

Data-Structures-And-Algorithms-Alfred-V-Aho
.pdfData Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
(3)p −.next −.element := x;
(4)p −.next −.next := temp end; { INSERT }
procedure DELETE ( p: position ); begin
p −.next := p −.next −.next end; { DELETE }
function LOCATE ( x: elementtype; L: LIST ): position; var
p: position; begin
p := L;
while p −.next <> nil
do
if p −.next −.element = x then return (p)
else
p := p −.next; return (p) { if not found }
end; { LOCATE }
function MAKENULL ( var L: LIST ) : position; begin
new(L);
L −.next := nil; return (L )
end; { MAKENULL }
Fig. 2.6. Some operations using the linked-list implementation.
However, if the linked-list implementation is used, the value of p, which is a pointer to the cell containing b, does not change because of the insertion, so afterward, the value of p is "position 4," not 3. This position variable must be updated, if it is to be used subsequently as the position of b.†
Fig. 2.7. Diagram of INSERT.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (10 of 40) [1.7.2001 18:58:59]

Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
Fig. 2.8. Diagram of DELETE.
Comparison of Methods
We might wonder whether it is best to use a pointer-based or array-based implementation of lists in a given circumstance. Often the answer depends on which operations we intend to perform, or on which are performed most frequently. Other times, the decision rests on how long the list is likely to get. The principal issues to consider are the following.
1.The array implementation requires us to specify the maximum size of a list at compile time. If we cannot put a bound on the length to which the list will grow, we should probably choose a pointer-based implementation.
2.Certain operations take longer in one implementation than the other. For example, INSERT and DELETE take a constant number of steps for a linked list, but require time proportional to the number of following elements when the array implementation is used. Conversely, executing PREVIOUS and END require constant time with the array implementation, but time proportional to the length of the list if pointers are used.
3.If a program calls for insertions or deletions that affect the element at the position denoted by some position variable, and the value of that variable will be used later on, then the pointer representation cannot be used as we have described it here. As a general principle, pointers should be used with great care and restraint.
4.The array implementation may waste space, since it uses the maximum amount of space independent of the number of elements actually on the list at any time. The pointer implementation uses only as much space as is needed for the elements currently on the list, but requires space for the pointer in each cell. Thus, either method could wind up using more space than the other in differing circumstances.
Cursor-Based Implementation of Lists
Some languages, such as Fortran and Algol, do not have pointers. If we are working with such a language, we can simulate pointers with cursors, that is, with integers that indicate positions in arrays. For all the lists of elements whose type is elementtype, we create one array of records; each record consists of an element and
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (11 of 40) [1.7.2001 18:58:59]
Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
an integer that is used as a cursor. That is, we define
var
SPACE: array [1..maxlength] of record element: elementtype;
next: integer end
If L is a list of elements, we declare an integer variable say Lhead, as a header for L. We can treat Lhead as a cursor to a header cell in SPACE with an empty element field. The list operations can then be implemented as in the pointer-based implementation just described.
Here, we shall describe an alternative implementation that avoids the use of header cells by making special cases of insertions and deletions at position 1. This same technique can also be used with pointer-based linked-lists to avoid the use of header cells. For a list L, the value of SPACE[Lhead].element is the first element of L. The value of SPACE[Lhead].next is the index of the cell containing the second element, and so on. A value of 0 in either Lhead or the field next indicates a "nil pointer"; that is, there is no element following.
A list will have type integer, since the header is an integer variable that represents the list as a whole. Positions will also be of type integer. We adopt the convention that position i of list L is the index of the cell of SPACE holding element i-1 of L, since the next field of that cell will hold the cursor to element i. As a special case, position 1 of any list is represented by 0. Since the name of the list is always a parameter of operations that use positions, we can distinguish among the first positions of different lists. The position END(L) is the index of the last element on L.
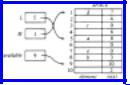
Figure 2.9 shows two lists, L = a, b, c and M = d, e, sharing the array SPACE, with maxlength = 10. Notice that all the cells of the array that are not on either list are linked on another list called available. This list is necessary so we can obtain an empty cell when we want to insert into some list, and so we can have a place to put deleted cells for later reuse.
Fig. 2.9. A cursor implementation of linked lists.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (12 of 40) [1.7.2001 18:58:59]
Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
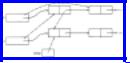
To insert an element x into a list L we take the first cell in the available list and place it in the correct position of list L. Element x is then placed in the element field of this cell. To delete an element x from list L we remove the cell containing x from L and return it to the beginning of the available list. These two actions can be viewed as special cases of the act of taking a cell C pointed to by one cursor p and causing another cursor q to point to C, while making p point where C had pointed and making C point where q had pointed. Effectively, C is inserted between q and whatever q pointed to. For example, if we delete b from list L in Fig. 2.9, C is row 8 of SPACE, p is SPACE[5].next, and q is available. The cursors before (solid) and after (dashed) this action are shown in Fig. 2.10, and the code is embodied in the function move of Fig. 2.11, which performs the move if C exists and returns false if C does not exist.
Figure 2.12 shows the procedures INSERT and DELETE, and a procedure initialize that links the cells of the array SPACE into an available space list. These procedures omit checks for errors; the reader may insert them as an exercise. Other operations are left as exercises and are similar to those for pointer-based linked lists.
Fig. 2.10. Moving a cell C from one list to another.
function move ( var p, q: integer ): boolean;
{ move puts cell pointed to by p ahead of cell pointed to by q } var
temp: integer; begin
if p = 0 then begin { cell nonexistent } writeln('cell does not exist'); return (false)
end
else begin temp := q; q := p;
p := SPACE[q ].next; SPACE[q ].next := temp; return (true)
end
end; { move }
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (13 of 40) [1.7.2001 18:58:59]
Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
Fig. 2.11. Code to move a cell.
Doubly-Linked Lists
In a number of applications we may wish to traverse a list both forwards and backwards efficiently. Or, given an element, we may wish to determine the preceding and following elements quickly. In such situations we might wish
procedure INSERT ( x: elementtype; p: position; var L: LIST );
begin
if p = 0 then begin
{ insert at first position } if move(available, L) then
SPACE[L].element := x
end
else { insert at position other than first } if move(available, SPACE[p].next)
then
{ cell for x now pointed to by SPACE[p].next }
SPACE[SPACE[p].next].element :=
x
end; { INSERT }
procedure DELETE ( p: position; var L: LIST ); begin
if p = 0 then
move(L, available) else
move(SPACE[p].next, available) end; { DELETE }
procedure initialize;
{ initialize links SPACE into one available list } var
i: integer; begin
for i := maxsize - 1 downto 1 do
SPACE[i].next := i + 1; available := 1;
SPACE[maxsize].next := 0 { mark end of available list } end; { initialize }
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (14 of 40) [1.7.2001 18:58:59]

Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
Fig. 2.12. Some procedures for cursor-based linked lists.
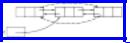
to give each cell on a list a pointer to both the next and previous cells on the list, as suggested by the doubly-linked list in Fig. 2.13. Chapter 12 mentions some specific situations where doubly-linked lists are essential for efficiency.
Fig. 2.13. A doubly linked list.
Another important advantage of doubly linked lists is that we can use a pointer to the cell containing the ith element of a list to represent position i, rather than using the less natural pointer to the previous cell. The only price we pay for these features is the presence of an additional pointer in each cell, and somewhat lengthier procedures for some of the basic list operations. If we use pointers (rather than cursors), we may declare cells consisting of an element and two pointers by
type
celltype = record element: elementtype; next, previous: − celltype
end;
position = − celltype;
A procedure for deleting an element at position p in a doubly-linked list is given in Fig. 2.14. Figure 2.15 shows the changes in pointers caused by Fig. 2.14, with old pointers drawn solid and new pointers drawn dashed, on the assumption that the deleted cell is neither first nor last.† We first locate the preceding cell using the previous field. We make the next field of this cell point to the cell following the one in position p. Then we make the previous field of this following cell point to the cell preceding the one in position p. The cell pointed to by p becomes useless and should be reused automatically by the Pascal run-time system if needed.
procedure DELETE (var p: position ); begin
if p−.previous <> nil
then
{ deleted cell not the first } p−.previous−.next: = p−.next;
if p−.next <> nil
then
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (15 of 40) [1.7.2001 18:58:59]
Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
{ deleted cell not the last } p−.next−.previous : = p−.previous
end; { DELETE }
Fig. 2.14. Deletion from a doubly linked list.
Fig. 2.15. Pointer changes for implementation of a deletion.
2.3 Stacks
A stack is a special kind of list in which all insertions and deletions take place at one end, called the top. Other names for a stack are "pushdown list," and "LIFO" or "last- in-first-out" list. The intuitive model of a stack is a pile of poker chips on a table, books on a floor, or dishes on a shelf, where it is only convenient to remove the top object on the pile or add a new one above the top. An abstract data type in the STACK family often includes the following five operations.
1.MAKENULL(S). Make stack S be an empty stack. This operation is exactly the same as for general lists.
2.TOP(S). Return the element at the top of stack S. If, as is normal, we identify the top of a stack with position 1, then TOP(S) can be written in terms of list operations as RETRIEVE(FIRST(S), S).
3.POP(S). Delete the top element of the stack, that is, DELETE(FIRST(S), S). Sometimes it is convenient to implement POP as a function that returns the element it has just popped, although we shall not do so here.
4.PUSH(x, S). Insert the element x at the top of stack S. The old top element becomes next-to-top, and so on. In terms of list primitives this operation is INSERT(x, FIRST(S), S).
5.EMPTY(S). Return true if S is an empty stack; return false otherwise.
Example 2.2. Text editors always allow some character (for example, "backspace") to serve as an erase character, which has the effect of canceling the previous uncanceled character. For example, if '#' is the erase character, then the string abc#d##e is really the string ae. The first '#' cancels c, the second d, and the third b.
Text editors also have a kill character, whose effect is to cancel all previous characters on the current line. For the purposes of this example, we shall use '@' as the kill character.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (16 of 40) [1.7.2001 18:58:59]
Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
A text editor can process a line of text using a stack. The editor reads one character at a time. If the character read is neither the kill nor the erase character, it pushes the character onto the stack. If the character read is the erase character, the editor pops the stack, and if it is the kill character, the editor makes the stack empty. A program that executes these actions is shown in Fig. 2.16.
procedure EDIT; var
S: STACK; c: char;
begin
MAKENULL(S);
while not eoln do begin read(c);
if c = '#' then
POP(S)
else if c = '@' then
MAKENULL(S)
else { c is an ordinary character } PUSH(c, S)
end;
print S in reverse order end; { EDIT }
Fig. 2.16. Program to carry out effects of erase and kill characters.
In this program, the type of STACK must be declared as a list of characters. The process of writing the stack in reverse order in the last line of the program is a bit tricky. Popping the stack one character at a time gets the line in reverse order. Some stack implementations, such as the array-based implementation to be discussed next, allow us to write a simple procedure to print the stack from the bottom. In general, however, to reverse a stack, we must pop each element and push it onto another stack; the characters can then be popped from the second stack and printed in the order they are popped.
An Array Implementation of Stacks
Every implementation of lists we have described works for stacks, since a stack with its operations is a special case of a list with its operations. The linked-list representation of a stack is easy, as PUSH and POP operate only on the header cell and the first cell on the list. In fact, headers can be pointers or cursors rather than
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (17 of 40) [1.7.2001 18:58:59]

Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
complete cells, since there is no notion of "position" for stacks, and thus no need to represent position 1 in a way analogous to other positions.
However, the array-based implementation of lists we gave in Section 2.2 is not a particularly good one for stacks, as every PUSH or POP requires moving the entire list up or down, thus taking time proportional to the number of elements on the stack. A better arrangement for using an array takes account of the fact that insertions and deletions occur only at the top. We can anchor the bottom of the stack at the bottom (high-indexed end) of the array, and let the stack grow towards the top (low-indexed end) of the array. A cursor called top indicates the current position of the first stack element. This idea is shown in Fig. 2.17.
Fig. 2.17. An array implementation of a stack.
For this array-based implementation of stacks we define the abstract data type STACK by
type
STACK = record top: integer;
elements: array[1..maxlength] of elementtype end;
An instance of the stack consists of the sequence elements[top], elements[top+1] , . . .
, elements[maxlength]. Note that if top = maxlength + 1, then the stack is empty.
The five typical stack operations are implemented in Fig. 2.18. Note that for TOP to return an elementtype, that type must be legal as the result of a function. If not, TOP must be a procedure that modifies its second argument by assigning it the value TOP(S), or a function that returns a pointer to elementtype.
procedure MAKENULL ( var S: STACK ); begin
S.top := maxlength + 1 end; { MAKENULL }
function EMPTY ( S: STACK ): boolean;
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (18 of 40) [1.7.2001 18:58:59]
Data Structures and Algorithms: CHAPTER 2: Basic Abstract DataTypes
begin
if S.top > maxlength then return (true)
else
return (false) end; { EMPTY }
function TOP ( var S: STACK ) : elementtype; begin
if EMPTY(S) then error('stack is empty')
else return(S.elements[S.top])
end; { TOP }
procedure POP ( var S: STACK ); begin
if EMPTY(S) then error('stack is empty')
else
S.top := S.top + 1 end; { POP }
procedure PUSH ( x: elementtype; var S: STACK ); begin
if S.top = 1 then error('stack is full')
else begin
S.top := S.top - 1; S.elements[S.top]: = x
end
end; { PUSH }
Fig. 2.18. Operations on stacks
2.4 Queues
A queue is another special kind of list, where items are inserted at one end (the rear) and deleted at the other end (the front). Another name for a queue is a "FIFO" or "first-in first-out" list. The operations for a queue are analogous to those for a stack, the substantial differences being that insertions go at the end of the list, rather than the beginning, and that traditional terminology for stacks and queues is different. We
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1202.htm (19 of 40) [1.7.2001 18:58:59]