

If to nil then with t* do begin
PrintTree (left, h + 1); for i := 1 to h do write) '); write(data: 6); writeln; PrintTree (rigth, h+ 1); end; end;
Звернення в основній програмі до цієї процедури для виве-дення на екран монітора побудованого дерева буде таким:
PrintTree(root, 0);
Якщо виконаємо наведену процедуру виведення вмісту побудованого збалансованого дерева, наприклад для послідовно-сті 2, 5, 1, 7, 6, 3, 10, 9, 4, то отримаємо вигляд дерева, зобра-женого на малюнку 31:
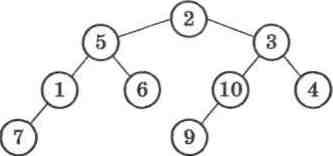
Мал. 31
Щоб визначити операції читання й запису елементів дерева, спочатку треба розібратися з операцією пошуку заданого елемента в дереві. Адже перш ніж вставляти елемент у дерево або вилучати його, необхідно знайти елемент, перед яким або після якого треба виконати відповідну операцію.
Зрозуміло, що дерево формується завжди за певною озна-кою. На відміну від списку, у кожної вершини дерева є два нащадки. Тобто, будуючи дерево, ми спочатку обумовлюемо ознаку, за якою один елемент є лівим, а другий - правим на-щадком для даного.
89
У збалансованому дереві такою ознакою є порядковий номер числа в заданій послідовності: перші числа заимають ліві «позиції» у лівому піддереві, а наступні числа - праві.
Можна також умовою формування дерева визначити якісну характеристику чисел, тобто їх значения: лівим нащадком для кожного числа у вершині дерева буде менше за нього число, а правим - більше. Дерево, побудоване таким чином, називаєть-ся деревом пошуку. Процедура створення такого дерева вигля-дае так:
procedure tree_find (х: integer; var р: Ptr); begin if p = nil then begin new (p); with p" do begin data := x;
left := nil; right := nil; end; end else
if x< p".data
then tree_find (x, pMeft) else treejirtd (x, рл.right); end;
Нехай нам відоме значения елемента дерева х, яке необхідно знайти. Найпростіший алгоритм опису цієї процедури є ре-курсивним. Якщо елемент не знайдено, пройдемо крайньою лі-вою межею дерева, поки не вийдемо на термінальну вершину, в якої покажчик на ліве піддерево дорівнює nil. Потім поверне-мося у найближчу батьківську вершину і здійснимо перехід до правого піддерева. Наступні діі' виконуватимемо аналогічно. Завершениям обходу дерева буде знаходження шуканого елемента або повернення назад у корінь дерева, що означатиме від-сутність у дереві шуканого елемента.
Процедура обходу дерева й одночасного пошуку заданого елемента виглядає так:
procedure search (t: Ptr); begin
if (t <> nil) and (f.data <> x) then with Г do begin
search (t'.left); search (f.rigth); end; end;
Аналогічно можна знайти елемент, для якого лівий або пра-вий нащадок є шуканим елементом, використавши для цього таку умову:
((tMeft <> nil) and (tMeft'.data о х)) or ((t\rigth О nil) and (t\rigth\data о x)).
Тобто можна знайти предка або батьківську вершину для шуканого елемента. Подібні операції ми визначали на структур! даних «список».
Поговоримо про визначення на побудованому дереві опера-цій читання та запису.
Залисати новий елемент у побудоване дерево не так уже й просто. Якщо побудоване дерево є ідеально збалансованим, то запис нового елемента у будь-яке місце порушить цю умову. Тому для збереження структури дерева запис повинен супрово-джуватися його переформуванням. Якщо ж дерево є деревом пошуку, то запис логічно здійснювати лише після відповідних термінальних вершин.
Розглянемо запис нового елемента зі значениям х саме у дерево пошуку. Послідовність дій повинна бути такою:
- «спуститися» гілками дерева до термінальної вершини за виконання умови х < p'.data або х > p".data;
— дописати елемент зі значениям х у визначене місце. Текст відповідної процедури повністю збігається із наведе-
ною вище процедурою створення дерева пошуку tree_find.
Читання заданого елемента з дерева є значно складнішою операцією. Треба вилучити елемент із побудованої структури, не порушивши при цьому закону ЇЇ будови.
Розглянемо такі три випадки:
-
елемент, що вилучається, є термінальною вершиною;
-
елемент, що вилучається, мае одного нащадка;
-
елемент, що вилучається, мае двох нащадків. Найпростішим є випадок, коли шуканий елемент є термі-
нальною вершиною або вершиною з одним нащадком. Склад-ніше, коли треба вилучити елемент, що мае обох нащадків, оскільки в цьому разі його необхідно замінити на крайній справа елемент його лівого шддерева або ж на крайній зліва елемент його правого шддерева.
Розглянемо створення повної версії процедури вилучення елемента з дерева пошуку поетапно.
Якщо шуканий елемент, значения якого знаходилося за адресою р, є термінальною вершиною, то досить цю адресу за-мінити на nil. Тобто до заміни вміст полів за адресоюр є таким: p".data = х; pMeft = nil; pA.rigth = nil, a після заміни - p = nil.
Якщо шуканий елемент, значения якого знаходилося за адресою р, мае лише одного нащадка, то він мае бути замінений
91
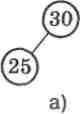
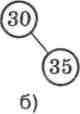
на нього. Це означає, що якщо відсутній правий нащадок (мал. 32, а), то шуканий елемент, що розташований за адре-сою р, мае набути значения елемента, що розташований зліва за адресою pMeft: р := pMeft. Якщо ж відсутній лівий нащадок (мал. 32, б), то шуканий елемент мае набути значения елемента, що розташований справа за адресою p".rigth: р := p'.rigth.
Коли ж шуканий елемент, що розташований за адресою р, мае двох нащадків, то його необхідно замінити крайнім справа нащадком у лівому піддереві. Чим це мотивовано? По-перше, це повинен бути елемент, що є термінальною вершиною, оскільки після його вилучення дерево пошуку не потребуе пе-ребудови і ми вже вміємо таку вершину вилучати. По-друге, цей елемент буде більший за лівого нащадка елемента, що ви-лучається, і менший за правого нащадка. Це слідує з умови по-будови дерева пошуку.
Найкраще розглянути конкретний приклад дерева і пере-свідчитися в логіці попередніх тлумачень (мал. 33).
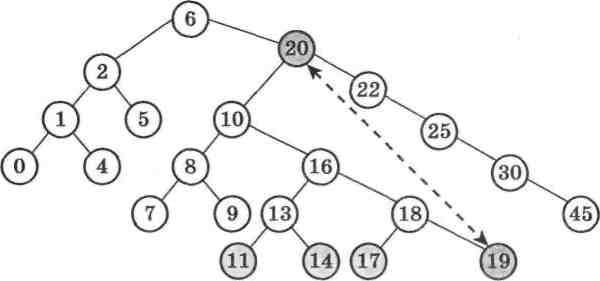
Мал. 33
Насамперед звернемо увагу на те, що для будь-якого елемента дерева пошуку, що не є термінальною вершиною, справ-джуеться тлумачення: всі елементи лівого шддерева менші за нього, а правого - більші. Саме на цьому буде грунтуватися на-ступне роз'яснення.
92
Нехай треба вилучити елемент дерева пошуку зі значениям 20. 3 малюнка видно, що справді всі елементи лівого під-дерева менші за цей елемент, а правого - більші за нього. На місце числа 20 ми повинні поставити елемент, менший за нього, щоб не порушити структуру правого піддерева. Такі елементи є лише у лівому піддереві. Але одночасно цей елемент повинен бути більший за його лівого нащадка, тобто більший за 10. Ця умова повинна бути збережена після переміщення, щоб не порушити структуру лівого піддерева. Такий елемент є у правому піддереві для вершини 10, оскільки саме тут розміщені всі елементи, більші за значения його вершини.
На перший погляд претендентом на переміщення може бути будь-яка з термінальних вершин 11, 14, 17, 19: для всіх цих значень лівий нащадок за значениям менший, а правий - біль-ший. Однак насправді лише термінальна вершина 19 може бути переміщеною на місце вершини зі значениям 20. Саме ЇЇ значения на новому місці не порушить структури дерева пошуку. Адже якщо на місце вершини 20 помістити вершину зі значениям 11, то в її лівому піддереві знайдуться елементи, більші за її' значения, наприклад числа 13, 18, 17, 16, і таким чином структура дерева буде порушена.
Отже, з погляду на побудову алгоритму для пошуку вершини, яка є претендентом на переміщення, необхідно весь час правою гілкою спускатися правим піддеревом вершини 10 до термінальної вершини. На цьому шляху ми дійдемо саме до шуканої термінальної вершини 19.
Тепер можемо записати послідовність описаних дій у вигля-ді процедури з відповідними коментарями:
procedure del (var р: Ptr; х: integer); var q: prt;
procedure d (var r: Ptr); {Рекурсивна процедура пошуку}
begin {крайнього справа найбільшого елемента.}
if rA.right <> nil {Будемо рухатися в глибину цього піддерева)
then d (rA.right) {крайньою справа гїлкою.}
else
begin
{Для знайденоі термінальноТ вершини} q'.data := r".data; q := г; {перенесемо посилання.}
{Вилучимо вершину зі значениям 19,} Г := г".left {записавши на її місце лівого нащадка.}
end; end; begin if p = nil
then writeln ('Шуканого елемента в дереві немає')
{Якщо шуканий елемент менший за значения} else if x<p\data {даноі вершини, то рухаємося вліво;}
93
end;
then del (pMeft, x)
{якщо шуканий елемент більший за значения} else if х > p".data {даної вершини, то рухаємося вправо;} then del (рл.right, x)
else {якщо шуканий елемент знайдено в дереві}
begin {у вершині з адресою р, то збережемо}
q := р; {його адресу в змінній q;}
{якщо в дано! вершини немає правого} {піддерева, то ви лучимо її, записавши} if q". right = nil
{на це місце вершину лівого піддерева;} then р := qMeft
{якщо в даноі вершини немає лівого} {піддерева, то вилучимо м, записавши} else if qMeft = nil
{на це місце вершину правого піддерева;} then р := q".right
{якщо в дано? вершини є обидва}
{піддерева, то перейдемо до Щ
{лівого нащадка, викликавши}
{рекурсивну процедуру.}
else d (qMeft);
{Вивільнимо пам'ять} dispose (q); {у купі від змінноі q.)
end;
Структура даних «дерево» так само, як i «список*, є структурою послідовного доступу, ми можемо знайти будь-який ви-значений елемент дерева, тільки починаючи з кореня дерева і рухаючись далі його гілками.
/ Запитання для самоконтролю
-
Яка структура даних називається деревом?
-
Зобразіть схематично дерево як структуру даних.
-
Наведіть приклади представления інформації у вигляді дерева.
-
Яке дерево називається упорядкованим?
-
Яка вершина дерева називається нащадком для даноі вершини?
-
Яка вершина дерева називається предком для даної вершини?
-
Яка вершина дерева називається коренем?
-
Що називається глибиною дерева?
-
Яка вершина дерева називається термінальною, а яка - внут-рішньою?
-
Як визначається степінь вершини і степінь дерева?
-
Як визначається довжина шляху до задано! вершини?
-
Як визначається довжина внутрішнього шляху всього дерева?
-
Як визначається довжина зовнішнього шляху всього дерева?
-
Які дерева називаються двійковими? Наведіть приклади двійко-вих дерев.
94
-
Запишіть опис структури даних «двійкове дерево» мовою Pascal та зобразіть його схематично.
-
Зобразіть схематично відображення на пам'ять комп'ютера еле-ментів двійкового дерева.
-
Поясніть принцип побудови ідеально збапансованого дерева.
-
Запишітьрекурсивнуфункцію побудови ідеальнозбалансовано-го дерева.
-
Запишіть процедуру виведення на екран монітора вмісту побудованого дерева.
-
Зобразіть збалансоване дерево, побудоване зі значєнь наведено! послідовності цілих чисел.
-
Поясніть принцип побудови дерева пошуку.
-
Запишіть процедуру побудови дерева пошуку.
-
Поясніть послідовність виконання дій при обході або перегляді елементів дерева.
-
Поясніть алгоритм запису нового елемента в дерево пошуку.
-
Поясніть алгоритм читання елемента з дерева пошуку.
-
Наведіть приклад дерева пошуку І продемонструйте алгоритм читання з нього деякого елемента.
-
Запишіть процедуру читання (вилучення) заданого елемента з дерева пошуку і поясніть роботу кожного оператора.
-
Який принцип доступу здійснюється до елементів дерева? Обґрунтуйте свою відповідь.
Завдання
-
Розробити програму побудови ідеально збалансованого дерева, елементами якого є цілі числа, що читаються з текстового файла. Передбачитй виведення вмісту побудованого дерева на екран монітора.
-
Розробити програму побудови ідеально збалансованого дерева, елементами якого є слова, що читаються з текстового файла. Передбачитй виведення вмісту побудованого дерева на екран монітора.
-
Розробити програму побудови дерева пошуку, елементами якого є цілі числа, що читаються з текстового файла. Передбачитй виведення вмісту побудованого дерева на екран мо-нітора.
-
Розробити програму побудови дерева пошуку, елементами якого є слова, що читаються з текстового файла. Передбачитй виведення вмісту побудованого дерева на екран монітора.
-
Розробити діалогову меню-орієнтовану програму роботи з елементами дерева пошуку за такими пунктами:
-
записати новий елемент у дерево;
-
прочитати заданий елемент із дерева;
-
вивести вміст дерева на екран монітора;
-
завершити роботу з деревом.
6. Протестувати розроблену програму в завданні 5, спостері- гаючи за вмістом побудованого дерева пошуку, за такою схемою:
95
-
записати новий елемент у дерево;
-
прочитати елемент дерева пошуку, що є термінальною вершиною;
-
прочитати елемент дерева пошуку, що мае лише правого нащадка;
-
прочитати елемент дерева пошуку, що мае лише лівого нащадка;
-
прочитати елемент дерева пошуку, що мае двох нащадків і не е коренем дерева;
-
прочитати елемент дерева пошуку, що мае двох нащадків і е коренем дерева.
7. Зробити письмовий аналіз виконання завдань 5, 6.
ХЕШ-ТАБЛИЦЯ
3 англійської мови слово hash перекладаеться «рубати», «кришити». Такий переклад справді відповідає ідеі', покладе-ній в основу структури даних «хеш-таблиця».
Ми з вами вже знаемо, що у випадку обробки великої кіль-кості інформації з її елементів можна утворити список. У цій структурі даних визначені операції пошуку, додавання та ви-лучення елементів, що носять назву «словникових». Однак список е структурою послідовного доступу, що зі збільшенням кількості елементів списку значно погіршує в часі виконання зазначених операцій. Який вихід у цьому разі можна запро-понувати? Зрозуміло, що чим менший список, тим швидше у ньому здійснюється пошук. Тому давайте розіб'ємо його на частини. Тепер послідовність пошуку буде такою: спочатку треба лише визначити, в якій із цих частин міститься шуканий елемент, а потім знайти його.
Наступний матеріал буде присвячений питаниям визначен-ня алгоритмів поділу інформації на окремі частини та принципу організацїї такої побудови інформащї.
Розглянемо задачу створення словника. За традицією всі слова, наприклад, українського словника розбиті на групи за алфавітом: першою е група слів на літеру «А», потім на літеру «Б» і т. д. Тому знайти потрібне слово у словнику просто. Однак у будь-якому словнику кожна така група містить різну кіль-кість слів, і це визначає нерівномірний розподіл слів у трупах. А тому в одних трупах, наприклад у словах на літеру «Є», пошук здійснюватиметься швидше, а в інших - набагато довше, наприклад у словах на літеру «А». Давайте запам'ятаемо цю особливість побудови словників, на яку ми зараз звернули ува-гу, і повернемося до цього факту трохи пізніше.
96
Щоб не склалася думка про те, що подібний поділ на групи можна використовувати лише для елементів, якими є слова, наведемо приклади іншої інформації, що може оброблятися по-дібним чином. Можна розглядати також числову інформацію, інформацію про кадри підприємства, про учнівський колектив школи, множину ідентифікаційних кодів громадян держави тощо. Якщо наведена на початку словникова інформація є мно-жиною елементів типу string, то наступна - будь-який число-вий тип, а останні приклади є інформацією, що описуються типом record.
А тепер перейдемо до розгляду питань щодо визначення ал-горитмів поділу елементів, з яких складається інформація, на групи.
Введемо поняття ключа key(x) елемента х, що призначений для його ідентифікації. Найчастіше елемент динамічної множини - це запис, що складається з кількох полів. Саме одним із полів і є ключ даного елемента. Інші поля - це додаткова ін-формація про елемент: його значения, покажчик на наступний за ним елемент, на попередній елемент тощо.
Отже, надалі вважатимемо, що елемент множини шукаеть-ся за ключей. У багатьох випадках усі ключі різні, і тоді множину можна розглядати як функцію, яка кожному існуючому ключу ставить у відповідність деяку додаткову інформацію. Найчастіше в якості ключів можуть бути числа або слова, що, як ми зазначали вище, є безпосередньо значениями елементів. У цьому разі можна говорити, наприклад, про існування деяко-го лексикографічного порядку для елементів множини, а саме про наименший елемент або про елемент, який є безпосередньо наступним за даним.
Наприклад, якщо множиною елементів є ідентифікаційні коди, то ключей може бути цей код, якщо слова, то, можливо, порядковии номер цього слова в упорядкованій послідовності всіх слів тощо.
У термінах введеного поняття ключа елемента можна говорити про розв'язання поставлено! задачі. Платформою для цього буде створення масиву, порядковии номер якого збігається з ключей елемента задано* множини, а вмістом - покажчик на цей елемент, тобто його адреса в пам'яті комп'ютера: А[кеу(х)] = х. У цьому разі доступ до елементів буде набагато швидшим, а саме — прямим. Такий спосіб організації вхідної інформації називається прямою адресацією (мал. 34).
4 Інф..|іиатіп.іі 'І Юіел 97
о
1
2 3
4 б б 7 8
9
|
А |
ключ дода |
||
|
0 |
|
\ / |
|
|
1 •- |
^ |
1 |
|
|
Я •- |
2 |
|
|
|
Ci ^ |
^ |
||
|
3 |
|
|
|
|
4 |
|||
|
|
|
5 |
|
|
|
|
||
|
6 |
|
|
|
|
7 |
|||
|
в а |
fc |
8 |
|
|
О » |
|
||
|
9 |
|
|
|
Мал. 34
На малюнку сірим кольором позначені ті елементи масиву, які мають посилання на nil, тобто у множині немає елементів, ключ яких збігається з цим порядковим номером елемента масиву А. Однак зрозуміло, що при великій кількості вхідної інформації можуть виникнути проблеми з розміщенням у па-м'яті. Саме в цьому і полягає досить очевидний недолік прямої адресації:
-
коли множина всіх можливих ключів велика, то зберігати в пам'яті такий масив непрактично, а інколи й неможливо;
-
якщо число реально існуючих у таблиці записів менше за кількість її елементів, то в цьому випадку пам'ять використо-вується неефективно.
Розглянемо іншу стратегію організації збереження інфор-мації. Нехай існує такий алгоритм визначення ключів елемен-тів, при якому всю їх множину можна поділити на групи, в яких елементи мають однаковий ключ. Назвемо ці групи сегментами. Для того щоб зберігати елементи сегментів, вико-ристаємо списки. Отримаємо фактично масив посилань на ад-реси списків елементів, що мають однаковий ключ.
Використанням ідеї застосування списків для елементів з однаковими ключами ми вирішили колиию, яка полягає у тому, що декілька елементів матимуть однаковий ключ.
Зрозуміло, що при такій організації інформації масив може мати набагато меншу кількість елементів. У найгіршому випадку кількість його елементів буде дорівнювати кількості елементів множини значень.
На малюнку 35 видно, що не всі ключі, передбачені в ма-сиві А, притаманні елементам задано!' множини.
98
|
|
|
nil |
|
|
||||||
|
|
|
|
|
|
||||||
|
|
|
ftj |
|
^ |
к |
|
|
nil |
||
|
|
|
|
w |
|
|
|||||
|
|
|
nil nil ni! |
|
|
|
|
||||
|
|
|
|||||||||
|
|
|
|
||||||||
|
|
|
|||||||||
|
|
|
|
|
|
|
|
||||
|
|
|
A, |
|
|
*, |
|
|
A, |
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
nil |
|
|
|
|
|
|
||
|
|
|
|
||||||||
|
|
|
h |
|
|
nil |
|||||
|
|
|
|
|
П1І |
|
|||||
|
|
*1 |
|
|
fe. |
|
|
nil |
|||
|
|
|
|
|
|
|
|||||
|
|
|
nil |
|
|
|
|
||||
|
|
|
|
||||||||

Мал. 35
Таким чином, масив тепер міститиме посилання на адреси, з яких починаються відповідні списки. Такий спосіб представления інформації називається хешуванням списками, а структура даних, організована таким чином, - хеш-таблицею.
Структура даних, організована за принципом хешування інформації, називається хеш-таблицею.
Проаналізувавши всі можливі ситуації щодо поділу елемен-тів заданої множини на групи, можна дійти висновку, що в найгіршому випадку при хешуванні списками може трапи-тися, що ключі всіх елементів збігаються і таблиця зводиться до одного списку довжини N. Зрозуміло, що в такому разі хешування беззмістовне.
Яким чином інформація, що міститься у хеш-таблиці, відоб-ражаеться на пам'ять комп'ютера? Ми, фактично, поділили всю множину елементів на окремі підмножини (списки), роз-містили їх у динамічній пам'яті і записали адреси їх початків у одновимірний масив. Отже, в пам'яті комп'ютера буде роз-мщений одновимірний масив, елементами якого будуть значения адрес початків відповідних списків. Якщо реалізація хеш-таблиці проходитиме в середовищі Turbo Pascal 7.0, то кожний елемент такого масиву займатиме 4 байти, а довжина його може бути майже 16 000 елементів. Саме стільки списків може бути використано і в хеш-таблиці. Зважаючи на те, що кожний список реалізується в окремому сегменті розміром 64 Кб, можна уявити собі і розміри задано! множини значень, для обробки яких застосована хеш-таблиця.
I
99
Тепер перейдемо до розгляду питания про принцип ПОДілу заданої множини елементів на групи.
Нехай якимось чином ми визначили, що при загальній кількості слів N списків елементів може бути не більш як т. Пронумеруємо їх від 0 до т - 1. Зазначимо, що у випадку рів-номірного розподілу в списках може бути по N/m елементів. Тоді схематично базова структура при відкритому хешуванні виглядатиме так (мал. 36):
О
1
от-1
Мал. 36
Надалі будемо казати, що масив, який називаеться таблицею сегментів (hash table) і проіндексований номерами сег-ментів О, 1, ..., т ~ 1, містить заголовки для т списків.
Опис хеш-таблиці виглядатиме так:
type segment = "seg; seg = record
element: integer; next: segment; end; hash = array[0.. 99] of segment;
Перейдемо до обговорення питания про визначення найоп-тимальнішого алгоритму поділу задано! множини елементів на сегменти-списки, тобто максимально рівномірного їх розподі-лу по списку.
Пошук сегмента здійснюється за принципом прямого доступу, оскільки адреси сегментів містяться в масиві. Пошук шу-каного елемента в сегменті здійснюється послідовно, оскільки сегмент організований як список. Логічно, що пошук заданого елемента у відповідному сегменті залежатиме, в першу чергу, від його розміру. Саме цей факт і є причиною обговорення питания, як найкраще поділити всю множину елементів на сегмента.
Нагадаемо приклад розподілу слів у словнику, що був наведений вище. При поділі слів на групи за першою літерою ці групи матимуть різну кількість слів і пошук у них здійснювати-меться не однаково швидко. Чи можна ці слова поділити за якоюсь іншою ознакою? Так, можна.
100
Зрозуміло, що найефективнішим пошук буде в тому разі, якщо сегменты матимуть максимально рівні розміри. Як ми вже зазначали вище, якщо задана множина складається з N елементів, тоді середня довжина списків повинна бути N/m. Причому чим ближче буде т до N, тим меншими будуть роз-міри сегментів і тим швидше здійснюватиметься пошук необидного елемента.
Надалі будемо говорити, що деякий елемент х і-го списку -це елемент заданої множини, для якого h(x) • і. Тобто існує деяка залежність — хеш-функція h(x), що для кожного елемента визначає порядковии номер сегмента-списку, в якому він міститься.
Для того щоб рівномірно розподілити елементи у сегментах, застосуємо випадковий принцип, що майже не залежить від х. Ідея побудови такої функції полягає у використанні методу ді-лення з остачею:
h(x) = xmodm.
Ми бачимо, що в даному алгоритмі велике навантаження щодо ефективності поділу елементів на сегмента лягае на вибір значения т. Дослідженнями доведено, що гарні результати отримуються, коли в якості т взяти просте число, яке досить сильно відрізняється від степеня двійки.
Розглянемо приклад побудови хеш-таблиці для множини з 2000 елементів. Як визначити просте число, яке б підійшло найкращим чином? Якщо нас зможе влаштувати варіант, коли у кожному сегменті буде в середньому три елементи, то в якос-ті значения т можна взяти 701. Це можна пояснити тим, що 701 ~ 2000/3 і воно не є степенем двійки: h(x) = х mod 701.
Ще один алгоритм побудови хеш-функції базується на метод! множення і полягае в наступному. Нехай кількість хеш-значень дорівнює т. Зафіксувавши константу К в інтервалі (0; 1), визначимо функцію так:
h (х) = trunc(m * frac(K * х)), де frac(K * х) - дробова частина К * х.
Яким же повинно бути значения константи К7 Взагалі метод множення спрацьовує при будь-яких значеннях К, але деякі з них можуть бути кращими за інші. Дональд Кнут, автор відо-мого тритомного видання «Мистецтво програмуваиня для ЕОМ», у результаті своїх досліджень дійшов висновку, що най-
>/5-1 кращим буде значения К 0,6180339887...
Наведемо приклад обчислення значения хеш-функщї методом множення для х = 123 456 і т = 10 000:
101
h( 123456) =trunc( 10000 " frac(0. 6180339887 * 123456)) = trunc( 10000 * frac (76300. 0041089472)) = trunc( 10000 " 0. 0041089472) = 41.
Зрозуміло, що при застосуванні обох алгоритмів обчислення хеш-значень вони попадатимуть до інтервалу цілих чисел [0; т - 1].
Хеш-функція для елементів множини, що є цілими числами, в термінах Pascal-програми буде такою:
function h (х: integer): 0.. m - 1; begin
h := <метод обчислення функції> end;
У випадку, коли елементами множини є слова, можна запропонувати такий алгоритм побудови хеш-функції: підсу-муємо всі цілочислові коди символів кожного елемента-слова, використовуючи стандартну функцію ord(x), і до результату підсумовування застосуємо певний алгоритм:
function h (х: string): 0.. m - 1; vari, sum: integer; begin
sum := 0;
for i := 1 to length(x) do sum := sum + ord(x[i]); h := <метод обчислення функції > end;
Шдсумуємо наведені пояснения. За задании ключем х і хеш-функцією h(x) можна визначити номер сегмента i, якому на-лежить пей ключ. А це, у свою чергу, дає нам змогу визначити адресу початку списку А[і], в якому розміщені елементи даного сегмента.
Перейдемо до розгляду основних операцій над елементами хеш-таблиць.
Перш за все необхідно підготувати масив посилань на сегмента, де знаходяться списки елементів множини:
procedure MakeNull (var A: hash); var i: integer; begin
for i := 0 to m - 1 do A[i] := nil end;
Пошук елемента в хеш-таблиці здійснюється за такою послі-довністю дій:
102
 function
find
(x:
string; A:
hash): boolean;
var
current:
segment; begin
function
find
(x:
string; A:
hash): boolean;
var
current:
segment; begin
{Визнзчення адреси початку сегмента, де може знаходитись х.} current := A[h (х) ];
find := true; {Початкове значения функції - true.}
while (current <> nil) and (current".element <> x) do
current := current".next; {Пошук у списку елемента х.}
{Якщо елемент не знайдено, повертасмо false.} if current = nil then find := false; end;
Запис, або вставления, нового елемента в хеш-таблицю за відсутності його в ній раціональніше робити у відповідний сегмент на самому його початку:
procedure ins (х: string; var A: hash);
{Оскільки хеш-таблиця зміниться, використовуємо var A.} var і: word;
OldHeader: segment; begin
begin
i:=h(x);
OldHeader :=A[i];
new(A[i]);
A[i]\element := x;
if not find (x, А) (Якщо елемент x у відповідному сегменті не знайдено, то} then
{визначаємо номер списку,}
{якому повинен належати елемент х;}
{запам'ятаємо адресу списку,}
(де повинен знаходитись х;}
{визначаємо нову адресу початку сегмента;}
{в поле значения елемента записуємо х;}
{в поле адреси записуемо попередню адресу}
{початку даного списку; тепер список буде}
A[i]".next := OldHeader {починатися з нового елемента /',}
end; {до нього буде «причеплена» стара частина списку.}
end;
Читання, або вилучення, заданого елемента з хеш-таблиці:
procedure del (х: string; var A: hash);
{Оскільки хеш-таблиця зміниться, використовуемо var А.} var i: word;
current: segment; begin
if find (x, А) {Якщо елемент x у відповідиому сегменті знайдено, то}
then begin
І := h (x); {визначаємо номер списку, якому належить елементх.}
if А[і]л.element = X {Якщо елементх стоїть у списку першим, то}
thenA[i] := A[i]\next {вилучаємох зі списку.}
else {Якщо елемент х стоіть у списку не першим, то}
begin
{визначаємо адресу початку сегмента,} current := A[i]; {де може знаходитисях.}
103
end;
{Пошук у списку еломента зі значениям X.} while (current".next О nil)
and (current".next".element <> x) do current := current".next;
{Вилучаємо елементхзі списку.} current".next := current".next".next end; end;
При використанні відкритих хеш-таблиць середній час ви-конання операцій зростає зі зростанням значения N/m. Особливо швидко він росте при перевищенні кількості елементів над кількістю сегментів. Для збереження стабільного часу виконання операщй над відкритою хеш-таблицею пропонуєть-ся при досягненні N досить великих значень створити нову хеш-таблицю з подвоєною кількістю сегментів. Наприклад, це раціонально робити для N > 2m. Така процедура називається реструктуризацією. Час на створення нової хеш-таблиці нада-лі компенсується більшою швидкістю виконання операцій зі збільшеним словником.
Нам залишилося розібратися, яким же с принцип доступу до елементів хеш-таблиці. Оскільки елементи списків доступні для перегляду посередництвом одновимірних масивів, елементи яких містять адресу початку даного списку в пам'яті комп'ютера, дана структура вважаеться структурою прямого доступу. Справді, оскільки доступ до інформації в масиві с прямим, тому й обробка інформації в хеш-таблиці буде набагато швидшою, ніж у тому випадку, якби весь словник було орга-нізовано як структуру даних «список».
/ Запитання для самоконтролю
-
Сформулюйте задачу обробки словниковоТ інформації.
-
Що називається ключем елемента х?
-
Який спосіб організації інформації називається прямою адреса-цією?
-
Які проблеми можуть виникнути при прямій адресаціі інфор-мації?
-
У чому полягає ідея хешування інформації? У чому полягає ко-лізія при такій організації інформаціі?
-
Що називається сегментами та хеш-таблицею?
-
Яким чином структура даних «хеш-таблиця» відображається на пам'ять комп'ютера?
-
Зобразіть схематично базову структуру при хешуванні списками.
-
Як виглядає опис хеш-таблиці мовою Pascal?
10. Як можна зробити обробку елементів хеш-таблиці ефектив-нішою?
104
-
 Яка
функція
називається хєш-функцією?
Яка
функція
називається хєш-функцією? -
Які існують алгоритми побудови хеш-функціі, що дають можли-вість більш-менш рівномірно розподілити елементи в сегментах?
-
Як визначаються параметри при обчисленні хеш-функцій за різ-ними алгоритмами? Обґрунтуйте свою відповідь.
-
Запишіть текст обчислення значень хеш-функції мовою Pascal.
-
Запишіть текст процедури пошуку елемента в хеш-таблиці та поясніть алгоритм, за яким вона працює.
-
Запишіть текст процедури запису елемента в хеш-таблицю та поясніть алгоритм, за яким вона працює.
-
Запишіть текст процедури читання елемента з хеш-таблиці та поясніть алгоритм, за яким вона працюе.
-
Що називається реструктуризацією хеш-таблиці? Для чого вона використовується?
-
Який принцип доступу здійснюється до елементів хеш-таблиці при їх обробці? Обґрунтуйте свою відповідь.
Завдання
1. Розробити діалогову меню-орієнтовану програму роботи з елементами хеш-таблиці за такими пунктами:
-
записати елемент у хеш-таблицю;
-
прочитати елемент із хеш-таблиці;
-
здійснити пошук елемента в хеш-таблиці;
-
завершити роботу з хеш-таблицею.
2. Протестувати програму завдання 1 для N - 100, застосу вавши для визначення хеш-функції метод ділення з остачею, за такою схемою:
-
створити хеш-таблицю, використавши процедуру запису елементів;
-
перевірити відсутність у хеш-таблиці елемента, що запи-сується;
-
записати цей елемент у хеш-таблицю;
-
перевірити наявність записаного елемента у хеш-таблиці;
-
перевірити наявність у хеш-таблиці елемента, що вилу-чаеться;
-
вилучити цей елемент із хеш-таблиці;
-
перевірити відсутність вилученого елемента у хеш-таб-лиці;
-
записати 10 нових елементів у хеш-таблицю, перевіряючи їх наявність у ній після запису;
-
виконати реструктуризацію хеш-таблиці.
-
Зробити письмовий аналіз виконання завдань 1,2.
-
Виконати завдання 1 для тієї самої вхідної інформації, застосувавши для визначення хеш-функції метод множення. Зробити письмовий аналіз виконання програми.
-
Порівняти результати виконання завдань 2 і 4. Зробити письмовий аналіз порівняльної характеристики.
105
10 1
Розділ IV
ооііоіI
0 0 0 D
10 10!
ОСНОВНІ
П0ШУК0ВІ АЛГОРИТМИ
ПОНЯТТЯ ПОШУКОВИХ АЛГОРИТМІВ
Пошук необхідної інформації - це одна з фуидаментальних задач теоретичної інформатики та програмування. Саме пошу-кові алгоритми найчастіше є фрагментами різноманітних більш складних алгоритмів.
Пошуковими алгоритмами називають алгоритми, що здійснюють пошук потрібної інформації у множині заданих елементів.
Пошукові алгоритми закладені в основи багатьох електрон-них систем обробки інформації: придбання квитка в заліз-ничних касах, отримання інформації про необхідний номер телефону в довідковій телефонній службі, користування пошуковими сайтами в Інтернеті, пошук інформації в будь-яких текстових редакторах тощо.
Ми також часто здійснюємо пошук і без використання ком-п'ютера. Це пошук інформації у довідниковій літературі, де інформація упорядкована за алфавітом, чи в будь-якій іншій книжці, де інформація не мае упорядкованого вигляду, але існує хоча б зміст.
Переходячи до питань алгоритмізації, слід зазначити, що пошук є ідеальною задачею, на якій можна розглядати відомі нам структури даних і застосовувати на них різноманітні алгоритми, досліджуючи при цьому їх ефективність.
Розглядаючи структури даних, ми вже торкнулися питания пошуку інформації у множині їх елементів. Тепер нашим зав-данням буде більш ретельний аналіз оцінки ефективності вико-нання тих чи ініпих пошукових алгоритмів на різних структурах даних.
Саме тому визначимо такі основні аспекти ознайомлення з пошуковими алгоритмами.
При обговоренні пошукових алгоритмів вважатимемо, що інформація описується певчими структурами даних. Якщо щ структури даних будуть складеними, такі, наприклад, як записи, що складаються з кількох полів, то нас цікавитиме значения лише одного з цих полів.
106
Тому надалі будемо говорити про деякий абстрактний тип даних item, що описуе запис з деяким полем, що виконуе роль ключа. Наше завдання полягатиме в тому, щоб здійснювати пошук елемента, ключ якого дорівнює заданому «аргументу пошуку» х. Отриманий у результаті індекс і, що задовольняє умову A[i].key = х, забезпечує доступ до інших полів знайденого елемента. Але надалі спростимо опис структури, мотивуючи це таким. Оскільки нас у першу черту цікавить сам процес пошуку, а не дані структури, то вважатимемо, що тип item і є тим самим ключей.
I останнє, вважатимемо, що група даних, у якій здійснюєть-ся пошук заданого елемента, є фіксованою. Це означатиме, що множина значень задається у кількості N елементів, що може бути описано таким масивом:
A: array[1„ N] of item;
Отже, базуючись на цих основних припущеннях, обгово-римо різні підходи до пошуку інформації у заданій групі еле-ментів.
ЛІНІЙНИЙ ПОШУК
Алгоритм лінійного пошуку
Найчастіше треба відшукати інформацію у невідсортованій послідовності елементів. У цьому випадку пошук зводиться до послідовного перегляду всіх елементів масиву, поки не знайде-мо шуканий елемент. Такий пошук називається лінійним, або послідовним.
Спочатку розглянемо алгоритм поставлено! задачі в такому трактуванні:
-
Задати масив значень А для пошуку.
-
Задати шуканий елемент х.
-
Починаючи з першого елемента масиву до останнього по-рівнювати їх із шуканим елементом І, в разі хоча б одного збі-гання їх значень, зафіксувати дю ситуацію.
-
У разі хоча б одного збігання значень елементів масиву зі значениям шуканого елемента, повідомити про це. У протилеж-ному випадку повідомити про відсутність шуканого елемента в заданому масиві значень.
Запишемо текст фрагмента Pascal-програми, що реалізує описаний алгоритм:
flag := false; for i := 1 to n do
if a[i] = x then flag ;= true;
107
if Hag then writeln ('Шуканий елемент знайдеио')
else writeln ('Шуканий елемент не знайдено');
Оцінкою ефективності роботи наведеного алгоритму є, в першу чергу, кількість порівняпь елементів масиву з шуканим елементом. Який висновок можна зробити, проаналізувавши виконання наведеного алгоритму?
Якщо шуканий елемент збігатиметься лише з ЛГ-м елементом масиву, тобто останнім у масиві, то для отримання результату треба виконати всі кроки циклу. У випадку, коли шуканий елемент збігатиметься з елементом масиву, індекс якого менший за N, то будуть виконані зайві порівняння, тобто перегляд масиву до кінця недоцільний. Тому для запису дослі-джуваного алгоритму ефективніше використати цикл із перед-умовою, який виконуватиметься за таких умов:
— ознака того, що не всі елементи масиву ще переглянуті: i<N;
- незбігання шуканого елемента з поточним елементом масиву: а[і] * х.
Зрозуміло, що обидві ці ознаки повинні виконуватись од-ночасно. Наведений вище алгоритм тепер матиме такий ви-гляд:
-
Почнемо перегляд заданого масиву з першого елемента.
-
Поки шуканий елемент х не збігається з поточним елементом масиву а[і] і ми не вийшли за межі заданого масиву, то перейти до наступного елемента в масиві.
-
Якщо при відшуканні елемента х у масиві ми вийшли за його межі, тобто порядковий номер поточного елемента масиву сягнув значения N, то це означав, що шуканий елемент у за-даному масиві відсутній. У протилежному випадку шуканий елемент знайдено на і-му місці в масиві.
Цьому фрагменту алгоритму відповідає такий текст Pascal-програми:
i:=1;
while (a[i] <> х) and (i <= N) do i := i + 1;
if i <= N then writeln ('Шуканий елемент знайдено')
else writeln ('Шуканий елемент не знайдено');
Зрозуміло, що останній алгоритм набагато ефективніший, ніж перший його варіант. Але і його можна вдосконалити.
Проаналізуємо випадки виконання умови (а[і] О х) and (i <= N) і подумаємо, чи можна ЇЇ спростити. У цій умові ми перевіряє-мо, чи не вийшли за межі заданого масиву і чи збігається поточний елемент масиву з шуканим. Перша частина умови потрібна тільки у випадку, коли ми не впевнені в тому, що шуканий елемент у масиві є. Це означав, що в разі стовідсотко-вої наявності шуканого елемента в масиві цю частину умови
108
можна вилучити. А коли можна бути впевненими в тому, що елемент у масиві точно є? Лише тоді, коли ми самі його туди запишемо! I дописати його треба в кінець масиву, щоб він не заважав відшуканню інших таких елементів, якщо вони в ма-сиві є: a[N + 1 ] := х. Тепер виконання умови a[N + 1 ] = х стверджує той факт, що шуканий елемент відсутній у заданому масиві, оскільки знайдено елемент, який ми штучно дописали в кінець масиву.
Описавши масив a: array[1.. N + 1] of <тип>, перепишемо алгоритм мовою Pascal у такому вигляді:
a[N + 1]:=x;
i:=1;
while (a[i] о х) do i :=i+ 1;
if i<N + 1 then writeln ('Шуканий елемент знайдено')
else writeln ('Шуканий елемент не знайдено');
Можна зробити висновок, що створено ефективний варіант лінійного пошукового алгоритму.
Оцінка ефективності лінійного пошуку напряму залежить від кількості елементів масиву. У найкращому варіанті, коли шуканий елемент знаходиться на першому місці, вона дорів-нює O(l), у найгіршому, коли шуканий елемент знаходиться на останньому місці або зовсім відсутній у масиві, — O(N), а в се-редньому варіанті - 0(N/2). Саме середній варіант можна ви-значити за остаточну оцінку даного пошукового методу.
/ Запитання для самоконтролю
-
Сформулюйте задачу пошуку задано! інформації в заданій групі значень.
-
Які алгоритми називаються пошуковими?
-
Наведіть приклади використання пошукових апгоритмів.
-
Визначте основні аспекти, на яких базується розробка пошукових алгоритмів.
-
У чому полягає лінійний, або послідовний, пошук інформації?
-
Запишіть алгоритм і текст Pascal-програми лінійного пошуку ін-формаціі, при виконанні якого повністю переглядається весь масив.
-
У чому полягає удосконалення попереднього алгоритму? Обґрунтуйте його та запишіть фрагмент алгоритму І текст Pascal-програми.
-
За рахунок чого можна удосконалити умову виконання повторения при пошуку заданого значения величини серед елементів масиву?
-
Запишіть остаточний найефективніший варіант лінійного пошукового алгоритму, що використовує найменшу кількість повторень і перевірок умов.
10. Якою є оцінка ефективності роботи лінійного пошукового алгоритму?
109
 Завдання
Завдання
-
Реалізувати алгоритм лінійпого пошуку заданого елемеп-та в масиві за допомогою циклу з лічильником мовою Pascal.
-
Реалізувати алгоритм лінійного пошуку заданого елемен-та в масиві за допомогою циклу з передумовою мовою Pascal.
-
Реалізувати алгоритм лінійного пошуку заданого елемен-та в масиві за допомогою циклу з передумовою, дописавши шу-каний елемент у кінець масиву мовою Pascal.
-
Порівняти виконання алгоритмів щодо кількості викона-них порівнянь у завданнях 1-3, протестувавши їх для випад-ків, коли шуканий елемент розміщений:
-
на початку масиву;
-
у кінці масиву;
-
посередині масиву.
5. Зробити письмовий аналіз завдання 4.