

Шины.PCI,.USB.и.FireWire
.pdfным для PCI способом), либо с использованием протокола расщепленных транз$ акций. В последнем случае целевое устройство подает сигнал Split Response (расщеп$ ление), внутренне исполняет команду, а потом инициирует собственную транзак$ цию (команда Split Completion) для пересылки данных или сообщения о завершении инициатору исходной (расщепленной) транзакции. Целевое устройство обязано расщеплять транзакцию, если не может ответить на нее до истечения начальной задержки (initial latency). Устройство, вызвавшее расщепляемую транзакцию, на$ зывается запросчиком (Requester). Устройство, завершающее расщепленную транз$ акцию (Completer), будем называть исполнителем. Для завершения транзакции исполнитель должен будет запросить управление шиной у арбитра; запросчик на этапе завершения будет выступать в роли целевого устройства. Завершать транз$ акцию расщепленным способом может устройство, даже и не являющееся фор$ мально мастером шины (по признакам в его конфигурационных регистрах). Транз акция завершения Split Completion во многом напоминает пакетную транзакцию записи, но отличается в фазе адресации: вместо полного адреса пространства па$ мяти или ввода/вывода по шине AD передается идентификатор последовательности
(с номером шины, устройства и функции запросчика), к которой относится это завершение, и только младшие 6 бит адреса (рис. 2.4). Исполнитель берет этот иден$ тификатор из атрибутов расщепленной им транзакции. По этому идентификатору (номеру шины запросчика) мосты доводят транзакцию завершения до устройства$ запросчика. В фазе атрибутов передается идентификатор исполнителя (CBN — но$ мер шины, CDN — номер устройства и CFN — номер функции, рис. 2.3, в). Запросчик должен распознать свой идентификатор последовательности и ответить на транз$ акцию обычным способом (немедленно). Последовательность может отрабатывать$ ся и не одной транзакцией завершения, а их серией, до исчерпания счетчика бай$ тов (или прекращаться по ошибке). К какому стартовому адресу относится каждая из транзакций завершения, запросчик вычисляет сам (он знает, что запрашивал и сколько байтов уже пришло). Транзакция завершения может нести либо запрошен$ ные данные чтения, либо сообщение о результатах транзакции — Split Complete Message.
Запросчик должен быть всегда готов к получению данных начатых им последова$ тельностей, причем данные разных последовательностей могут приходить в про$ извольном порядке. Исполнитель может выдавать транзакции завершения на не$ сколько последовательностей также в произвольном порядке. В пределах каждой последовательности завершения, естественно, должны быть упорядочены по ад$ ресам (которые не передаются). Атрибуты в транзакции завершения содержат но$ мер шины, устройства и функции исполнителя и счетчик байтов. Кроме того, здесь присутствуют три специфических флага:
BCM (Byte Count Modified) — признак того, что будет передано меньше байтов данных, чем просил запросчик (передается с данными завершения);
SCE (Split Completion Error) — признак ошибки завершения, устанавливается при передаче сообщения завершения как ранний признак ошибки (до декоди$ рования самого сообщения);
SCM (Split Completion Message) — признак сообщения (отличает сообщение от данных).
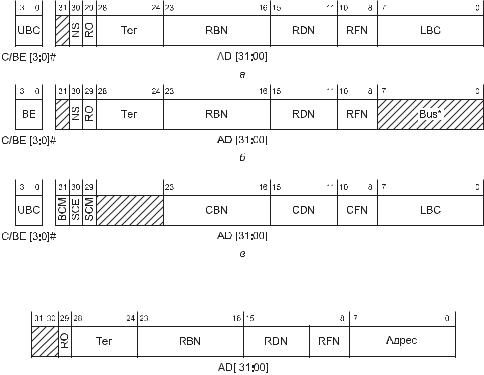
Рис. 2.3. Форматы атрибутов транзакции PCI X: а — пакетной, б — одиночной (* биты [7:0] используются только в цикле конфигурационной записи), в — завершения расщепленной
Рис. 2.4. Формат адреса завершения расщепленной транзакции PCI X
Особенности передачи данных в PCI X 2.0
В PCI$X 2.0 вдобавок к вышеописанным изменениям протокола появился новый режим Mode 2, отличающийся ускорением блочной записи в память и применени$ ем ECC$контроля. Этот режим возможен только при низком (1,5 В) напряжении питания интерфейсных схем. Режим Mode 2 имеет следующие особенности:
во всех транзакциях на 1 такт увеличено время декодирования адреса целевым устройством — задержки его ответа сигналом DEVSEL# на обращенную к нему команду. Этого лишнего такта требует ECC$контроль (устройство проверяет достоверность адреса и команды). По той же причине минимальное время по$ коя шины между транзакциями увеличено с 1 до 2 тактов;
в транзакциях пакетной записи в память (команда Memory Write Block) исполь$ зуется удвоенная или учетверенная скорость передачи данных по отношению к тактовой частоте. В этих транзакциях сигналы BEx# используются для синхро низации от источника данных (по прямому назначению они не используются, поскольку подразумевается обязательное разрешение всех байтов). Каждая передача данных (32, 64 или 16 бит) сопровождается стробами, в качестве кото$ рых используются сигналы BEx#. Пары линий BE[1:0]# и BE[3:2]# передают диф$
ференциальные стробирующие сигналы для линий данных AD[15:0] и AD[31:16] соответственно. В одном такте шины может быть две или четыре подфазы дан ных (data subphase), этим и обеспечиваются режимы PCI$X266 и PCI$X533 при частоте шины 133 МГц. Поскольку все управляющие сигналы синхронизиру$ ются по сигналу общей синхронизации (CLK), гранулярность передач становит$ ся равной двум или четырем подфазам данных. Для 32$разрядной шины это означает, что в транзакциях можно передавать (а также останавливать и приос$ танавливать передачи) данные порциями, кратными 8 или 16 байтам.
В 64$битном варианте шины линии AD[63:32] используются только в фазах дан$ ных; для адреса (даже 64$битного) и атрибутов используется только 32$битная шина.
Для устройств, работающих в Mode 2, вводится возможность использования 16$бит$ ной шины. При этом фазы адреса и атрибутов занимают по два такта, а фазы дан$ ных идут всегда парами (обеспечивая обычную гранулярность). В шине AD исполь$ зуются линии AD[16:31], по которым в первой фазе пары передаются биты [0:15],
аво второй — [16:31]. По линиям C/BE[2:3]# в первой фазе передаются биты C/BE[0:1]#,
аво второй — C/BE[2:3]#. Для ECC$контроля используются линии ECC[2:5], по ко$ торым в первой фазе передаются биты ECC[0, 1, 6] и специальный бит контроля E16,
аво второй — ECC[2, 3, 4, 5]. 16$битная шина предназначена только для встроенных применений (слоты и карты расширения не предусматриваются).
Обмен сообщениями между устройствами (команда DIM)
В PCI$X 2.0 введена возможность передачи информации (сообщений) устройству, адресуясь с помощью идентификатора (номера шины, устройства и функции). Для адресации и маршрутизации этих сообщений, которыми могут обмениваться любые устройства шины (включая и главный мост), не используется адресное про$ странство памяти или ввода/вывода. Сообщения передаются последовательнос$ тями, в которых используются команды DIM (Device ID Message), отличающиеся специфичностью адреса и атрибутов. В фазе адреса (рис. 2.5, а) передается иденти фикатор получателя сообщений (Completer ID) — номер его шины (CBN), устрой$ ства (CDN) и функции (CFN). Бит RT (Route Type) указывает тип маршрутизации сообщения: 0 — явная адресация с использованием вышеуказанного идентифика$ тора, 1 — неявная адресация к главному мосту (при этом идентификатор не ис$ пользуется). Бит SD (Silent Drop) задает способ отработки ошибок при выполне$ нии данной транзакции: 0 — обычный (как для записи в память), 1 — игнорирование некоторых типов ошибок (но не контроля четности или ECC). Поле Message Class задает класс сообщения, в соответствии с которым трактуется младший байт адре$ са. Транзакция может использовать и двухадресный цикл, при этом в первой фазе адреса по линиям C/BE[3:0]# передается код команды DAC, содержимое бит AD[31:00] соответствует рис. 2.5, а. Во второй фазе адреса по линиям C/BE[3:0]# пе$ редается код команды DIM, а все биты AD[31:00] трактуются в зависимости от класса
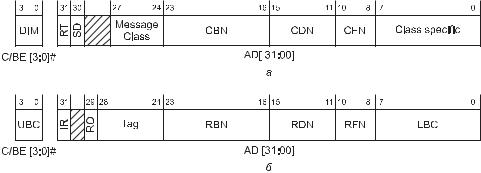
сообщения. Устройство, поддерживающее обмен сообщениями, декодировав ко$ манду DIM, проверяет поля идентификаторов получателя на соответствие своему собственному.
В фазе атрибутов (рис. 2.5, б) передается идентификатор источника сообщения (RBN, RDN и RFN), тег сообщения (Tag), 12$битный счетчик байтов (UBC и LBC) и дополнительные биты$признаки. Бит IR (Initial Request) является признаком на$ чала сообщения, которое может быть разорвано на несколько частей инициато$ ром, получателем или промежуточными мостами (во всех последующих частях бит обнулен). Бит RO (Relaxed Ordering) указывает на возможность неупорядоченной доставки данного сообщения по отношению к другим сообщениям и записям в память, распространяемым в том же направлении (порядок доставки фрагментов данного сообщения сохраняется всегда).
Тело сообщения, передаваемое в фазах данных, может иметь длину до 4096 байт (предел обусловлен 12$битным счетчиком длины). Содержимое тела определяет$ ся классом сообщения; класс 0 отдается на использование по воле производителя.
Сообщения с явной маршрутизацией маршрутизируются мостами на основе номе$ ра шины получателя. Проблемы передачи могут возникать только на главных мо$ стах: если в системе имеется несколько главных мостов, то архитектурная связь между ними может быть очень сложной (например, через магистрали контроллера памяти). Передача сообщений с шины на шину через главные мосты желательна (это проще, чем передача транзакций всех типов), но не строго обязательна. Под$ держка этой передачи дает больше свободы пользователю (не приходится при рас$ становке устройств принимать во внимание всю топологию шин). Сообщения с не явной маршрутизацией передаются только по направлению к хосту.
Поддержка DIM для устройств PCI$X необязательна; мосты PCI$X Mode 2 обяза$ ны поддерживать DIM. Если сообщение DIM адресуется к устройству, находяще$ муся на шине, работающей в стандартном режиме PCI (или путь к нему ведет че$ рез PCI), мост либо просто аннулирует это сообщение (если SD = 1), либо отвергает транзакцию (Target Abort, если SD = 0).
Рис. 2.5. Форматы в транзакции DIM: а — адрес, б — атрибуты
Границы диапазонов адресов и транзакций
Области пространств памяти и ввода/вывода, занимаемые устройством (точнее, функцией), описываются регистрами BAR (Base Address Register) в заголовке кон$ фигурационного пространства. При этом подразумевается, что длина области вы$ ражается числом 2n (n = 0, 1, 2…) и область выровнена естественным образом. В PCI области памяти выделяются по 2n параграфов (16 байт), то есть минимальный раз$ мер области — 16 байт. Области ввода/вывода выделяются по 2n двойных слов. Мосты PCI$PCI имеют карты адресов памяти с гранулярностью 1 Мбайт и карты ввода/вывода с гранулярностью 4 кбайт.
В PCI пакетная транзакция может быть прервана на границе любого двойного слова (в 64$битных операциях — учетверенного слова). В PCI$X ради оптимизации об$ ращений к памяти пакетные транзакции разрешается прерывать только в разре$ шенных точках, называемых ADB (Allowable Disconnect Boundary — разрешенные границы отключения). Точки ADB располагаются с интервалом 128 байт — это целое число (1, 2, 4 или 8) строк кэша современных процессоров. Конечно, это ог$ раничение относится только к границам транзакций внутри последовательности. Если последовательность должна по плану заканчиваться не на границе ADB, то и ее последняя транзакция будет завершена не на границе. Однако этой ситуации стараются избегать, разрабатывая такие структуры данных, которые могут быть выровнены подходящим образом (иногда даже ценой избыточности).
С границами адресов связан термин ADQ (ADB Delimited Quantum) — часть транз$ акции или буферной памяти (в мостах и устройствах), лежащая между границами соседних ADB. Например, транзакция, пересекающая одну границу ADB, состоит из двух ADQ (квантов) данных и занимает в мосте два буфера ADQ.
В соответствии с разрешенными границами транзакций области памяти, занимае$ мые устройствами PCI$X, также должны начинаться и заканчиваться на ADB — память выделяется квантами ADQ. Таким образом, минимальная область памяти, выделяемая устройству PCI$X, не может быть меньше 128 байт, а с учетом правил описания области ее размер может составлять 128 × 2n байт.
Время выполнения транзакций, таймеры и буферы
Протокол PCI регламентирует время (число тактов), допустимое для различных фаз транзакций. Работа шины контролируется несколькими таймерами, не позво$ ляющими попусту расходовать такты шины и помогающими планировать распре$ деление полосы пропускания.
Каждое целевое устройство должно достаточно быстро отвечать на адресованную ему транзакцию. Ответ адресованного целевого устройства (сигнал DEVSEL#) дол$ жен появиться в 1–3 такте после фазы адреса, в зависимости от «проворности» устройства: 1 такт — быстрое (Fast), 2 — среднее (Medium), 3 — медленное (Slow)
декодирование. Следующий такт при отсутствии ответа отводится на перехват транзакции мостом с субтрактивным декодированием адреса.
Задержка первой фазы данных (target initial latency), то есть задержка появления сигнала TRDY# относительно FRAME#, не должна превышать 16 тактов шины. Если устройство по своей природе иногда может не успевать уложиться в этот интер$ вал, оно должно формировать сигнал STOP#, прекращая транзакцию. Это заставит ведущее устройство повторить транзакцию, и с большой вероятностью эта попыт$ ка окажется успешной. Если устройство медленное и часто не укладывается в 16 тактов, то оно должно выполнять отложенную транзакцию (Delayed Transaction, см. выше). Целевое устройство имеет инкрементный механизм слежения за дли$ тельностью циклов (Incremental Latency Mechanism), который не позволяет ин$ тервалу между соседними фазами данных в пакете (target subsequent latency) пре$ вышать 8 тактов шины. Если целевое устройство не успевает работать в таком темпе, оно обязано остановить транзакцию. Желательно, чтобы устройство сообщало о своем «неуспевании» как можно раньше, не выжидая предельных 16 или 8 так$ тов, — это экономит полосу пропускания шины.
Инициатор также не должен задерживать поток — допустимая задержка от начала FRAME# до сигнала IRDY# (master data latency) и между фазами данных не должна превышать 8 тактов. Целевое устройство время от времени может отвергать опе$ рацию записи в память с запросом повтора (это, к примеру, может происходить при записи в видеопамять). У инициатора есть «предел терпения» для завершения операции — таймер максимального времени исполнения (maximum complete time). Таймер имеет порог 10 мкс — 334 такта при 33 МГц или 668 тактов на 66 МГц. За это время инициатор должен иметь возможность «протолкнуть» хоть одну фазу данных. Таймер начинает отсчет с момента запроса повтора операции записи в па$ мять и сбрасывается при последующем завершении транзакции записи в память, отличном от запроса повтора. Устройства, не способные выдерживать ограниче$ ние на максимальное время исполнения записи в память, должны предоставлять драйверу возможность определять их состояние, в котором достаточно быстрая запись в память невозможна. Драйвер, естественно, должен учитывать это состоя$ ние и не «напрягать» шину и устройство бесплодными попытками записи.
Право на управление шиной (сигнал GNT#) может быть отобрано у инициатора
влюбой момент времени. В зависимости от исполняемой команды и состояния сигналов ведущее устройство должно либо прервать транзакцию, либо продолжать ее до запланированного завершения. Каждое ведущее устройство, способное сфор$ мировать пакет с более чем двумя фазами данных, должно иметь собственный про$ граммируемый таймер задержки (master latency timer, или просто latency timer). Этот таймер фактически задает ограничение на длину пакетной транзак$ ции и, следовательно, на пропускную способность шины, предоставляемую этому устройству. Таймер запускается каждый раз по выставлении этим устройством сигнала FRAME# и отсчитывает такты шины до достижения значения, указанного
водноименном конфигурационном регистре. Поведение ведущего устройства после срабатывания таймера зависит от типа команды и состояния сигналов FRAME# и GNT# на момент срабатывания таймера:

если ведущее устройство снимает сигнал FRAME# до срабатывания таймера, тран$ закция завершается нормально;
Если сигнал GNT# снят и исполняемая команда не является записью памяти с ин$ валидацией, то инициатор обязан сократить транзакцию, сняв сигнал FRAME#. При этом ему позволяется завершить текущую и выполнить еще одну фазу данных;
если сигнал GNT# снят и исполняется запись в память с инвалидацией, то ини$ циатор должен завершить транзакцию по концу текущей (если передается не последнее двойное слово строки) или следующей (если двойное слово — послед$ нее) строки кэша.
Задержка арбитража (arbitration latency) определяется как число тактов от подачи инициатором запроса REQ# до получения права управления шиной GNT#. Эта задерж$ ка зависит от активности других инициаторов, быстродействия устройств (чем мень$ ше они вводят тактов ожидания, тем лучше) и «проворности» собственно арбитра.
При конфигурировании ведущие устройства сообщают свои потребности, указы$ вая максимально допустимую задержку предоставления доступа к шине (Max_Lat) и минимальное время, на которое им должно предоставляться управление шиной (Min_GNT). Эти потребности определяются присущим устройству темпом переда$ чи данных и его организацией. Однако будут ли эти потребности реально удовлет$ ворены (по ним должна определяться стратегия арбитража) — неясно1. Задержка предоставления доступа определяется как время от подачи запроса REQ# до полу$ чения GNT# и перехода шины в состояние покоя (только с этого момента данное устройство может начать транзакцию). Она зависит от числа ведущих устройств на шине, их активности и назначенных им значений таймеров задержки (в их ре$ гистрах Latency Timer, где время задается в тактах шины). Чем больше значения у этих таймеров, тем большее время придется другим устройствам ожидать предо$ ставления управления шиной при ее значительной загрузке. Одно из слагаемых задержки предоставления доступа — задержка арбитража.
Шина позволяет уменьшить мощность (ток), потребляемую устройствами, ценой увеличения числа тактов в транзакциях, применяя пошаговое переключение линий AD[31:0] и PAR, — так называемый степпинг (address/data stepping). Здесь возмож$ ны два варианта:
плавный шаг (continuous stepping) — начало формирования сигналов слаботоч$ ными формирователями за несколько тактов до выставления сигнала$квалифи$ катора действительной информации (FRAME# в фазе адреса, IRDY# или TRDY# в фазе данных). За эти несколько тактов сигналы «доползут» до требуемого зна$ чения при меньшем токе потребления;
дискретный шаг (diskrete stepping) — нормальные формирователи срабатыва$ ют не все сразу, а группами (например, побайтно), в каждом такте по группе. При этом снижаются броски тока, поскольку одновременно переключается мень$ ше формирователей.
1 Автору пока не удалось найти следы управления арбитражем в ОС Windows и UNIX.
Устройство само может и не пользоваться этими возможностями (см. описание бита 7 регистра команд в главе 5), но должно «понимать» такие циклы. Задержи$ вая сигнал FRAME#, устройство рискует потерять право доступа к шине, если ар$ битр получит запрос от более приоритетного устройства. По этой причине PCI 2.3 степпинг отменен для всех транзакций, кроме обращений к конфигурацион$ ному пространству устройств (конфигурационные циклы типа 0). В этих цик$ лах устройство может и не успеть в первом же такте транзакции распознать сигнал выборки IDSEL, который приходит с соответствующей линии ADx через резистор.
В PCI X требования к количеству тактов ужесточились:
инициатор не имеет права вводить такты ожидания. В транзакциях записи ини$ циатор выставляет на шину начальные данные (Data0) через 2 такта после фазы атрибутов; если транзакция пакетная, то следующие (Data1) — через 2 такта после ответа устройства сигналом DEVSEL#. Если целевое устройство не дает го$ товности (сигнала TRDY#), то инициатор должен в каждом такте чередовать дан$ ные Data0–Data1, пока целевое устройство не даст готовность (ему позволи$ тельно вводить только четное число тактов ожидания);
целевое устройство имеет право вводить такты ожидания только для началь$ ной фазы данных транзакции; для последующих фаз данных ожидание недопу$ стимо.
Для максимального использования возможностей шины устройства должны иметь буферы, чтобы накапливать в них данные для пакетных транзакций. Рекомендует$ ся для устройств со скоростью передачи данных до 5 Мбайт/с иметь буфер, по крайней мере на 4 двойных слова. Для более высоких скоростей рекомендуется буфер на 32 двойных слова. Для обмена с системной памятью наиболее эффектив$ ны транзакции, работающие с целыми строками кэша, что тоже учитывают при определении размера буфера. Однако увеличение размера буфера может вы$ звать трудности при обработке ошибок, а также вести к увеличению задержек доставки данных (пока устройство не заполнит определенный объем буфера, оно не начнет передачу этих данных по шине, и их потребители будут ожи$ дать).
В спецификации приводится пример организации карты Fast Ethernet (скорость передачи — 10 Мбайт/с), у которой для каждого направления передачи имеется 64$байтный буфер, разделенный на две половины (ping$pong buffer). Когда адап$ тер заполняет одну половину буфера приходящим кадром, он выводит в память накопленное содержимое другой половины, после чего половины меняются роля$ ми. Каждая половина выводится в память за 8 фаз данных (около 0,25 мкс на час$ тоте 33 МГц), что соответствует установке MIN_GNT = 1. При скорости прихода данных 10 Мбайт/с каждая половина заполняется за 3,2 мкс, что соответствует установке MAX_LAT = 12 (в регистрах MIN_GNT и MAX_LAT время задается в интерва$ лах по 0,25 мкс).
Контроль достоверности передачи и обработка ошибок
Для контроля достоверности передачи информации на шине PCI применяется проверка четности адреса и данных; в PCI$X используется и ECC$контроль с ис$ правлением однобитных ошибок. ECC$контроль обязателен при работе в Mode 2, он может использоваться и при работе в Mode 1. Метод контроля достоверности сообщается мостом в шаблоне инициализации по окончании аппаратного сброса шины. Мост выбирает тот метод контроля, который поддерживают все абоненты его вторичной шины (и он сам). Для сообщения об ошибках служат сигналы PERR# (протокольная сигнализация между устройствами) и SERR# (сигнал фатальной ошибки, вызывающий, как правило, немаскируемое прерывание системы).
При контроле четности используются сигналы PAR и PAR64, обеспечивающие чет$ ность числа «единиц» на наборах линий AD[31:0], C/BE[3:0]#, PAR и AD[63:32], C/BE[7:4]#, PAR64. Сигналы четности PAR и PAR64 вырабатываются тем устройством, которое в данный момент управляет шиной AD (выводит команду и адрес, атрибу$ ты или данные). Сигналы четности в режиме PCI вырабатываются с задержкой на один такт относительно контролируемых ими линий AD и C/BE#. В PCI$X при опе$ рациях чтения правила немного иные: биты четности в такте N относятся к битам данных такта N – 1 и сигналам C/BE# такта N – 2. Сигналы PERR# и SERR# вырабаты$ ваются приемником информации в такте, следующем за тактом, в котором нару$ шено условие четности.
При ECC контроле в 32$разрядном режиме для контроля линий AD[31:0] и C/BE[3:0]# применяется 7$битный код ECC с сигналами ECC[6:0]; в 64$разрядном режиме применяется 8$битный код с сигналами ECC[7:0]; в 16$разрядном режиме применяется несколько измененная схема ECC7 + 1. В любом из режимов ECC$ контроль позволяет исправлять только одиночные ошибки и обнаруживать боль$ шинство ошибок с большей кратностью. Исправление ошибок может быть за$ прещено программно (через регистр управления ECC$контролем), при этом обнаруживаются все ошибки кратности 1, 2 и 3. В любом случае в регистрах ECC$ контроля сохраняется диагностическая информация. Биты ECC выводятся на шину по тем же правилам и с теми же задержками, как и биты четности. Однако сигналы PERR# и SERR# вырабатываются приемником информации через такт после действи$ тельных бит ECC — «лишний» такт отдается на анализ синдрома ECC и попытку исправления ошибки.
Обнаруженная ошибка четности, как и ошибка более чем в одном бите, обнару$ женная при ECC$контроле, считается неисправимой (unrecoverable). Достоверность информации в фазе адреса, а в PCI$X и в фазе атрибутов, проверяется целевым устройством. В случае обнаружения неисправимой ошибки в этих фазах целевое устройство подает сигнал SERR# (в течение одного такта) и устанавливает в своем регистре состояния бит 14 — Signaled System Error. В фазе данных достовер$ ность проверяет устройство$приемник данных; в случае обнаружения неисправи$ мой ошибки оно подает сигнал PERR# и устанавливает в своем регистре состояния
бит 15 — Detected Parity Error.
В регистре состояния устройства имеется бит 8 (Master Data Parity Error), который отражает неудачу выполнения транзакции (последовательности) из$за обнаруженной ошибки данных. В PCI и PCI$X его правила установки формально различны:
в PCI этот бит устанавливается только инициатором транзакции, когда он сам ввел (при чтении) или обнаружил (при записи) сигнал PERR#;
в PCI$X этот бит устанавливается запросчиком транзакции или мостом: будучи инициатором команд чтения, мост обнаруживает ошибку в данных; будучи ини$ циатором команд записи, мост обнаруживает сигнал PERR#; будучи целевым ус$ тройством, мост получает данные завершения с ошибкой или сообщение завер$ шения с ошибкой транзакции записи от одного из устройств.
В случае обнаружения ошибки данных у устройства PCI$X и его драйвера есть два варианта поведения:
не пытаясь выполнить какие$то действия по восстановлению и продолжению работы, подать сигнал SERR# — это сигнал катастрофической ошибки, который может трактоваться ОС как повод к перезагрузке. Для устройств PCI это един$ ственно возможный вариант поведения;
не подавать сигнал SERR#, а пытаться обработать ошибку самостоятельно. Это можно делать только программно с учетом всех возможных побочных эффек$ тов от лишних операций (простой повтор чтения может, например, привести к потере данных).
Выбор варианта поведения обеспечивается установкой бита 0 (Uncorrectable Data Error Recovery Enable) в регистре PCI-X Command. По умолчанию (после сбро$ са) он обнулен — по ошибке данных устанавливается сигнал SERR#; иной вариант должен выбирать драйвер, «умеющий» самостоятельно обрабатывать ошибки.
Обнаружение ошибки в фазе адреса или атрибутов всегда является фатальной ошибкой.
Инициатор (запросчик) транзакции должен иметь возможность уведомить драй$ вер об отвержении транзакции по условию Master Abort (нет ответа от целевого устройства) или Target Abort (отказ целевого устройства), используя прерывания или другие подходящие средства. Если такое уведомление невозможно, устрой$ ство должно подавать сигнал SERR#.
Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
Как было сказано выше, шина PCI не предоставляет возможности прямого досту$ па к памяти с использованием централизованного контроллера в стиле 8237A (как для шины ISA). Для разгрузки центрального процессора от рутинных перекачек данных предлагается прямое управление шиной со стороны устройств, называе$ мых ведущими устройствами шины (PCI Bus Master). Степень интеллектуальнос$