

НИУ МЭИ (МЭИ (ТУ))
Кафедра прикладной математики
Лабораторная работа № 5 по дисциплине: «Математическая статистика» на тему: «Критерий хи-квадрат проверки гипотез»
Выполнил:
студент группы А-13-08
Бочаров Иван
Основные теоремы
Теорема К. Пирсона. Если гипотеза Н верна и pi0 > 0, i=1,...,m, то при n распределение статистики Х2 асимптотически подчиняется распределению хи-квадрат с m - 1 степенями свободы, т.е.
Р{ X2 < x / H } Fm-1(x) P{ 2m-1 < x }.
Порог h выберем из условия: вероятность ошибки первого рода должна быть малой - равной выбираемому значению - уровню значимости:
P{ отклонить H / H верна} = P{ X 2 h / H } P{2m-1 h} = ,
откуда
h = Q( 1-, n -1) (3)
- квантиль уровня 1- распределения хи-квадрат с m -1 степенями свободы.
Процедура (2) - (3) проверки Н может быть записана иначе: гипотеза Н отклоняется, если
P{2m-1 X2} , (4)
т.е. если мала вероятность получения (при справедливости Н) такого же расхождения, как в опыте (т.е. X2), или ещё большего. Вероятность слева в (4) называется минимальным уровнем значимости (при любом значении , большем P{X2m-1 X2}, гипотеза, очевидно, отклоняется).
2. Проверка сложной гипотезы о вероятностях
Пусть A1, ...,Am -mисходов некоторого опыта,n- число независимых повторений опыта,1,...,m - числа появлений исходов. Проверяемая гипотезаНпредполагает, что вероятности исходовP(Ai)являются известными функциямиpi(a) k-мерного параметраa = (a1,...,ak), т.е.
Н: Р(Аi) = pi(a), i = 1, ..., m,
но значение анеизвестно.
Для проверки гипотезы Нопределим статистику
 (6)
(6)
По теореме Фишера, если Нверна, то приnраспределение статистикиХ2асимптотически подчиняется распределению хи-квадрат с числом степеней свободыf = m-1- k,и потомуотклоняем Н, если
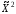 h,
(7)
h,
(7)
где h = Q(1-, f) - квантиль уровня 1-распределения хи-квадрат с числом степеней свободыf; такой порог обеспечивает выбранный уровеньвероятностиP(отклонитьН / Н) ошибки 1-го рода. Если (7) не выполняется, делаем вывод, чтонаблюдения не противоречат гипотезе. Распределению хи-квадрат сf = m-1-kстепенями свободы асимптотически подчиняется также статистика
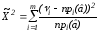 , (8)
, (8)
где
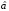 - оценка максимального правдоподобия
дляа, и потому в (7) может быть
использована статистика (8) вместо (6).
Процедура (7) может быть записана иначе:
если
- оценка максимального правдоподобия
дляа, и потому в (7) может быть
использована статистика (8) вместо (6).
Процедура (7) может быть записана иначе:
если
P{f2 X2} (9)
то гипотеза Нотклоняется.
Проверка гипотезы о типе распределения
Пусть
требуется проверить гипотезу о том,
что выборка x1, ..., xnизвлечена из совокупности, распределенной
по некоторому закону, известному с
точностью доk-мерного параметраа=(а1,...,аk).
Оказываются теоретически обоснованными
следующие действия: разобьем весь
диапазон наблюдений наmинтервалов,
определим значенияi-число наблюдений вi-м интервале,
получим значение оценки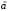 минимизацией (6) или методом максимального
правдоподобия, определим вероятностиpi(
минимизацией (6) или методом максимального
правдоподобия, определим вероятностиpi(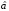 )попадания вi-й интервал, вычислим
(6) или (8) и примем решение по (7).
)попадания вi-й интервал, вычислим
(6) или (8) и примем решение по (7).
Пример 1. Проверка нормальности.
Проверим гипотезу о нормальном законе распределения размеров головок заклепок, сделанных на одном станке, по выборке объема n = 200; измерения приведены в таблице 1. Оценками для а(среднего) и(стандартного отклонения) являются
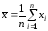 и
и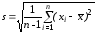
Результаты измерения диаметров заклепок занесем в таблицу с одним столбцом (d) и 200 строками:

Во время работы с модулем «Подбор распределения» наблюдаем оценки параметров Mean:13.42,Variance: 0.018.
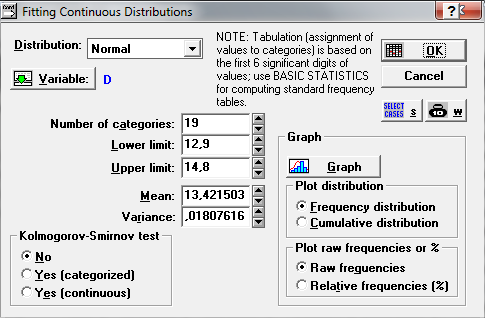
Наблюдаем таблицу частот, в которой нам нужны столбцы observed frequency (наблюдаемые частоты) иexpectedfrequency (ожидаемые частоты). Сравним графически наблюдаемые и ожидаемые частоты: выделим соответствующие столбцы -Graphs - CustomGraphs - 2D Graphs...- OK. Наблюдаем некоторое различие.
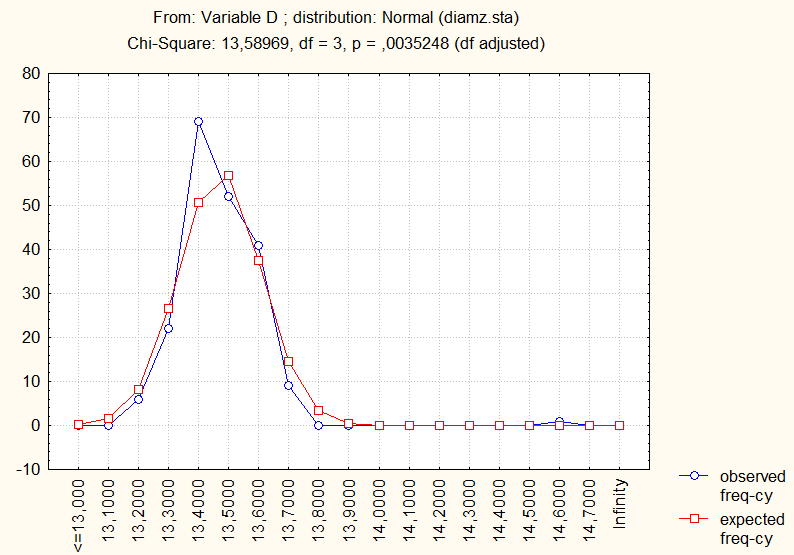
В таблице приведено значение статистики (8) Chi-Square: 13.58969, количество степеней свободыd.f.= 3, которое получилось при объединении интервалов для выполнения условий
np 10,i=1, ...,m;(5а)
10,i=1, ...,m;(5а)
если же mпорядка десяти и более, достаточно выполнения
np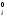 4,i=1,
...,m. (5б)
4,i=1,
...,m. (5б)
: f= 6 - 1 - 2 = 3. Приведено значение вероятности
Р2 3 13.58969=р= 0.00352.
Видно, что в выборке имеется одно аномальное значение 14.56 (№ 188), которое могло появиться в результате какой-либо ошибки (при записи наблюдений, при перепечатке или попалась деталь с другого станка и т.д.). Удалим его и снова проверим гипотезу. Удаление одного наблюдения, если оно типично, не может изменить характеристики совокупности из 200 элементов; если же изменение происходит, следовательно, это наблюдение типичным не является и должно быть удалено.
Чтобы не портить исходные данные, продублируем их в новый столбец, например, dc, и удалим аномальное наблюдение.
Повторим проверку гипотезы для “цензурированной” выборки и убедимся в том, что наблюдения не противоречат гипотезе о нормальности.
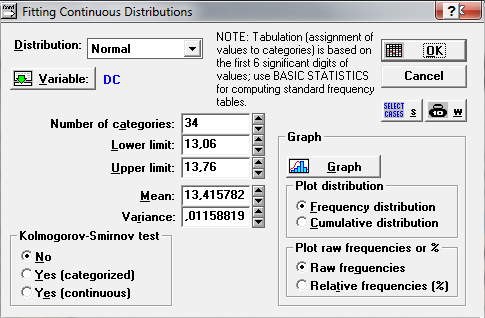
Вероятность получить большое отклонение велика, гипотеза принимается.