

Тимофеева, УМК_Математ. методы в филологии
.pdfПример 2. Поиск всех вхождений синтагмы in other words. Анализируется один текст.
Query: in other words
Item type: a Syntagma
# |
Items |
Links |
Freq. |
|
|
|
|
1. |
in other words |
1 (2) |
2 |
|
|
|
|
|
|
|
2 |
|
|
|
|
Пример 3. Поиск всех вхождений словосочетания из трѐх слов The same point. Анализируется один текст.
Query: The same point
Item type: a Word Conjunction x3
# |
Items |
Links |
Freq. |
|
|
|
|
1. |
The same point |
1 (3) |
3 |
|
|
|
|
|
|
|
3 |
|
|
|
|
Пример 4. Поиск всех вхождений словосочетания из трѐх слов does not a* (символ «*» означает, что в третьем слове словосочетания буквы, следующие за первой, могут быть любыми). Анализируется один текст.
Query: does not a*
Item type: a Word Conjunction x3
# |
Items |
Links |
Freq. |
|
|
|
|
1. |
does not add |
1 (1) |
1 |
|
|
|
|
2. |
does not affect |
1 (4) |
4 |
|
|
|
|
3. |
does not apply |
1 (1) |
1 |
|
|
|
|
4. |
does not argue |
1 (1) |
1 |
|
|
|
|
|
|
|
7 |
|
|
|
|
Пример 5. Поиск всех вхождений словосочетания из трѐх слов what is * (символ «*» означает, что третье слово в искомых словосочетаниях может быть любым). Анализируется один текст.
Query: what is *
Item type: a Word Conjunction x3
# |
Items |
Links |
Freq. |
|
|
|
|
1. |
what is asserted |
1 (2) |
2 |
|
|
|
|
2. |
what is being |
1 |
(4) |
4 |
|
|
|
|
|
3. |
what is conventionally |
1 |
(2) |
2 |
|
|
|
|
|
4. |
what is conversationally |
1 |
(3) |
3 |
|
|
|
|
|
5. |
what is expressed |
1 |
(2) |
2 |
|
|
|
|
|
6. |
what is implicated |
1 |
(4) |
4 |
|
|
|
|
|
7. |
what is meant |
1 |
(2) |
2 |
|
|
|
|
|
8. |
what is not |
1 |
(2) |
2 |
|
|
|
|
|
9. |
what is said |
1 |
(88) |
88 |
|
|
|
|
|
10. |
what is the |
1 |
(2) |
2 |
|
|
|
|
|
|
|
|
|
111 |
|
|
|
|
|
Пример 6. Поиск всех вхождений словосочетания из трѐх слов lack of * в двух заданных текстах. Анализируются два текста, использована операция объединения множеств.
Query: lack of *
Item type: a Word Conjunction x3
# |
Items |
Links |
Freq. |
|
|
|
|
|
|
1. |
lack of a |
1 |
(1), 2 (1) |
2 |
|
|
|
|
|
2. |
lack of compelling |
1 |
(1) |
1 |
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
Тема 1.2. Электронные тезаурусы
Электронные тезаурусы позволяют анализировать отношения между заданными лексическими единицами (синонимия, антонимия, гипонимия / гиперонимия, меронимия / холонимия, тропонимия, каузальные отношения и др.). Области использования электронных тезаурусов: снятие неоднозначности при автоматическом анализе текста, измерение семантических расстояний между лексемами, информационный поиск, автоматическая классификация лексики, автоматическое реферирование и индексирование, машинный перевод и др.
Базовая единица электронных тезаурусов – синонимический ряд (синсет). На множестве синсетов определены бинарные отношения:
•гипонимии / гиперонимии
•антонимии
•конверсии
•меронимии / холонимии
•следования
идр.
Отношение гипонимии / гиперонимии (isA-отношение, родовидовое) является центральным для существительных. Это отношение транзитивно и несимметрично. Гипоним наследует все свойства гиперонима.

Отношение меронимии/ холонимии (часть - целое) имеет ряд подвидов:
•компонентобъект (ветка – дерево)
•элемент – множество (дерево - лес)
•порция – материал – (кусок – кекс)
•материал – объект (стекло – бокал)
•часть деятельности (оплата – покупка)
•место – местность (Новосибирск – Россия)
Отношение тропонимии – основа описания иерархии глаголов. Отношение тропонимии является специальным видом отношения следования, для его выявления используется следующий критерий: глаголы V1 и V2 связаны отношением тропонимии (V1 является тропонимом V2), если V1 означает определенный специфический вариант выполнения действия V2 (например, «бормотать» означает «говорить» определѐнным специфическим образом).
Для описания качественных прилагательных базовым является отношение антонимии. Относительные прилагательные описываются посредством соотнесения с синсетами соответствующих существительных.
Разработка тезауруса WordNet («ворднет») началась в Принстонском университете в 1984 г., с 1995 г. словарь появился в Интернете (http://wordnet.princeton.edu/). Инициатором и руководителем проекта WordNet был Джордж Миллер, один из основоположников психолингвистики. Первоначально электронный тезаурус создавался как модель человеческой памяти, при его разработке активно использовались психолингвистические эксперименты. Позже оказалось, что электронные тезаурусы в гораздо большей степени заинтересовали специалистов по компьютерной лингвистике, а не психолингвистов. В течение 1996-1999 гг. были разработаны ворднеты для испанского, голландского, итальянского языков. Позже появились ворднеты для французского, чешского, немецкого, эстонского и других языков.
С 1999 г. на кафедре математической лингвистики СПбГУ (группа под руководством И.В.Азаровой) разрабатывается электронный тезаурус RussNet для русского языка
(http://project.phil.pu.ru/RussNet/index_ru.shtml). На сайте проекта представлена подробная документация. Там же можно скачать фрагмент тезауруса (глаголы эмоционального состояния) и бесплатную демонстрационную версию программы VisDic, предназначенную для просмотра и редактирования wordnet-тезаурусов.
ВПетербургском университете путей сообщения разрабатывается ещѐ один электрон-
ный тезаурус для русского языка: Russian WordNet (http://wordnet.ru/, http://pgups.ru/abitur/inostrancam/inter/ruwordnet/).
Один из масштабных современных проектов – многоязычная лексическая база EuroWordNet (http://www.illc.uva.nl/EuroWordNet/).
Врамках этого тезауруса языки связываются между собой при помощи системы межъязыковых индексов ILI (Inter-Lingual-Index) в большую многоязычную базу данных. Посредством индекса можно переходить от одной структуры WordNet к другой (то есть от одного языка к другому). В качестве базового используется WordNet Принстонского университета, к нему сводятся ворднеты других языков. Ниже приведено схематичное изображение структуры EuroWordNet.

Все разработчики wordnet-словарей объединены в ассоциацию Global WordNet Association (http://www.globalwordnet.org/).
Тема 1.3. Дешифровочные модели языка
Основные виды языковых моделей представлены на следующей схеме, предложенной Ю.Д. Апресяном.
Признаки |
Что известно |
Характер ис- |
Характер |
ко- |
Цель |
Тип |
лингвисту |
ходной ин- |
нечной |
ин- |
|
модели |
|
формации |
формации |
|
|
|
|
|
|
|
|
Исследовательские |
Текст (и мно- |
Текст |
Грамматика и |
Моделирование |
|
|
жество пра- |
|
словарь |
|
деятельности |
|
вильных фраз) |
|
|
|
лингвиста |
|
|
|
|
|
|
Аналитические |
Грамматика и |
Текст |
Изображение |
Моделирование |
|
|
словарь |
|
структуры |
тек- |
понимания текста |
|
|
|
ста |
|
|
|
|
|
|
|
|
Синтетические |
Грамматика и |
Изображение |
Текст |
|
Моделирование |
|
словарь |
структуры |
|
|
производства |
|
|
текста |
|
|
текста |
|
|
|
|
|
|
Порождающие |
Грамматика и |
Алфавит сим- |
Множество |
Моделирование |
|
|
словарь |
волов и пра- |
правильных |
умения отли- |
|
|
|
вила образо- |
фраз и |
изо- |
чать правильное |
|
|
вания и пре- |
бражение |
их |
от неправильно- |
|
|
образования |
структуры |
го в языке |
|
|
|
фраз |
|
|
|
|
|
|
|
|
|
Первый тип моделей («исследовательские») включает так называемые дешифровочные модели, работая с которыми лингвист не использует лингвистическую информацию о языке (возможно, не имеет таковой, если язык ему неизвестен), пытаясь выявить единицы языка и отношения между ними исключительно на основе формальных рассуждений, использующих дистрибутивные и частотные характеристики различных участков текста.
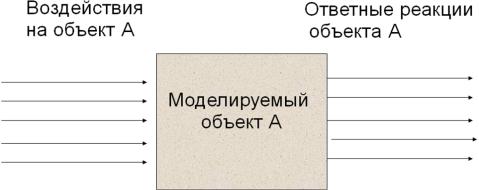
Функциональная модель объекта. Допустим, что имеется некоторый объект А, внутреннее устройство которого мы не знаем и наблюдать не можем. Нас интересует определѐнная функция F, выполняемая этим объектом, и его поведение, направленное на осуществление данной функции, доступно нашему наблюдению. Функциональная модель объекта А воспроизводит это поведение. При этом не предполагается, что такая модель похожа на моделируемый объект А также и по своему внутреннему устройству. Любое представление о внутреннем устройстве объекта А в этом случае может рассматриваться толь-
ко как гипотеза.
В кибернетике при описании и экспериментальном тестировании таких моделей используется понятие «чѐрный ящик» (ненаблюдаемый объект, на который можно оказывать определѐнные виды внешних воздействий–стимулов, и наблюдать реакции, возникающие в ответ на то или иное воздействие).
Человеческую коммуникацию естественно рассматривать именно таким образом, по-
скольку внутреннее устройство языка наблюдать невозможно. Для того чтобы осуще-
ствить такое наблюдение надо было бы заглянуть в сознание говорящих, посмотреть, где и как хранится в нѐм знание языка, какие процессы ответственны за его использование. Достоверных знаний об этом нет. Следовательно, все существующие теории языка, характеризующие его внутреннее устройство, являются лишь гипотезами. Таковы, в частности, все грамматические и семантические теории, фигурирующие в современной лингвистике. О качестве таких теорий можно судить только по тому, насколько хорошо они позволяют выполнять те задачи, для решения которых были созданы.

Далее рассмотрим один из видов функциональных моделей языка, а именно, дешифровочные модели. В качестве иллюстрации, дающей представление о таких моделях, приведѐм задачу из школьной олимпиады по лингвистике и математике.
Задача. Даны глагольные формы старояпонского языка с переводами на русский язык: тасукэдзарубэкарики – он не должен был помогать; тасукэдзарураси – он, наверное, не помогал; тасукэрарэсикаба – если бы ему помогали; тасукэсасэрарэкэри – его заставляли помогать (давно); тасукэсасэки – он заставлял помогать;
тасукэрарэтарики – ему помогли;
тасукэтакарикэри – он хотел помогать (давно).
Задание 1. Переведите на старояпонский язык: ему помогали (давно); если бы он хотел помогать; его, наверное, не заставляли помогать; он помог.
Задание 2. Переведите на русский язык: тасукэсасэрарэдзарубэкарисикаба.
Человек, обладающий хотя бы начальными навыками лингвистического анализа (на уровне средних классов школы), сможет предположить, что для решения этой задачи надо найти японские буквосочетания с общим семантическим компонентом, сравнить их между собой и постараться выяснить, какие именно цепочки букв являются носителями данного элемента смысла.
Похожие соображения были положены в основу определѐнного класса функциональных моделей языка, называемых дешифровочными моделями. Математические модели такого типа разрабатывали, например, Б.В. Сухотин, Н.Д. Андреев, И.И. Ревзин.
Рассмотрим некоторые базовые математические понятия, используемые при формализации языка в рамках дешифровочных моделей. Эти понятия понадобятся и для других разделов данного курса.
V – конечное множество элементарных символов, называемое алфавитом (или словарѐм) рассматриваемого языка
Цепочка над алфавитом V – любая упорядоченная последовательность элементов из V. Считается, что элементы цепочки пронумерованы слева направо.
Пустая цепочка – цепочка, не содержащая ни одного символа, обычно обозначается знаком .
Длина цепочки w обозначается так: |w|.
Пример:
V={ещѐ, в, полях, белеет, снег, а, воды, уж, весной, шумят}
Возможные цепочки над алфавитом V:
белеет в полях снег, весной ещѐ, а снег полях,
шумят уж ещѐ,
,
…
Вхождение элемента w V в цепочку h есть пара w,n , где n – порядковый номер элемента w в цепочке h.
Пример 1. Цепочка h: Бегут и будят сонный брег, бегут и блещут и гласят

Вхождения элементов:
бегут,1 , бегут,6 ,
и,2 , и,7 , и,9 ,
будят,3 , сонный,4 , брег,5 , блещут,8 , гласят,10
Конкатенацией непустых цепочек х и у из алфавита V называется цепочка и ху.
Если для каких-то цепочек v, w, x, y из алфавита V имеет место равенство v= xwy, то будем называть цепочку х w y (где символ не принадлежит V) вхождением цепочки w в
цепочку v.
Если существует вхождение w в v, то будем называть w подцепочкой цепочки v.
Через V* обозначается множество всех цепочек над алфавитом V, включая пустую цепочку .
V+ – множество всех цепочек над алфавитом V, исключая пустую цепочку .
Пример 2. Цепочка h: Ещѐ в полях белеет снег, а воды уж весной шумят
Цепочки над алфавитом V, не входящие в h:
вбелеет, а шумят,
ва уж
Цепочки над алфавитом V, входящие в h:
в полях белеет снег, уж весной, полях белеет.
Пример 3. Рассмотрим другой алфавит символов: V ={х х - буква русского алфавита или пробел}
Цепочка h: Ещѐ в полях белеет снег, а воды уж весной шумят
Цепочки над алфавитом V, входящие в h:
в полях белеет сн, есн, ях
Цепочки над алфавитом V, не входящие в h:
ещѐ еет весной, полях уж ят
Контекст – любая упорядоченная пара цепочек f,g
Пусть F – некоторое конечное подмножество цепочек над алфавитом V (например, множество фраз некоторого языка), F V+
Будем говорить, что слово х допускается контекстом f,g , если цепочка fхg F.
Пусть F = {в полях белеет снег, белеет снег, воды уж весной шумят}
Примеры контекстов:
в полях, снег , слово белеет допускается этим контекстом, так как в F имеется фраза в
полях белеет снег;
 , снег , слово белеет допускается этим контекстом, так как возможна фраза белеет снег.
, снег , слово белеет допускается этим контекстом, так как возможна фраза белеет снег.
Слово х замещает слово у, если любой контекст, допускающий слово у, допускает также и слово х.
Слово х взаимозамещаемо со словом у, если х замещает у и у замещает х. Отношение взаимозамещаемости является эквивалентностью.
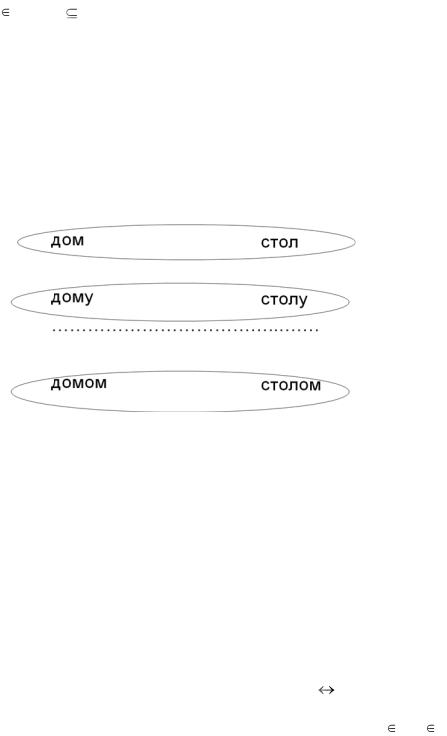
Например, слово слон может оказаться взаимозамещаемоым со словом стол, поскольку эти слова относятся к одному типу словоизменения и замена одного на другое не нарушает грамматической правильности высказывания.
И.И. Ревзин использует формальную модель, основанную на отношении взаимозамещаемости, для определения понятий «падеж», «парадигма», «часть речи», «род».
Допустим, что х V и S(х) V.
Множество S(х) называют семейством, если S(х) включает все такие и только такие слова у, которые взаимозамещаемы с х.
Например, семейство S(слон) может включать слова стол, стул, дом, но не может включать слова весна, бежит, ещѐ.
Семейство объединяет дистрибутивно сходные слова. (Можно сравнить анализ от-
ношения взаимозамещаемости с дистрибутивным анализом, развиваемым в рамках американской структурной лингвистики и детально описанным в книге Г. Глисона Введение в дескриптивную лингвистику).
Ниже приведено схематичное изображение семейств для слов дом и стол.
На основе отношения взаимозамещаемости И.И. Ревзин строит теоретикомножественную типологическую классификацию языков.
Тема 1.4. Лексические функции
Модели языка, лежащие в основе систем автоматического перевода, автоматического анализа / синтеза текстов, автоматического реферирования и поиска информации, используют многие математические понятия. Рассмотрим один из вариантов использования понятия «функция».
Лексические функции введены для описания регулярных отношений между смыслами слов. Детальное описание лексических функций и их видов можно найти в книге: И.А.Мельчук. Опыт теории лингвистических моделей «СМЫСЛ ТЕКСТ». М., 1974.
Пусть А и В – некоторые множества, h - отношение, ставящее в соответствие каждому элементу х из А некоторый элемент у из В. Такое отношение h(х)=у, где х А, у В назы-
вают функцией.
А – область определения функции h. В – область значений функции h.

Пусть V множество всех слов и словосочетаний рассматриваемого языка. Например:
слон V, цветок V, это окно V, зелѐное дерево V, {слон, цветок, это окно, зелѐное дерево} V.
Лексическая функция f(х)=Y ставит в соответствие заданному слову (словосочетанию) х V некоторое множество слов (словосочетаний) Y V, такое что для любых х1, х2 выполняется следующее свойство: если f(х1) и f(х2) существуют, то между f(х1) и х1, с одной стороны, и между f(х2) и х2, с другой стороны, всегда имеет место одно и то же смысловое отношение. В этом случае х называют аргументом лексической функции f, а Y – еѐ значением.
Пример 1. Conv (с0) — слово, называющее то же соотношение, что и с0, но с перестановкой актантов (конверсив). Нижние индексы при символе указывают на порядок
актантов (по сравнению с определѐнным каноническим их порядком). |
|
Conv21 (бояться) = {страшить, пугать} |
|
Conv321 (купить) = {продать}, так как купить [А, В, у С] продать [С, В, Адат.] |
|
Conv321 (преподавать) = {учиться}, так как преподавать [А, В, Сдат.] |
учиться |
[С, Вдат., у А] |
|
Пример 2. Centr – типовое обозначение «центральной» части предмета или процесса.
Centr (лес) = {чаща, глушь} Centr (работа) = {разгар}
Пример 3. Caus – «каузировать ситуацию».
Caus (сквер) = {разбить}
Пример 4. Magn – обозначение высокой степени, интенсивности.
Magn (выносливый) = {необыкновенно, чрезвычайно, двужильный, неутомимый, как ишак}
Magn (работать) = {как вол, как лошадь, как проклятый, напряжѐнно, не покладая рук, самозабвенно, с огоньком, с душой, упорно}
Magn (сильный) = {исключительно, как медведь, необыкновенно, чрезвычайно, богатырь, Илья Муромец}
Пример 5. Sing – типовое название одной «штуки», одного «кванта» некоторого объекта или действия:
Sing (капуста) = {качан}
Sing (дождь) = {капли, струи} Sing (горох) = {горошина} Sing (табун) = {лошадь}
Sing (стог) = {сено}
Противоположная функция – Mult. Mult (качан) = {капуста}
Пример 6. Пусть С0 – название ситуации, А и В – названия двух еѐ семантических актантов, причѐм все три слова (С0, А, В) – существительные. Для построения правильной русской фразы, описывающей данную ситуацию, необходимо ввести личный глагол (предполагается, что он «семантически пуст», то есть не добавляет никаких дополнительных смыслов к тем, которые выражены посредством С0, А, В). Такой глагол можно выбрать несколькими способами, в зависимости от того, какие синтаксические роли будут иметь С0, А и В. Ниже перечислены некоторые из возможностей. На рисунке схематично изображены возможности выбора глагола для С0 = власть.
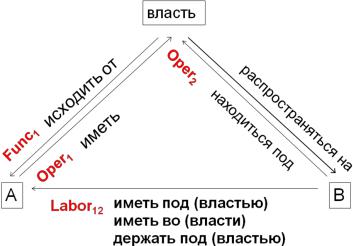
Oper1, Oper2 – глагол, связывающий название первого (соответственно второго) аргумента в роли подлежащего с названием ситуации в роли первого дополнения.
Oper1 (шаг) = Oper1 (вывод) = {делать} Oper1 (решение) = {принимать}
Oper2 (экзамен) = {держать, сдавать} Oper2 (продажа) = {быть, иметься в}
Func0, Func1, Func2 – глагол, имеющий название ситуации подлежащим, а названия аргументов, если они есть, - дополнениями.
Func0 (ночь) = {стоять}
Func0 (тишина) = {стоять, царить} Func1 (приказ) = {исходить от} Func1 (заслуга) = {принадлежать}
Func2 (власть) = {распространяться на}
Labor12 – глагол, связывающий название первого аргумента в роли подлежащего с названием второго аргумента в роли первого дополнения и с названием ситуации в роли второго дополнения:
Labor12 (орден) = {награждать}
Labor12 (власть) = {иметь под, иметь во, держать под} Labor12 (приветствия) = {осыпать}
Тема 1.5. Модель порождения загадок. Модель порождения юмористических текстов
Множества, функции, отношения обычно используются и в рамках других формальных моделей языка, в частности, при моделировании процессов генерации текстов определѐнного типа. Рассмотрим два примера таких моделей: семиотическая модель порождения загадок (Журинский А.Н. Семантическая структура загадки. М.: Наука, 1989) и семиотическая модель порождения одного из видов юмористических текстов (Щеглов Ю.К. Семиотический анализ одного типа юмора // Семиотика и информатика. Вып. 6. М., 1975. С.
165-198).
Предлагаемая А.Н. Журинским модель основана на следующей гипотезе. Ситуация, описанная текстом загадки (преобразованная ситуация, или ПС) структурно сходна с ситуацией, которую требуется отгадать (исходная загаданная ситуация, или ИС). Именно это сходство и делает возможным угадывание исходной ситуации по предъявленной в тексте загадки преобразованной ситуации.