

Java_J2EE_Job_Interview_Companion
.pdf190 |
Enterprise – XML |
Enterprise - XML
Q.What is XML? XML stands for eXtensible Markup Language. XML is a grammatical system for constructing custom markup languages for describing business data, mathematical data, chemical data etc. XML loosely couples disparate applications or systems utilizing JMS, Web services etc. XML uses the same building blocks that HTML does: elements, attributes and values.
Q.Why is XML important?
•Scalable: Since XML is not in a binary format you can create and edit files with anything and it’s also easy to debug. XML can be used to efficiently store small amounts of data like configuration files (web.xml, application.xml, strutsconfig.xml etc) to large company wide data with the help of XML stored in the database.
•Fast Access: XML documents benefit from their hierarchical structure. Hierarchical structures are generally faster to access because you can drill down to the section you are interested in.
•Easy to identify and use: XML not only displays the data but also tells you what kind of data you have. The mark up tags identifies and groups the information so that different information can be identified by different application.
•Stylability: XML is style-free and whenever different styles of output are required the same XML can be used with different style-sheets (XSL) to produce output in XHTML, PDF, TEXT, another XML format etc.
•Linkability, in-line usability, universally accepted standard with free/inexpensive tools etc
Q. When would you not use an XML?
XML is verbose and it can be 4-6 times larger in size compared to a csv or a tab delimited file. If your network lacked bandwidth and/or your content is too large and network throughput is vital to the application then you may consider using a csv or tab delimited format instead of an XML.
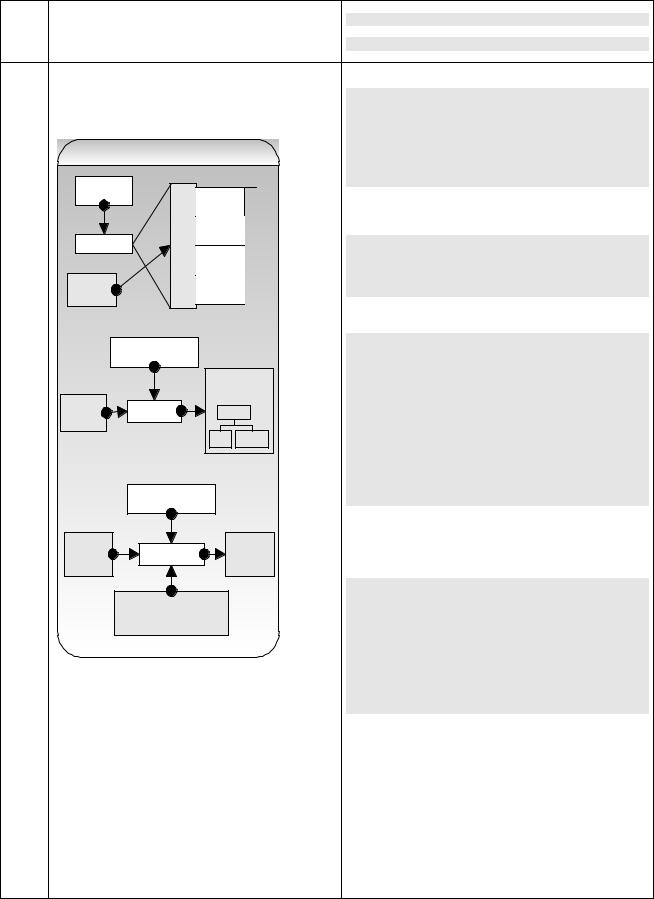
Q 93: What is the difference between a SAX parser and a DOM parser? SF
 PI
PI
 MI FAQ
MI FAQ
A 93:
SAX parser |
DOM parser |
||
A SAX (Simple API for XML) parser does not create any |
A DOM (Document Object Model) parser creates a tree |
||
internal structure. Instead, it takes the occurrences of |
structure in memory from an input document and then |
||
components of an input document as events (i.e., event |
waits for requests from client. |
||
driven), and tells the client what it reads as it reads through |
|
|
|
the input document. |
|
|
|
|
|
||
A SAX parser serves the client application always only with |
A DOM parser always serves the client application with the |
||
pieces of the document at any given time. |
entire document no matter how much is actually needed by |
||
|
|
the client. |
|
|
|
||
A SAX parser, however, is much more space efficient in |
A DOM parser is rich in functionality. It creates a DOM tree |
||
case of a big input document (because it creates no internal |
in memory and allows you to access any part of the |
||
structure). What's more, it runs faster and is easier to learn |
document repeatedly and allows you to modify the DOM |
||
than DOM parser because its API is really simple. But from |
tree. But it is space inefficient when the document is huge, |
||
the functionality point of view, it provides a fewer functions, |
and it takes a little bit longer to learn how to work with it. |
||
which means that the users themselves have to take care of |
|
|
|
more, such as creating their own data structures. |
|
|
|
|
|
||
Use SAX parser when |
Use DOM when |
||
|
Input document is too big for available memory. |
|
Your application has to access various parts of the |
|
When only a part of the document is to be read and we |
|
document and using your own structure is just as |
|
|
complicated as the DOM tree. |
|
|
create the data structures of our own. |
|
Your application has to change the tree very frequently |
|
If you use SAX, you are using much less memory and |
||
|
|
and data has to be stored for a significant amount of |
|
|
performing much less dynamic memory allocation. |
|
time. |
|
|
|
|

|
|
|
|
Enterprise – XML |
191 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Xerces, Crimson etc |
|
|
|
|
XercesDOM, SunDOM, OracleDOM |
|
|
|
SAX Parser example: |
|
|
DOM Parser example: |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Use JAXP (Java API for XML Parsing) which enables |
|
etc. |
|
|
|
|||
|
|
|
|
|
|
|
|
|||
|
|
applications to parse and transform XML documents |
|
Use JAXP (Java API for XML Parsing) which enables |
|
|||||
|
|
independent of the particular XML parser. Code can be |
|
applications to parse and transform XML documents |
|
|||||
|
|
developed with one SAX parser in mind and later on can be |
|
independent of the particular XML parser. Code can be |
|
|||||
|
|
changed to another SAX parser without changing the |
|
developed with one DOM parser in mind and later on can be |
|
|||||
|
|
application code. |
|
changed to another DOM parser without changing the |
|
|||||
|
|
|
|
|
|
application code. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Q 94: Which is better to store data as elements or as attributes? DC
A 94: A question arising in the mind of XML/DTD designers is whether to model and encode certain information using an element, or alternatively, using an attribute. The answer to the above question is not clear-cut. But the general guideline is:
Using an element: <book><title>Lord of the Rings</title>...</book>: If you consider the information in question to be part of the essential material that is being expressed or communicated in the XML, put it in an element
Using an attribute: <book title=" Lord of the Rings "/>: If you consider the information to be peripheral or incidental to the main communication, or purely intended to help applications process the main communication, use attributes.
The principle is data goes in elements and metadata goes in attributes. Elements are also useful when they contain special characters like “<”, “>”, etc which are harder to use in attributes. The most important reason to use element is its extensibility. It is far easier to create child elements to reflect complex content than to break an attribute into pieces. You can use attributes along with elements to refine your understanding of that element with extra information. Attributes are less verbose but using attributes instead of child elements with the view of optimizing document size is a short term strategy, which can have long term consequences.
Q 95: What is XPATH? What is XSLT/XSL/XSL-FO/XSD/DTD etc? What is JAXB? What is JAXP? SF FAQ
A 95:
What |
Explanation |
|
Example |
|
is |
|
|
|
|
XML |
XML stands for eXtensible Markup Language |
|
Sample.xml |
|
|
|
|
|
|
|
|
|
<?xml version="1.0"?> |
|
|
|
|
<note> |
|
|
|
|
<to>Peter</to> |
|
|
|
|
<from>Paul</from> |
|
|
|
|
<title>Invite</title> |
|
|
|
|
<content language=”English”>Not Much</content> |
|
|
|
|
< content language=”Spanish”>No Mucho</content > |
|
|
|
|
</note> |
|
|
|
|
|
|
DTD |
DTD stands for Document Type Definition. XML provides |
|
Sample.dtd |
|
|
an application independent way of sharing data. With a |
|
|
|
|
DTD, independent groups of people can agree to use a |
|
<!ELEMENT note (to, from, title, content)> |
|
|
common DTD for interchanging data. Your application can |
|
<!ELEMENT to (#PCDATA)> |
|
|
use a standard DTD to verify that data that you receive |
|
<!ELEMENT from (#PCDATA)> |
|
|
from the outside world is valid. You can also use a DTD to |
|
<!ELEMENT title (#PCDATA)> |
|
|
verify your own data. So the DTD is the building blocks or |
|
<!ELEMENT content (#PCDATA)> |
|
|
schema definition of the XML document. |
|
<!ATTLIST content language CDATA #Required> |
|
|
|
|
|
|
XSD |
XSD stands for Xml Schema Definition, which is a |
|
Sample.xsd |
|
|
successor of DTD. So XSD is a building block of an XML |
|
|
|
|
document. |
|
<?xml version="1.0"?> |
|
|
|
|
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" |
|
|
If you have DTD then why use XSD you may ask? |
|
targetNamespace="http://www.w3schools.com" |
|
|
|
|
xmlns="http://www.w3schools.com" |
|
|
XSD is more powerful and extensible than DTD. XSD has: |
|
elementFormDefault="qualified"> |
|
|
• Support for simple and complex data types. |
|
<xs:element name="note"> |
|
|
• Uses XML syntax. So XSD are extensible just like |
|
<xs:complexType> |
|
|
|
|
|
|

192 |
|
Enterprise – XML |
|
|
|
|
|
|
|
|
|
XML because they are written in XML. |
<xs:sequence> |
|
|
• |
Better data communication with the help of data |
<xs:element name="to" type="xs:string"/> |
|
|
|
types. For example a date like 03-04-2005 will be |
<xs:element name="from" type="xs:string"/> |
|
|
|
interpreted in some countries as 3rd of April 2005 and |
<xs:element name="title" type="xs:string"/> |
|
|
|
in some other countries as 04th March 2005. |
<xs:element name="content" type="xs:string"/> |
|
|
|
|
</xs:sequence> |
|
|
|
|
</xs:complexType> |
|
|
|
|
<xs:attribute name="language" type=”xs:string” |
|
|
|
|
use=”Required” /> |
|
|
|
|
</xs:element> |
|
|
|
|
</xs:schema> |
|
|
|
|
|
|
XSL |
XSL stands for eXtensible Stylesheet Language. The XSL |
To convert the Sample.xml file to a XHTML file let us apply the |
|
|
|
consists of 3 parts: |
following Sample.xsl through XALAN parser. |
|
|
|
• |
XSLT: Language for transforming XML documents |
Sample.xsl |
|
|
|
from one to another. |
<?xml version="1.0"?> |
|
|
|
|
|
|
|
• |
XPath: Language for defining the parts of an XML |
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl"> |
|
|
|
document. |
<xsl:template match="/"> |
|
|
|
|
<xsl:apply-templates select="note " /> |
|
•XSL-FO: Language for formatting XML documents. </xsl:template>
|
|
For example to convert an XML document to a PDF |
<xsl:template match="note"> |
|
|||
|
|
document etc. |
|
||||
|
|
|
|
|
|
<html> |
|
|
XSL can be thought of as a set of languages that can : |
<head> |
|
||||
|
|
|
|
|
|
<title><xsl:value-of |
|
|
• |
Define parts |
of an XML. |
select="content/@language"> |
|
||
|
• |
Transform an XML document to XHTML (eXtensible |
</title> |
|
|||
|
</head> |
|
|||||
|
|
Hyper Text Markup Language) document. |
|
||||
|
|
</html> |
|
||||
|
• |
Convert an XML document to a PDF document. |
|
||||
|
</xsl:template> |
|
|||||
|
• |
Filter and sort XML data. |
|
||||
|
</xsl:stylesheet> |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
You get the following output XHTML file: |
|
|
|
Xalan (from Apache). |
|
|
|||
|
XSLT processor example: |
Sample.xhtml |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
<html> |
|
|
Processor |
example: |
FOP (Formatting Objects |
<head> |
|
||
|
Processor from Apache) |
|
|||||
|
<title>English</title> |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
</head> |
|
|
|
|
|
|
|
</html> |
|
|
|
|
|
|
|
Now to convert the Sample.xml into a PDF file apply the |
|
|
|
|
|
|
|
following FO (Formatting Objects) file Through the FOP |
|
|
|
|
|
|
|
processor. |
|
|
|
|
|
|
|
Sample.fo |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
<?xml version="1.0" encoding="ISO-8859-1"?> |
|
|
|
|
|
|
|
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format"> |
|
|
|
|
|
|
|
<fo:layout-master-set> |
|
|
|
|
|
|
|
<fo:simple-page-master master-name="A4"> |
|
|
|
|
|
|
|
</fo:simple-page-master> |
|
|
|
|
|
|
|
</fo:layout-master-set> |
|
|
|
|
|
|
|
<fo:page-sequence master-reference="A4"> |
|
|
|
|
|
|
|
<fo:flow flow-name="xsl-region-body"> |
|
|
|
|
|
|
|
<fo:block> |
|
|
|
|
|
|
|
<xsl:value-of select="content[@language='English']"> |
|
|
|
|
|
|
|
</fo:block> |
|
|
|
|
|
|
|
</fo:flow> |
|
|
|
|
|
|
|
</fo:page-sequence> |
|
|
|
|
|
|
|
</fo:root> |
|
|
|
|
|
|
|
which gives a basic Sample.pdf which has the following line |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Not Much |
|
|
|
|
|
||||
XPath |
Xml Path Language, a language for addressing parts of an |
As per Sample.xsl |
|
||||
|
|
|
|
Enterprise – XML |
193 |
|
|
XML document, designed to be used by both XSLT and |
<xsl:template match=”content[@language=’English’]”> |
||||
|
XPointer. We can write both the patterns (context-free) and |
|||||
|
expressions using the XPATH Syntax. XPATH is also used |
……… |
|
|||
|
in XQuery. |
|
|
|
<td><xsl:value-of |
select=”content/@language” /></td> |
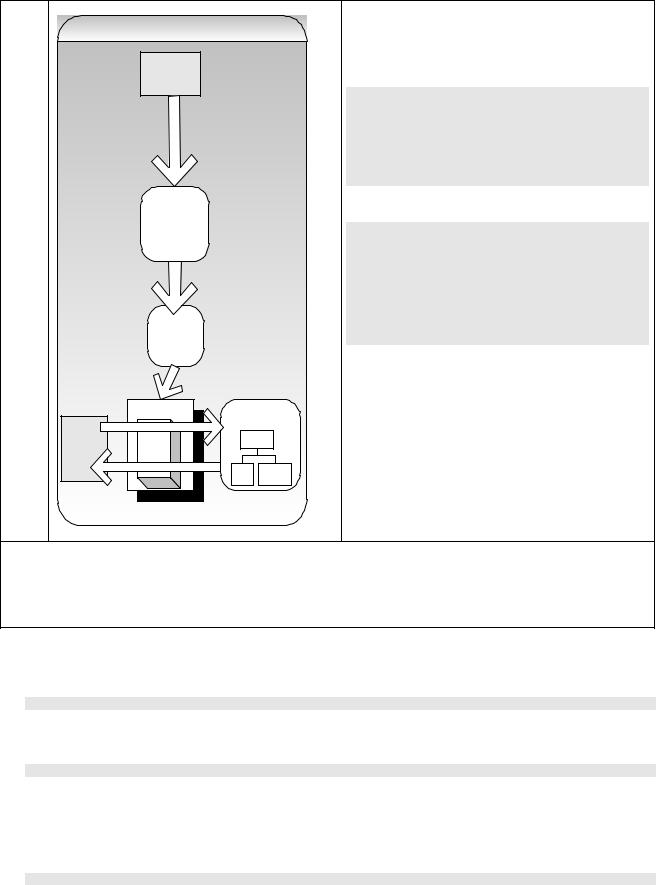
JAXP |
Stands for Java API for XML Processing. This provides a |
DOM example using JAXP: |
||||
|
common interface for creating and using SAX, DOM, and |
DocumentBuilderFactory dbf = |
||||
|
XSLT APIs in Java regardless of which vendor’s |
|||||
|
implementation is actually being used (just like the JDBC, |
DocumentBuilderFactory.newInstance(); |
||||
|
JNDI interfaces). JAXP has the following packages: |
DocumentBuilder db = dbf.newDocumentBuilder(); |
||||
|
|
|
|
|
Document doc = |
|
|
|
JAXP |
|
db.parse(new File("xml/Test.xml")); |
||
|
|
|
NodeList nl = doc.getElementsByTagName("to"); |
|||
|
|
|
|
implements |
Node n = nl.item(0); |
|
|
SAXParser |
|
|
System.out.println(n.getFirstChild().getNodeValue()); |
||
|
Factory |
|
|
Content |
|
|
|
|
|
SAXExample |
Handler |
SAX example using JAXP: |
|
|
|
SAXReader |
Error |
|||
|
|
|
|
|||
|
|
|
|
|
|
|
|
SAXParser |
|
|
Handler |
SAXParserFactory spf = |
|
|
|
|
DTD |
|||
|
|
|
|
SAXParserFactory.newInstance(); |
||
|
XML |
|
|
Handler |
SAXParser sp = spf.newSAXParser(); |
|
|
|
|
Entity |
SAXExample se = new SAXExample(); |
||
|
Sample. |
|
|
sp.parse(new File("xml/Sample.xml"),se); |
||
|
|
|
Resolver |
|||
|
xml |
|
|
|
|
|
|
|
|
|
where SAXExample.Java code snippet |
||
|
|
|
|
|
||
|
|
DocumentBuilder |
|
|
public class SAXExample extends DefaultHandler { |
|
|
|
|
|
|
|
|
Factory |
|
|
public void startElement( |
|
|
|
|
|
|
|
|
|
Document |
String uri, |
|
|
|
|
String localName, |
||
|
XML |
|
(DOM) |
||
|
Document |
String qName, |
|||
|
note |
||||
|
Sample. |
Attributes attr) |
|||
|
Builder |
||||
|
xml |
|
to |
from |
throws SAXException { |
|
|
|
System.out.println("--->" + qName); |
||
|
|
|
|
|
|
|
|
|
|
|
} |
|
|
|
|
|
... |
|
|
Transformer |
|
|
} |
|
|
Factory |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The DefaultHandler implements ContentHandler, |
|
Source |
|
|
Result |
DTDHandler, EntityResolver, ErrorHandler |
|
Transformer |
|
|
||
|
sample. |
|
sample. |
XSLT example using JAXP: |
|
|
xml |
|
|
xhtml |
|
|
|
|
|
||
|
|
|
|
|
StreamSource xml = |
|
|
Transformation |
|
|
new StreamSource(new File("/xml/Sample.xml")); |
|
|
instructions |
|
|
StreamSource xsl = new StreamSource( |
|
|
sample.xsl |
|
|
new File("xml/Sample.xsl")); |
|
|
|
|
StreamResult result = |
|
|
|
|
|
|
|
|
|
|
|
|
new StreamResult(new File("xml/Sample.xhtml")); |
• |
javax.xml.parsers Æ common interface for different |
TransformerFactory tf = |
|||
TransformerFactory.newInstance(); |
|||||
|
vendors of SAX, DOM parsers). |
|
Transformer t = tf.newTransformer(xsl); |
||
• |
org.xml.sax Æ Defines basic SAX API. |
t.transform(xml, result); |
|||
• |
org.w3c.dom Æ Defines Document Object Model and |
|
|||
|
its componenets. |
|
|
This gives you Sample.xhtml |
|
•javax.xml.transform Æ Defines the XSLT API which
|
allows you to transform XML into other forms like |
<html> |
|
|
PDF, XHTML etc. |
<head> |
|
|
Required JAR files are jaxp.jar, dom.jar, xalan.jar, |
<title>English</title> |
|
|
</head> |
|
|
|
xercesImpl.jar. |
</html> |
|
|
|
|
|
JAXB |
Stands for Java API for XML Binding. This standard |
Let’s look at some code: |
|
|
defines a mechanism for writing out Java objects as XML |
|
|
|
(Marshaling) and for creating Java objects from XML |
For binding: |
|
|
structures (unMarshaling). (You compile a class |
|
|
|
description to create the Java classes, and use those |
xjc.sh –p com.binding sample.xsd –d work |
|
|
classes in your application.) |
|
|
Enterprise – XML |
195 |
Q.How will you embed an XML content within an XML document?
A.By using a CDATA section.
<message>
<from>LoansSystem</from>
<to>DocumentSystem</to>
<body>
<![CDATA[
<application>
<number>456</number>
<name>Peter</name> <detail>blah blah</detail>
</application>
]]>
</body>
</message>
Q.How do you write comments in an XML document?
A.<!-- This is an XML comment -->
Q.How do you write an attribute value with single quotes? How do you write an element value of “> 500.00”?
A.You need to use an internal entity reference like < for <, > for >, & for &, " for “, ' for ‘.
<customer name=”"Mr. Smith"” /> <cost> > 500.00</cost>
Q.What is a well-formed XML document?
A.A well formed document adheres to the following rules for writing an XML.
•A root element is required. A root element is an element, which completely contains all the other elements.
•Closing tags are required. <cust>abc</cust> or <cust/>
•Elements must be properly nested.
•XML is case sensitive. <CUSTOMER> and <Customer> elements are considered completely separate.
•An attribute’s value must always be enclosed in either single or double quotes.
•Entity references must be declared in a DTD before being used except for the 5 built-in (<, > etc) discussed in the previous question.
Q.What is a valid XML document?
A.For an XML document to be valid, it must conform to the rules of the corresponding DTD (Document Type Definition – internal or external) or XSD (XML Schema Definition).
Q.How will you write an empty element?
A.
<name age=”25”></name>
or
<name age=”25” />
Q.What is a namespace in an XML document?
A.Namespaces are used in XML documents to distinguish one similarly titled element from another. A namespace must have an absolutely unique and permanent name. In an XML, name space names are in the form of a URL. A default namespace for an element and all its children can be declared as follows:
<accounts xmlns=”http://www.bank1.com/ns/account”>
…
</accounts>
Individual elements can be labeled as follows:
<accounts xmlns=”http://www.bank1.com/ns/account” xmlns:bank2=”http://www.bank2.com/ns/account”> <name>FlexiDirect</name> <!-- uses the default name space --> <bank2:name>Loan</bank2:name> <!-- >
…
</accounts>

196 |
Enterprise – XML |
Q.Why use an XML document as opposed to other types of documents like a text file etc?
•It is a universally accepted standard.
•Free and easy to use tools are available. Also can be stored in a database.
•Fast access due to its hierarchical structure.
•Easy to identify and use due to its markup tags.
Q.What is your favorite XML framework or a tool?
A.My favorite XML framework is JiBX, which unmarshals an XML document to graph of Java objects and marshals a graph of Java objects back to an XML document. It is simple to use, very flexible and fast. It can be used with existing Java classes.
Q.Explain where your project needed XML documents?
A.It is hard to find a project, which does not use XML documents.
•XML is used to communicate with disparate systems via messaging or Web Services.
•XML based protocols and standards like SOAP, ebXML, WSDL etc are used in Web Services.
•XML based deployment descriptors like web.xml, ejb-jar.xml, etc are used to configure the J2EE containers.
•XML based configuration files are used by open-source frameworks like Hibernate, Spring, Struts, and Tapestry etc.
Enterprise – SQL, Database, and O/R mapping |
197 |
Enterprise – SQL, Database, and O/R mapping
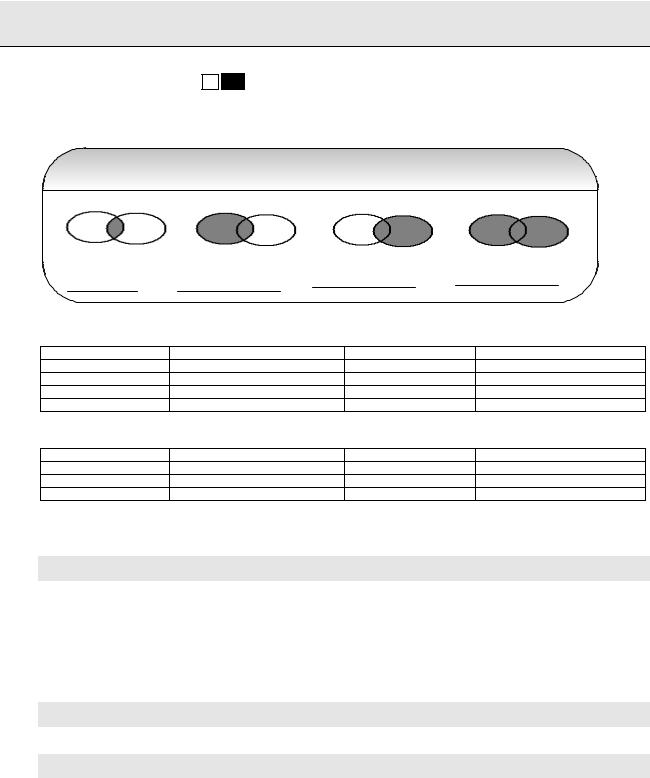
Q 96: Explain inner and outer joins? SF FAQ
A 96: Joins allow database users to combine data from one table with data from one or more other tables (or views, or synonyms). Tables are joined two at a time making a new table containing all possible combinations of rows from the original two tables. Lets take an example (syntax vary among RDBMS):
Joins and Set operations in Relational Databases
Inner join |
Left outer join |
Right outer join |
Full outer join |
Employees table |
|
|
|
Id |
Firstname |
Surname |
State |
1001 |
John |
Darcy |
NSW |
1002 |
Peter |
Smith |
NSW |
1003 |
Paul |
Gregor |
NSW |
1004 |
Sam |
Darcy |
VIC |
Executives table |
|
|
|
Id |
Firstname |
Surname |
State |
1001 |
John |
Darcy |
NSW |
1002 |
Peter |
Smith |
NSW |
1005 |
John |
Gregor |
WA |
Inner joins: Chooses the join criteria using any column names that happen to match between the two tables. The example below displays only the employees who are executives as well.
SELECT emp.firstname, exec.surname FROM employees emp, executives exec
WHERE emp.id = exec.id;
The output is:
Firstname |
Surname |
John |
Darcy |
Peter |
Smith |
Left Outer joins: A problem with the inner join is that only rows that match between tables are returned. The example below will show all the employees and fill the null data for the executives.
SELECT emp.firstname, exec.surname FROM employees emp left join executives exec ON emp.id = exec.id;
On oracle
SELECT emp.firstname, exec.surname FROM employees emp, executives exec
WHERE emp.id = exec.id(+);
The output is:
Firstname |
Surname |
John |
Darcy |
Peter |
Smith |
Paul |
|
Sam |
|

198 |
Enterprise – SQL, Database, and O/R mapping |
Right Outer join: A problem with the inner join is that only rows that match between tables are returned. The example below will show all the executives and fill the null data for the employees.
SELECT emp.firstname, exec.surname FROM employees emp right join executives exec ON emp.id = exec.id;
On oracle
SELECT emp.firstname, exec.surname FROM employees emp, executives exec
WHERE emp.id(+) = exec.id;
The output is:
Firstname |
Surname |
John |
Darcy |
Peter |
Smith |
|
Gregor |
Full outer join: To cause SQL to create both sides of the join
SELECT emp.firstname, exec.surname FROM employees emp full join executives exec
ON emp.id = exec.id;
On oracle
SELECT emp.firstname, exec.surname FROM employees emp, executives exec
WHERE emp.id = exec.id (+)
UNION
SELECT emp.firstname, exec.surname FROM employees emp, executives exec
WHERE emp.id(+) = exec.id
Note: Oracle9i introduced the ANSI compliant join syntax. This new join syntax uses the new keywords inner join, left outer join, right outer join, and full outer join, instead of the (+) operator.
The output is:
Firstname |
Surname |
John |
Darcy |
Paul |
|
Peter |
Smith |
Sam |
|
|
Gregor |
Self join: A self-join is a join of a table to itself. If you want to find out all the employees who live in the same city as employees whose first name starts with “Peter”, then one way is to use a sub-query as shown below:
SELECT emp.firstname, emp.surname FROM employees emp WHERE
city IN (SELECT city FROM employees where firstname like ‘Peter’)
The sub-queries can degrade performance. So alternatively we can use a self-join to achieve the same results.
On oracle
SELECT emp.firstname, emp.surname FROM employees emp, employees emp2
WHERE emp.city = emp2.city
AND emp2.firstname LIKE 'Peter'
The output is:
|
Firstname |
Surname |
|
|
John |
Darcy |
|
|
Peter |
Smith |
|
|
Paul |
Gregor |
|
|
|
|
|
Q 97: Explain a sub-query? How does a sub-query impact on performance? SF
 PI FAQ
PI FAQ
A 97: It is possible to embed a SQL statement within another. When this is done on the WHERE or the HAVING statements, we have a subquery construct. What is subquery useful for? It is used to join tables and there are cases where the only way to correlate two tables is through a subquery.
SELECT emp.firstname, emp.surname FROM employees emp WHERE
Enterprise – SQL, Database, and O/R mapping |
199 |
emp.id NOT IN (SELECT id FROM executives);
There are performance problems with sub-queries, which may return NULL values. The above sub-query can be re-written as shown below by invoking a correlated sub-query:
SELECT emp.firstname, emp.surname FROM employees emp WHERE emp.id NOT EXISTS (SELECT id FROM executives);
The above query can be re-written as an outer join for a faster performance as shown below:
SELECT emp.firstname, exec.surname FROM employees emp left join executives exec on emp.id = exec.id AND exec.id IS NULL;
The above execution plan will be faster by eliminating the sub-query.
Q 98: What is normalization? When to denormalize? DC
 PI FAQ
PI FAQ
A 98: Normalization is a design technique that is widely used as a guide in designing relational databases. Normalization is essentially a two step process that puts data into tabular form by removing repeating groups and then removes duplicated data from the relational tables (Additional reading recommended).
Redundant data wastes disk space and creates maintenance problems. If data that exists in more than one place must be changed, the data must be changed in exactly the same way in all locations which is time consuming and prone to errors. A change to a customer address is much easier to do if that data is stored only in the Customers table and nowhere else in the database.
Inconsistent dependency is a database design that makes certain assumptions about the location of data. For example, while it is intuitive for a user to look in the Customers table for the address of a particular customer, it may not make sense to look there for the salary of the employee who calls on that customer. The employee's salary is related to, or dependent on, the employee and thus should be moved to the Employees table. Inconsistent dependencies can make data difficult to access because the path to find the data may not be logical, or may be missing or broken.
First Normal Form |
Second Normal Form |
Third Normal Form |
A database is said to be in First |
A database is in Second Normal Form |
A database is in Third Normal Form when |
Normal Form when all entities |
when it is in First Normal Form plus |
it is in Second Normal Form and each |
have a unique identifier or key, |
every non-primary key column in the |
column that isn't part of the primary key |
and when every column in every |
table must depend on the entire primary |
doesn't depend on another column that |
table contains only a single value |
key, not just part of it, assuming that the |
isn't part of the primary key. |
and doesn't contain a repeating |
primary key is made up of composite |
|
group or composite field. |
columns. |
|
|
|
|
When to denormalize? Normalize for accuracy and denormalize for performance.
Typically, transactional databases are highly normalized. This means that redundant data is eliminated and replaced with keys in a one-to-many relationship. Data that is highly normalized is constrained by the primary key/foreign key relationship, and thus has a high degree of data integrity. Denormalized data, on the other hand, creates redundancies; this means that it's possible for denormalized data to lose track of some of the relationships between atomic data items. However, since all the data for a query is (usually) stored in a single row in the table, it is much faster to retrieve.
Q 99: How do you implement one-to-one, one-to-many and many-to-many relationships while designing tables? SF
A 99: One-to-One relationship can be implemented as a single table and rarely as two tables with primary and foreign key relationships.
One-to-Many relationships are implemented by splitting the data into two tables with primary key and foreign key relationships.
Many-to-Many relationships are implemented using join table with the keys from both the tables forming the composite primary key of the junction table.
Q 100: How can you performance tune your database? PI FAQ