.: x, x2); получим:
y = 9.9 - 0.9 x + 0.21 x2,
(1.33) (0.57) (0.05)
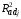 =
0.891, s
= 1.53,
=
0.891, s
= 1.53,
коэффициент
1
= -0.9 незначимо отличается от 0. Эта
регрессия лучше предыдущей в смысле
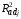 и s.
Однако, возможно, регрессия третьей
степени окажется лучше?
и s.
Однако, возможно, регрессия третьей
степени окажется лучше?
3) Построим регрессию третьей степени: y = о + 1 x + 2 x2 + 3 x3
(indep. Var.: x, x2 , x3 ); получим:
y = 11.6 - 2.32 х + 0.52 х2 - 0.02 х3
(2.33) (1.75) (0.36) (0.02)
 =
0.890, s
= 1.53,
=
0.890, s
= 1.53,
 незначимо
отличаются от 0. Поскольку степень
увеличилась без увеличения
незначимо
отличаются от 0. Поскольку степень
увеличилась без увеличения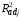 ,
от регрессии третьей степени отказываемся
в пользу (31) второй степени. Однако,
гипотеза о нулевом значении
1
в (31) не отклоняется (p-level
= 0.1),
и потому построим
,
от регрессии третьей степени отказываемся
в пользу (31) второй степени. Однако,
гипотеза о нулевом значении
1
в (31) не отклоняется (p-level
= 0.1),
и потому построим
4) регрессию y = о + 2 x2 без линейного члена (indep. Var.: x2 ); получим
y = 8.02 + 0.13 x2
(0.54) (0.01)
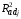 =
0.884, s
= 1.6,
=
0.884, s
= 1.6,
Сравнивая
ее по
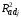 и s
с регрессией, включающей линейный член,
отдаем предпочтение второй, поскольку
ошибка прогноза s
меньше.
и s
с регрессией, включающей линейный член,
отдаем предпочтение второй, поскольку
ошибка прогноза s
меньше.
Задание 4.
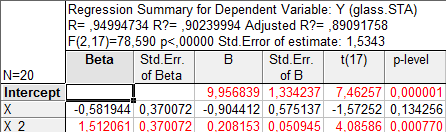
Имеются 20 наблюдений по некоторому технологическому процессу химического производства ; х и у – изменяемое содержание двух веществ; z – контролируемый параметр получаемого продукта. Полагая, что z = P(x,y) + ε, где P(x,y) = β0 + β1x + β2y + β3x2 + β4xy + β5y2 – многочлен второй степени, ε – случайная составляющая, Mε = 0, Dε = σ2, необходимо оценить функцию P(x,y) и найти точку её минимума.
Построим регрессию для z8. Рассмотрим полученные результаты:
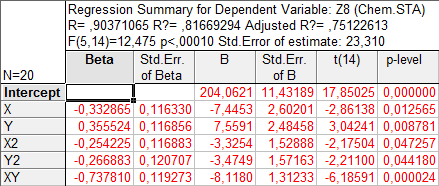
P(x,y) = 204,06 – 7,45x + 7,56y – 3,33x2 – 8,12xy – 3,47y2
(11,43) (2,60) (2,48) (1,53) (1,57) (1,31)
Построим графики полученной функции и найдём точку её минимума:
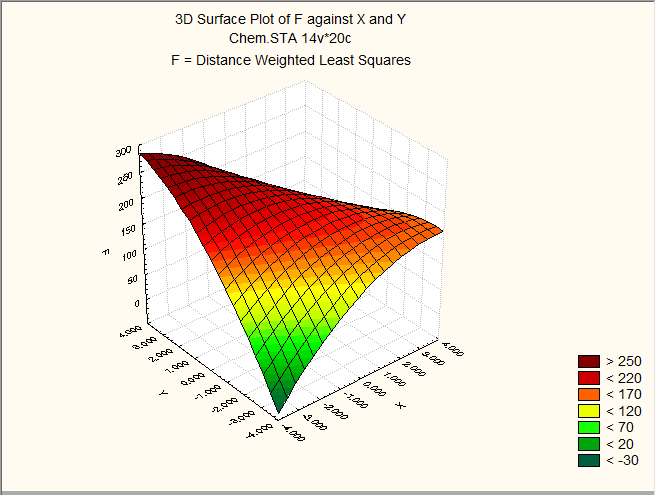
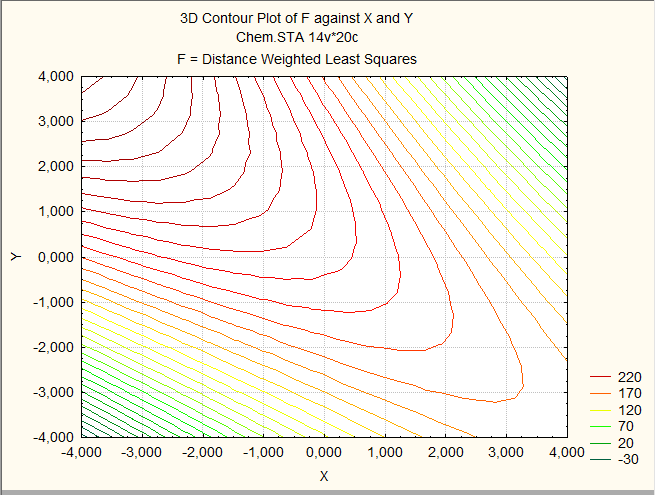
По полученным графикам можно сказать, что точкой минимума функции является точка (-4;-4), но в этой точке нет наблюдений величины z8. Среди точек попадающих в диапазон измерений точкой минимума является точка (3,2).