

Лабораторная работа №1
.docxМинистерство цифрового развития, связи и массовых коммуникаций
Российской Федерации Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное
учреждение высшего образования
Московский технический университет связи и информатики
Кафедра «Математическая кибернетика и информационные технологии»
Лабораторная работа №1
по дисциплине
«Управление данными»
Москва 2023
Оглавление
Цель работы 2
Ход лабораторной работы 3
Вывод 17
Цель работы
Ознакомиться с методами предобработки данных из библиотеки Scikit Learn.
Ход лабораторной работы
Мной был загружен датасет по ссылке. Созданный Python скрипт представлен на рисунке 1.

Рисунок 1 – Python скрипт
Результат работы скрипта представлен на рисунке 2.
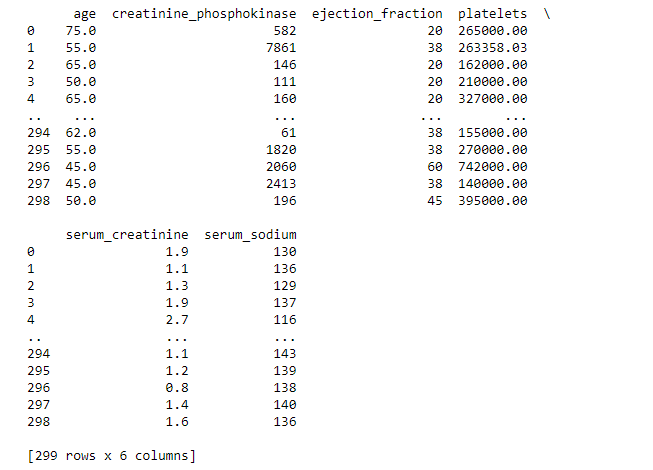
Рисунок 2 – Результат работы скрипта
На рисунке 3 представлен код для построения гистограммы признаков.
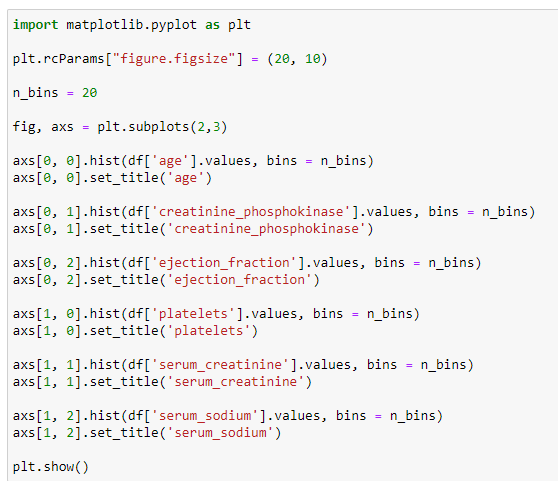
Рисунок 3 - Код для построения гистограммы признаков
На рисунке 4 представлены построенные гистограммы признаков.
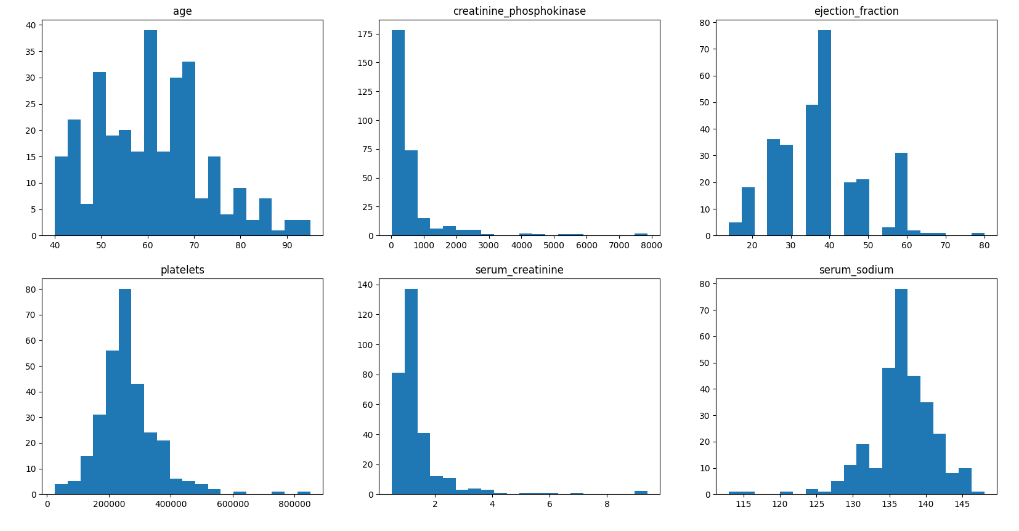
Рисунок 4 - Построенные гистограммы признаков
Так как библиотека Sklearn работает с NumPy массива, то преобразуем датафрейм к двумерному массиву NumPy, где строка соответствует наблюдению, а столбец признаку. Результат представлен на рисунке 5
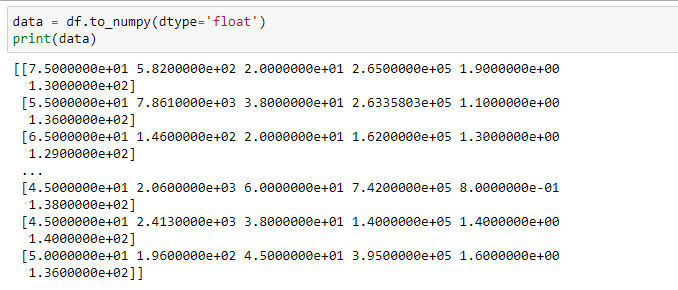
Рисунок 5 – Преобразование к двумерному массиву
На рисунках 6-8 представлен код для построения гистограммы стандартизированных данных.

Рисунок 6 – Подключение модуля и настройка стандартизации
![]()
Рисунок 7 – Стандартизация данных

Рисунок 8 – код для построения гистограммы
Построенные диаграммы представлены на рисунке 9
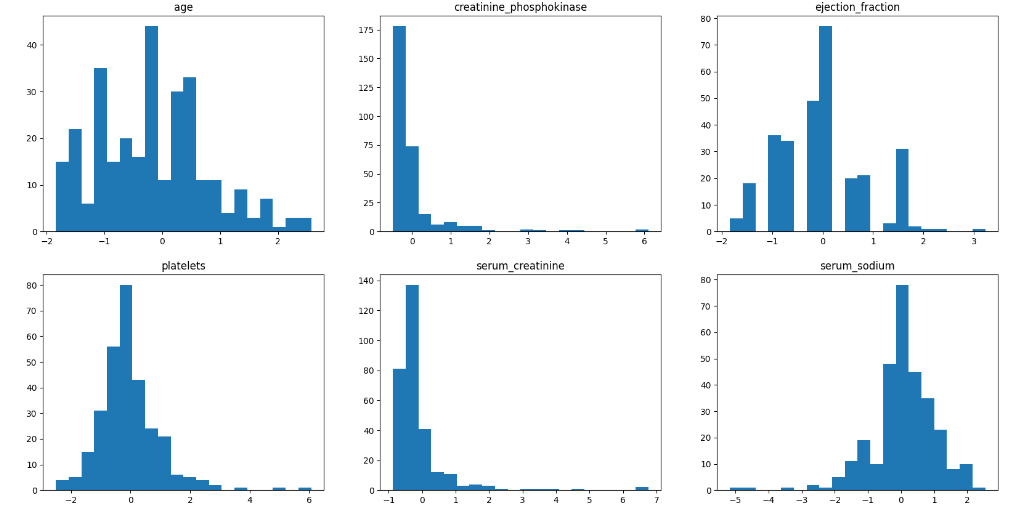
Рисунок 9 – Построенные диаграммы
Рассчитал мат. ожидание и СКО до и после стандартизации. На основании этих значений вывел для каждого признака формулы по которым они стандартизировались. Результат представлен на рисунке 10.

Рисунок 10 – Расчёт мат ожидания
Сравнил значения из формул с полями mean_ и var_ объекта scaler. Результат представлен на рисунке 11.
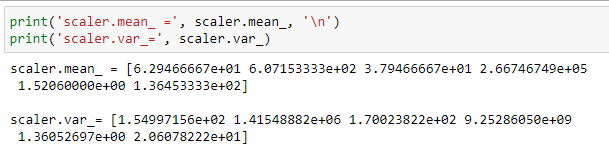
Рисунок 11 – Результат сравнения
Провел настройку стандартизации на всех данных и сравнить с результатами настройки на основании 150 наблюдений. Результат представлен на рисунке 12.
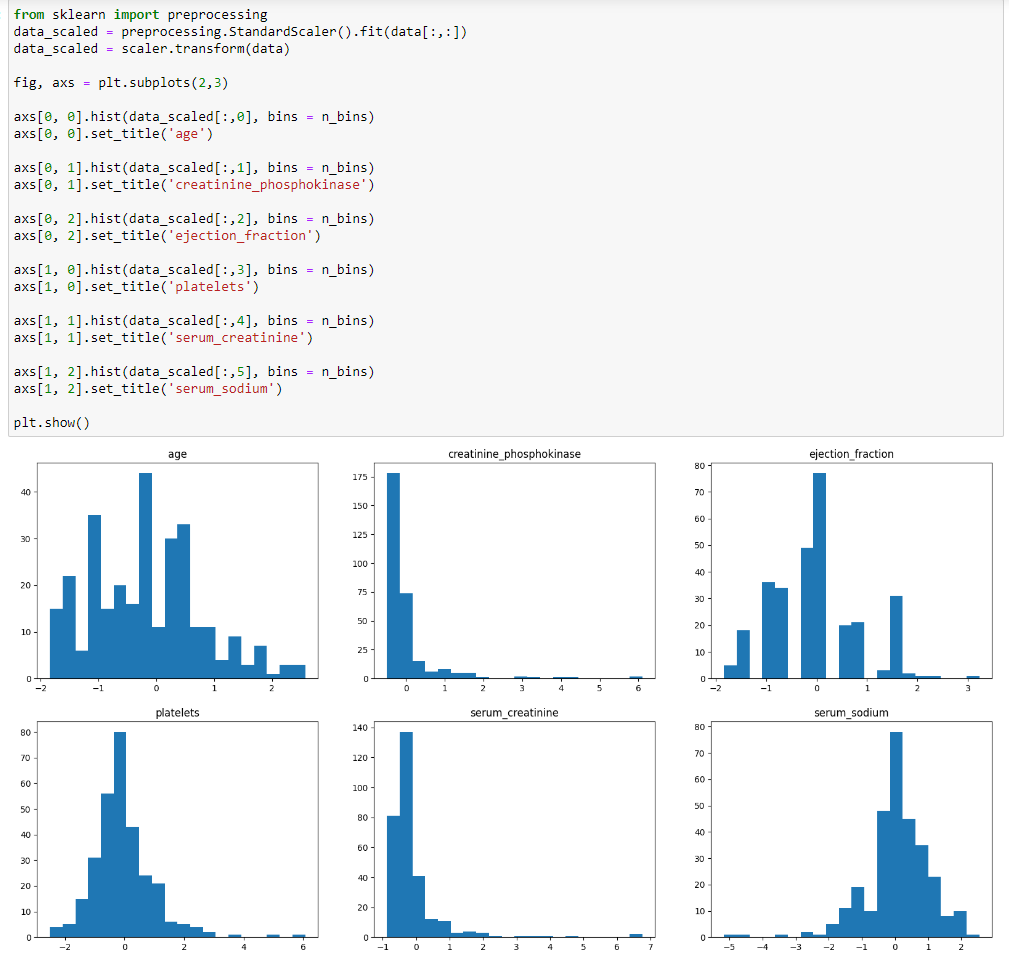
Рисунок 11 – Постройка стандартизации
Привел данные к диапазону используя MinMaxScaler. Код представлен на рисунке 12.

Рисунок 12 – Приведение к диапазону
Построил гистограммы для признаков и сравните с исходными данными. Результат представлен на рисунке 13.
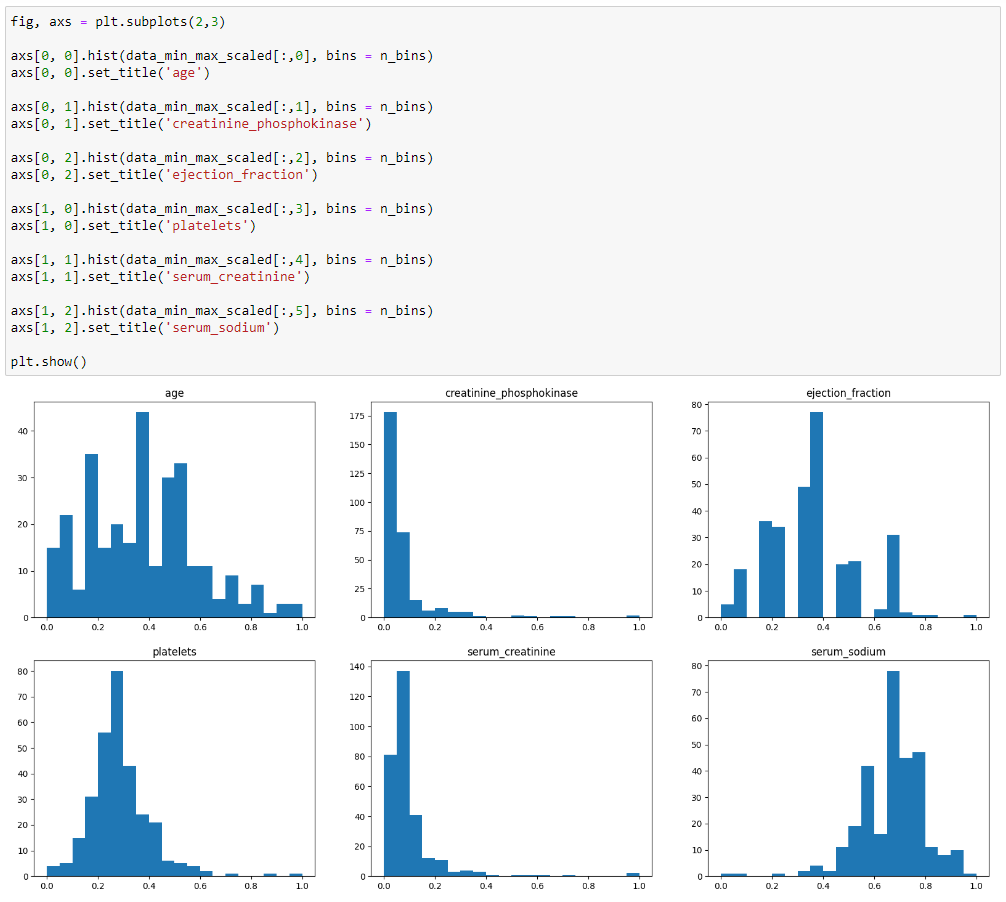
Рисунок 13 - гистограммы для признаков
Через параметры MinMaxScaler определил минимальное и максимальное значение в данных для каждого признака. Результат представлен на рисунке 14.

Рисунок 14 - минимальное и максимальное значение в данных для каждого признака
Аналогично трансформировал данные используя MaxAbsScaler и RobustScaler. Построить гистограммы. Определить к какому диапазону приводятся данные.
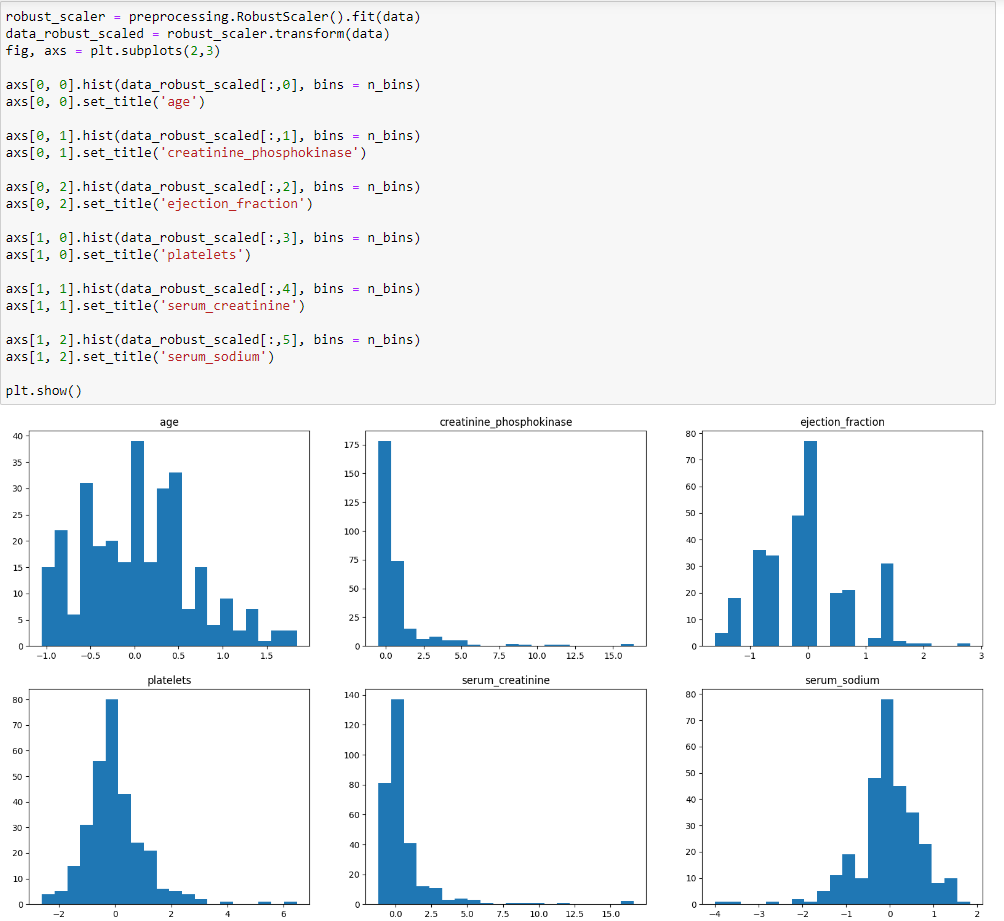
Рисунок 14 – Трансформация данных
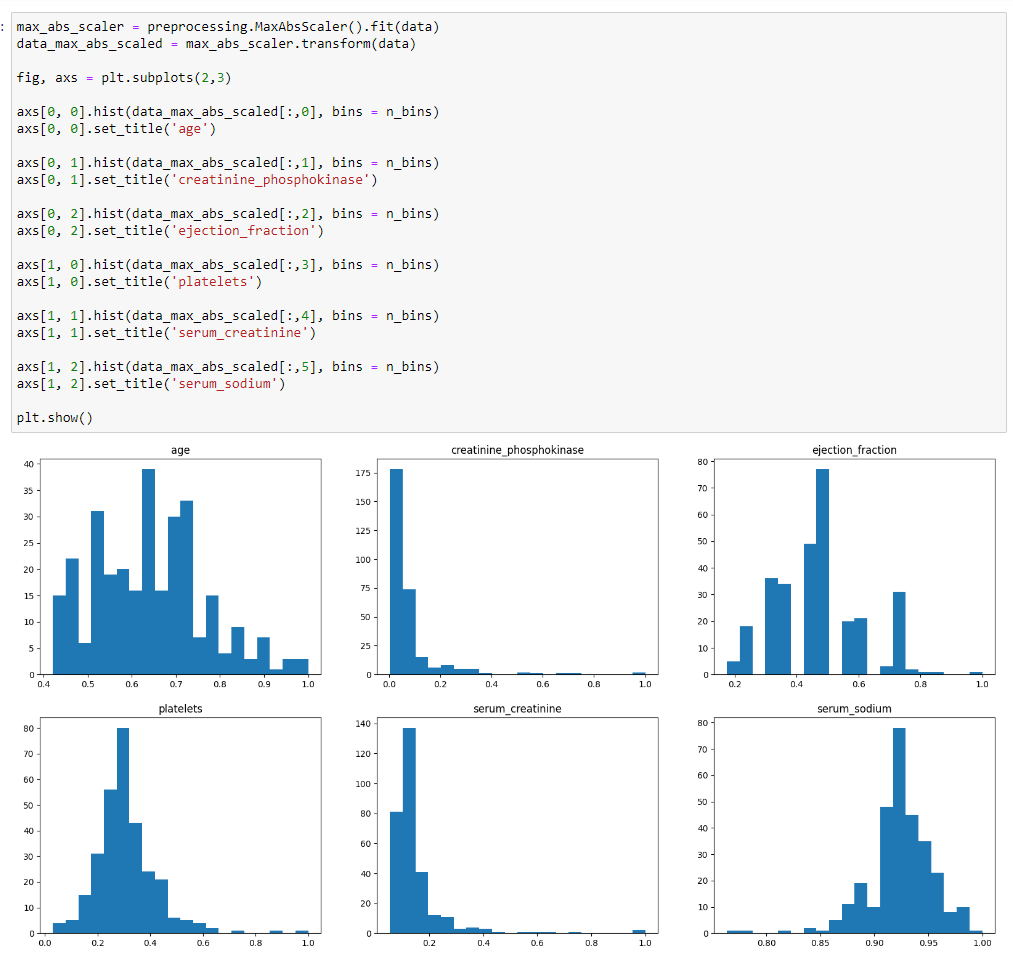
Рисунок 15 – Трансформация данных
Написал функцию, которая приводит все данные к диапазону [-5 10]
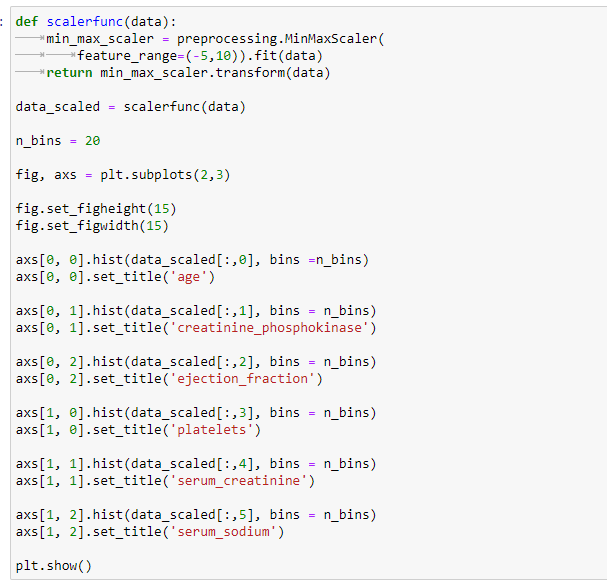
Рисунок 16 – код
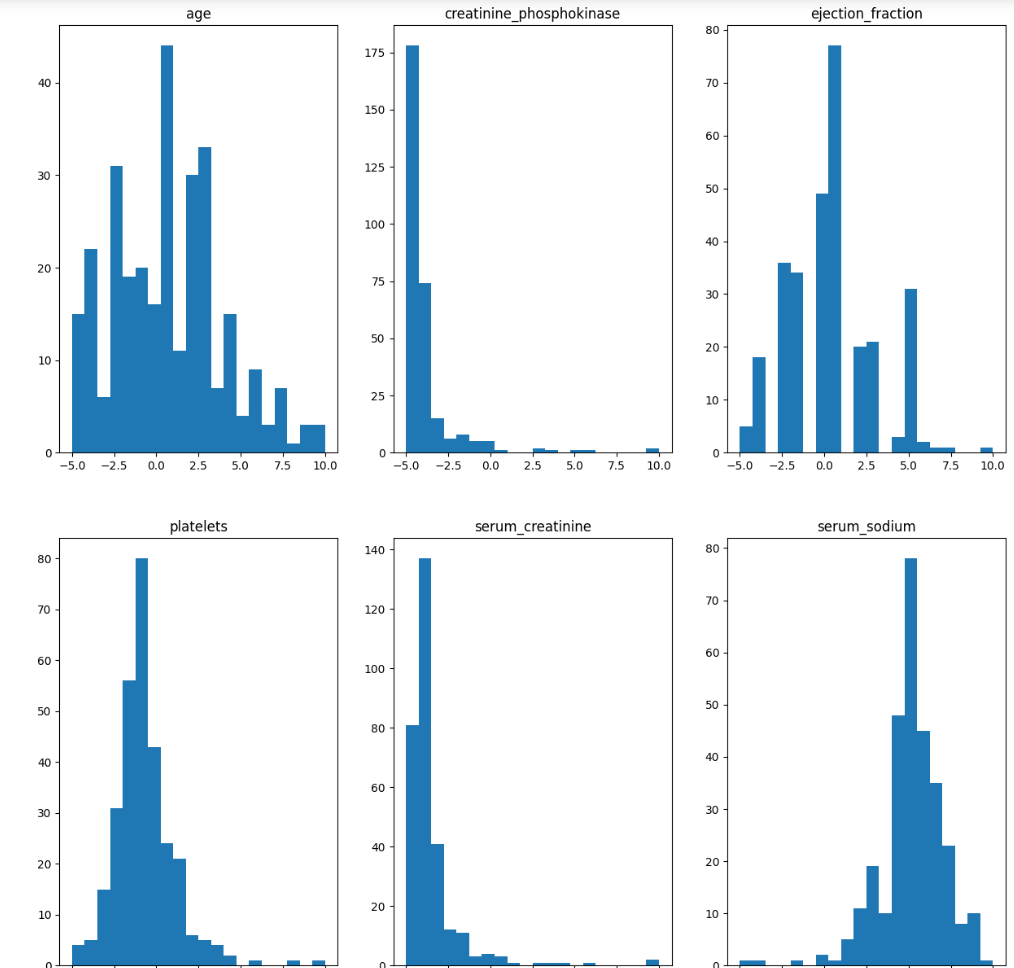
Рисунок 17 - Результат работы
Привел данные к равномерному распределению используя QuantileTransformer
![]()
Рисунок 18 – Код
Построил гистограммы и сравните с исходными данными. Результат работы представлен на рисунке 19.

Рисунок 19 – Результат работы
Самостоятельно привел данные к нормальному распределению используя PowerTransformer. Результат представлен на рисунке 20.

Рисунок 20 – Приведение к нормальному распределению
Провел дискретизацию признаков, используя KBinsDiscretizer, на следующее количество диапазонов: age - 3 creatinine_phosphokinase - 4 ejection_fraction - 3 platelets - 10 serum_creatinine - 2 serum_sodium – 4.

Рисунок 21 - дискретизация признаков
Построение диаграмм представлено на рисунке 22.
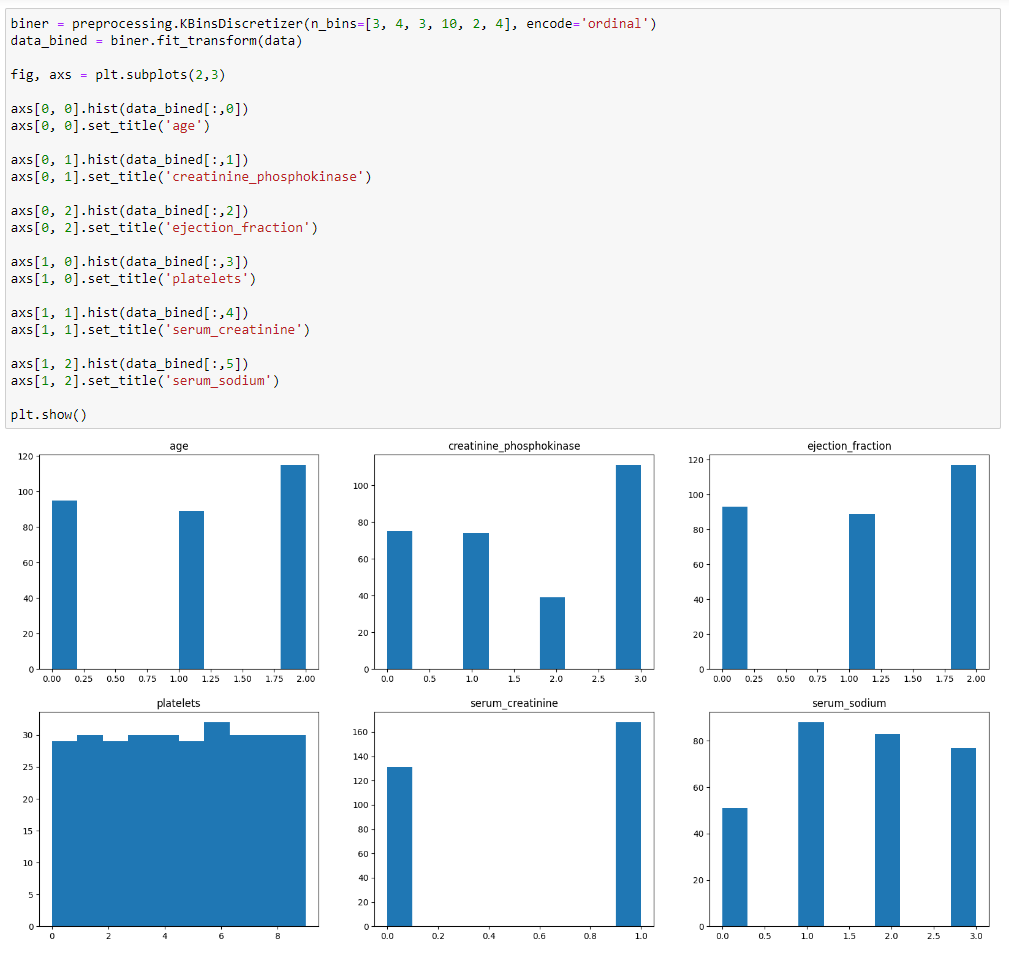
Рисунок 22 – Результат работы
Через параметр bin_edges_ вывел диапазоны каждого интервала для каждого признака. Результат работы представлен на рисунке 23.
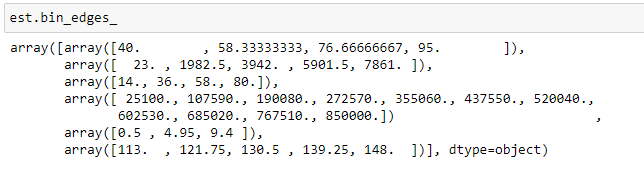
Рисунок 23 – Результат работы
Вывод
Ознакомился с методами предобработки данных из библиотеки Scikit Learn.